







网上研究ConcurrentHashMap的帖子多如牛毛,有几篇不错,推荐一下:
- IBM developerWorks 探索 ConcurrentHashMap 高并发性的实现机制
- skywang12345的博客 Java多线程系列--“JUC集合”04之 ConcurrentHashMap
几个要点:
1. 通过将哈希表拆分成多个片段(Segment)实现“锁分段”,用多个小锁取代一个大锁,减少冲突
2. 内部数据尽量定义为 final, 或volatile, 并利用sun.misc.Unsafe,实现对读操作不需要加锁即可进行并行操作
//TODO 需要继续研究sun.misc.Unsafe
3. 用链表处理哈希碰撞的情况,通过copy元素 + 修改bucket引用的方式,使得在修改的时候,不影响已经开始的读取操作(读到的可能为修改之前的值)。
这一点在上面推荐的两篇文章中有详细介绍。
4. power-of-two for HashMap buckets
关于哈希处理部分,推荐两篇帖子
HashMap requires a better hashCode() - JDK 1.4 Part II
CurrentHashMap的数据结构如下图
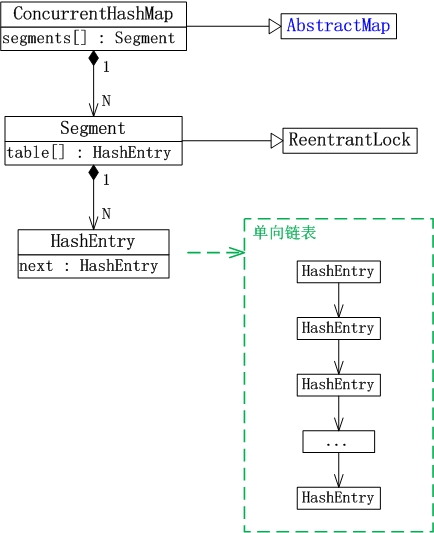
最后记录几个读源码时候的几个点,便于复习
1、Segment的数量,不小于concurrentLevel的最小的2的幂。每个Segment中的哈希表长度是是2的幂。Threashold是当前哈希表中最多容纳的HashEntry数量,如果超过,哈希表长度*2,rehash
2、为避免所存储的key的hash值导致大量碰撞,对原始hash值再进行一次hash,详见hash()方法。源码中注释如下:
/**
* Applies a supplemental hash function to a given hashCode, which
* defends against poor quality hash functions. This is critical
* because ConcurrentHashMap uses power-of-two length hash tables,
* that otherwise encounter collisions for hashCodes that do not
* differ in lower or upper bits.
*/
3、根据hash值的最高n位来定位segment: (hash >>>segmentShift ) & segmentMask
4、注意下面这个判断条件,用到集合,千万要保证 hash()方法 和 equals() 的一致性
if ((k = e.key) == key || (e.hash == h && key.equals(k)))5、要理解透彻,相关的知识、代码要多看,例如:非公平锁,哈希算法,Volatile,Unsafe,内存模型等等
最后,看代码遇到一个问题:
大量的文档中都提到:HashEntry的key, hash, next都是final的,但我读的 JDK 7u55的代码,next属性是volatile. 并且,在CHM的源码中,对next属性只有read,没有write,那么修饰符改为volatie的目的何在呢?















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









