







又到期末考试了,需要做问卷星来复习了。
但是网络教学平台上的题太多了,没办法写了个脚本来提取。
通过此脚本生成的excel,可以直接导入问卷星生成问卷。
1. 使用步骤
- 登录网络教学平台
- F12 打开开发者工具->Application->cookie
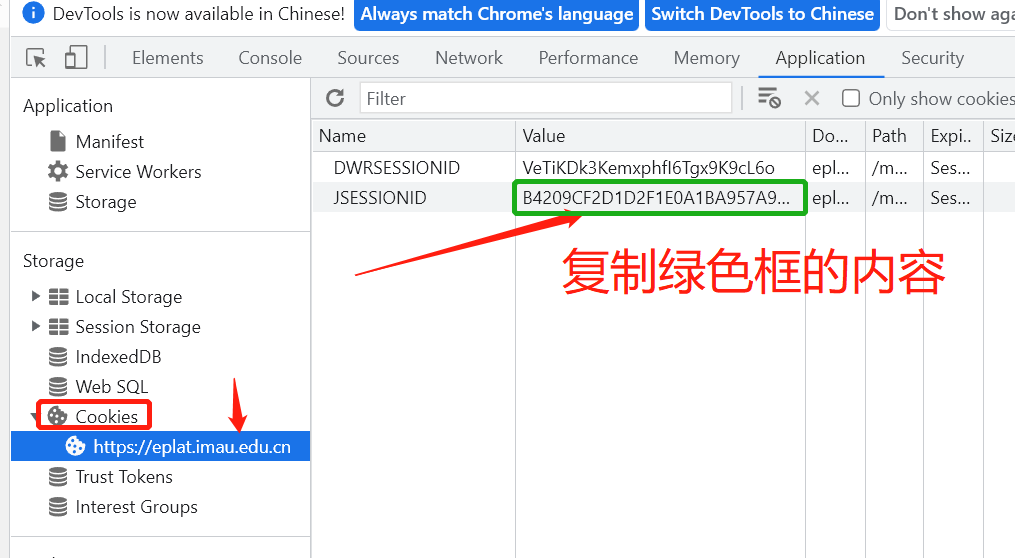
- 找到 JSESSIONID 这个字段,把他的值复制下来。然后把代码中的JSEESIONID替换成你的
s = requests.get(url, headers={
'cookie': 'JSESSIONID=2820553AF02867CBE9DB35273D032158'# 这里=后面的替换成你的sessionid
})
- 安装 pandas, requests, BeautifulSoup依赖
pip install beautifulsoup4 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
- 复制你要爬取的测试结果页面(注意是结果页面!!就是已经答完,可以查看答案的那种结果页面)的URL网址,把测试名也带上去
fetch_all([
('https://eplat.imau.edu.cn/meol/test/stuQtestResult.do?testId=84246354', '第二章测试题'),
('https://eplat.imau.edu.cn/meol/test/stuQtestResult.do?testId=85256551', '第三章测试题'),
('https://eplat.imau.edu.cn/meol/test/stuQtestResult.do?testId=91007573', '第五章测试'),
('https://eplat.imau.edu.cn/meol/test/stuQtestResult.do?testId=91008411', '第六章测试'),
('https://eplat.imau.edu.cn/meol/test/stuQtestResult.do?testId=91251387', '第七章测试'),
('https://eplat.imau.edu.cn/meol/test/stuQtestResult.do?testId=91318025', '8237和DAC0832测试'),
])
2. 完整代码
import time
import pandas as pd
import requests
from bs4 import BeautifulSoup
def right_answer_convert(option_list: list):
index_list = [i for i, item in enumerate(option_list) if '答案' in item]
answer_tag_text = option_list[index_list[0]]
for _ in index_list:
option_list.remove(answer_tag_text)
ret_answer = []
for i, item in enumerate(index_list):
ret_answer.append(chr(ord('A') + item - i - 1))
return ''.join(ret_answer)
def fetch_one(url, save_file=''):
s = requests.get(url, headers={
'cookie': 'JSESSIONID=D916E34E743A99701B33AC73CDE3F6ED',
'User-Agent':'Mozilla/5.0(iPhone;U;CPUiPhoneOS4_3_3likeMacOSX;en-us)AppleWebKit/533.17.9(KHTML,likeGecko)Version/5.0.2Mobile/8J2Safari/6533.18.5'
})
soup = BeautifulSoup(s.text, 'html.parser')
question_raw_list = soup.find_all('div', class_='test_checkq_question_editorWrapper')
ret_list = []
for question_raw in question_raw_list:
each_question = dict()
each_question['type'] = '单选'
each_question['title'] = question_raw.find('div', class_='title').text.strip()
question_option = question_raw.find('div', class_='item')
# print(question_option)
if question_option is None:
each_question['answer'] = question_raw.find('div', class_='rightAnswer_body').text.strip()
print(each_question['answer'])
if each_question['answer'] in ['T', 'F']:
each_question['type'] = '判断题'
each_question['answer'] = each_question['answer'].replace('T', '对').replace('F', '错')
each_question['option'] = ['对', '错']
else:
each_question['type'] = '简答题'
else:
question_option = question_raw.find('div', class_='item').find_all('span')
each_question['option'] = list(map(lambda x: x.get_text(), question_option))
each_question['answer'] = right_answer_convert(each_question['option'])
each_question['option'] = list(filter(lambda x: '答案' not in x, each_question['option']))
each_question['type'] = '单选题' if len(each_question['answer']) == 1 else '多选题'
ret_list.append(each_question)
col_name_list = ['题型', '题目', '选项1', '选项2', '选项3', '选项4', '选项5', '正确答案', '答案解析', '分值']
df = pd.DataFrame(columns=col_name_list)
for i in ret_list:
template = {
'题型': i['type'],
'题目': i['title'],
'正确答案': i['answer'],
'答案解析': '',
'分值': '1'
}
if i['type'] not in ['判断题', '简答题']:
for j, item in enumerate(i['option']):
template['选项' + str(j + 1)] = item
# df = df.append(template, ignore_index=True)
df = pd.concat([df, pd.DataFrame(template, index=[0])], ignore_index=True)
timestamp = str(int(time.mktime(time.localtime(time.time()))))
df.to_excel('{}_{}.xlsx'.format(save_file, timestamp), index=False)
# print(df)
def fetch_all(url_list):
for i in url_list:
fetch_one(i[0], i[1])
if __name__ == '__main__':
fetch_all([
('https://eplat.imau.edu.cn/meol/test/stuQtestResult.do?testId=84246354', '第二章测试题'),
('https://eplat.imau.edu.cn/meol/test/stuQtestResult.do?testId=85256551', '第三章测试题'),
('https://eplat.imau.edu.cn/meol/test/stuQtestResult.do?testId=91007573', '第五章测试'),
('https://eplat.imau.edu.cn/meol/test/stuQtestResult.do?testId=91008411', '第六章测试'),
('https://eplat.imau.edu.cn/meol/test/stuQtestResult.do?testId=91251387', '第七章测试'),
('https://eplat.imau.edu.cn/meol/test/stuQtestResult.do?testId=91318025', '8237和DAC0832测试'),
])


















 858
858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











