






解决GAN训练过程中的报错:one of the variables needed for gradient computation has been modified by an inplace operation
tensor的一些attribute:
* requires_grad 是否需要计算梯度
* grad (叶子节点)梯度值
* grad_fn (非叶子结点)创建该张量所用方法
* is_leaf 是否为叶子节点(用户创建而非运算得到的张量)
只有当节点的requires_grad = True时,反向传播才会计算该节点的梯度值
动态计算图:
计算图有两个主要元素:
* 节点(数据)
* 边(运算)
每次搭建完一个计算图,在反向传播结束后,整个计算图就在内存中被释放了(只要loss.backward涉及到的边和非叶子节点的梯度值都会被释放),只保留叶子节点的梯度值。
如果想在同一计算图中定义多个loss,那么需要设置loss.backward(retain_graph=True)
相当于“注释”掉了loss.backward但保留了其计算出的梯度值
Inplace操作:
a = a + 1 a指向新的内存地址
a += 1 a的内存地址不变
* 对于非叶子节点,inplace操作只要不影响反向传播就没有问题,例如torch.nn.Relu(inplace=True)
* 对于reuqires_grad=False叶子节点,如果该节点不影响反向梯度的计算(该值不被梯度计算所需要比如add操作,或者前方节点梯度截断),那么可以进行inplace操作
* 对于requires_grad=True的叶子节点是不能使用inplace操作的,这会使该叶子节点变成非叶子节点(参与了运算)并“抢占”原先叶子节点的内存地址,从而破坏反向传播
GAN:
生成对抗网络模型中optimizer.step()就是inplace操作(代码参考从PyTorch中的梯度计算出发谈如何避免训练GAN中出现inplace error_算法菜鸟飞高高的博客-CSDN博客
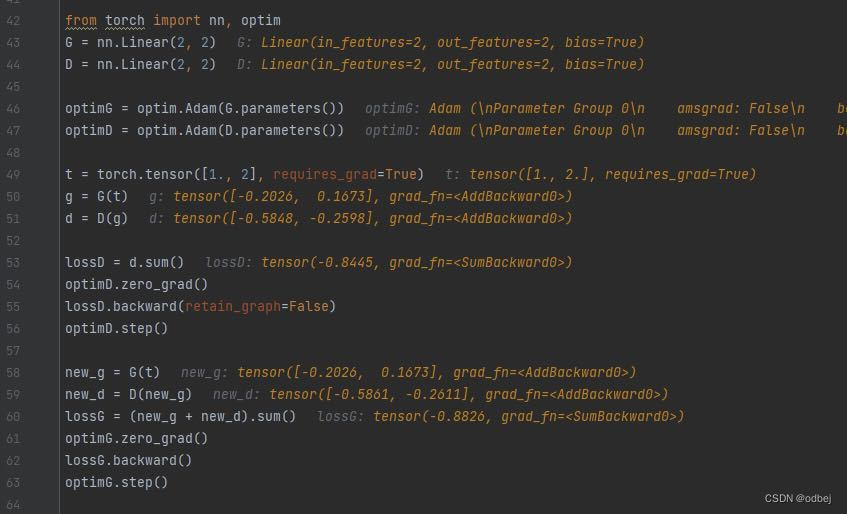
lossD.backward(retain_graph=False)未保留计算图,g=G(t),d=D(g)都被释放,
所以需要重新搭建计算图计算lossG。 而此时D中的参数已经经过optimD更新,相当于使用训练过的D去训练G
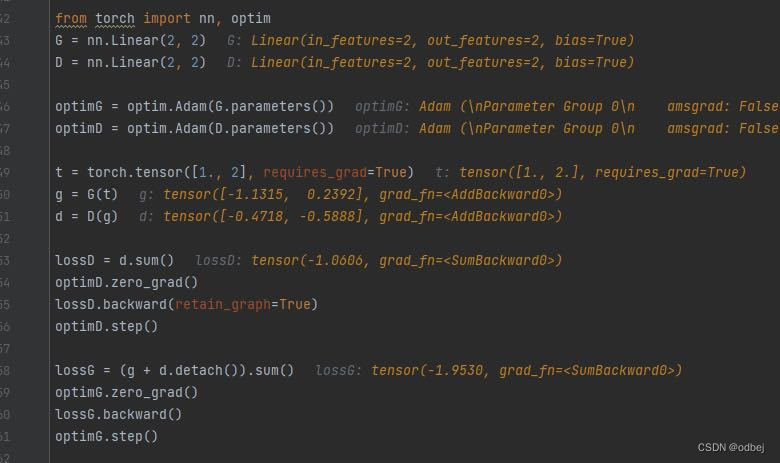
lossD.backward(retain_graph=True)保留计算图,计算lossG时可以延用之前计算得出的g=G(t),d=D(g),节省了计算资源,相当于使用参数未经更新的D来训练G。
但D的参数已经被更新了,而这些参数直接参与了反向梯度的计算。lossG中的d中参数已经发生了改变,不再是原来求的d的那个D了。直接运行会报错某个计算梯度需要的变量被inplace操作了
上图使用了detach()函数,该函数的作用就是创建一个张量与原张量共享内存地址,但requires_grad=False,有截断梯度的作用,类似with torch.no_grad 截断了该点的梯度,即使之前的节点需要计算梯度,梯度也无法回传,所以lossG中的d.detach()实际上没有发挥作用
总结:所以最好的方法就是先更新D,然后使用更新过的D重新计算lossG去更新G;或者在一个计算图中先更新G,计算lossD时利用g.detach()截断回传给new_G的梯度需求,再更新D
(纯属个人学习笔记,有错误希望大佬指正,感谢~)















 1991
1991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









