






假如21类,生成一个21张的heatmap,然后上采样到原图大小,利用softmax对像素进行分类,就是最后通过逐个像素地求其在21张图像该像素位置的最大数值描述(概率)作为该像素的分类。相当于每个像素为一个样本。 1.这里对如何对每个像素进行分类,讲1x1x21直接平铺输入softmax吗???2.为什么要卷积成21个通道与类别的种类个数对应
- Part 1
概念:图像语义分割(Semantic Segmentation)是图像处理和是机器视觉技术中关于图像理解的重要一环,也是 AI 领域中一个重要的分支。语义分割即是对图像中每一个像素点进行分类,确定每个点的类别(如属于背景、人或车等),从而进行区域划分。目前,语义分割已经被广泛应用于自动驾驶、无人机落点判定等场景中。与分类不同的是,语义分割需要判断图像每个像素点的类别,进行精确分割。!图像语义分割是像素级别的但是由于CNN在进行convolution和pooling过程中丢失了图像细节,即feature map size逐渐变小,所以不能很好地指出物体的具体轮廓、指出每个像素具体属于哪个物体,无法做到精确的分割。
2. Part 2 CNN: CNN已经在图像分类分方面取得了巨大的成就,涌现出如VGG和Resnet等网络结构,并在ImageNet中取得了好成绩。CNN的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征 : 1.较浅的卷积层感知域较小,学习到一些局部区域的特征;2.较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征。
这些抽象特征对物体的大小、位置和方向等敏感性更低,从而有助于分类性能的提高。这些抽象的特征对分类很有帮助,可以很好地判断出一幅图像中包含什么类别的物体。图像分类是图像级别的
Part 3
FCN改变了什么?
FCN提出可以把后面几个全连接都换成卷积,这样就可以获得一张2维的feature map,后接softmax获得每个像素点的分类信息,从而解决了分割问题,

最高维的feature map,我们成为headmap.对headmap上采样(psampling的意义在于将小尺寸的高维度feature map恢复回去,以便做pixelwise prediction,获得每个点的分类信息)到原图尺寸大小,然后对每个像素进行分类


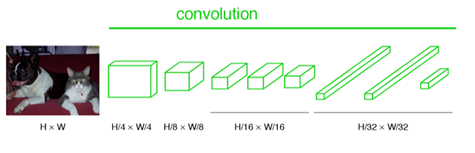
经过多次卷积和pooling以后,得到的图像越来越小,分辨率越来越低。其中图像到 H/32∗W/32 的时候图片是最小的一层时,所产生图叫做heatmap热图,热图就是我们最重要的高维特征图。
得到高维特征的heatmap之后就是最重要的一步也是最后的一步对原图像进行upsampling,把图像进行放大、放大、放大,到原图像的大小。
(也就是将高维特征图翻译成原图时对应的分割图像!!)
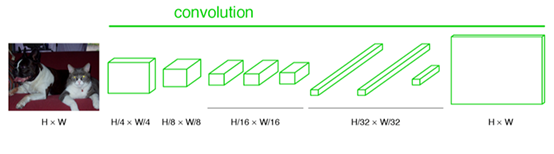
最后的输出是21张heatmap经过upsampling变为原图大小的图片,为了对每个像素进行分类预测label成最后已经进行语义分割的图像,这里有一个小trick,就是最后通过逐个像素地求其在21张图像该像素位置的最大数值描述(概率)作为该像素的分类。因此产生了一张已经分类好的图片,如下图右侧有狗狗和猫猫的图。
Part 4
什么是上采样?
上采样(upsampling)一般包括2种方式:
- Resize,如双线性插值直接缩放,类似于图像缩放(这种方法在原文中提到)
- Deconvolution,也叫Transposed Convolution
Part 5
语义分割网络在特征融合时也有2种办法:(与FCN逐点相加不同,U-Net采用将特征在channel维度拼接在一起,形成更“厚”的特征)
- FCN式的逐点相加,对应caffe的EltwiseLayer层,对应tensorflow的tf.add()
Part 6 总结一下,CNN图像语义分割也就基本上是这个套路: 2. 下采样+上采样:Convlution + Deconvlution/Resize 3. 多尺度特征融合:特征逐点相加/特征channel维度拼接 4. 获得像素级别的segement map:对每一个像素点进行判断类别
Part 7 下图是Longjon用于语义分割所采用的全卷积网络(FCN)的结构示意图, 在Alexnet基础上, 最后的channel=4096的feature map经过一个1x1的卷积层, 变为channel=21的feature map, 然后经过上采样和crop, 变为与输入图像同样大小的channel=21的feature map, 也就是图中的pixel-wise prediction。 在Longjon的试验中一共有20个语义类别, 加上背景类别每个像素应该有21个softmax预测类, 因此pixel-wise prediction中channel=21。

Reference
https://blog.csdn.net/qq_36269513/article/details/80420363
https://zhuanlan.zhihu.com/p/31428783
翻译:
https://www.jianshu.com/p/91c5db272725
https://www.jianshu.com/p/06550e84b13d?utm_campaign=maleskine&utm_content=note&utm_medium=seo_notes&utm_source=recommendation
指标说明:
https://blog.csdn.net/majinlei121/article/details/78965435
跳级结构:
https://blog.csdn.net/zhangjunhit/article/details/75635476















 4671
4671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









