







一、集成学习法(Ensemble Learning)
首先,让我们先来了解一下,什么是集成学习法。
① 将多个分类方法聚集在一起,以提高分类的准确率。
(这些算法可以是不同的算法,也可以是相同的算法。)
② 集成学习法由训练数据构建一组基分类器,然后通过对每个基分类器的预测进行投票来进行分类
③ 严格来说,集成学习并不算是一种分类器,而是一种分类器结合的方法。
④ 通常一个集成分类器的分类性能会好于单个分类器
⑤ 如果把单个分类器比作一个决策者的话,集成学习的方法就相当于多个决策者共同进行一项决策。

(集成学习法图解)
要掌握集成学习法,我们会提出以下两个问题:
1)怎么训练每个算法?
2)怎么融合每个算法?
因此,bagging方法和boosting方法应运而生
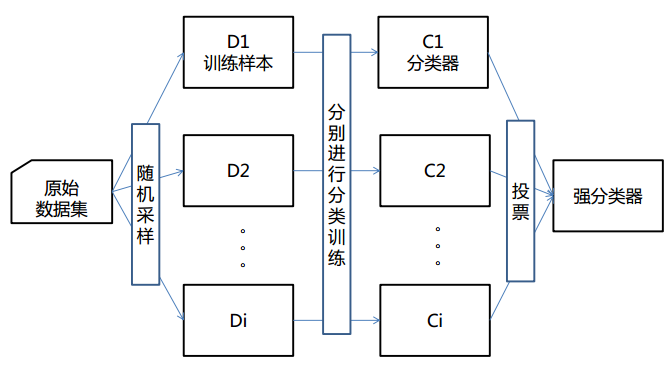
二、bagging(装袋)方法
① Bagging又叫自助聚集,是一种根据均匀概率分布从数据中重复抽样(有放回)的技术。
② 每个抽样生成的自助样本集上,训练一个基分类器;对训练过的分类器进行投票,将测试样本指派到得票最高的类中。
③ 每个自助样本集都和原数据一样大
④ 有放回抽样,一些样本可能在同一训练集中出现多次,一些可能被忽略。
(bagging方法图解)
为了让大家更好地理解bagging方法,这里提供一个例子。
X 表示一维属性,Y 表示类标号(1或-1)测试条件:当x<=k时,y=?;当x>k时,y=?;k为最佳分裂点
下表为属性x对应的唯一正确的y类别
现在进行5轮随机抽样,结果如下

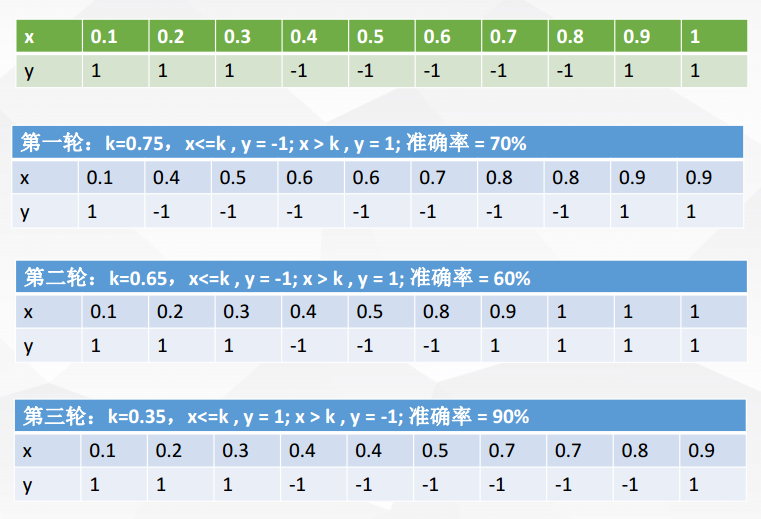
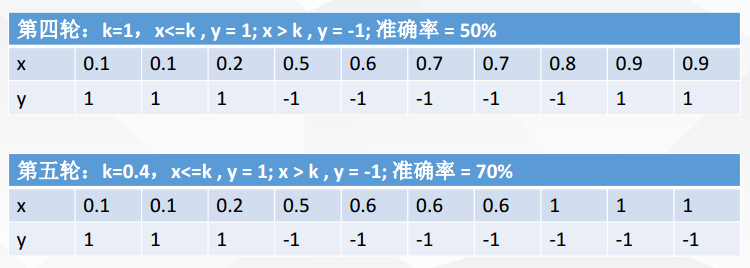
每一轮随机抽样后,都生成一个分类器
然后再将五轮分类融合
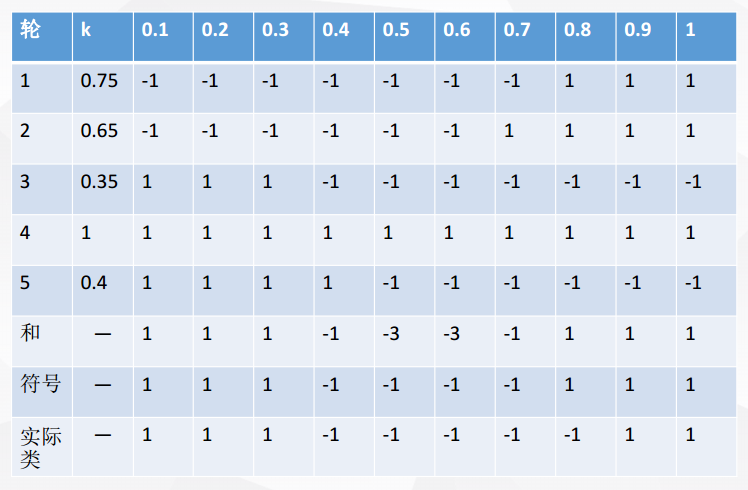
对比符号和实际类,我们可以发现:在该例子中,Bagging使得准确率可达90%
由此,总结一下bagging方法:
① Bagging通过降低基分类器的方差,改善了泛化误差
② 其性能依赖于基分类器的稳定性;如果基分类器不稳定,bagging有助于降低训练数据的随机波动导致的误差;如果稳定,则集成分类器的误差主要由基分类器的偏倚引起
③ 由于每个样本被选中的概率相同,因此bagging并不侧重于训练数据集中的任何特定实例
三、boosting(提升)方法
① boosting是一个迭代的过程,用于自适应地改变训练样本的分布,使得基分类器聚焦在那些很难分的样本上
② boosting会给每个训练样本赋予一个权值,而且可以再每轮提升过程结束时自动地调整权值。开始时,所有的样本都赋予相同的权值1/N,从而使得它们被选作训练的可能性都一样。根据训练样本的抽样分布来抽取样本,得到新的样本集。然后,由该训练集归纳一个分类器,并用它对原数据集中的所有样本进行分类。每轮提升结束时,更新训练集样本的权值。增加被错误分类的样本的权值,减小被正确分类的样本的权值,这使得分类器在随后的迭代中关注那些很难分类的样本。
四、由此我们可以对比Bagging和Boosting
① bagging的训练集是随机的,各训练集是独立的;而boosting训练集的选择不是独立的,每一次选择的训练集都依赖于上一次学习的结果
② bagging的每个预测函数都没有权重;而boosting根据每一次训练的训练误差得到该次预测函数的权重
③ bagging的各个预测函数可以并行生成;而boosting只能顺序生成。(对于神经网络这样极为耗时的学习方法,bagging可通过并行训练节省大量时间开销)
然而,Bagging和Boosting都可以视为比较传统的集成学习思路。 现在常用的Random Forest,GBDT(迭代决策树),GBRank其实都是更加精细化,效果更好的方法。














 3797
3797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









