







 本文深入介绍了Spark,对比了Spark与MapReduce的区别,强调Spark的DAG图支持、Cache机制、多线程池模型和丰富的API。还探讨了Spark的生态系统、核心组件如Master和Worker,以及关键概念——弹性分布式数据集(RDD)的特点和创建方式。此外,文章详细讨论了RDD的操作、依赖关系、Stage划分以及WordCount案例,展示了Spark在YARN上的运行架构,提到了Spark SQL和Spark Streaming的功能,最后介绍了血统(Lineage)在数据容错中的重要作用。
本文深入介绍了Spark,对比了Spark与MapReduce的区别,强调Spark的DAG图支持、Cache机制、多线程池模型和丰富的API。还探讨了Spark的生态系统、核心组件如Master和Worker,以及关键概念——弹性分布式数据集(RDD)的特点和创建方式。此外,文章详细讨论了RDD的操作、依赖关系、Stage划分以及WordCount案例,展示了Spark在YARN上的运行架构,提到了Spark SQL和Spark Streaming的功能,最后介绍了血统(Lineage)在数据容错中的重要作用。
1.Spark简介
什么是Spark?
Spark是UC BerkeleyAmp实验室开源的类Hadoop MapReduce的通用并行计算框架
Spark VS MapReduce
MapReduce
①.缺少对迭代计算以及DAG运算的支持
②.Shuffle过程多次排序和落地,MR之间的数据需要落Hdfs文件系统
Spark
①.提供了一套支持DAG图的分布式并行计算的编程框架,减少多次计算之间中间结果写到hdfs的开销
②.提供Cache机制来支持需要反复迭代计算或者多次数据共享,减少数据读取的IO开销
③.使用多线程池模型来减少task启动开稍,shuffle过程中避免不必要的sort操作以及减少磁盘IO操作
④.广泛的数据集操作类型(map,groupby,count,filter)
⑤.Spark通过提供丰富的Scala, Java,PythonAPI及交互式Shell来提高可用性
⑥.RDD之间维护了血统关系,一旦RDDfail掉了,能通过父RDD自动重建,保证了容错性。 采用容错的、高可伸缩性的akka作为通讯框架
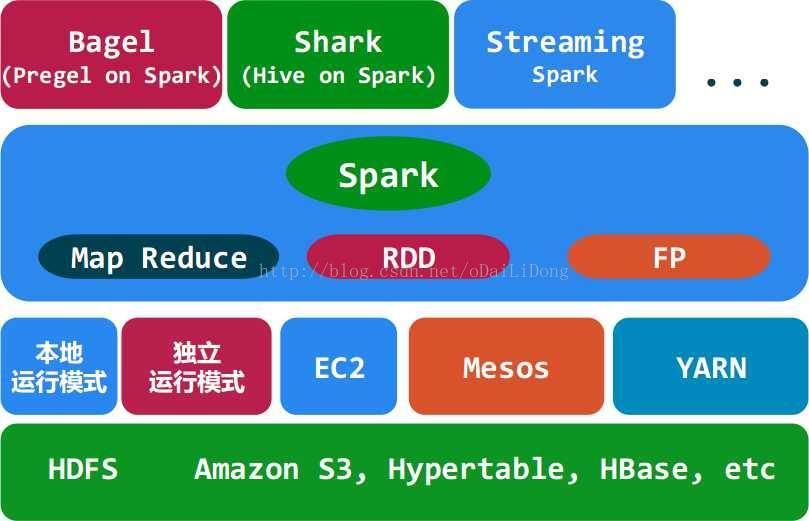
2.Spark生态系统
3.Scala集合简介
vallist2 = List(1,2,3,4,5)
list2.map{x=>x +8} //{9,10,11,12,13}
list2.filter{x=>x > 3} //{4,5}
list2.reduce(_ + _)
更多scala学习网址:http://twitter.github.io/scala_school/zh_cn/collections.html
4.spark的关键组件
•Master
•Worker
•SparkContext(客户端)
5.核心概念:弹性分布式数据集
Spark围绕的概念是弹性分布式数据集(RDD),这是一个有容错机制并可以被并行操作的元素集合。
RDD的特点:
失败自动重建。对于丢失部分数据分区只需根据它的lineage(见文章最后介绍)就可重新计算出来,而不需要做特定的Checkpoint
可以控制存储级别(内存、磁盘等)来进行重用。默认是存储于内存,但当内存不足时,RDD会spill到disk
必须是可序列化的。
目前RDD有两种创建方式:并行集合(ParallelizedCollections):接收一个已经存在的Scala集合,然后进行各种并行计算。 Hadoop数据集(HadoopDatasets):在一个文件的每条记录上运行函数。只要文件系统是HDFS,或者hadoop支持的任意存储系统即可。这两种类型的RDD都可以通过相同的方式进行操作。
1.并行集合(Parallelized Collections)
•并行集合是通过调用SparkContext的parallelize方法,在一个已经存在的Scala集合上创建的(一个Seq对象)。集合的对象将会被拷贝,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









