






安装
安装ES
docker安装
//安装es7.4.2版本
docker pull elasticsearch:7.4.2
//安装kibana7.4.2版本
docker pull kibana:7.4.2
创建es挂载的本机宿主机目录
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
//设置es运行外界ip访问
echo "http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml
//设置目录开放所有权限
chmod -R 777 /mydata/elasticsearch/
启动运行es
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx128m" -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins -d elasticsearch:7.4.2
如果是云服务器记得开启防火墙端口9200和9300
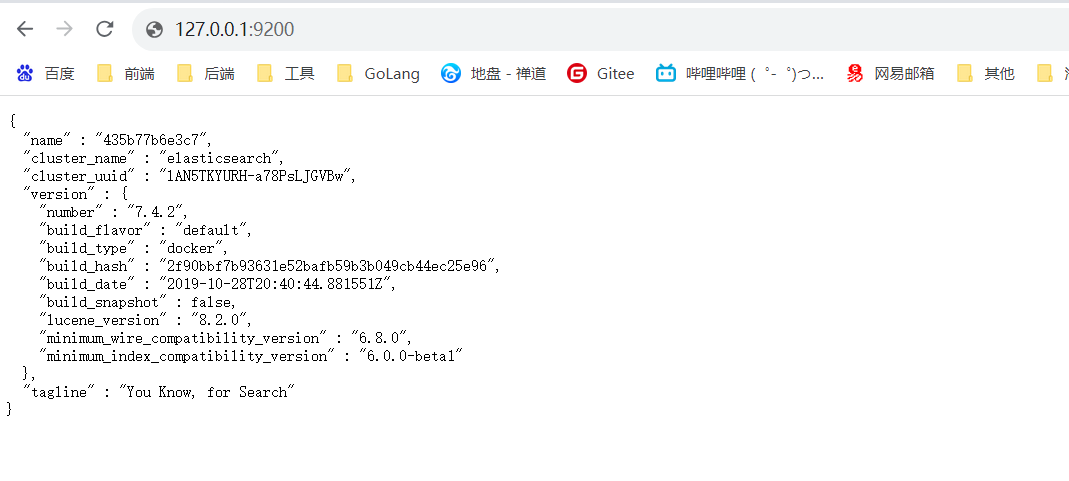
验证是否安装成功
安装Kibana
docker安装
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://121.62.21.74:9200 -p 5601:5601 \
-d kibana:7.4.2
如果是云服务器记得开启防火墙端口5601
提示这个说明正在安装,需要等待一会即可

出现这个就说明安装成功了
入门
_cat基本命令
- IP:9200/_cat/nodes查询所有节点信息,435b77b6e3c7就是节点的name



- IP:9200/_cat/indices查询所有的索引,类似于mysql中的show databases;

索引文档
** 类似于mysql中保存一条数据记录**
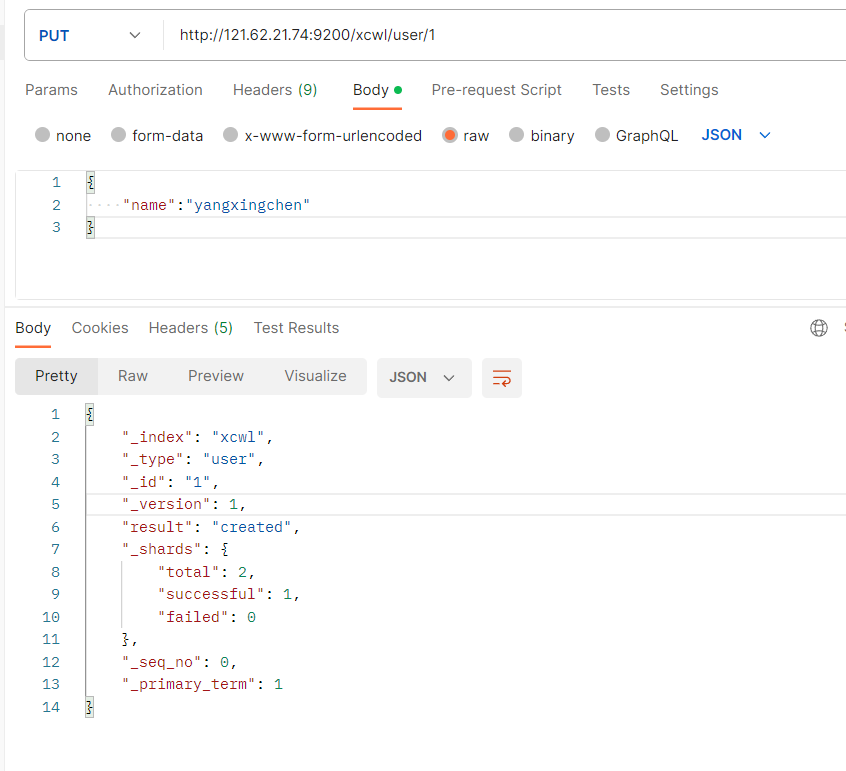
PUT
(必须携带主键ID,存在id就修改,不存在id就新建)
PUT IP:9200/索引名/类型名/主键id
- _index:索引名称
- _type:类型名称
- _id传递进来的id
- result:create(新建)
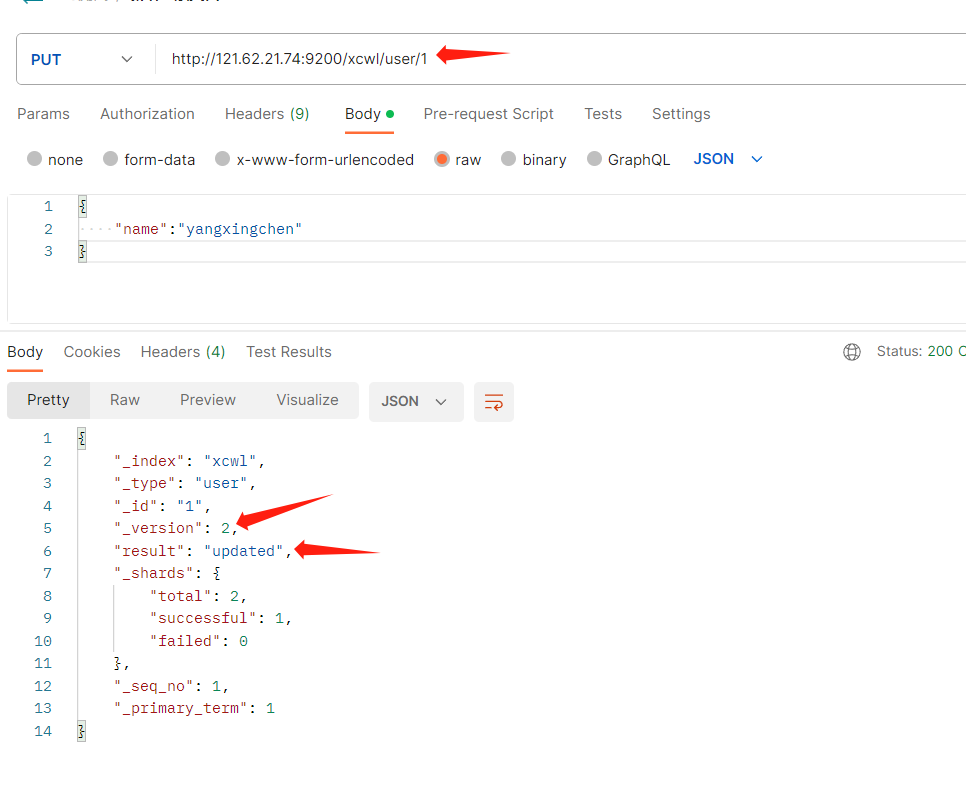
如果两次发送同样的主键id和值。那么就会返回update修改
- _version:表示版本修改了多少次
- result:update(如果你往已经存在的主键id里面发送put,那么就代表修改)
POST
POST IP:9200/索引名/类型名/主键id
- _index:索引名称
- _type:类型名称
- _id传递进来的id
- result:create(新建)
(可以不用携带id,不携带id就随机生成一个id,携带id就新建这个id的主键,携带已存在的id就修改)
- 不携带ID就随机生成一个id
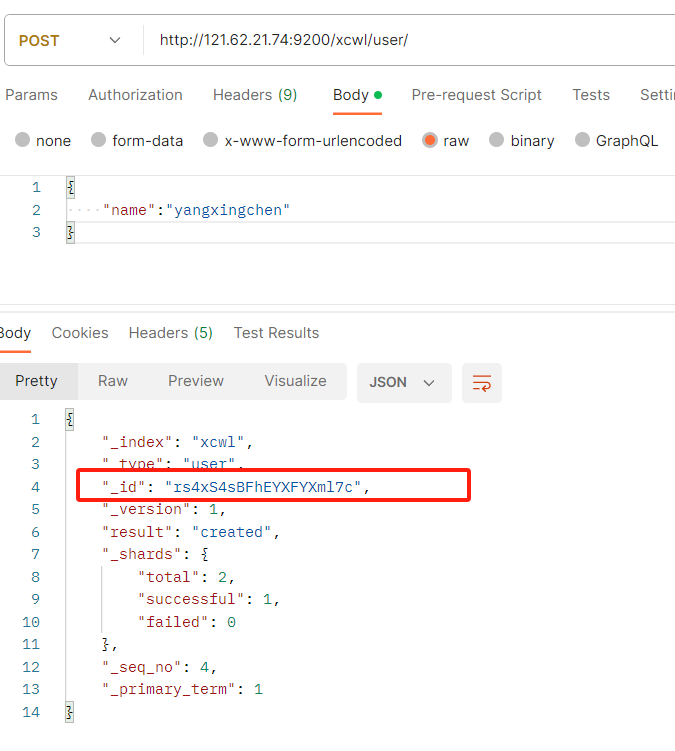
- 携带ID,就新建这个id的索引
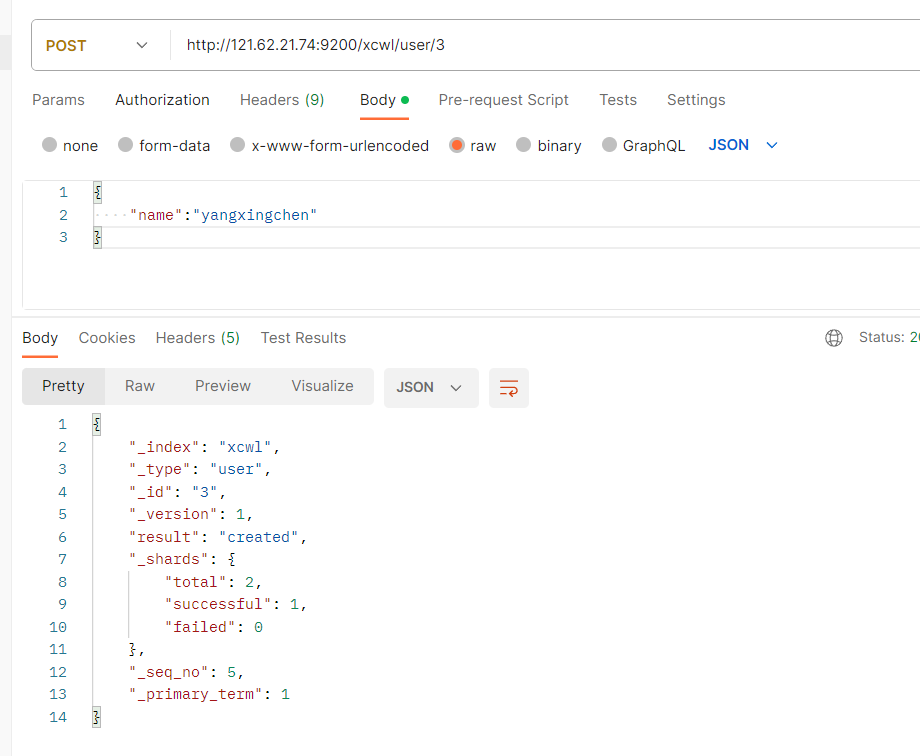
- 携带已存在创建的id,就修改这个id
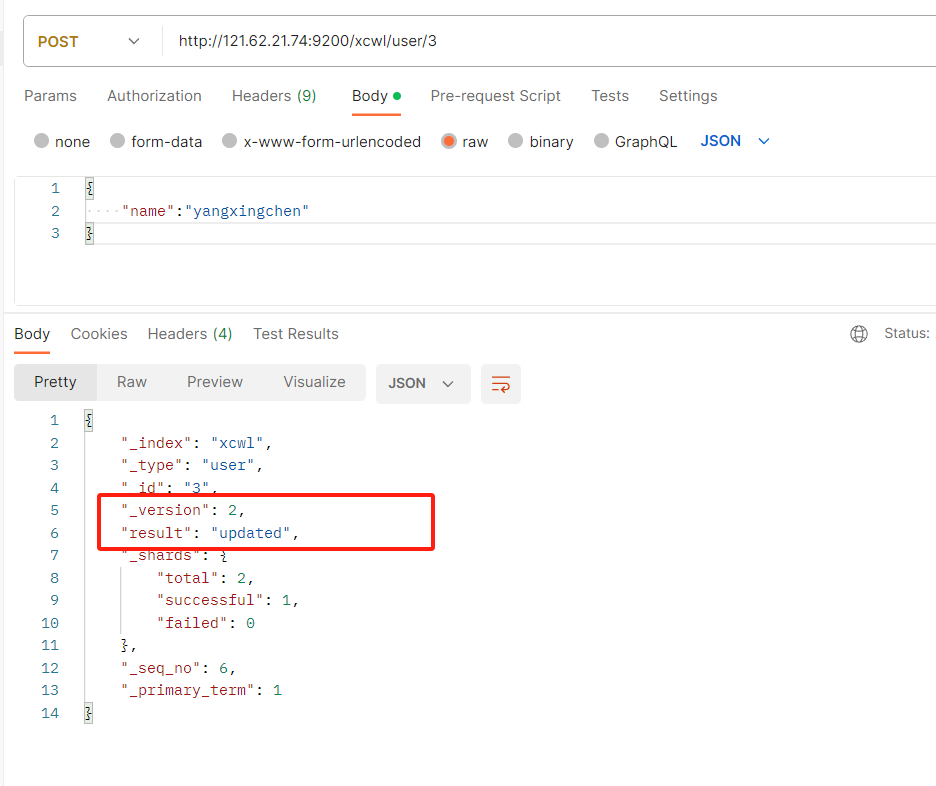
总结:
PUT和POST都可以,
POST新增,如果不指定id,会自动生成一个id,指定id就会修改这个数据,并新增版本号
PUT可以新增可以修改,PUT必须指定id,由于PUT指定id,我们一般都用来做修改操作,不指定id就发请求会报错。
查询文档
GET IP:9200/索引名/类型名/主键id
- _index是我们的索引名
- _type是我们的类型名
- 是我们的主键id名_id
- _seq_no是我们的版本号,更新一次这个版本号就自动增加1(适合做乐观锁)
- found:是否查询到数据
- _source:是我们数据的内容文档
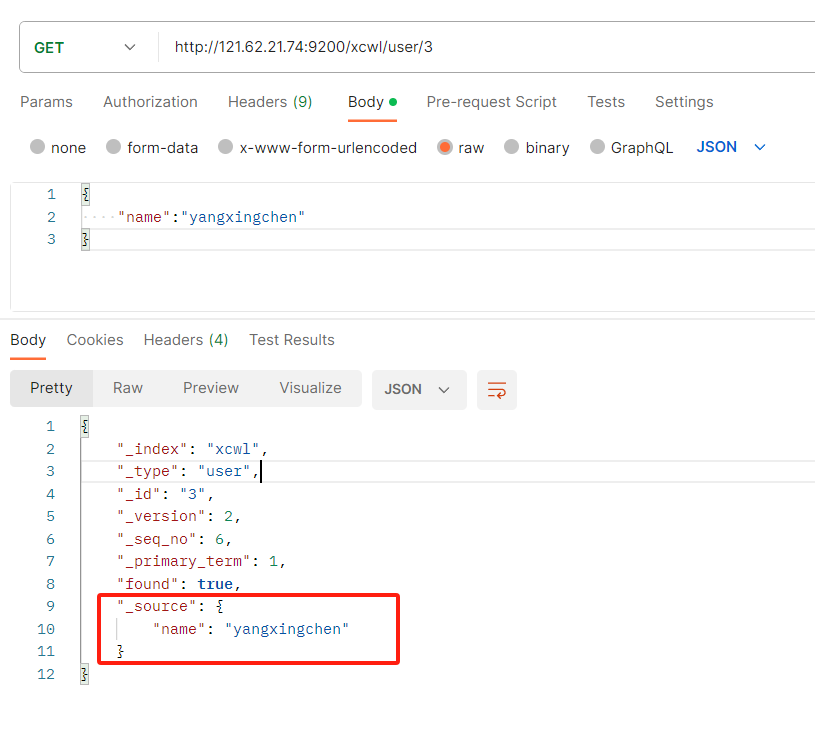
乐观锁
- 我们先查询这个id的_seq_no和_primary_term,通过这个我们来进行实现乐观锁
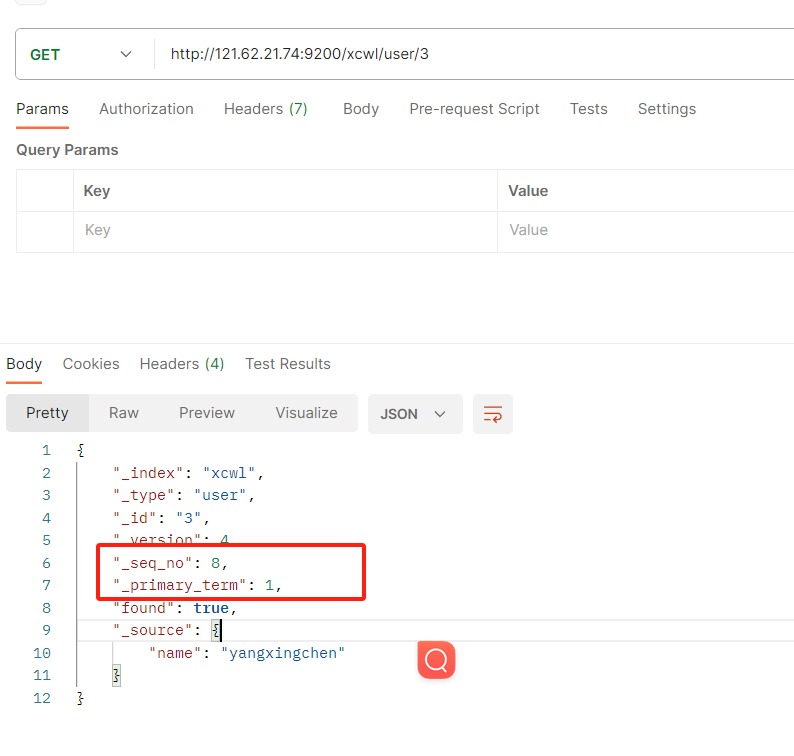
- POST IP:9200/xcwl/user/3?if_seq_no=7&if_primary_term=1 参数携带上if_seq_no和if_primary_term即可,这个if_seq_no=7是通过get查询文档拿到的,当我们进行乐观锁更新的时候,都 带上上一次查询的值进行传递即可更新成功或失败
成功
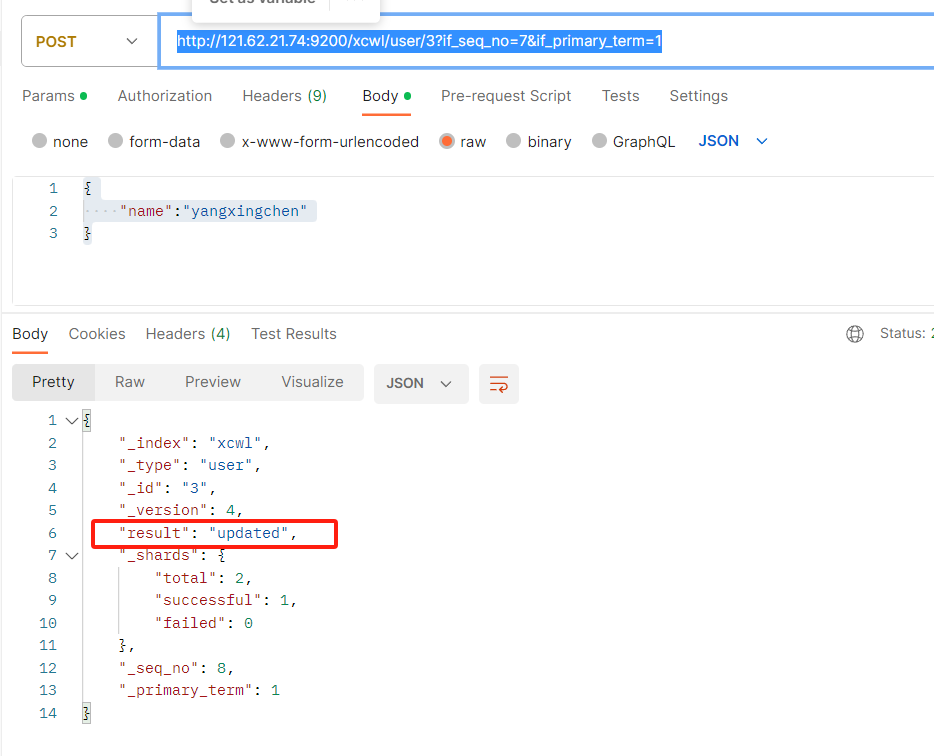
失败
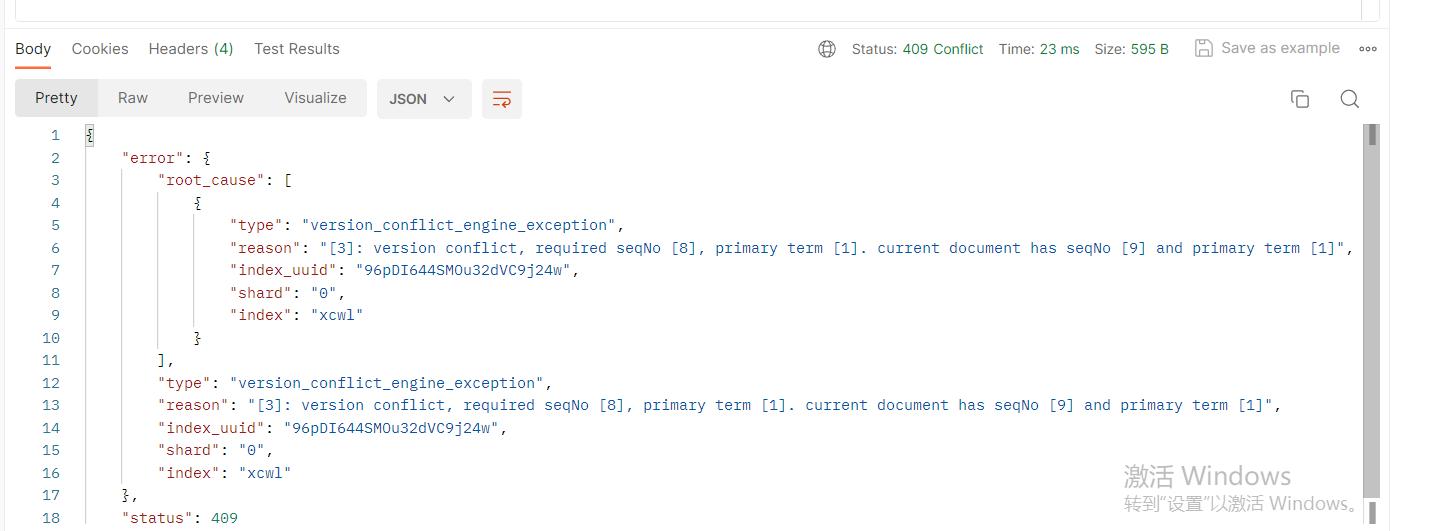
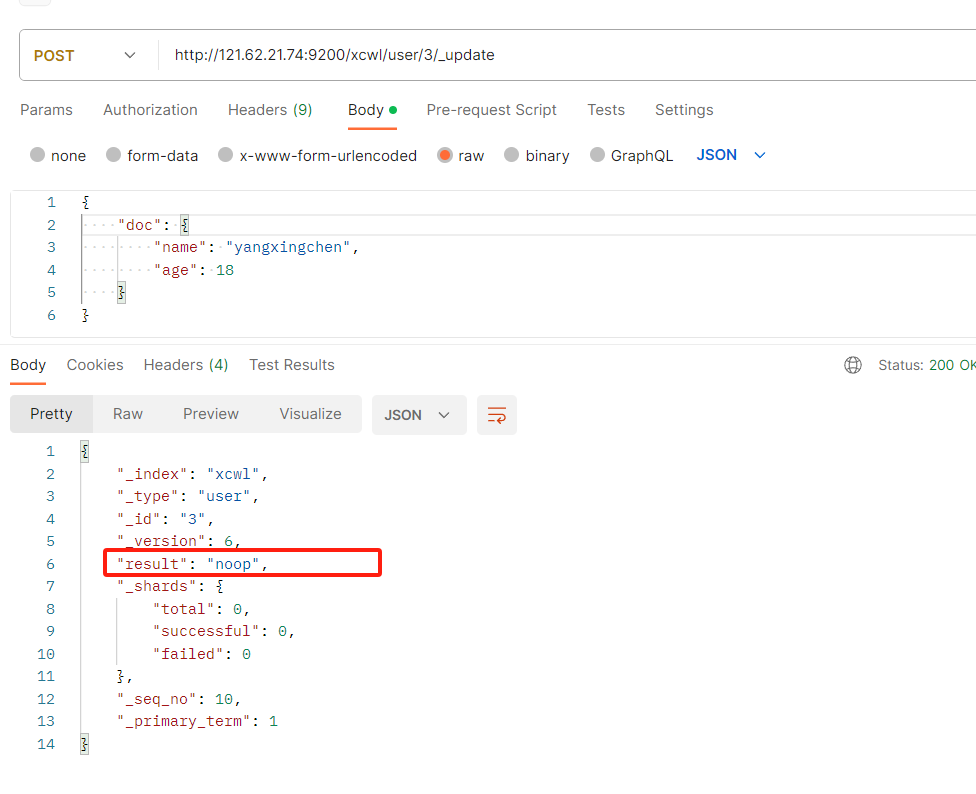
更新文档
_update
校验更新:所谓的校验更新就是,每次更新的时候把新数据和旧数据对比一下,如果相同就不更新,不相同在在更新,字段后面携带_update,
带_update需要在body里面嵌套doc:{值}
POST/PUT
每次更新:每次更新都直接更新,不对比新旧数据是否一样,都直接更新。
总结:对于大并发下更新不带_update,对应大并发查询下偶尔更新适合带update,不需要带doc对象

删除文档
删除某个id主键
DELETE IP:9200/xcwl/user/ID主键
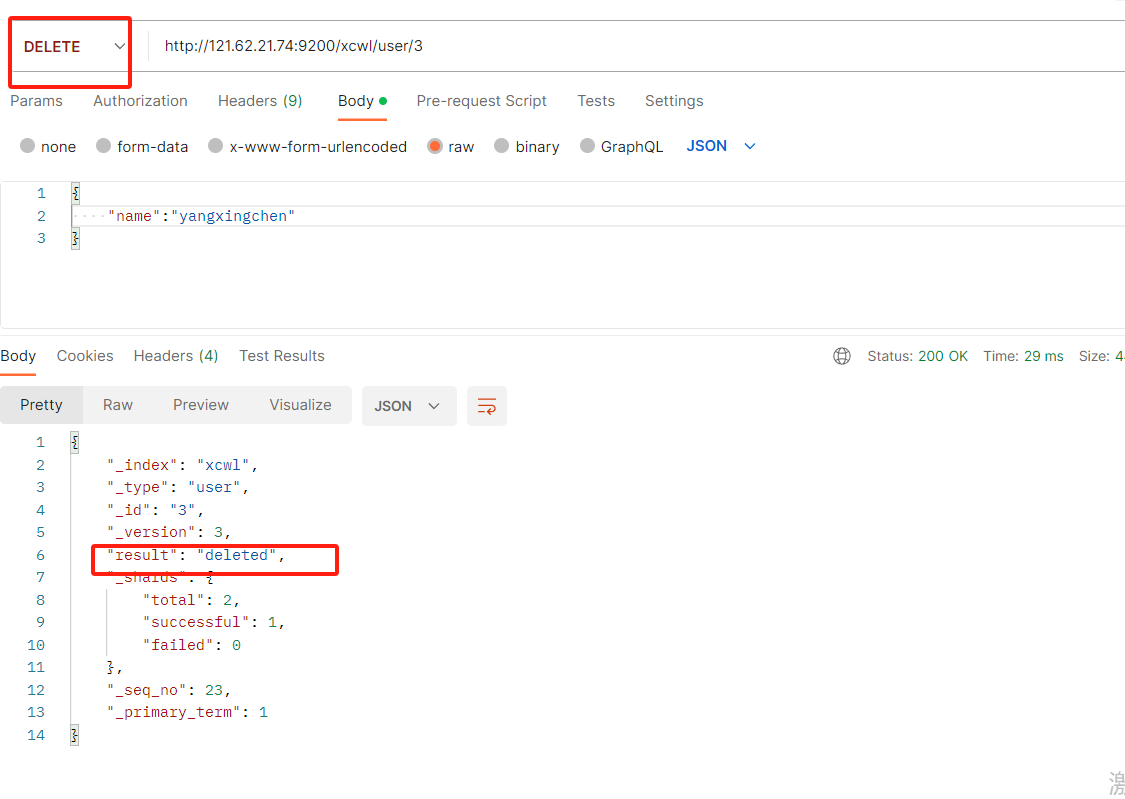
删除整个索引
DELETE IP:9200/索引名
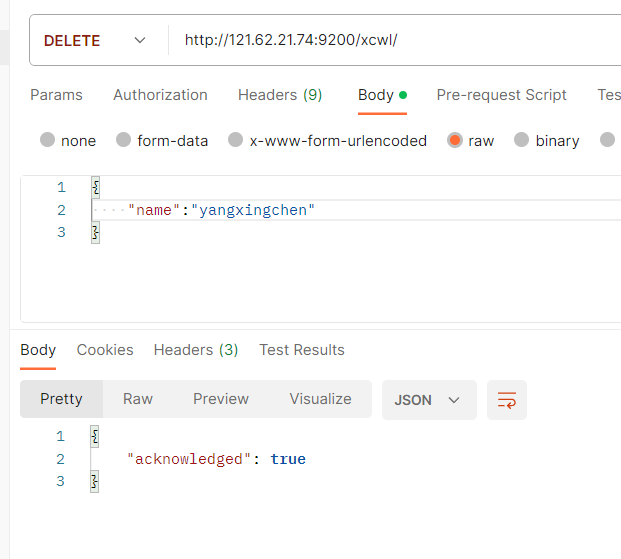
注意:没有删除分类的方法,只有删除索引和id主键
批量新增
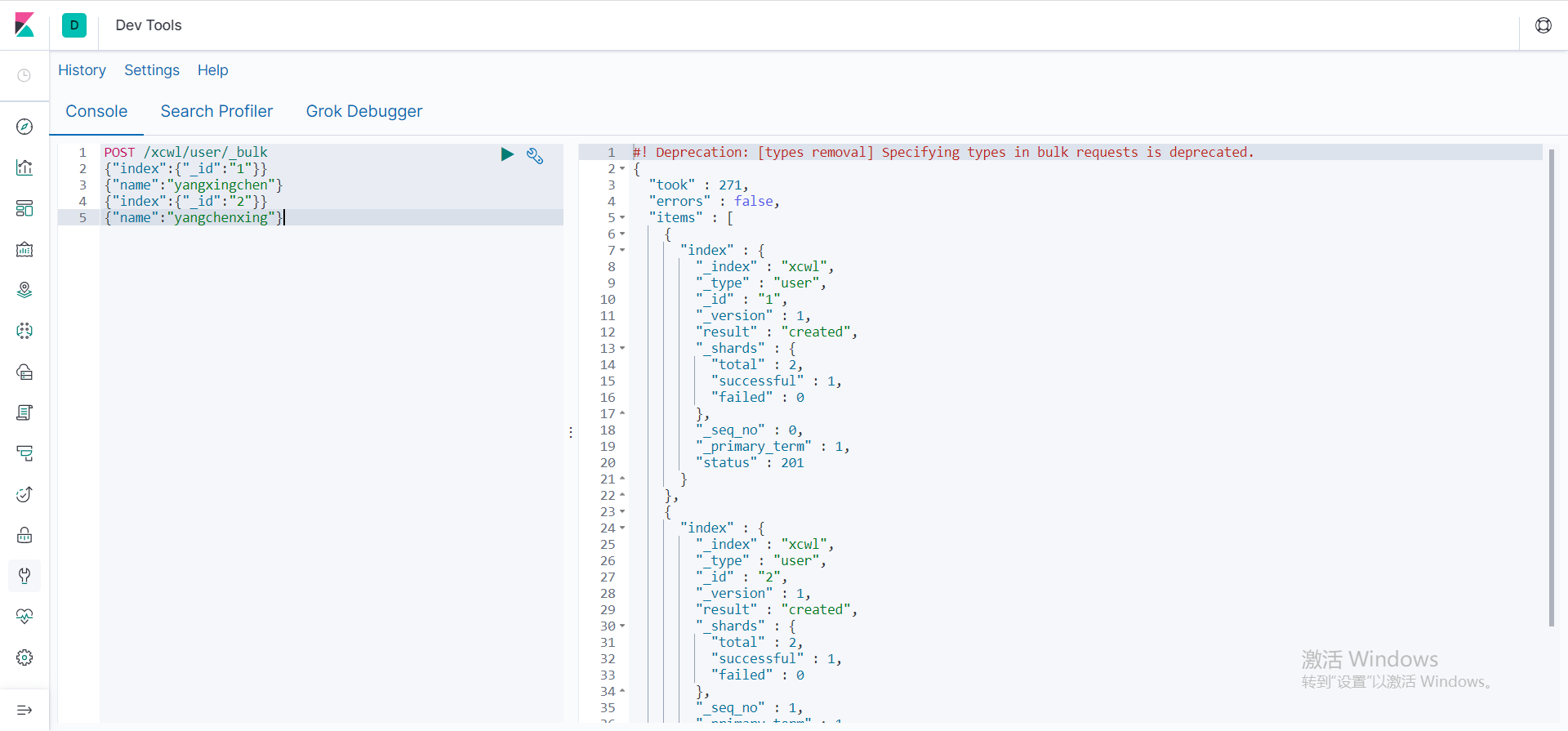
- 统一给某个类型下新增数据
POST IP:9200/索引名/类型名/_bulk
//第一行是id主键,第二行是body的内容值
{"index":{"_id":"1"}}
{"name":"yangxingchen"}
{"index":{"_id":"2"}}
{"name":"yangchenxing"}
插入两条数据,这里使用的kibana,在kibana左侧菜单栏选择dev_tools,即可
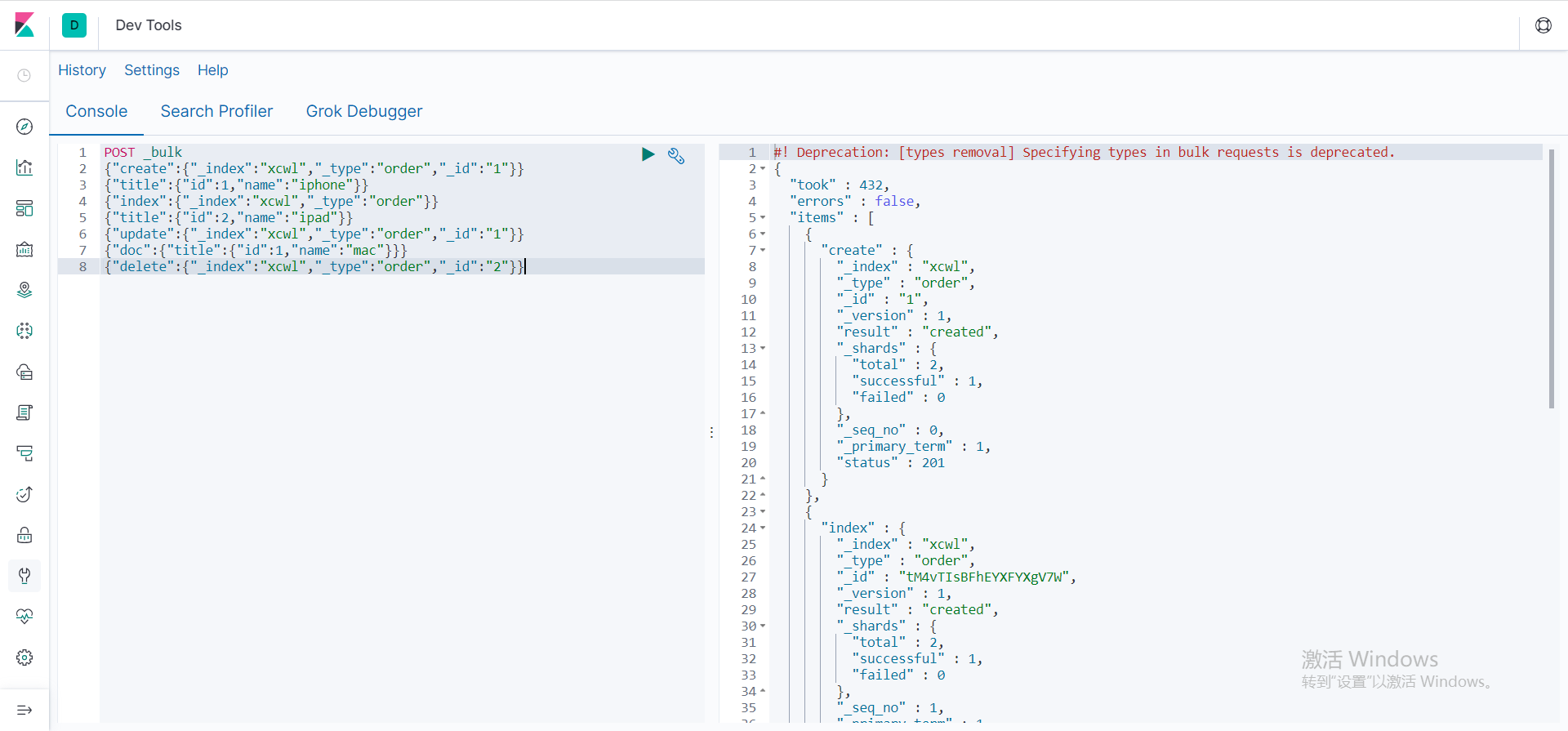
- 给不同类型下批量新增数据
POST :9200/_bulk
除了delete是一行,其他的新增修改都是两行
- 数据指定一个id索引
{"create":{"_index":"xcwl","_type":"order","_id":"1"}}
{"title":{"id":1,"name":"iphone"}}
- 数据随机一个id索引
{"index":{"_index":"xcwl","_type":"order"}}
{"title":{"id":2,"name":"ipad"}}
- 更新一条数据
{"update":{"_index":"xcwl","_type":"order","_id":"1"}}
{"doc":{"title":{"id":1,"name":"mac"}}}
- 删除一条数据
{"delete":{"_index":"xcwl","_type":"order","_id":"2"}}
- 完整批量插入数据
{"create":{"_index":"xcwl","_type":"order","_id":"1"}}
{"title":{"id":1,"name":"iphone"}}
{"index":{"_index":"xcwl","_type":"order"}}
{"title":{"id":2,"name":"ipad"}}
{"update":{"_index":"xcwl","_type":"order","_id":"1"}}
{"doc":{"title":{"id":1,"name":"mac"}}}
{"delete":{"_index":"xcwl","_type":"order","_id":"2"}}
高级
新增测试数据
将下方的测试数据赋值到binaba批量新增方法添加到我们的ES中
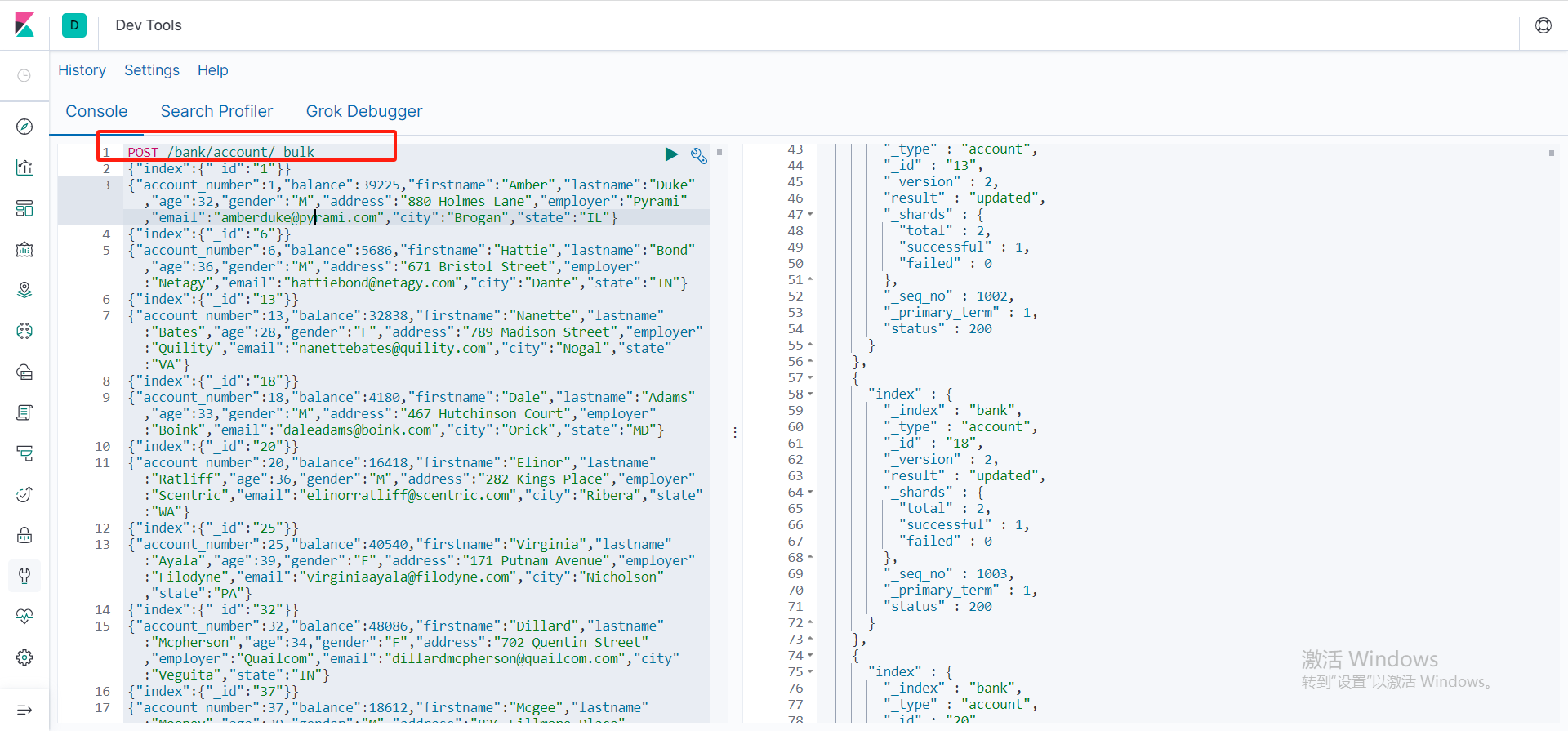
POST /bank/account/_bulk
{"index":{"_id":"1"}}
{"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"amberduke@pyrami.com","city":"Brogan","state":"IL"}
{"index":{"_id":"6"}}
{"account_number":6,"balance":5686,"firstname":"Hattie","lastname":"Bond","age":36,"gender":"M","address":"671 Bristol Street","employer":"Netagy","email":"hattiebond@netagy.com","city":"Dante","state":"TN"}
高级检索
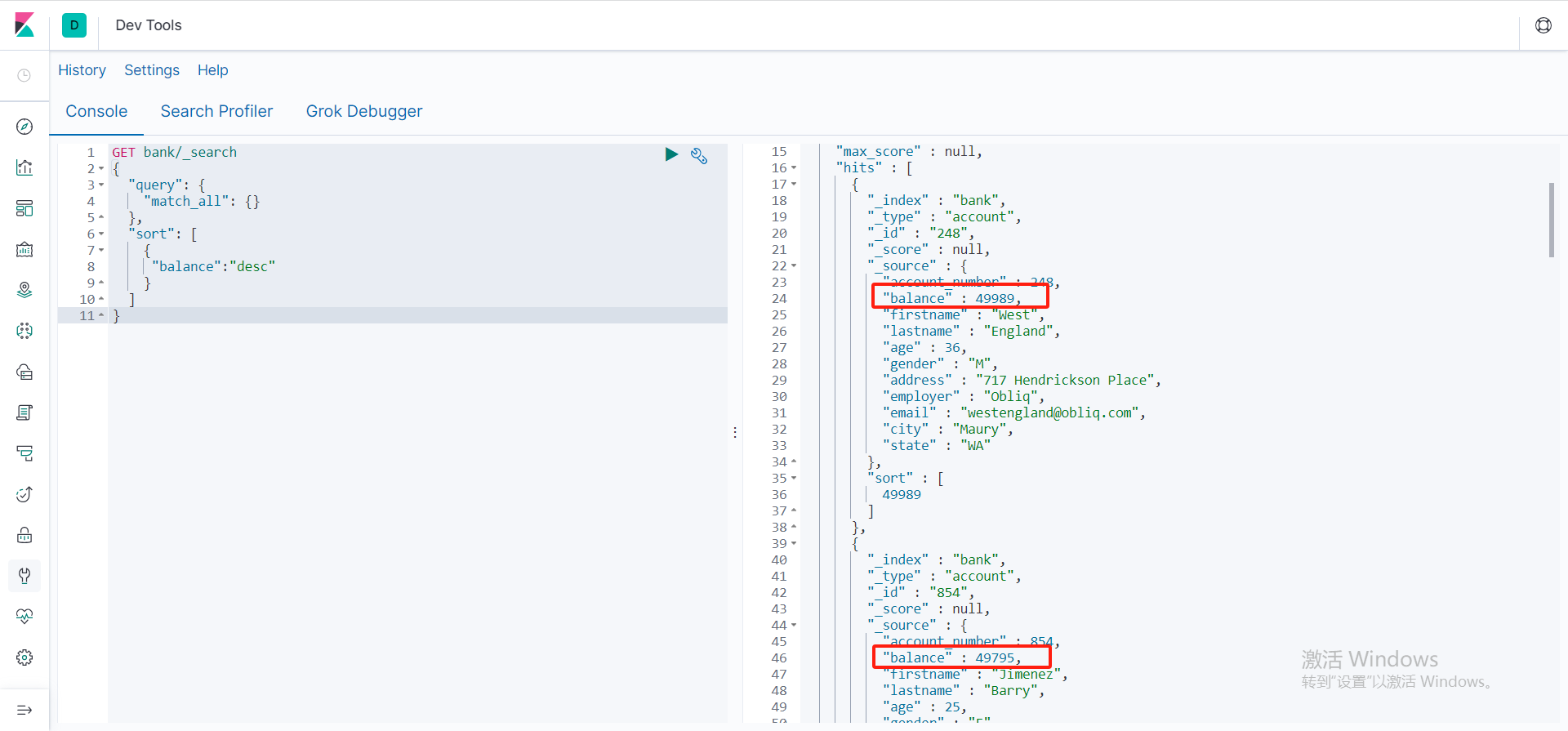
排序查询
sort是可以数组,可以多个字段进行检索
{
"balance":"desc"
},
{
"xxx":"xxx"
}
GET bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"balance":"desc"
}
]
}
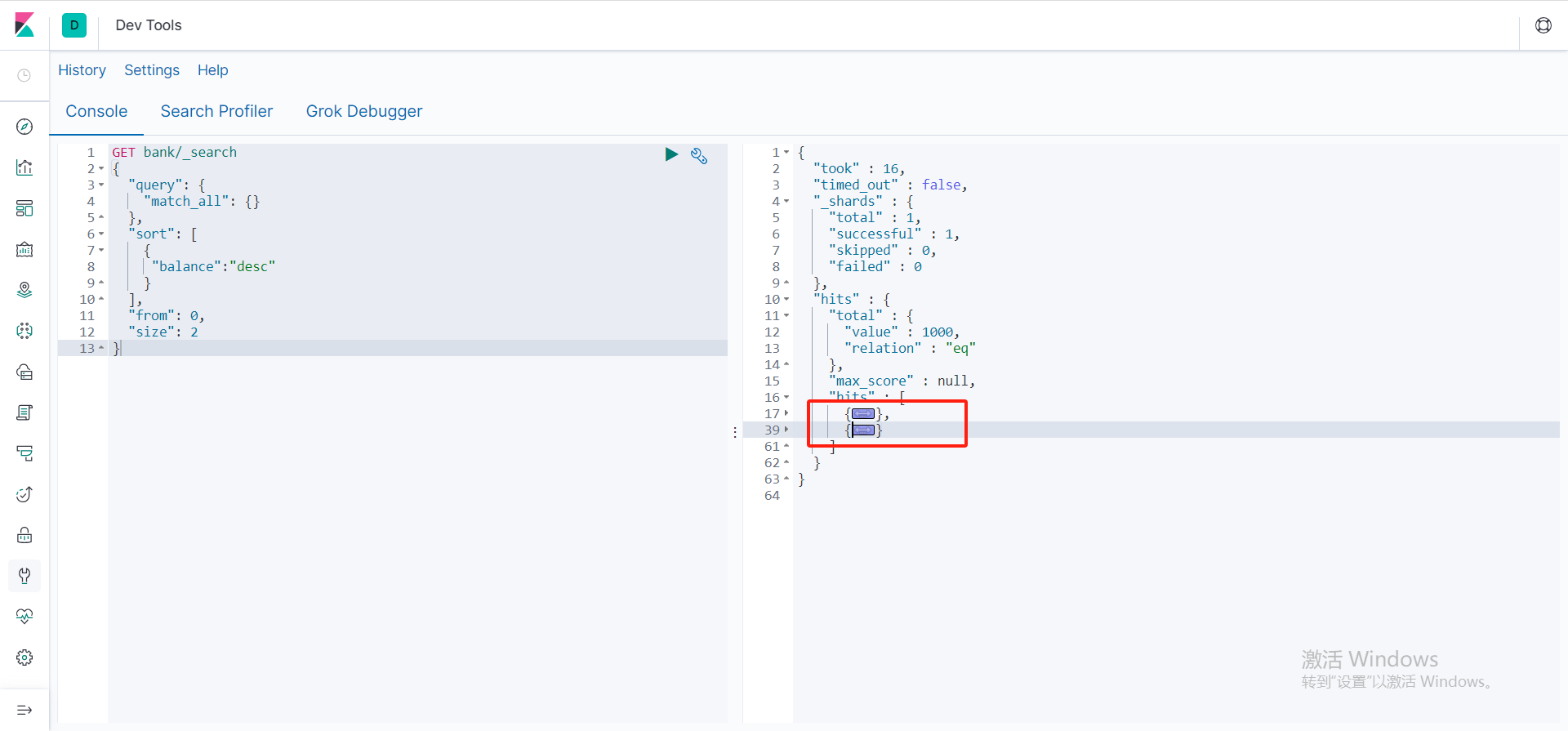
分页查询
GET bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"balance":"desc"
}
],
"from": 0,
"size": 2
}
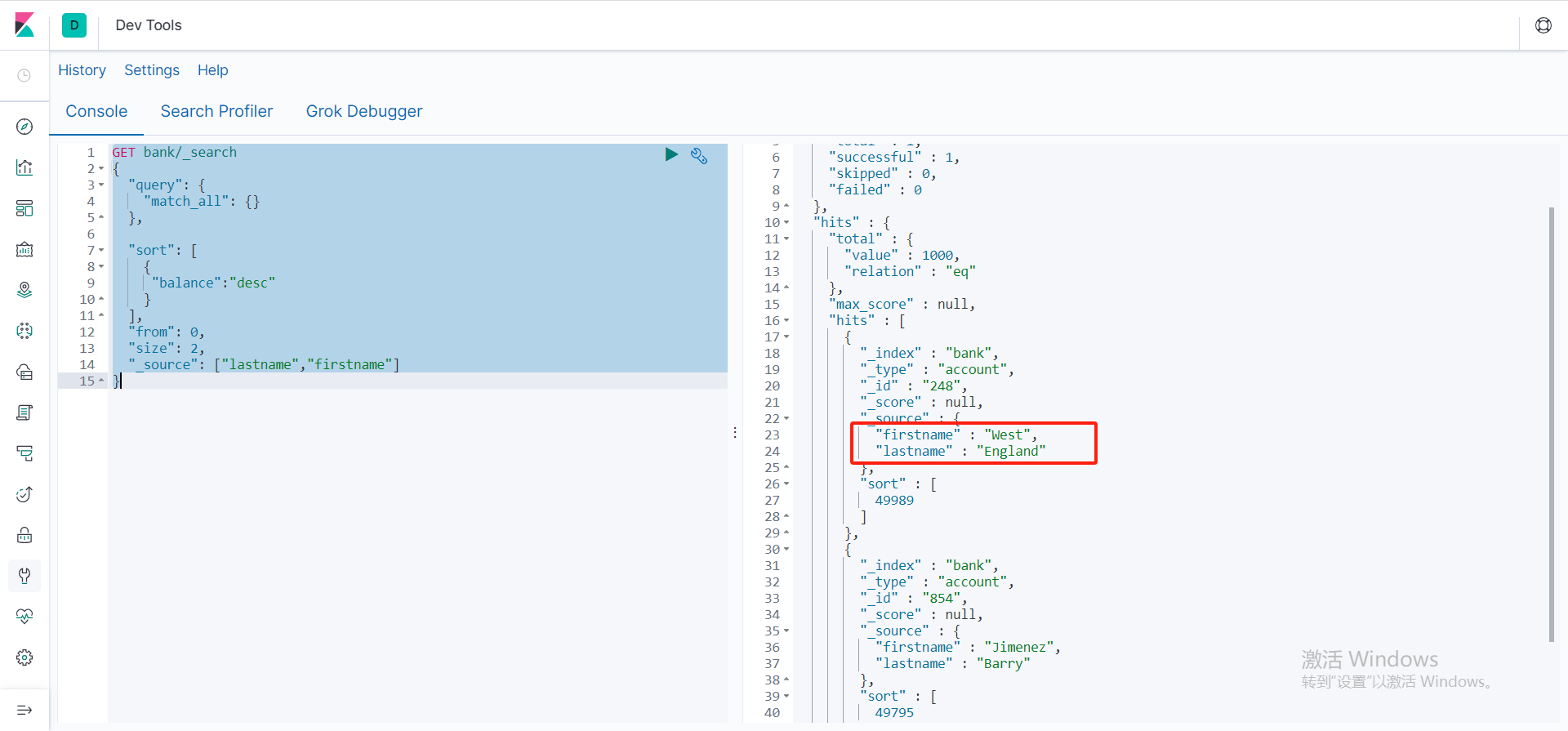
只返回指定字段
使用_source来设置返回指定字段,类似于mysql中的select xx,xx from xxx
GET bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"balance":"desc"
}
],
"from": 0,
"size": 2,
"_source": ["lastname","firstname"]
}
全文索引查询
match检索,可以根据你的字段和值进行全文检索
可以根据检索得分,由高到低进行排序的。底层采用倒排索引,以及分词进行匹配
GET bank/_search
{
"query": {
"match": {
"address": "Lane"
}
}
}
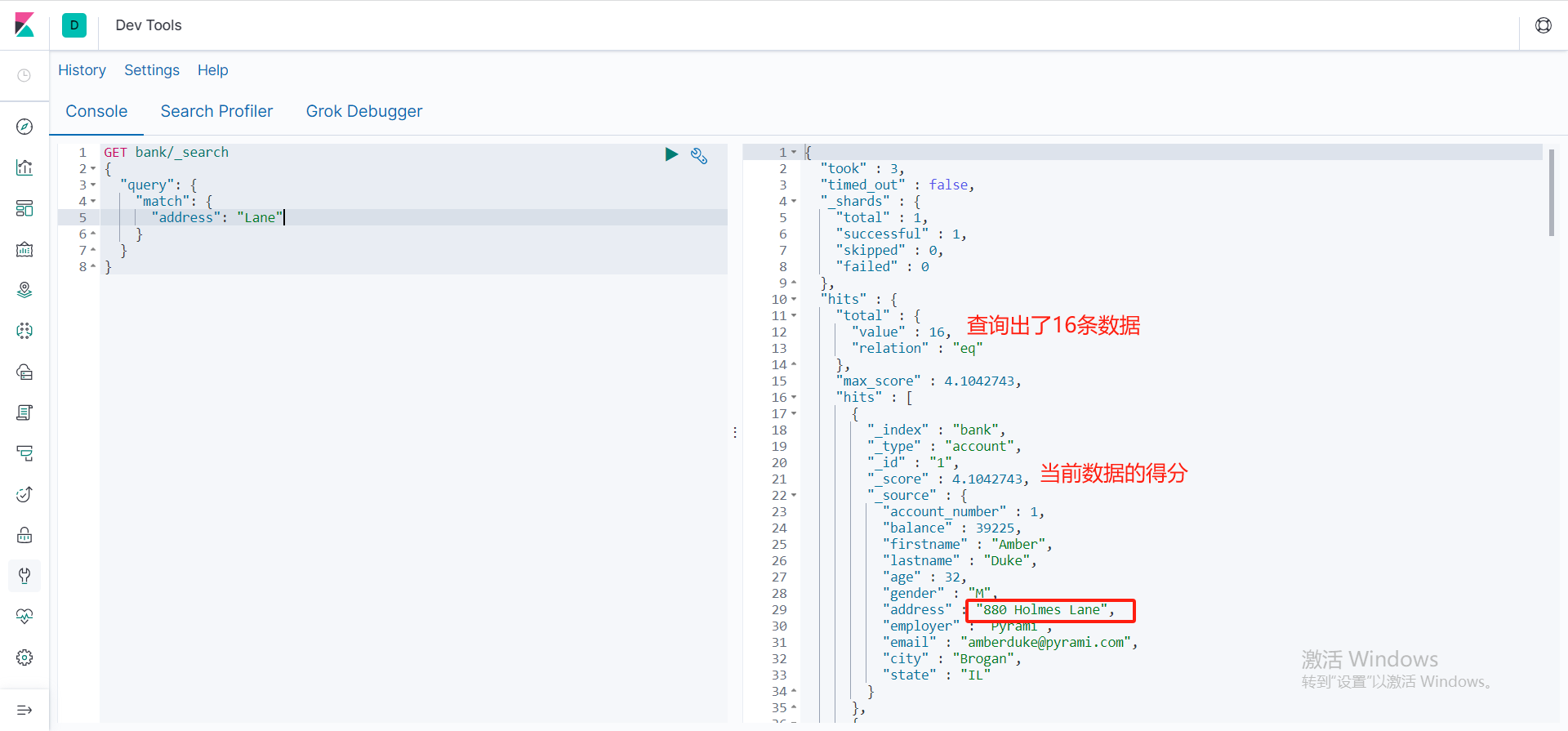
全文完全匹配
在match匹配情况下,字段.keyword就可以查询出精准匹配信息
GET bank/_search
{
"query": {
"match": {
"address.keyword": "789 Madison Street"
}
}
}
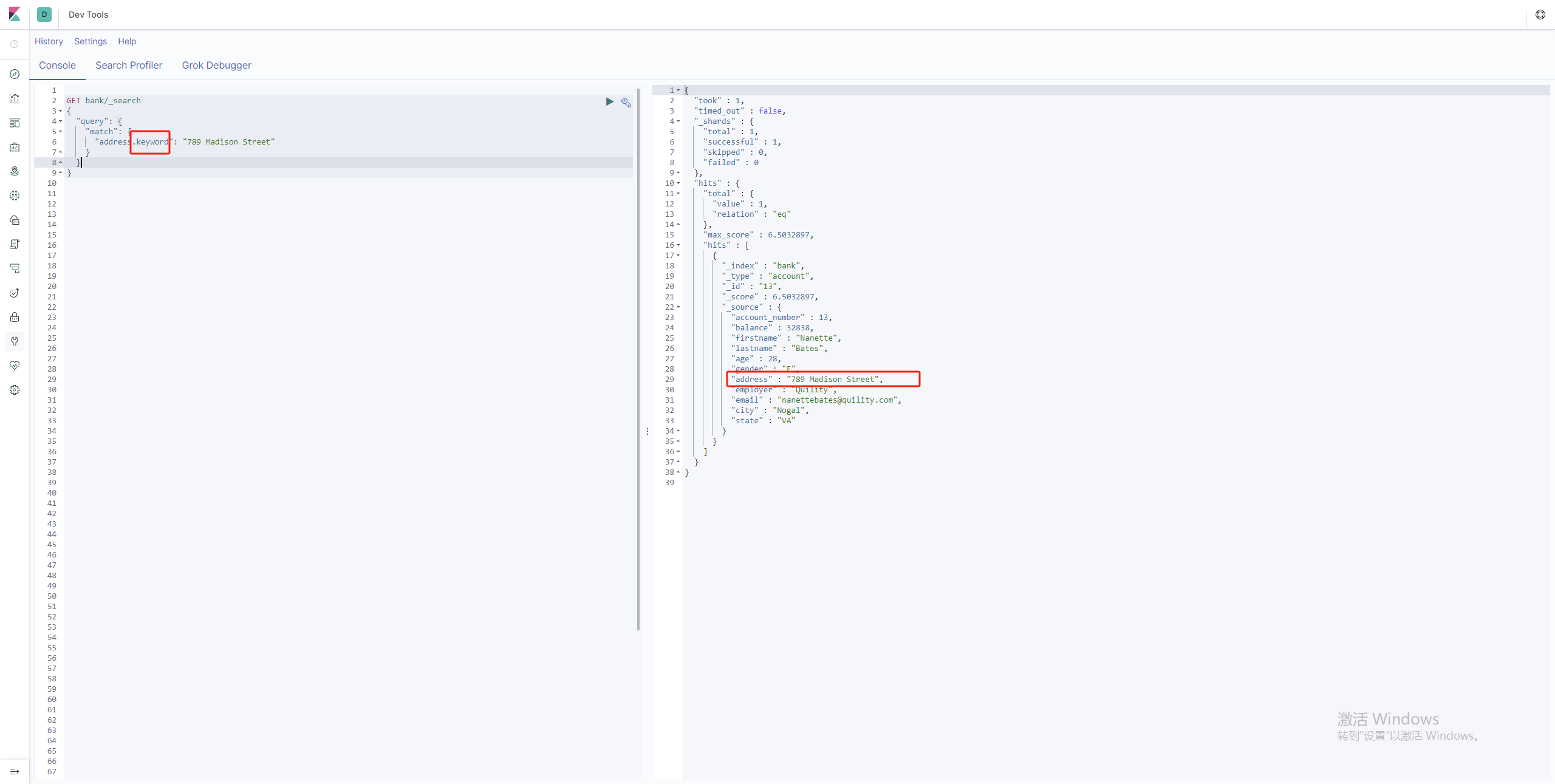
短语匹配
包含完整的短语,而不是match进行分词匹配
GET bank/_search
{
"query": {
"match_phrase": {
"address": "Holmes"
}
}
}
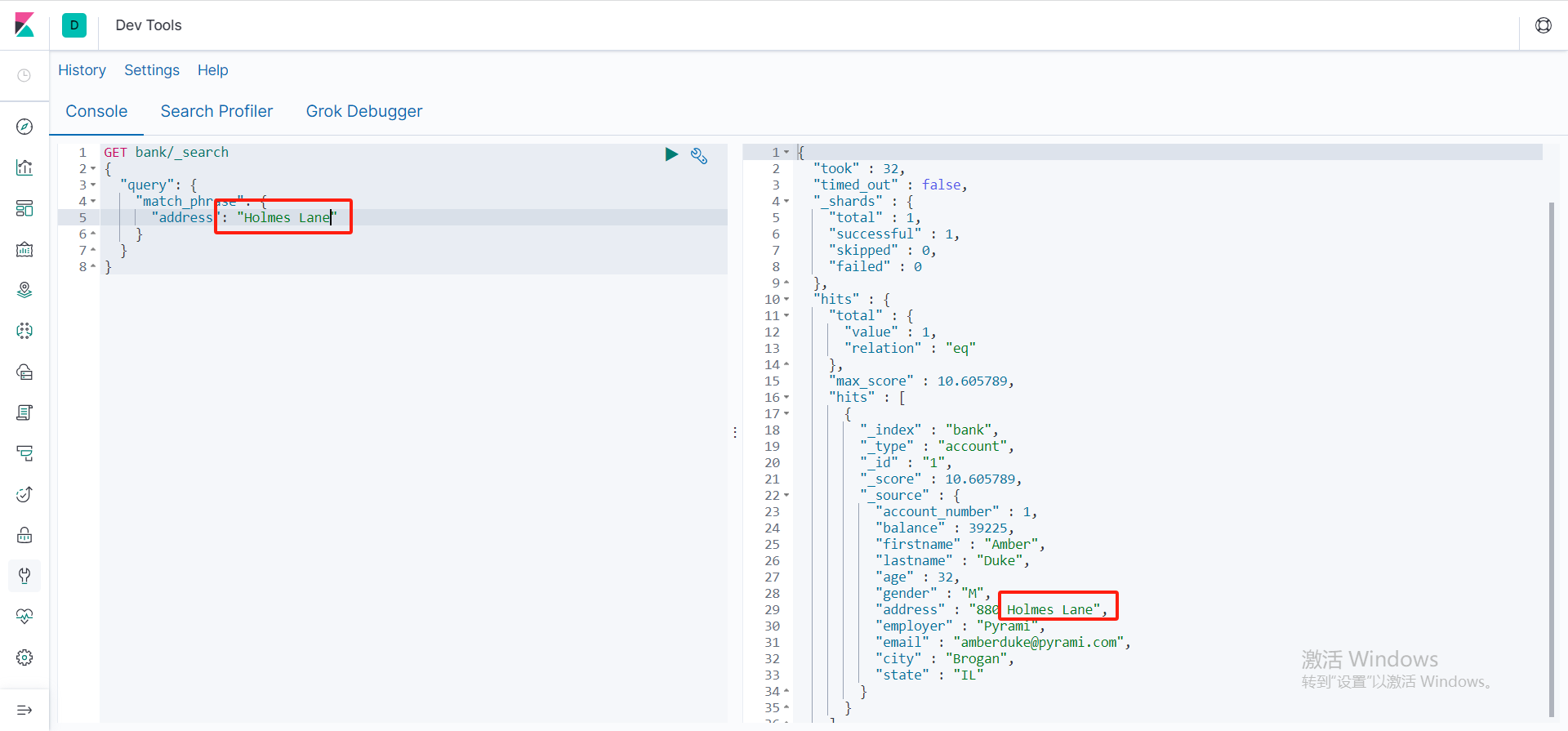
多字段匹配检索
multi_match是多字段匹配检索,query是条件也支持分词检索,fields是一个数组,可以多字段进行匹配检索
GET bank/_search
{
"query": {
"multi_match": {
"query": "mill Movico",
"fields": ["address","city"]
}
}
}
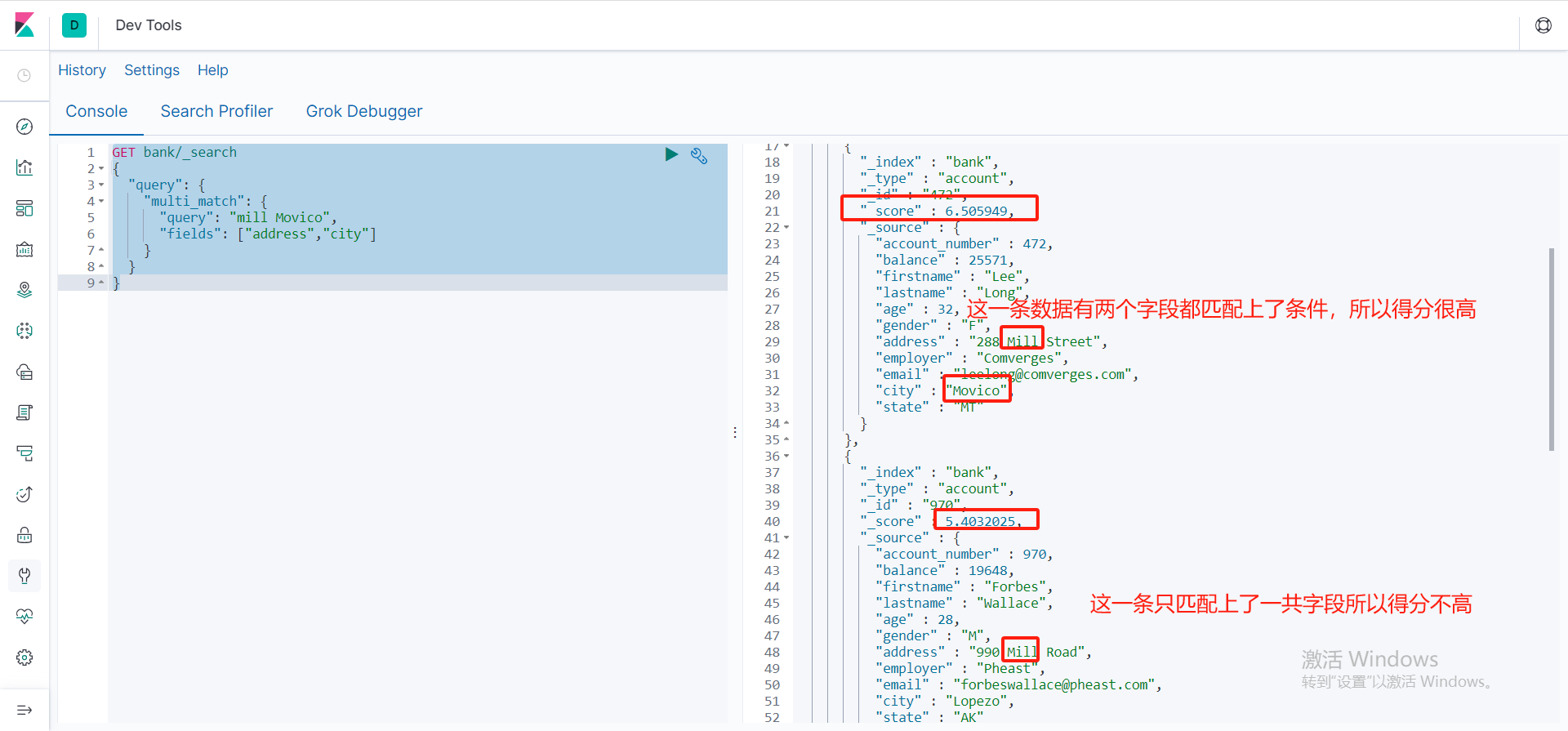
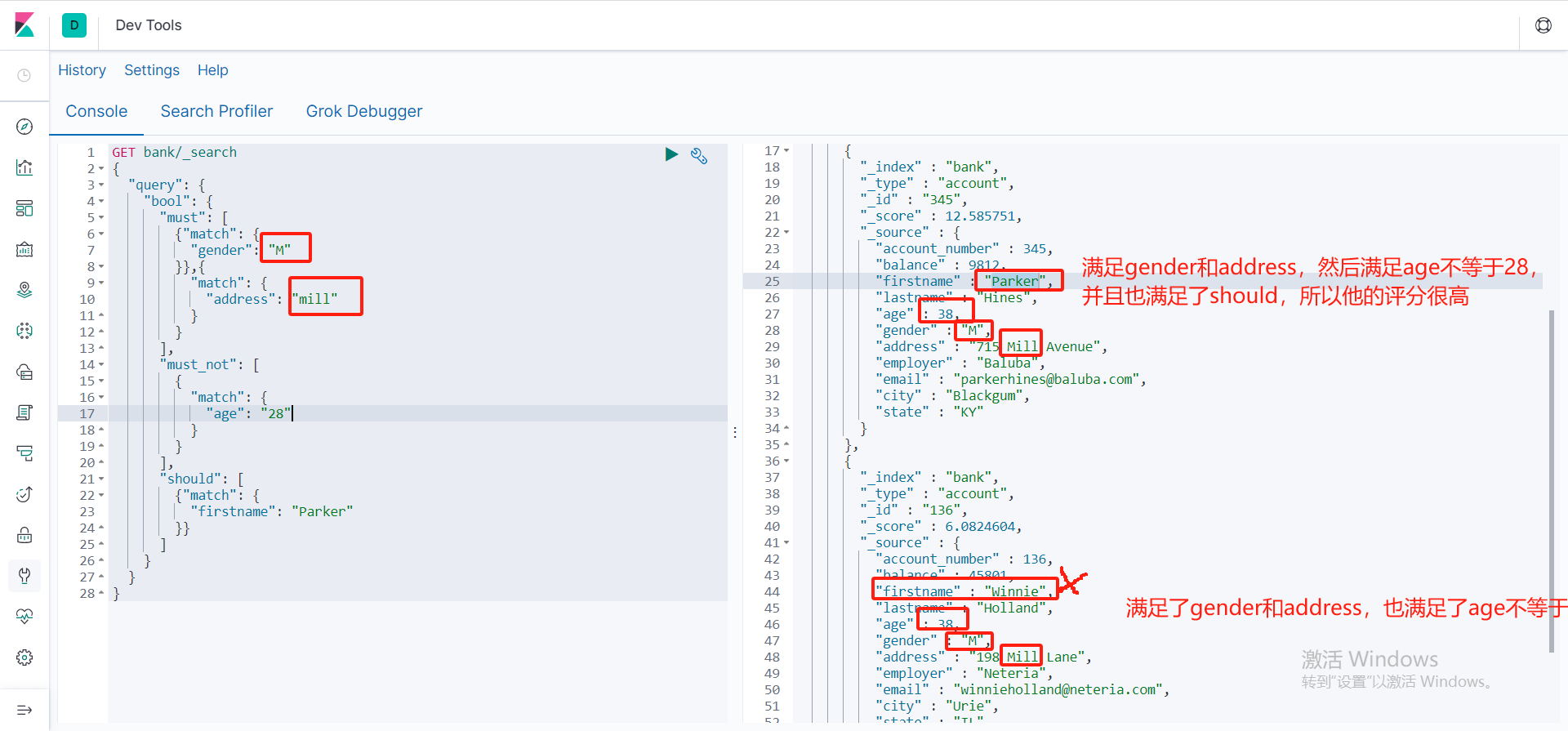
bool复合查询
复合查询表示:多个条件满足,
- must表示必须满足匹配条件
- must_not 表示必须不满足条件not_no
- should表示可以满足也可以不满足,如果满足那么我就给这条数据高评分
GET bank/_search
{
"query": {
"bool": {
"must": [
{"match": {
"gender": "M"
}},{
"match": {
"address": "mill"
}
}
],
"must_not": [
{
"match": {
"age": "28"
}
}
],
"should": [
{"match": {
"firstname": "Parker"
}}
]
}
}
}
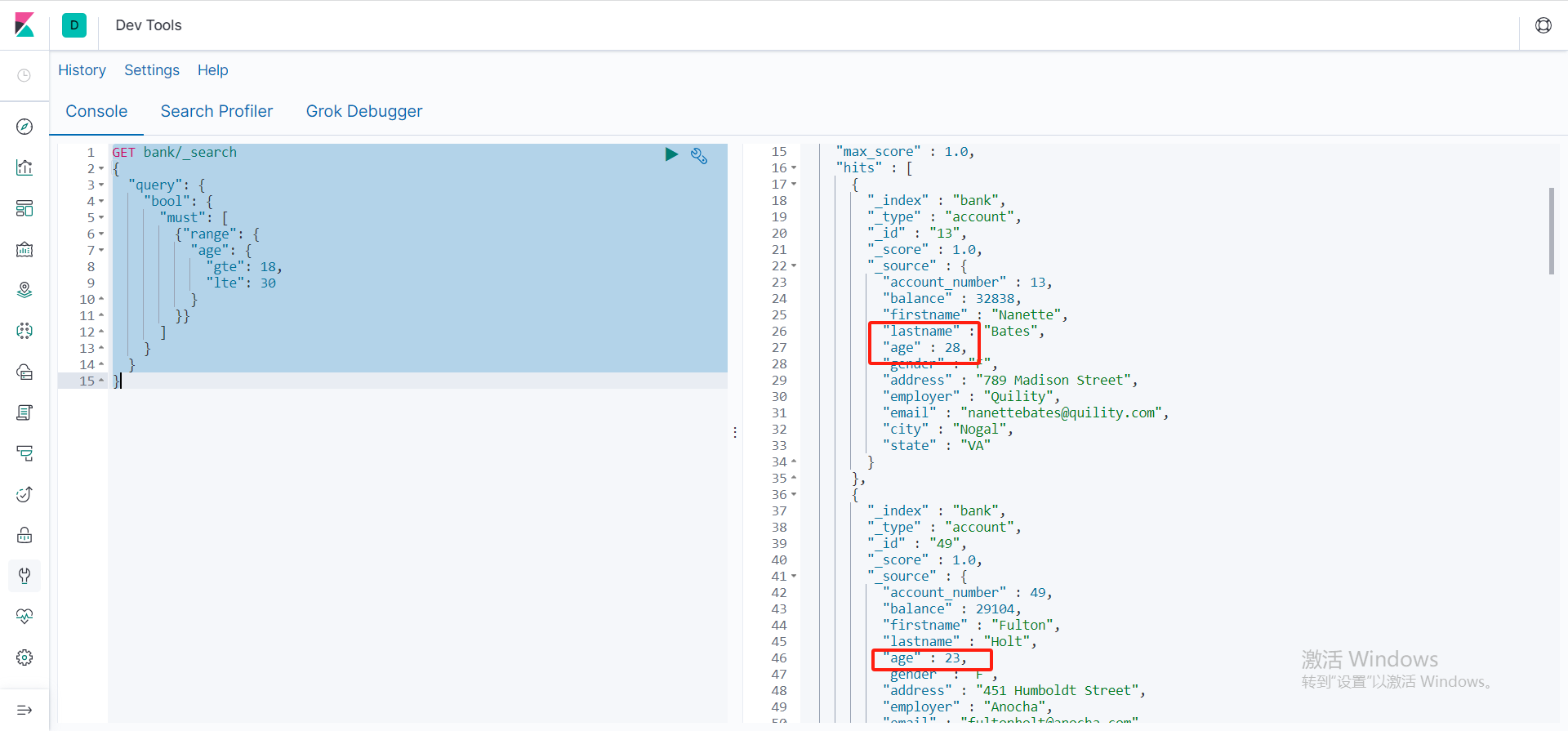
区间查询
使用range可以进行区间查询,get:最小,lte:最大
GET bank/_search
{
"query": {
"bool": {
"must": [
{"range": {
"age": {
"gte": 18,
"lte": 30
}
}}
]
}
}
}
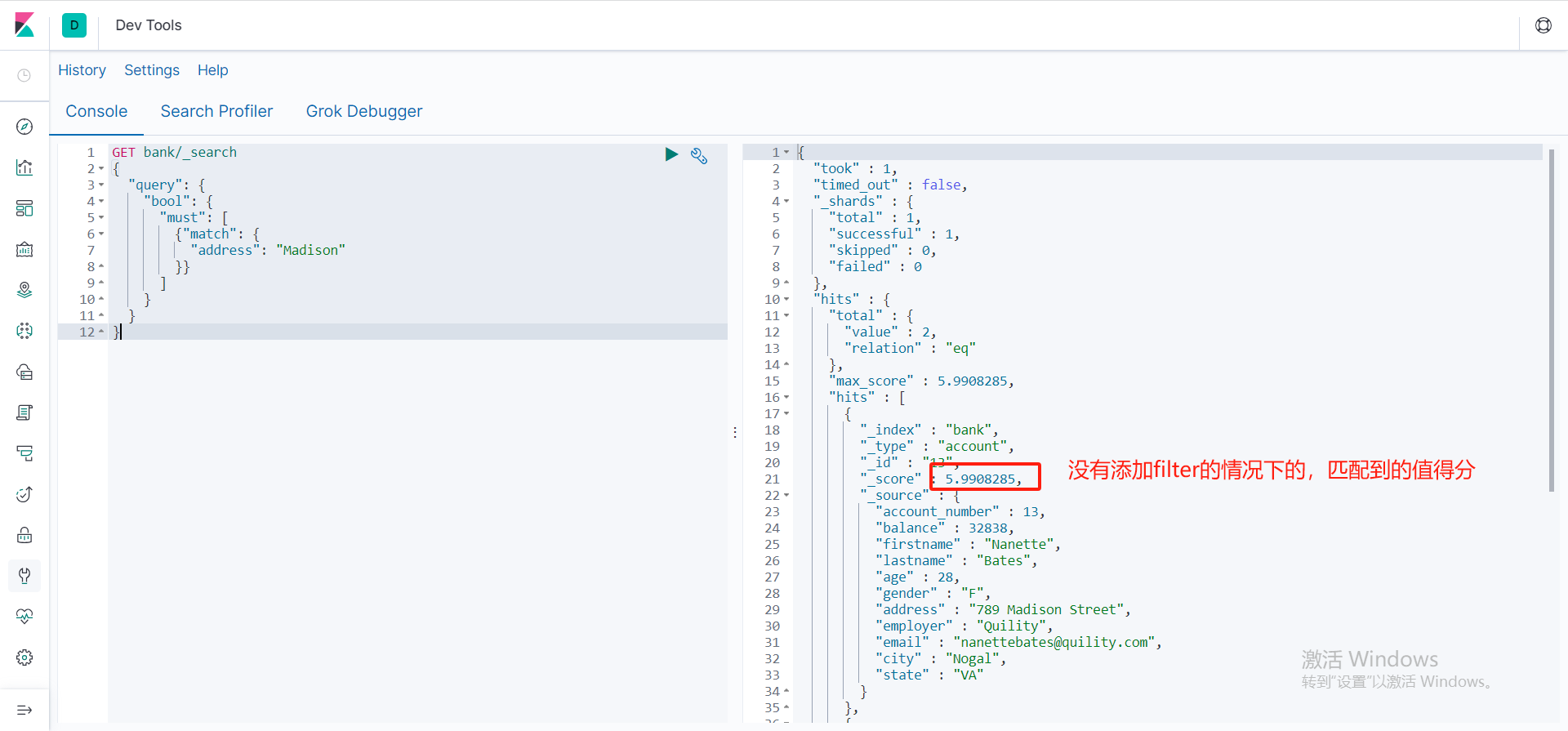
Filter
Filter:最大的特点就是匹配上的数据不参加相关性得分,must以及must_not和should在满足检索条件的时候都会给相对于的相关性得分,而filter在检索的时候就算匹配上检索条件了,也不会给检索的值加相关性得分。
- 没有添加filter只使用match来匹配,匹配成功的相关性得分
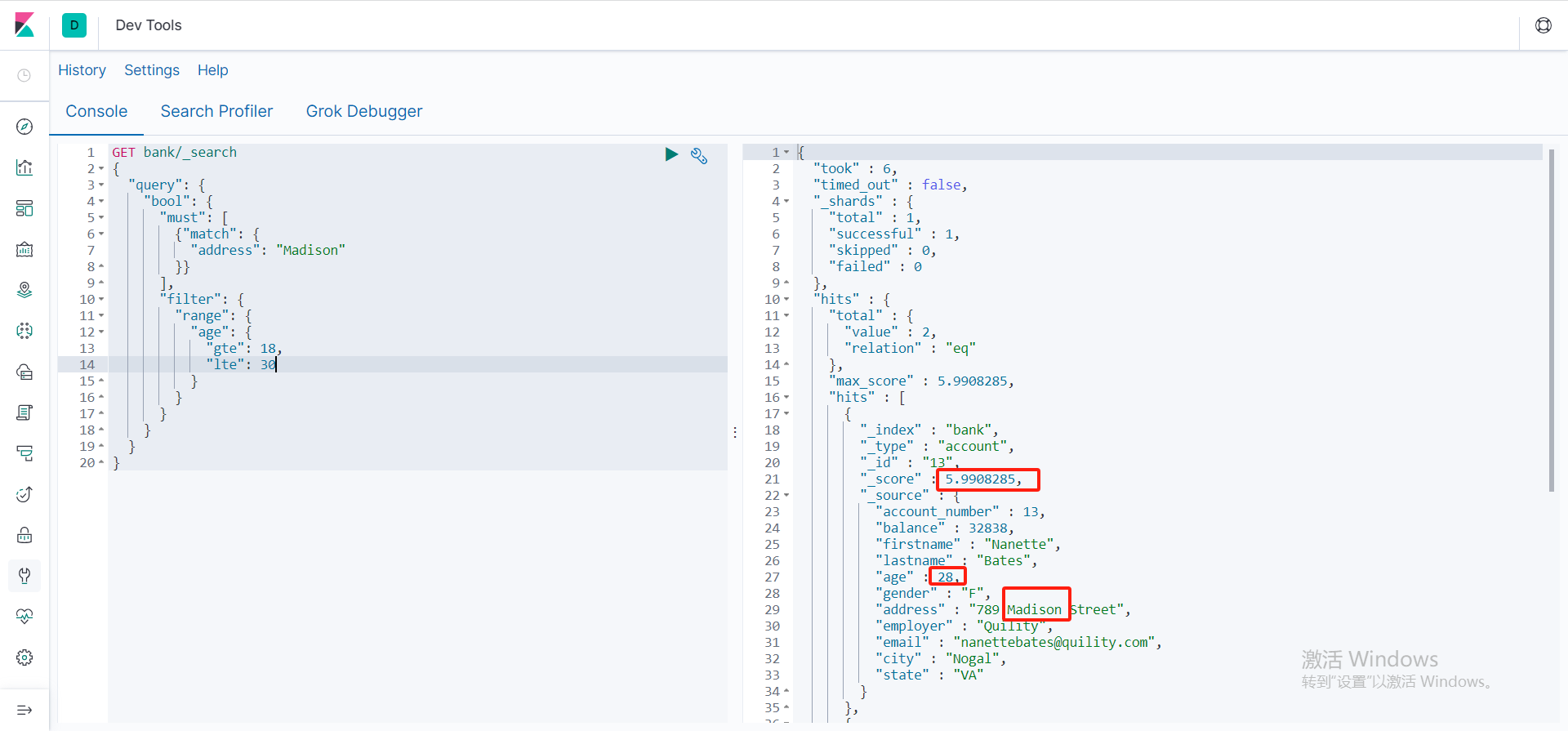
- 添加filter后匹配上的值,也不会累加相关性得分,还是以前的得分
term非文本查询
trem 适合查询非字符串字段,比如整数小数型,因为他不具备分词功能。
GET bank/_search
{
"query": {
"term": {
"age": "28"
}
}
}
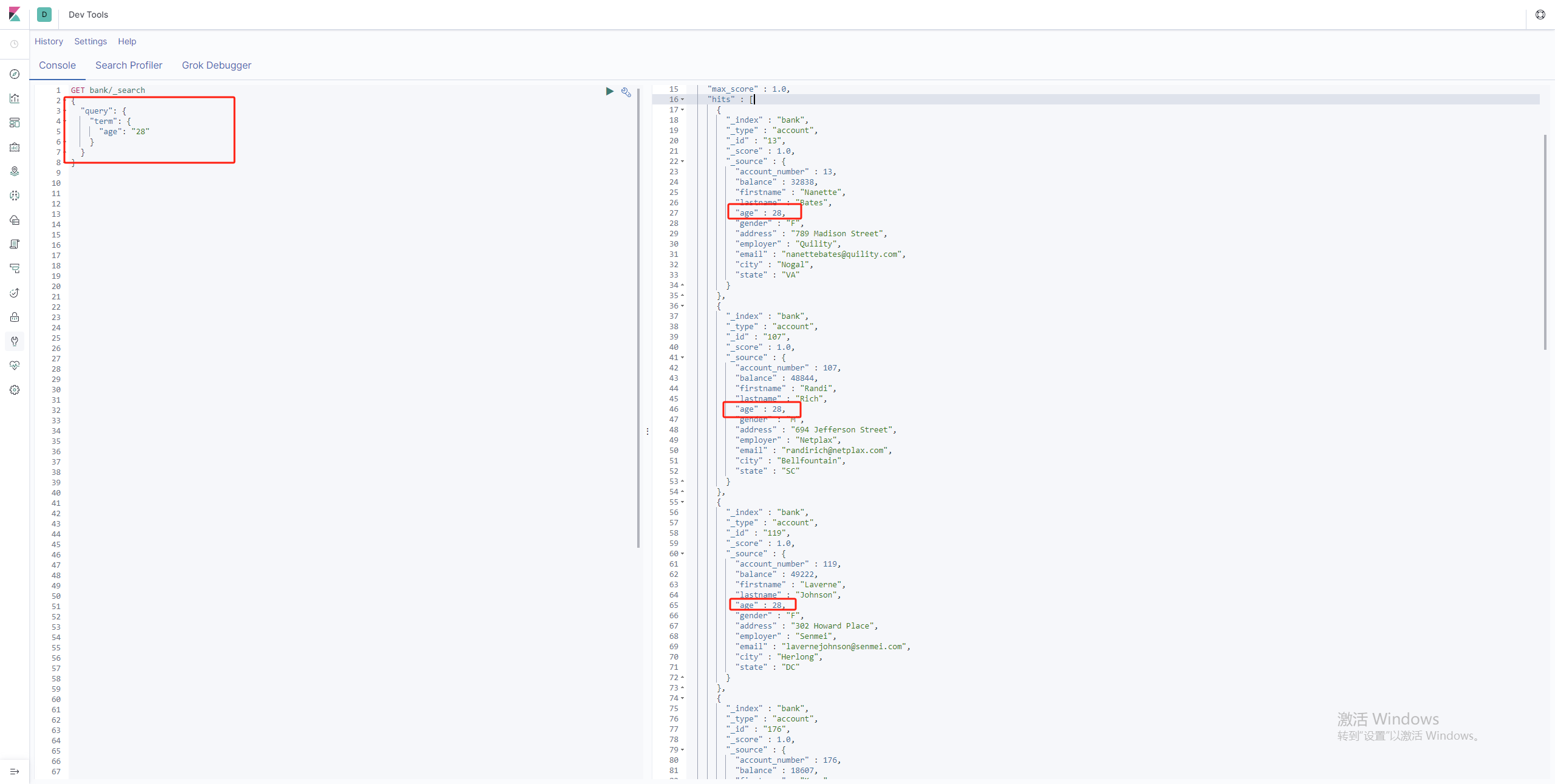
数组对象查询场景
- 我们创建一共数组对象数据
PUT my_index/_doc/1
{
"group":"fans",
"user":[{
"fi":"san",
"ls":"zhang"
},
{
"fi":"wu",
"ls":"wang"
}
]
}
- 我们查询一下fi=san,ls=wang,按道理都没有条件满足的,应该查不出来才对
GET my_index/_search
{
"query": {
"bool": {
"must": [
{"match": {
"user.fi": "san"
}},
{"match": {
"user.ls": "wang"
}}
]
}
}
}
- 结果
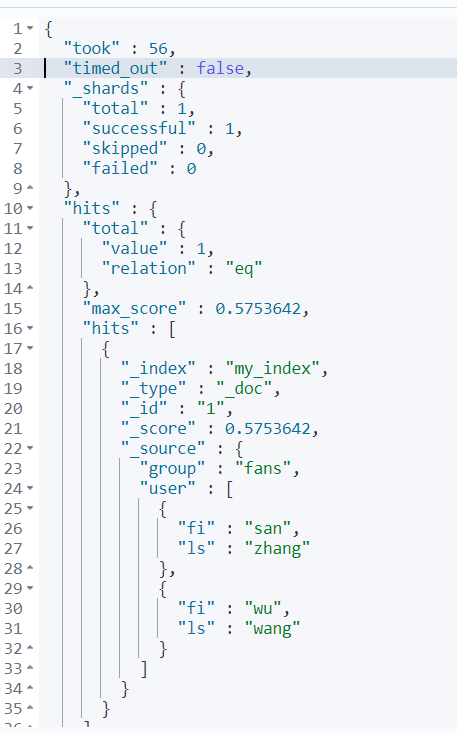
- 应为ES做了扁平化处理
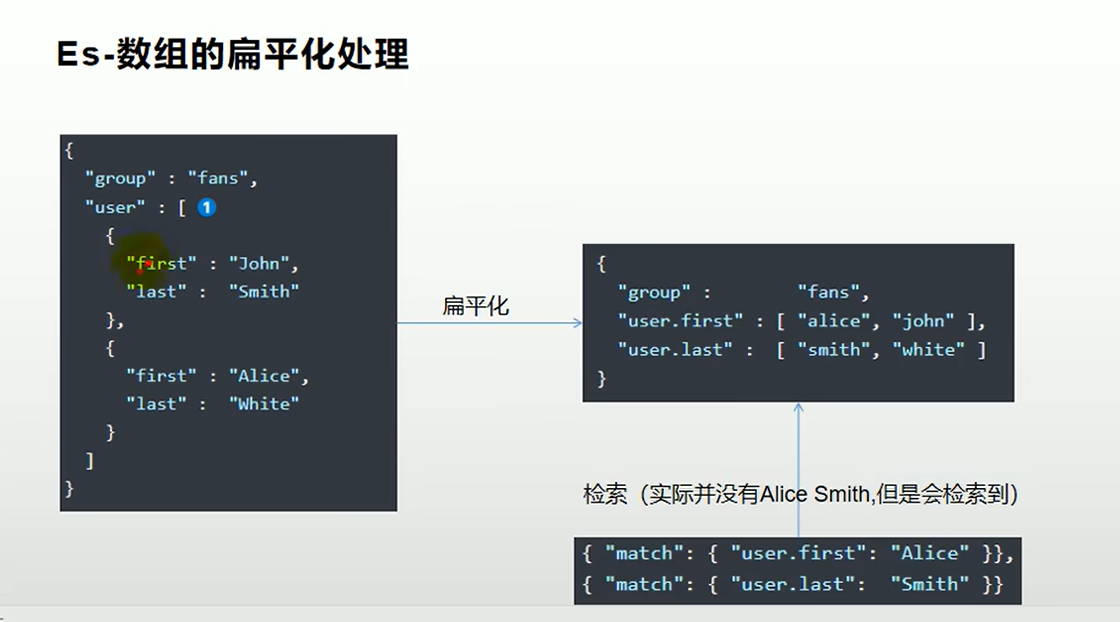
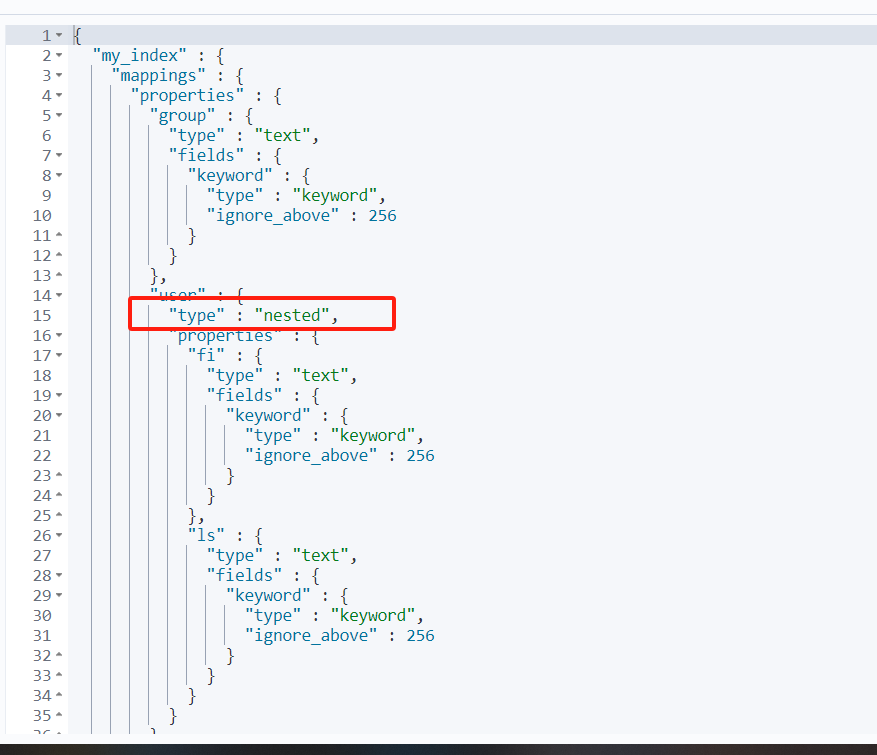
- 先将索引删掉,然后创建一个索引,并且设置user.type=nested
DELETE my_index
PUT my_index
{
"mappings": {
"properties": {
"user":{
"type": "nested"
}
}
}
}
PUT my_index/_doc/1
{
"group":"fans",
"user":[{
"fi":"san",
"ls":"zhang"
},
{
"fi":"wu",
"ls":"wang"
}
]
}
- 这个时候就查不出来了
GET my_index/_search
{
"query": {
"bool": {
"must": [
{"match": {
"user.fi": "san"
}},
{"match": {
"user.ls": "zhang"
}}
]
}
}
}
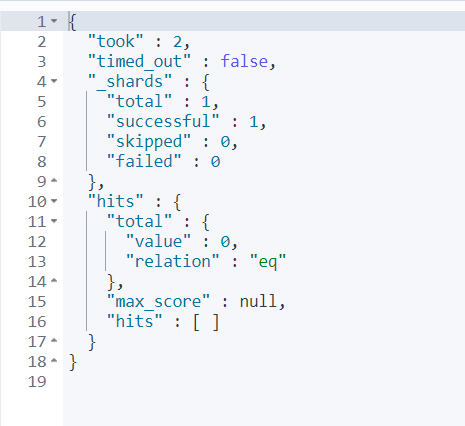
聚合分析
(aggregations)聚合分析类似于mysql中的GROUPBY 和sql的聚合函数(age,count…)
| avg | 平均 |
|---|---|
| terms | 分组 |
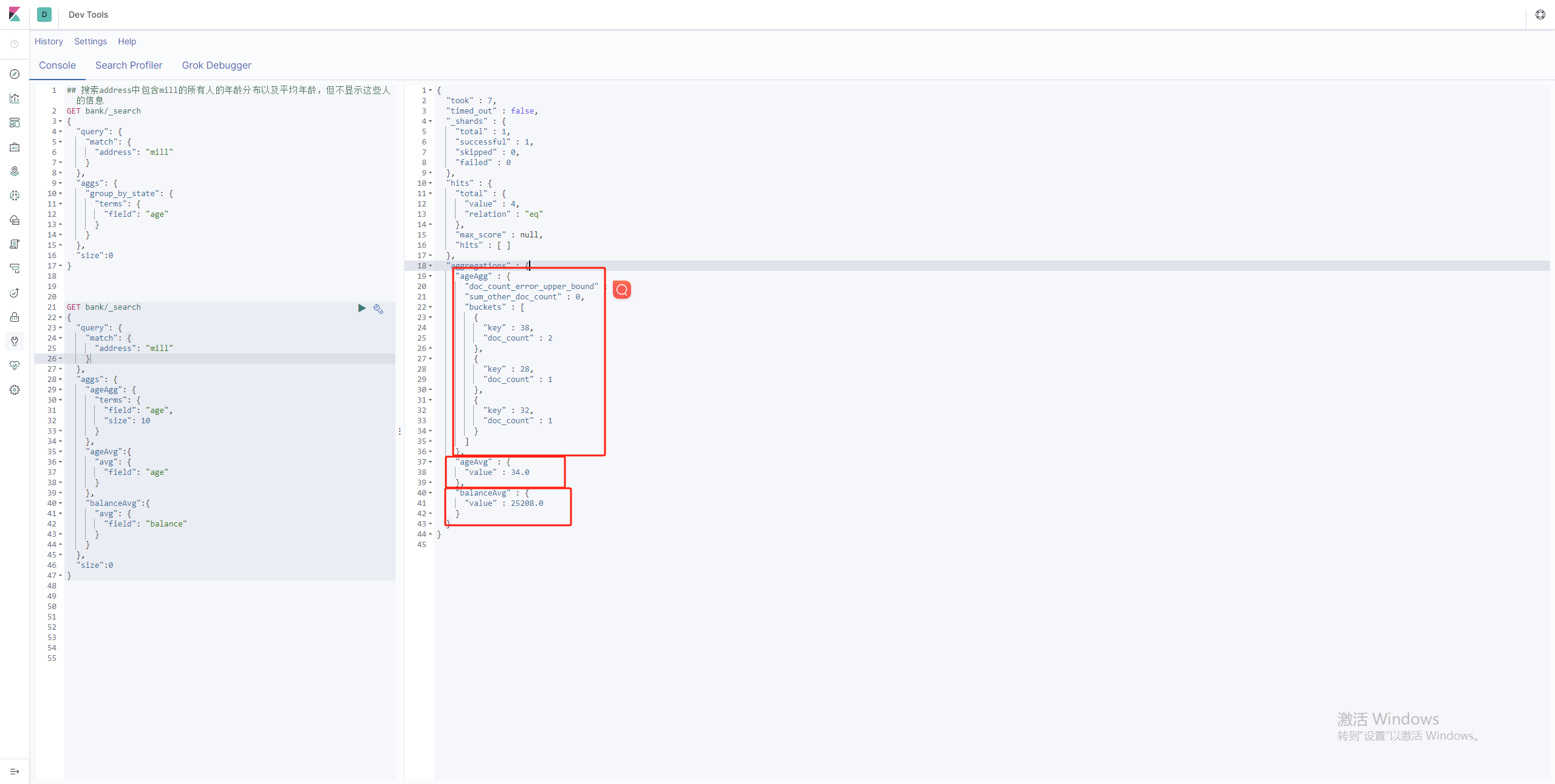
- 查询出地址中含有mill 的人,并且统计出年龄分布,平均年龄,平均薪资。
GET bank/_search
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 10
}
},
"ageAvg":{
"avg": {
"field": "age"
}
},
"balanceAvg":{
"avg": {
"field": "balance"
}
}
},
"size":0
}
小练习
- 搜索address中包含mill的所有人的年龄分布以及平均年龄,但不显示这些人的信息
GET bank/_search
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": {
"group_by_state": {
"terms": {
"field": "age"
}
}
},
"size":0
}
- 按照年龄聚合,并且请求这些年龄的这些人的平均薪资
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 1000
},
"aggs": {
"balance": {
"avg": {
"field": "balance"
}
}
}
}
},
"size": 1
}
- 查询所有的年龄分布,并且这些年龄段中M的平均薪资和F的平均薪资以及这个年龄段的总体平均薪资
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 1000
},
"aggs": {
"genderAgg": {
"terms": {
"field": "gender.keyword",
"size": 10
},
"aggs": {
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
},
"ageGenderAgg":{
"avg": {
"field": "balance"
}
}
}
}
}
}
Mapping映射
使用 /索引/_mapping 可以查询当前索引下的索引字段类型
GET /bank/_mapping
- 因为我们在创建值得适合传递得字段没有给他指定类型, 那么ES就自动识别出类型给我们设置进去
- 如果ES识别出来得类型跟我们预期不符合,我们就可以自己设置某个字段得类型。
字段名称:{“type”:“类型”}
integer:整数,text:可全文检索得文本,keyword:精确检索
PUT /user_index
{
"mappings": {
"properties": {
"age":{"type": "integer"},
"name":{"type": "text"},
"email":{"type": "keyword"}
}
}
}
给以及创建过得字段得索引新增一共字段
- 给user_index新增一共uid字段
- 设置类型为long
- 设置index为false表示不参与索引,这样检索得时候这个字段就不会呗检索到
PUT /user_index/_mapping
{
"properties":{
"uid":{
"type":"long",
"index":false
}
}
}
注意:我们不能更新已存在字段得映射类型
解决方法:
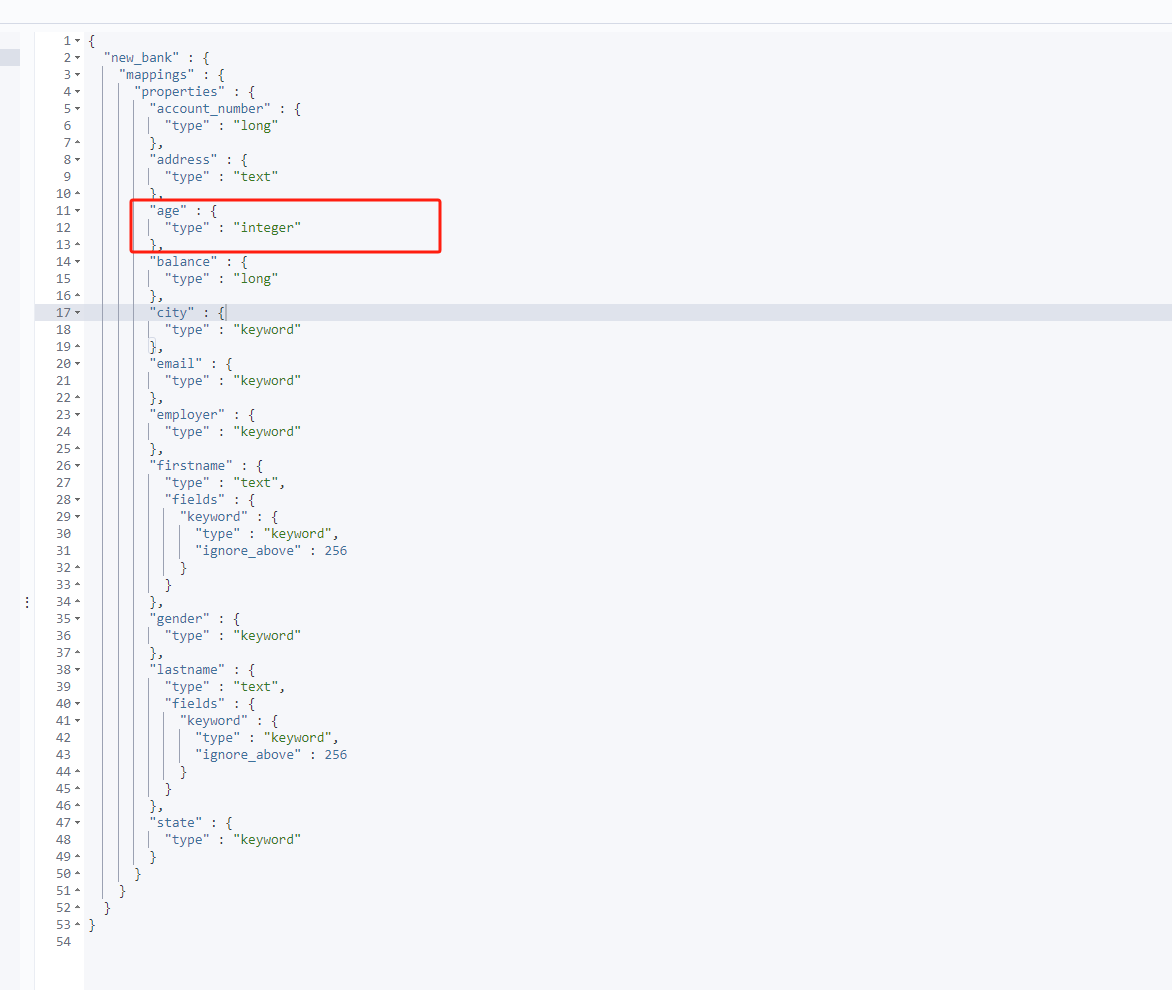
- 想要修改映射,唯一解决得方法,就是创建一个新的索引,吧数据迁移到新的索引上
- 创建一个新得索引,必须要和老得索引字段名称一样
PUT /new_bank
{
"mappings": {
"properties": {
"account_number" : {
"type" : "long"
},
"address" : {
"type" : "text"
},
"age" : {
"type" : "integer"
},
"balance" : {
"type" : "long"
},
"city" : {
"type" : "keyword"
},
"email" : {
"type" : "keyword"
},
"employer" : {
"type" : "keyword"
},
"firstname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"gender" : {
"type" : "keyword"
},
"lastname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"state" : {
"type" : "keyword"
}
}
}
}
- 执行_reindex 迁移,source:老索引得数据,dest:新索引得数据
- 如果老索引有类型的话要带上type,就是GET /bank/account/1,这里得索引名/类型名/id主键
POST _reindex
{
"source": {
"index": "bank",
"type": "account"
},
"dest": {
"index": "new_bank"
}
}
- 这样就吧一千条数据迁移到新的索引
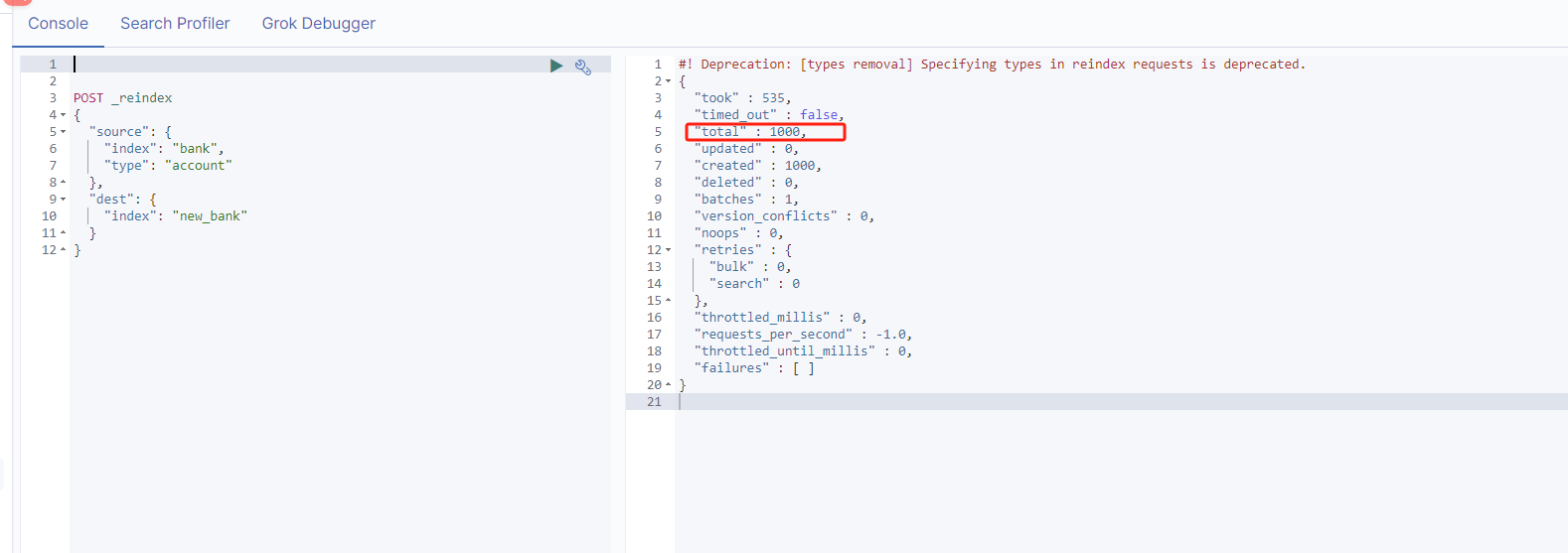
- GET new_bank/_mapping
- 全部都是我们新创建得索引类型
分词
使用自带的分词器
使用ES自带得分词器索引/_analyze 可以将我们得内容,进行分词,
analyzer:那种类型的分词
text:需要分词的内容
POST _analyze
{
"analyzer": "standard",
"text": "Accelerate high-quality software development. Our AI-powered platform drives innovation with tools that boost developer velocity."
}
- 缺点:仅支持英文分词,不支持中文分词
- 解决方法:安装ik分词器,实现中文分词
ik分词器
- 安装ik分词器
ik分词器GitHub下载地址https://github.com/medcl/elasticsearch-analysis-ik
注意下载版本要和ES版本一样,这个是ES版本。7.4.2就下载ik的7.4.2版本zip格式的。
- 解压到ES的plugins目录下,这里我重命名为ik了。
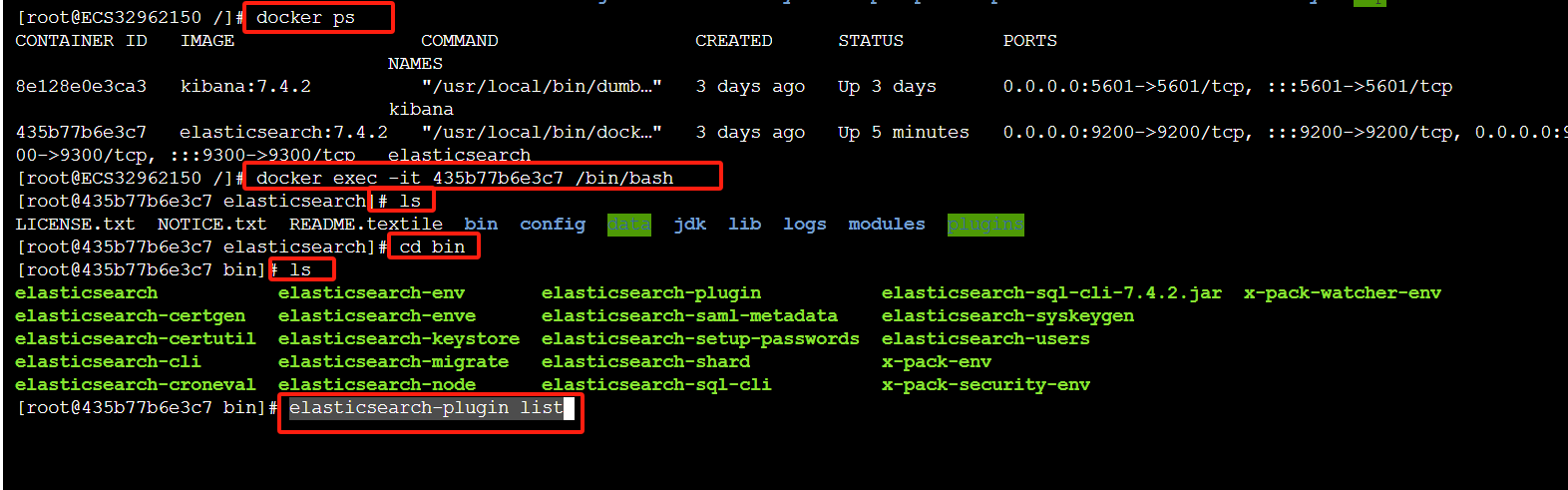
- 进入ES的bin目录,如果是docker安装的情况下先进入到容器内部,然后进入bin
- 执行命令 elasticsearch-plugin list
- 重启ES或者docker
- 测试一下,这里post路径就是 索引/_analyze即可
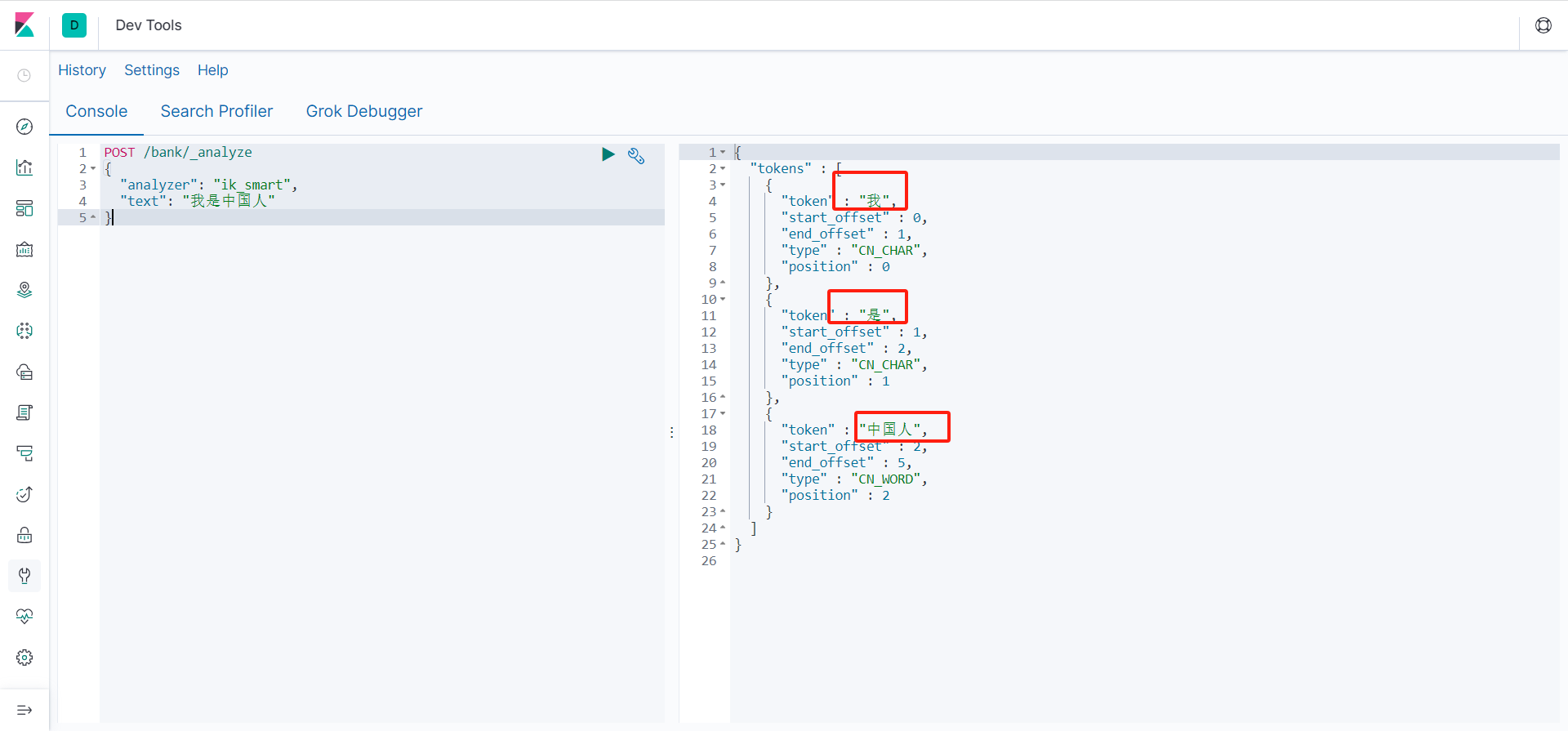
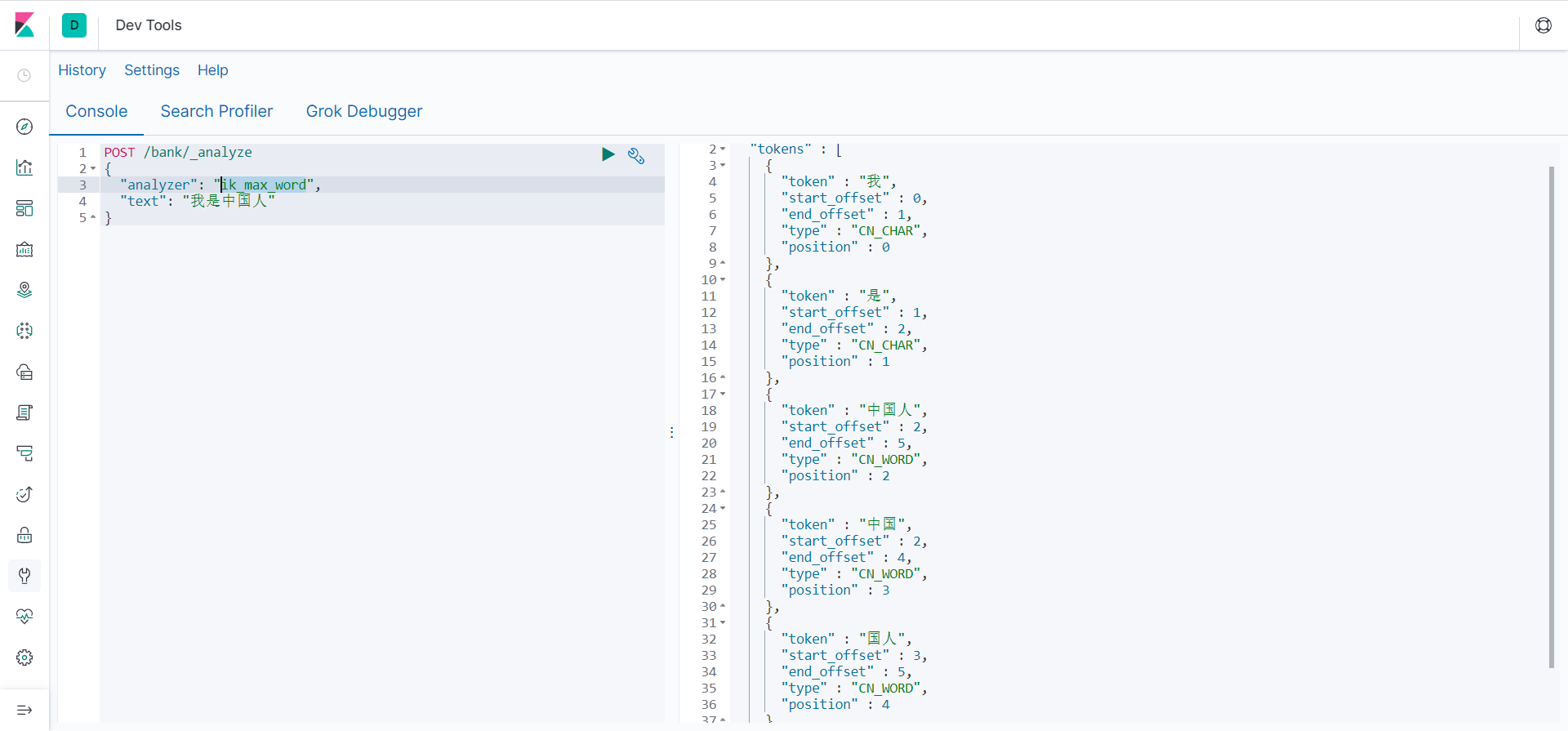
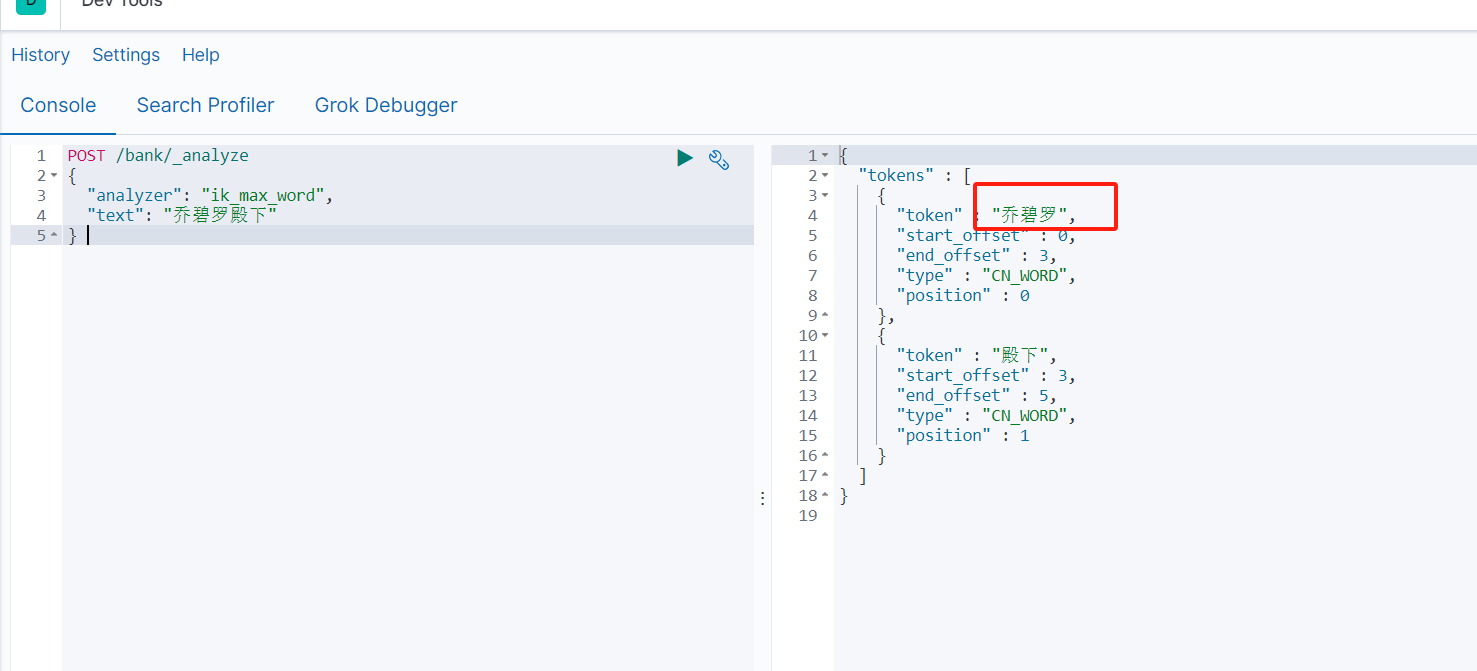
- IK分词器有两种,一种是子智能分词ik_smart,还有一种是ik_max_word会将文本做最细颗粒度的拆分
POST /bank/_analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}
POST /bank/_analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
自定义词库
- 如果我们使用ik分词器,会发现没有达到我们想要的分词效果,我想要自定义分词
- 打开elasticsearch安装目录下的/plugins/ik/config
- 编写IKAnalyzer.cfg.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://xx.xx.com/fenci.txt</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://xxx.xxx.com/notfenci.txt</entry>
</properties>

- 在分词文件里面,一行是一个词
- 测试
整合SpringBoot
- 引入依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.2</version>
</dependency>
<properties>
<java.version>1.8</java.version>
<spring-cloud.version>Greenwich.SR3</spring-cloud.version>
<elasticsearch.version>7.4.2</elasticsearch.version>
</properties>
- 编写配置类
package com.atguigu.gulimall.search.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/*
1.导入依赖
2.编写配置
*/
@Configuration
public class ElasticSeartchConfig {
@Bean
public RestHighLevelClient esRestClient() {
RestHighLevelClient http = new RestHighLevelClient
(RestClient.builder(new HttpHost("121.62.21.74", 9200, "http")));
return http;
}
}
新增
IndexRequest indexRequest = new IndexRequest("users");
User user = new User();
user.setName("张三");
user.setAge(18);
user.setGender("男");
indexRequest.source(user,XContentType.JSON);
IndexResponse index = esRestClient.index(indexRequest, RequestOptions.DEFAULT);
return index;
查询
简单查询
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("bank");//定义索引
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("age","30"));
searchSourceBuilder.size(20);
searchSourceBuilder.from(1);
searchRequest.source(searchSourceBuilder);
SearchResponse search = esRestClient.search(searchRequest, RequestOptions.DEFAULT);
return search;
GET bank/_search
{
"query": {
"match": {
"age": "30"
}
}
}
集合查询
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("bank");//定义索引
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("age","30"));
TermsAggregationBuilder aggAgg = AggregationBuilders.terms("ageAgg").field("age");
AvgAggregationBuilder balance = AggregationBuilders.avg("balanceAgg").field("balance");
searchSourceBuilder.aggregation(aggAgg).aggregation(balance);
searchSourceBuilder.size(20);
searchSourceBuilder.from(1);
searchRequest.source(searchSourceBuilder);
SearchResponse search = esRestClient.search(searchRequest, RequestOptions.DEFAULT);
return search;
GET bank/_search
{
"query": {
"match": {
"age": "30"
}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age"
}
},
"balanceAgg":{
"avg": {
"field": "balance"
}
}
}
}














 420
420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









