









前言
本课程来自深度之眼deepshare.net,部分截图来自课程视频。
文章标题:GloVe: Global Vectors for Word Representation
原标题翻译:基于全局共现信息的词表示
GloVe–在word2vec基础上的一种改进方法(念:哥路)
作者:Jeffrey Pennington(原研究方向是理论物理,数学扎实,这个模型的推导公式超多)
单位:Stanford University
发表会议及时间:EMNLP2014
在线LaTeX公式编辑器
论文总览

学习目标

第一课:论文导读
词表示
想要让机器能够理解语言,最基础的也是最重要的就是将自然语言编码为机器能够处理的方式,词作为自然语言中粒度最小的组成单元,如何从无监督文本语料中提取词的语义,是自然语言处理中的基础问题。
词袋模型
词袋模型是最早的一种词表示方法,其简单、高效、可解释性,导致其现在在某些场景中仍是词的重要表达方式,要掌握词袋模型的中心思想及优缺点。
语言模型
神经语言模型是目前最火热的研究方向,也是词表示技术的来源与基础,掌握最基本的神经语言模型及衍生出的skip-gram、CBOW词表示技术,是掌握基于深度学习的NLP任务的基石。
词表示简介
自然语言是一套用来表达含义的复杂系统。在这套系统中,词是表义的基本单元。词表示指的是,通过某种方式将单词(token)编码为计算机可以处理的形式(向量),这是实现自然语言理解中最基础也是最重要的步骤。高质量的词表示可以使计算机有效地完成各种自然语言相关的任务,如机器翻译、自动问答、人机对话等。
离散表示(独热表示)
屏幕[0,1,0,0,0]
画质[1,0,0,0,0]
很好[0,0,0,0,1]
屏幕画质很好[1,1,0,0,1]
稠密表示
屏幕[0.1,2.9,-1.2]
画质[1.8,0.4,-0.9]
很好[0.5,-0.6,0.8]
屏幕画质很好[2.4,2.7,-1.3]
词表示研究意义
词表示已成为所有基于深度学习的自然语言处理(NLP)系统的重要组成部分,它们在固定长度的向量中编码单词,以大幅度提高神经网络处理文本数据的能力。


独热表示One-hot Representation
虽然已经讲过很多遍,但是还是再记一下:
One-hot编码,又称独热编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。One-hot在特征提取上属于词袋模型(bag of words)。关于如何使用one-hot抽取文本特征向量我们通过以下例子来说明。假设语料库中有三段话:
我爱中国
爸爸妈妈爱我
爸爸妈妈爱中国
对语料库分词对每个词编号
1:我;2:爱;3:爸爸;4:妈妈;5:中国
句向量可以看下面例子:

即:
我爱中国[1,1,0,0,1]
爸爸妈妈爱我[1,1,1,1,0]
爸爸妈妈爱中国[0,1,1,1,1]
词袋模型,未考虑词序:我爱中国和爱我中国两个句子都是[1,1,0,0,1];
假设词与词相互独立,不能表达词的相似度:爸爸和妈妈应该是有一定的相似度的,但是他们的编码分别是[0,0,1,0,0]和 [0,0,0,1,0],两个向量的余弦相似度为0;
词的表示高维、离散、稀疏,很难处理。
有两个方向来改进它:
词表示发展历史The History of Word Representation
趋势:让词的语义更“准确”地编码到有限维的向量中
在向量子空间中保持词的语义关系
基于独热的词表示→基于共现矩阵的词表示→基于神经网络的词表示
基于共现矩阵的词表示
词共现矩阵 Window based Co-occurrence Matrix
You shall know a word by the company it keeps.-Firth,J.R.Papers in Linguistics,1957.
假设语料库中有三段话:
I like deep learning.
I like NLP.
I enjoy flying.
构建一个“词汇-上下文”的矩阵,其中每行对应一个词,每列表示一种不同的上下文,窗口大小为1,矩阵中的每个元素表示对应词汇和其上下文的共现次数。在这种表示方式下,矩阵中的一行描述了对应词汇的上下文的分布,也就是该词汇的向量表示。

高维、离散、稀疏→分解、降维
以上是term-term,也就是词与词的共现矩阵表示,还有一种是term-document的共现矩阵,把列头换成文档,表示每个词在文档中出现的次数。
基于矩阵奇异值分解的词表示SVD-based Word Representation
基本思想:Deerwster提出利用奇异值分解(SVD)方法对共现矩阵进行分解。这种方法可以看作是对频率矩阵进行降噪和降维处理,并从中挖掘出词汇的潜在含义。类似的方法还有非负矩阵分解(NMF)、典型关联分析(CCA)等。

对X进行SVD
X
=
U
S
V
T
X=USV^T
X=USVT
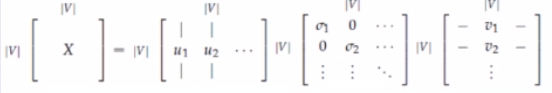
中间的矩阵S除了对角线,其他位置都是0。对角线上的元素
σ
i
\sigma_i
σi称为奇异值。从矩阵U中选取前k列,作为词向量。
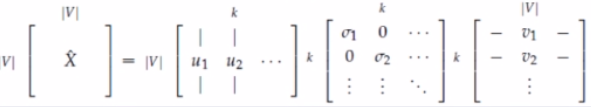

SVD得到了word的稠密矩阵,该矩阵具有很多良好的性质:语义相近的词在向量空间相近,甚至可以一定程度反映word间的线性关系。

缺点:
1.矩阵维度经常变动,比如新词频繁加入
2.绝大部分词不会共现,矩阵过于稀疏
3.矩阵维度很高,大约是
1
0
6
×
1
0
6
10^6×10^6
106×106
4.训练时的计算复杂度是
O
(
∣
V
∣
3
)
O(|V|^3)
O(∣V∣3)V是词表大小
基于神经网络的词表示
语言模型Language Model
Sentence 1:美联储主席本·伯南克昨天告诉媒体7000亿美元的救助资金
Sentence 2:美主席联储本·伯南克告诉昨天媒体7000亿美元的资金救助
哪个句子更像一个合理的句子?如何量化评估?
P
(
S
)
=
P
(
w
1
,
w
2
,
.
.
.
,
w
n
)
=
P
(
w
1
)
P
(
w
2
∣
w
1
)
P
(
w
3
∣
w
1
,
w
2
)
.
.
.
P
(
w
n
∣
w
1
,
w
2
,
.
.
.
,
w
n
−
1
)
P(S)=P(w_1,w_2,...,w_n)=P(w_1)P(w_2|w_1)P(w_3|w_1,w_2)...P(w_n|w_1,w_2,...,w_{n-1})
P(S)=P(w1,w2,...,wn)=P(w1)P(w2∣w1)P(w3∣w1,w2)...P(wn∣w1,w2,...,wn−1)
语言模型:
L
=
∑
w
∈
C
l
o
g
P
(
w
∣
c
o
n
t
e
x
t
(
w
)
)
L=\sum_{w\in C}logP(w|context(w))
L=∑w∈ClogP(w∣context(w))
神经网络语言模型

首先随机初始化一个词表大小×D的词表示矩阵,矩阵有词表大小行,每一行都是一个词的表示,对于输入的句子的矩阵,是在词表示矩阵中找到对应的词表示,然后输入到神经网络中,目的是在神经网络中最大化在上下文条件下一个句子中最大概率会出现哪个词,通过梯度优化更新词表示矩阵,最后得到概率分布。虽然是一个语言模型,但是通过这个模型得到了词表示矩阵。在神经网络语言模型的基础上,发展出两个基于神经网络的词表示方法:CBOW和Skip-gram。

Skip-gram
单独把Skip-gram拿出来再讲一下,因为GloVe最终可以推导为Skip-gram的一种特殊形式。

损失函数为:最大化根据中心词预测周围窗口词出现的概率
L
=
−
1
T
∑
t
=
1
T
∑
−
m
<
=
j
<
=
m
j
<
>
0
log
p
(
w
t
+
j
∣
w
t
)
L=-\frac{1}{T}\sum_{t=1}^T\sum_{\underset{j<>0}{-m<=j<=m}}\text{log}p(w_{t+j}|w_t)
L=−T1t=1∑Tj<>0−m<=j<=m∑logp(wt+j∣wt)

p
(
w
t
+
j
∣
w
t
)
=
e
x
p
(
V
w
t
T
V
w
t
+
j
)
∑
i
=
1
∣
V
∣
e
x
p
(
V
w
t
T
V
w
i
)
p(w_{t+j}|w_t)=\frac{exp(V_{w_t}^TV_{w_{t+j}})}{\sum_{i=1}^{|V|}exp(V_{w_t}^TV_{w_{i}})}
p(wt+j∣wt)=∑i=1∣V∣exp(VwtTVwi)exp(VwtTVwt+j)
小结
基于矩阵分解的词表示方法:首先统计语料库中的“词-文档”或者“词-词”共现矩阵,然后通过矩阵分解的方法来获得一个低维词向量。
优点:利用全局统计信息
缺点:时间复杂度高、过度重视共现词频高的单词对
基于神经网络的词表示方法:通过神经网络使上下文窗口内频繁共现的单词对的表示接近优点:效果较好、速度快
缺点:没有充分利用全局统计信息、过度重视共现词频高的单词对
GloVe:取长补短,结合两种方法的优点学习词表示
前期知识储备
词表示
掌握词表示的思想,熟悉其发展历程
词共现矩阵
掌握词共现矩阵的构造方法,了解SVD分解的过程及推导
word2vec
了解基于神经网络的词表示,熟悉其代表性方法skip-gram的训练和使用方法
第二课 论文精读
论文结构
摘要
1.当前词向量学习模型能够通过向量的算术计算捕捉词之间细微的语法和语义规律,但是这种规律背后的原理依旧不清楚。(可解释性差)
2.经过仔细的分析,我们发现了一些有助于这种词向量规律的特性,并基于词提出了一种新的对数双线性回归模型,这种模型能够利用全局矩阵分解和局部上下文的优点来学习词向量。
3.我们的模型通过只在共现矩阵中的非0位置训练达到高效训练的目的。
4.我们的模型在词对推理任务上得到75%的准确率,并且在多个任务上得到最优结果。
原文:
Recent methods for learning vector space representations of words have succeeded
in capturing fine-grained semantic and syntactic regularities using vector arithmetic, but the origin of these regularities has remained opaque.
We analyze and make explicit the model properties needed for such regularities to emerge in word vectors. The result is a new global logbilinear regression model that combines the advantages of the two major model families in the literature: global matrix factorization and local context window methods.
Our model efficiently leverages statistical information by training only on the nonzero elements in a word-word cooccurrence matrix, rather than on the entire sparse matrix or on individual context windows in a large corpus.
The model produces a vector space with meaningful substructure, as evidenced by its performance of 75% on a recent word analogy task. It also outperforms related models on similarity tasks and named entity recognition.
论文小标题
- Introduction
- Related Work
2.1Matrix Factorization Methods
2.2Shallow Window Based Methods - The GloVe Model
3.1Relationship to Other Models
3.2Complexity of the model - Experiments
4.1Evaluation methods
4.2Corpora and training details
4.3Results
4.4Model Analysis:Vector Length and Context Size
4.5Model Analysis:Corpus Size
4.6Model Analysis:Run-time
4.7Model Analysis:Comparison with word2vec - Conclusion
GloVe模型
观察分析
原理:
我们可以使用一些词来描述一个词,比如我们使用冰块和蒸汽来描述固体、气体、水和时尚四个词。
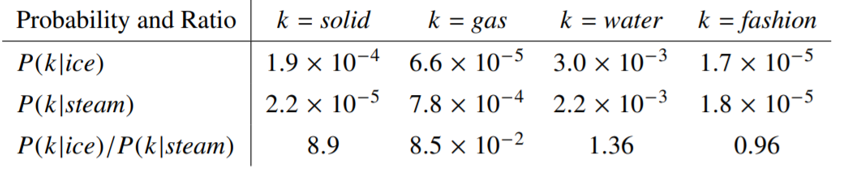
与冰块接近,并且和蒸汽不接近;固体并且概率比值很大与蒸汽接近,并且和冰块不接近;气体并且概率比值很小与冰块和蒸汽都不接近;水和时尚并且概率比值不大不小
结论:共现矩阵的概率比值可以用来区分词。上例中,利用第三行的比值:
F
(
w
i
,
w
j
,
w
~
k
)
=
P
i
k
P
j
k
(1)
F(w_i,w_j,\tilde w_k)=\cfrac{P_{ik}}{P_{jk}}\tag1
F(wi,wj,w~k)=PjkPik(1)
solid和gas可以相互区分。但是water和fashion是不可区分的。
为了描述差异,对比值计算进行改进:
F
(
w
i
−
w
j
,
w
~
k
)
=
P
i
k
P
j
k
(2)
F(w_i-w_j,\tilde w_k)=\cfrac{P_{ik}}{P_{jk}}\tag2
F(wi−wj,w~k)=PjkPik(2)
原文:
We begin with a simple example that showcases how certain aspects of meaning can be extracted directly from co-occurrence probabilities. Consider two words i and j that exhibit a particular aspect of interest; for concreteness, suppose we are interested in the concept of thermodynamic phase, for which we might take i = ice and j = steam.
The relationship of these words can be examined by studying the ratio of their co-occurrence probabilities with various probe words, k. For words k related to ice but not steam, say k = solid, we expect the ratio Pik /Pjk will be large. Similarly, for words k related to steam but not ice, say k = gas, the ratio should be small. For words k like
water or fashion, that are either related to both ice and steam, or to neither, the ratio should be close to one. Table 1 shows these probabilities and their ratios for a large corpus, and the numbers confirm these expectations. Compared to the raw probabilities, the ratio is better able to distinguish relevant words (solid and gas) from irrelevant words (water and fashion) and it is also better able to discriminate between the two relevant words.
但是公式2中左边是向量,右边是标量,要改成:
F
(
(
w
i
−
w
j
)
T
,
w
~
k
)
=
P
i
k
P
j
k
(3)
F((w_i-w_j)^T,\tilde w_k)=\cfrac{P_{ik}}{P_{jk}}\tag3
F((wi−wj)T,w~k)=PjkPik(3)
这里的具体推导下面有,不重复写了。
符号定义
X
X
X:表示“词-词”(term-term)共现矩阵,是一个对阵矩阵;
X
i
j
X_{ij}
Xij:表示词j出现在中心词i的上下文(基于窗口)的次数;
X
i
=
∑
k
X
i
k
X_i=\sum_kX_{ik}
Xi=∑kXik:表示任何词出现在词i上下文的总的次数;
P
i
j
=
X
i
j
X
i
P_{ij}=\cfrac{X_{ij}}{X_i}
Pij=XiXij:表示单词j出现在词i的上下文的概率。
| R a t i o = P i k P j k Ratio=\cfrac{P_{ik}}{P_{jk}} Ratio=PjkPik | j,k相关 | j,k不相关 |
|---|---|---|
| i,k相关 | 1 | 非常大 |
| i,k不相关 | 非常小 | 1 |
论文中给出的例子:
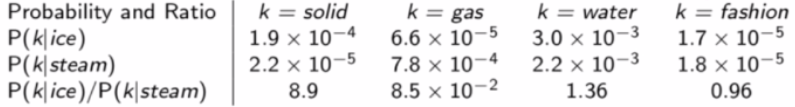
当k=water的时候ice和steam有某种联系
模型
模型动机

要求
R
a
t
i
o
=
P
i
k
P
j
k
Ratio=\cfrac{P_{ik}}{P_{jk}}
Ratio=PjkPik ,GloVe弄了一个函数F长成这个样子:
F
(
w
i
,
w
j
,
w
~
k
)
=
P
i
k
P
j
k
(1)
F(w_i,w_j,\tilde w_k)=\frac{P_{ik}}{P_{jk}} \tag 1
F(wi,wj,w~k)=PjkPik(1)
其中:
w
i
,
w
j
w_i,w_j
wi,wj是d维词向量
w
~
k
\tilde w_k
w~k是上下文检测词
因为向量空间具有线性结构(就是男人vs女人类似于国王vs王后):
F
(
w
i
−
w
j
,
w
~
k
)
=
P
i
k
P
j
k
(2)
F(w_i-w_j,\tilde w_k)=\frac{P_{ik}}{P_{jk}} \tag 2
F(wi−wj,w~k)=PjkPik(2)
公式2左边是个向量,右边是一个标量,因此我们可以使用向量点积来建模:
F
(
(
w
i
−
w
j
)
T
w
~
k
)
=
P
i
k
P
j
k
(3)
F((w_i-w_j)^T\tilde w_k)=\frac{P_{ik}}{P_{jk}} \tag 3
F((wi−wj)Tw~k)=PjkPik(3)
希望w和
w
~
\tilde w
w~保持对称可变换(就是互换ij等式依然成立),为了保持对称性,公式3中的左边可以变成:
F
(
(
w
i
−
w
j
)
T
w
~
k
)
=
F
(
w
i
T
w
~
k
)
F
(
w
j
T
w
~
k
)
(4)
F((w_i-w_j)^T \tilde w_k)=\cfrac{F(w_i^T\tilde w_k)}{F(w_j^T\tilde w_k)}\tag 4
F((wi−wj)Tw~k)=F(wjTw~k)F(wiTw~k)(4)
把公式4带回去公式3得到:
F
(
w
i
T
w
~
k
)
F
(
w
j
T
w
~
k
)
=
P
i
k
P
j
k
(5)
\frac{F(w_i^T\tilde w_k)}{F(w_j^T\tilde w_k)}=\cfrac{P_{ik}}{P_{jk}}\tag 5
F(wjTw~k)F(wiTw~k)=PjkPik(5)
按公式5中分子分母对位相等的原则可得:
F
(
w
i
T
w
~
k
)
=
P
i
k
=
X
i
k
X
i
(6)
F(w_i^T\tilde w_k)=P_{ik}=\cfrac{X_{ik}}{X_i}\tag 6
F(wiTw~k)=Pik=XiXik(6)
为了满足公式4中提到的对称性,F应该是一个exp函数(不知道为什么,论文里面就是这样定义的),而且exp函数有:
e
a
−
b
=
e
a
e
b
e^{a-b}=\cfrac{e^a}{e^b}
ea−b=ebea,故:
F
(
(
w
i
−
w
j
)
T
w
~
k
)
=
e
x
p
(
(
w
i
−
w
j
)
T
w
~
k
)
=
e
x
p
(
w
i
T
w
~
k
−
w
j
T
w
~
k
)
=
e
x
p
(
w
i
T
w
~
k
)
e
x
p
(
w
j
T
w
~
k
)
=
P
i
k
P
j
k
(7)
F\left ((w_i-w_j)^T\tilde w_k\right)=exp\left ((w_i-w_j)^T\tilde w_k\right)\\=exp\left (w_i^T\tilde w_k-w_j^T\tilde w_k\right)=\cfrac{exp(w_i^T\tilde w_k)}{exp(w_j^T\tilde w_k)}=\cfrac{P_{ik}}{P_{jk}}\tag 7
F((wi−wj)Tw~k)=exp((wi−wj)Tw~k)=exp(wiTw~k−wjTw~k)=exp(wjTw~k)exp(wiTw~k)=PjkPik(7)
公式7中,比较简单的解就是:分子等于分子,分母等于分母,由于分子分母中的i,j都是参数,换成其他字母也可以成立,也就是:
e
x
p
(
w
m
T
w
~
k
)
=
P
m
k
,
m
∈
(
0
,
∣
V
∣
)
exp(w_m^T\tilde w_k)=P_{mk},m\in (0,|V|)
exp(wmTw~k)=Pmk,m∈(0,∣V∣)
为了方便还是写成i吧,然后结合公式6得到:
e
x
p
(
w
i
T
w
~
k
)
=
P
i
k
=
X
i
k
X
i
(8)
exp(w_i^T\tilde w_k)=P_{ik}=\cfrac{X_{ik}}{X_i}\tag 8
exp(wiTw~k)=Pik=XiXik(8)
公式8不好优化,因为exp函数中x变化一点点,y的结果会变动很大所以要对公式两边同时求log
w
i
T
w
~
k
=
l
o
g
(
P
i
k
)
=
l
o
g
(
X
i
k
X
i
)
=
l
o
g
(
X
i
k
)
−
l
o
g
(
X
i
)
(9)
w_i^T\tilde w_k=log(P_{ik})=log(\cfrac{X_{ik}}{X_i})=log(X_{ik})-log(X_i)\tag 9
wiTw~k=log(Pik)=log(XiXik)=log(Xik)−log(Xi)(9)
由于
l
o
g
(
x
i
)
log(x_i)
log(xi)和k无关,只和第i个词有关,可以看做是一个偏置
b
i
b_i
bi
w
i
T
w
~
k
=
l
o
g
(
X
i
k
)
−
b
i
w
i
T
w
~
k
+
b
i
=
l
o
g
(
X
i
k
)
(10)
w_i^T\tilde w_k=log(X_{ik})-b_i \\ w_i^T\tilde w_k+b_i=log(X_{ik}) \tag {10}
wiTw~k=log(Xik)−biwiTw~k+bi=log(Xik)(10)
公式10中右边是对称的:
l
o
g
(
x
i
k
)
=
l
o
g
(
x
k
i
)
log(x_{ik})=log(x_{ki})
log(xik)=log(xki),右边是不对称的:
w
i
T
w
~
k
+
b
i
≠
w
k
T
w
~
i
+
b
k
w_i^T\tilde w_k+b_i\neq w_k^T\tilde w_i+b_k
wiTw~k+bi=wkTw~i+bk
这样明显不会相等,所以加一个
b
k
b_k
bk把右边变成对称的:
w
i
T
w
~
k
+
b
i
+
b
k
=
w
k
T
w
~
i
+
b
k
+
b
j
w_i^T\tilde w_k+b_i +b_k= w_k^T\tilde w_i+b_k+b_j
wiTw~k+bi+bk=wkTw~i+bk+bj
为了和
w
~
k
\tilde w_k
w~k对应,把偏置
b
k
b_k
bk变成
b
~
k
\tilde b_k
b~k(原文就是这样搞的):
w
i
T
w
~
k
+
b
i
+
b
~
k
=
l
o
g
(
X
i
k
)
(11)
w_i^T\tilde w_k+b_i +\tilde b_k=log(X_{ik}\tag {11})
wiTw~k+bi+b~k=log(Xik)(11)
上式只是理想情况,实际只能要求左右两边接近,对公式11的左右两边使用交叉熵,得到损失函数(交叉熵目标就是使得左边尽量接近右边):
J
=
∑
i
,
j
=
1
V
(
w
i
T
w
~
j
+
b
i
+
b
~
j
−
l
o
g
(
X
i
j
)
)
2
(12)
J=\sum_{i,j=1}^V(w_i^T\tilde w_j+b_i +\tilde b_j-log(X_{ij}))^2\tag {12}
J=i,j=1∑V(wiTw~j+bi+b~j−log(Xij))2(12)
其中:V is the size of the vocabulary.
根据经验,如果两个词共同出现的次数越多,那么这两个词就越相关,其在损失函数中的权值应该也就越大引入权重函数
f
(
X
i
k
)
f(X_{ik})
f(Xik)
PS:在公式13中对于每个词k可以做为中心词和上下文词,因此有两种向量表示(
w
^
k
\widehat w_k
w
k和
w
k
w_k
wk),论文中简单粗暴直接用两个向量相加来表示最终结果
J
=
∑
i
,
j
V
f
(
X
i
j
)
(
w
i
T
w
~
j
+
b
i
+
b
~
j
−
l
o
g
(
X
i
j
)
)
2
(13)
J=\sum_{i,j}^V f(X_{ij})(w_i^T\tilde w_j+b_i +\tilde b_j-log(X_{ij}))^2\tag {13}
J=i,j∑Vf(Xij)(wiTw~j+bi+b~j−log(Xij))2(13)
如何设计权重函数
f
(
X
i
k
)
f(X_{ik})
f(Xik)呢?
f
(
X
i
k
)
f(X_{ik})
f(Xik)应该符合以下三个特点:
(1)
f
(
0
)
=
0
f(0)=0
f(0)=0如果两个词没有共同出现过,权重就是0,不参加训练
(2)
f
(
X
)
f(X)
f(X)必须是非减函数,两个词共现次数多,权重不能变小
(3)不能过分重视高频词对,对特别大的
X
X
X不能取特别高的值(比如汉语中的“的")
根据以上三个特点,论文构造了如下这么一个权重函数:
f
(
x
)
=
{
(
x
x
m
a
x
)
α
,
i
f
x
<
x
m
a
x
1
,
o
t
h
e
r
w
i
s
e
(14)
f(x)=\left\{\begin{matrix} (\cfrac{x}{x_{max}})^\alpha ,if\space x<x_{max}\\ 1,otherwise \end{matrix}\right.\tag {14}
f(x)=⎩⎨⎧(xmaxx)α,if x<xmax1,otherwise(14)
超参数
x
m
a
x
=
100
;
α
=
0.75
x_{max}=100; \alpha=0.75
xmax=100;α=0.75

实验结果
测试任务Evaluation methods
做了三类实验
第一:Word analogies:"a is to b as c is to?"遍历词典,找到和
w
b
−
w
a
+
w
c
w_b-w_a+w_c
wb−wa+wc最接近(余弦相似度最大)的词,这个也是主实验。SG是Skip-gram。

下划线代表对比组中最好结果。
第二Word similarity:两个单词语义相似性计算(余弦相似度)

第三:NER:命名实体识别

参数的选择
·向量长度对结果的影响
·窗口大小对结果的影响
 对于三个图,加大向量维度和窗口大小结果都会变好。
对于三个图,加大向量维度和窗口大小结果都会变好。
对于维度而言,200维是一个临界点,超过这个维度性能提升不明显;
Symmetric context对称和Asymmetric context非对称计算,前者在计算中心词的时候左右两边词都参与计算,后者在计算中心词的时候只有左边参与计算;
语法紫色线在非对称算法上表现比较好,因为类似形容词之类的一般都是看邻近词和词序较多,语义绿色线在对称算法上表现比较好,而且对于词的距离不敏感,所以随着窗口增大性能一直有提升。
这个结论对于我们的下游任务不一样,选择的算法也应该不一样。
Performance is better on the syntactic(语法紫色线) subtask for small and asymmetric context windows, which aligns with the intuition that syntactic information is mostly drawn from the immediate context and can depend strongly on word order. Semantic(语义绿色线) information, on the other hand, is more frequently non-local, and more of it is captured with larger window sizes.
性能与数据集大小的关系
总体趋势是数据量越大,效果越好

注意:绿色的语义结果在wiki语料上用小数据集取得的结果比数据量大的数据集效果好,说明在语义训练的时候,数据集的质量比数量更加重要,因为wiki百科上包含很多语义的指代,而其他语料虽然数据量大,但是包含错误,因此训练效果还不如wiki。
性能对比Model Analysis:Comparison with word2vec

tip:作图的时候改变坐标可以凸显差距。
与skip-gram的联系
Q
i
j
=
e
x
p
(
w
i
T
w
~
j
)
∑
k
=
1
∣
V
∣
e
x
p
(
w
i
T
w
~
k
)
(15)
Q_{ij}=\frac{exp({w_i}^T\tilde w_{j})}{\sum_{k=1}^{|V|}exp({w_i}^T{\tilde w_{k}})}\tag{15}
Qij=∑k=1∣V∣exp(wiTw~k)exp(wiTw~j)(15)
公式15是skip-gram建模周围词j出现在单词i上下文的概率
Q
i
j
Q_{ij}
Qij
得到的目标函数为:
J
=
−
∑
i
∈
c
o
r
p
u
s
j
∈
c
o
n
t
e
x
t
(
i
)
log
Q
i
j
(16)
J=-\sum_{\underset{j\in context(i)}{i\in corpus}}\text{log}Q_{ij}\tag{16}
J=−j∈context(i)i∈corpus∑logQij(16)
公式16是针对整个语料库的,所以可以把16拆分为17,公式16中的j是i的上下文,公式17中的j只是遍历从1到V的词,
X
i
j
X_{ij}
Xij是i和j共现的次数。由于我们需要利用全局统计信息,因此一个单词对可能出现很多次,因此,我们首先把所有相同的单词对先进行计算
J
=
−
∑
i
=
1
V
∑
j
=
1
V
X
i
j
log
Q
i
j
(17)
J=-\sum_{i=1}^V\sum_{j=1}^VX_{ij}\text{log}Q_{ij}\tag{17}
J=−i=1∑Vj=1∑VXijlogQij(17)
根据符号定义中的:
X
i
=
∑
k
X
i
k
X_i=\sum_kX_{ik}
Xi=∑kXik和
P
i
j
=
X
i
j
X
i
P_{ij}=\cfrac{X_{ij}}{X_i}
Pij=XiXij得到:
J
=
−
∑
i
=
1
V
∑
j
=
1
V
X
i
P
i
j
log
Q
i
j
=
−
∑
i
=
1
V
X
i
∑
j
=
1
V
P
i
j
log
Q
i
j
=
∑
i
=
1
V
X
i
H
(
P
i
,
P
j
)
(18)
J=-\sum_{i=1}^V\sum_{j=1}^VX_{i}P_{ij}\text{log}Q_{ij}=-\sum_{i=1}^VX_{i}\sum_{j=1}^VP_{ij}\text{log}Q_{ij}\\=\sum_{i=1}^VX_iH(P_i,P_j)\tag{18}
J=−i=1∑Vj=1∑VXiPijlogQij=−i=1∑VXij=1∑VPijlogQij=i=1∑VXiH(Pi,Pj)(18)
其中
H
(
P
i
,
P
j
)
H(P_i,P_j)
H(Pi,Pj)是分布
P
i
P_i
Pi和
P
j
P_j
Pj的交叉熵损失。
交叉熵在这里并不是一个好的损失:(过于偏重长尾分布、交叉熵需要归一化,计算量大)
解决方法就是使用均方损失,不怎么受到长尾分布的影响
J
^
=
∑
i
=
1
V
X
i
∑
j
=
1
V
(
P
i
j
−
Q
i
j
)
2
(19)
\widehat J=\sum_{i=1}^VX_{i}\sum_{j=1}^V(P_{ij}-Q_{ij})^2\tag{19}
J
=i=1∑VXij=1∑V(Pij−Qij)2(19)
抛弃计算
P
i
j
P_{ij}
Pij,因为需要归一化,费时,得到:
J
^
=
∑
i
=
1
V
X
i
∑
j
=
1
V
(
P
^
i
j
−
Q
^
i
j
)
2
(20)
\widehat J=\sum_{i=1}^VX_{i}\sum_{j=1}^V(\widehat P_{ij}-\widehat Q_{ij})^2\tag{20}
J
=i=1∑VXij=1∑V(P
ij−Q
ij)2(20)
直接计算次数(就是单词出现的次数),即
P
^
i
j
=
X
i
j
\widehat P_{ij}=X_{ij}
P
ij=Xij,
Q
^
i
j
=
e
x
p
(
w
i
T
w
^
j
)
\widehat Q_{ij}=exp(w_i^T\widehat w_j)
Q
ij=exp(wiTw
j),然后:
J
^
=
∑
i
=
1
V
∑
j
=
1
V
X
i
(
X
i
j
−
e
x
p
(
w
i
T
w
^
j
)
)
2
(21)
\widehat J=\sum_{i=1}^V\sum_{j=1}^VX_{i}(X_{ij}-exp(w_i^T\widehat w_j))^2 \tag{21}
J
=i=1∑Vj=1∑VXi(Xij−exp(wiTw
j))2(21)
由于
X
i
j
X_{ij}
Xij是共现次数,往往很大,优化为对数形式(就是对括号里面的东西分别取对数,这里也可以理解为要求两个分布的距离,因此可以同时对两个分布进行相同的变换):
J
^
=
∑
i
=
1
V
∑
j
=
1
V
X
i
(
log
X
i
j
−
w
i
T
w
^
j
)
2
=
∑
i
=
1
V
∑
j
=
1
V
X
i
(
w
i
T
w
^
j
−
log
X
i
j
)
2
(22)
\widehat J=\sum_{i=1}^V\sum_{j=1}^VX_{i}(\text{log}X_{ij}-w_i^T\widehat w_j)^2\\ =\sum_{i=1}^V\sum_{j=1}^VX_{i}(w_i^T\widehat w_j-\text{log}X_{ij})^2 \tag{22}
J
=i=1∑Vj=1∑VXi(logXij−wiTw
j)2=i=1∑Vj=1∑VXi(wiTw
j−logXij)2(22)
对比Glove的损失函数公式13:
J
=
∑
i
,
j
V
f
(
X
i
j
)
(
w
i
T
w
^
j
+
b
i
+
b
^
j
−
l
o
g
(
X
i
j
)
)
2
(13)
J=\sum_{i,j}^V f(X_{ij})(w_i^T\widehat w_j+b_i +\widehat b_j-log(X_{ij}))^2\tag {13}
J=i,j∑Vf(Xij)(wiTw
j+bi+b
j−log(Xij))2(13)
可以看到公式22中对于公式13中的权重函数不一样,22的权重函数形式为
X
i
X_{i}
Xi(单词i出现的次数),公式13的权重函数就是skip-gram中对单词进行重采样处理。整体上面来看GloVe相当于skip-gram的一种特殊形式,GloVe的权重函数设置更加合理,所以训练效果更加好。
讨论和总结
A、提出一种新的词表示方法
1.考虑全局信息
2.理论可解释
B、加入了一种权重函数来衡量高频词
C、对后续工作有很大启发:实验分析十分详尽
关键点
·矩阵分解的词向量学习方法
·基于上下文的词向量学习方法
·预训练词向量
创新点
·提出了一种新的词向量训练模型—GloVe
·在多个任务上取得最好的结果
·公布了一系列预训练的词向量
启发点
·相对于原始的概率,概率的比值更能够区分相关的词和不相关的词,并且能够区分两种相关的词。
Compared to the raw probabilities,the ratio is better able to distinguish relevant words(solid and gas)from irrelevant words(water and fashion)and it is also better able to discriminate between the two relevant words.(3 The GloVe Model P3)
·我们提出了一种新的对数双线性回归模型,这种模型结合全局矩阵分解和局部上下文的优点。
The result is a new global log-bilinear regression model that combines the advantages of the two major model families in the literature:global matrix factorization and local context window methods.(Abstract)
代码复现
准备工作
直接参考baseline 1的内容即可,数据集都一样的。
数据处理
import numpy as np
import os
import pickle # 用于数据保存的库,通常用于序列化的保存字典
from torch.utils import data
# 总体步骤:
# ·数据集加载
# ·构建word2id并去除低频词
# ·构建共现矩阵
# ·生成训练集
# ·保存结果
class Wiki_Dataset(data.DataLoader):
def __init__(self, min_count, window_size):
self.min_count = min_count
self.window_size = window_size
self.datas, self.labels = self.get_co_occur(data)
def __getitem__(self, index): # 根据index返回对应的数据
return self.datas[index], self.labels[index]
def __len__(self): # 求长度
return len(self.datas)
def read_data(self):
# 数据集加载
data = open(self.path + "/text8.txt").read()
data = data.split() # 用空格进行分词
self.word2freq = {}
for word in data:
if self.word2freq.get(word) != None: # 出现过的词词频+1
self.word2freq[word] += 1
else: # 未出现过的词词频为1
self.word2freq[word] = 1
word2id = {}
for word in self.word2freq:
if self.word2freq[word] < self.min_count: # 忽略词频小于min_count的单词
continue
else:
if word2id.get(word) == None:
word2id[word] = len(word2id)
self.word2id = word2id
print(len(self.word2id))
print(len(self.word2freq))
return data
# 构建共现矩阵
def get_co_occur(self, data):
self.path = os.path.abspath('.')
if "data" not in self.path:
self.path += "/data"
if not os.path.exists(self.path + "/label.npy"): # 如果没有保存则重新处理
print("Processing data...")
data = self.read_data()
print("Generating co-occurrences...")
vocab_size = len(self.word2id)
comat = np.zeros((vocab_size, vocab_size)) # 根据词表大小初始化全0共现矩阵
for i in range(len(data)):
if i % 1000000 == 0:
print(i, len(data))
if self.word2id.get(data[i]) == None: # 低频词不在word2id中,则忽略
continue
w_index = self.word2id[data[i]] # 找到中心词后映射为id
for j in range(max(0, i - self.window_size),
min(len(data), i + self.window_size + 1)): # 以中心词为中心在窗口范围内进行循环
if self.word2id.get(data[j]) == None or i == j: # 自己与自己共现次数为0,且周围词是低频词则忽略
continue
u_index = self.word2id[data[j]] # 找到周围词id
comat[w_index][u_index] += 1 # 共现次数+1
coocs = np.transpose(np.nonzero(comat)) # 将非零部分提取出来
labels = [] # 生成标签
for i in range(len(coocs)):
if i % 100000 == 0:
print(i, len(coocs))
labels.append(comat[coocs[i][0]][coocs[i][1]])
labels = np.array(labels)
np.save(self.path + "/data.npy", coocs)
np.save(self.path + "/label.npy", labels)
pickle.dump(self.word2id, open(self.path + "/word2id", "wb")) # 使用wb二进制的方式打开文件,并导入数据
else: # 如果已经保存则直接读取
coocs = np.load(self.path + "/data.npy")
labels = np.load(self.path + "/label.npy")
self.word2id = pickle.load(open(self.path + "/word2id", "rb"))
return coocs, labels
if __name__ == "__main__":
wiki_dataset = Wiki_Dataset(min_count=50, window_size=2)
print(wiki_dataset.datas.shape)
print(wiki_dataset.labels.shape)
print(wiki_dataset.labels[0:100])
模型
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
class glove_model(nn.Module):
# x_max是权重函数中上限
# alpha是权重函数中的指数,一般默认3/4
def __init__(self, vocab_size, embed_size, x_max, alpha): # 必须实现
super(glove_model, self).__init__()
self.vocab_size = vocab_size
self.embed_size = embed_size
self.x_max = x_max
self.alpha = alpha
# 中心词向量,大小为vocab_size*embed_size,转换为float64(double型)因为后面的label是double型的
self.w_embed = nn.Embedding(self.vocab_size, self.embed_size).type(torch.float64)
# 中心词bias,每一个词对应一个bias
self.w_bias = nn.Embedding(self.vocab_size, 1).type(torch.float64)
# 周围词向量
self.v_embed = nn.Embedding(self.vocab_size, self.embed_size).type(torch.float64)
# 周围词bias
self.v_bias = nn.Embedding(self.vocab_size, 1).type(torch.float64)
# w_data是batchsize的向量
def forward(self, w_data, v_data, labels): # 必须实现
w_data_embed = self.w_embed(w_data) # batchsize*embedsize
w_data_bias = self.w_bias(w_data) # bs*1
v_data_embed = self.v_embed(v_data) # bs*embed_size
v_data_bias = self.v_bias(v_data) # bs*1
# 生成权重,就是损失函数中的f(x_ij)
weights = torch.pow(labels / self.x_max, self.alpha)
weights[weights > 1] = 1
# 这里最外面可以求和,为了值不要太大,我们用的是mean,对应的就是论文中的损失函数J的公式
loss = torch.mean(weights * torch.pow(torch.sum(w_data_embed * v_data_embed, 1) + w_data_bias + v_data_bias -
torch.log(labels), 2))
return loss
def save_embedding(self, word2id, file_name): # 额外实现,保存词向量到embedding文件夹,其他模型可能是save_model,保存到checkpoint文件夹
embedding_1 = self.w_embed.weight.data.cpu().numpy()
embedding_2 = self.v_embed.weight.data.cpu().numpy()
embedding = (embedding_1 + embedding_2) / 2 # 这里和Word2Vec一样,用中心词和周围词的参数平均作为向量表示并保存
fout = open(file_name, 'w')
fout.write('%d %d\n' % (len(word2id), self.embed_size))
for w, wid in word2id.items():
e = embedding[wid]
e = ' '.join(map(lambda x: str(x), e))
fout.write('%s %s\n' % (w, e))
测试
import numpy as np
import torch
import torch.optim as optim
from tqdm import tqdm
import config as argumentparser
from data import Wiki_Dataset
from model import glove_model
# 导入参数
config = argumentparser.ArgumentParser()
# 判断GPU是否可用
if config.cuda and torch.cuda.is_available():
torch.cuda.set_device(config.gpu)
wiki_dataset = Wiki_Dataset(min_count=config.min_count, window_size=config.window_size)
training_iter = torch.utils.data.DataLoader(dataset=wiki_dataset,
batch_size=config.batch_size,
shuffle=True,
num_workers=2)
# 模型初始化
model = glove_model(len(wiki_dataset.word2id), config.embed_size, config.x_max, config.alpha)
# 根据GPU空闲情况,选择相应的GPU进行计算
if config.cuda and torch.cuda.is_available():
torch.cuda.set_device(config.gpu)
model.cuda()
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate)
loss = -1
for epoch in range(config.epoch):
process_bar = tqdm(training_iter)
# data有两个维度,一个维度是中心词w,一个维度是周围词v
for data, label in process_bar:
w_data = torch.Tensor(np.array([sample[0] for sample in data])).long()
v_data = torch.Tensor(np.array([sample[1] for sample in data])).long()
if config.cuda and torch.cuda.is_available():
torch.cuda.set_device(config.gpu)
w_data = w_data.cuda()
v_data = v_data.cuda()
label = label.cuda()
loss_now = model(w_data, v_data, label)
if loss == -1: # 对损失进行平滑处理
loss = loss_now.data.item()
else:
loss = 0.95 * loss + 0.05 * loss_now.data.item()
process_bar.set_postfix(loss=loss) # 输出loss
process_bar.update() # 梯度更新
optimizer.zero_grad() # 梯度置零
loss_now.backward()
optimizer.step()
model.save_embedding(wiki_dataset.word2id, "./embeddings/result.txt")















 1941
1941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











