







文章目录
部分截图来自原课程视频《2023李宏毅最新生成式AI教程》,B站自行搜索。
用AI运行AI,顾名思义就是使用AI来统筹调用其他AI来解决复杂问题。常见的AI运行AI工具有:
AutoGPT: https://github.com/Significant-Gravitas/Auto-GPT
AgentGPT: https://agentgpt.reworkd.ai
BabyAGl: https://github.com/yoheinakajima/babyagi
Godmode: https://godmode.space/?ref=futuretools.io
这里面推荐使用Godmode,相较其他工具更加友好,可以随时调整执行计划,可以以10分钟为单位分段执行查看执行结果,且不需要魔法上网就可以访问(但需要谷歌或推特账号登录)。
Godmode使用示例
Godmode界面非常简洁,在输入框中输入你要完成的任务,模型就会自动将该任务进行切分:
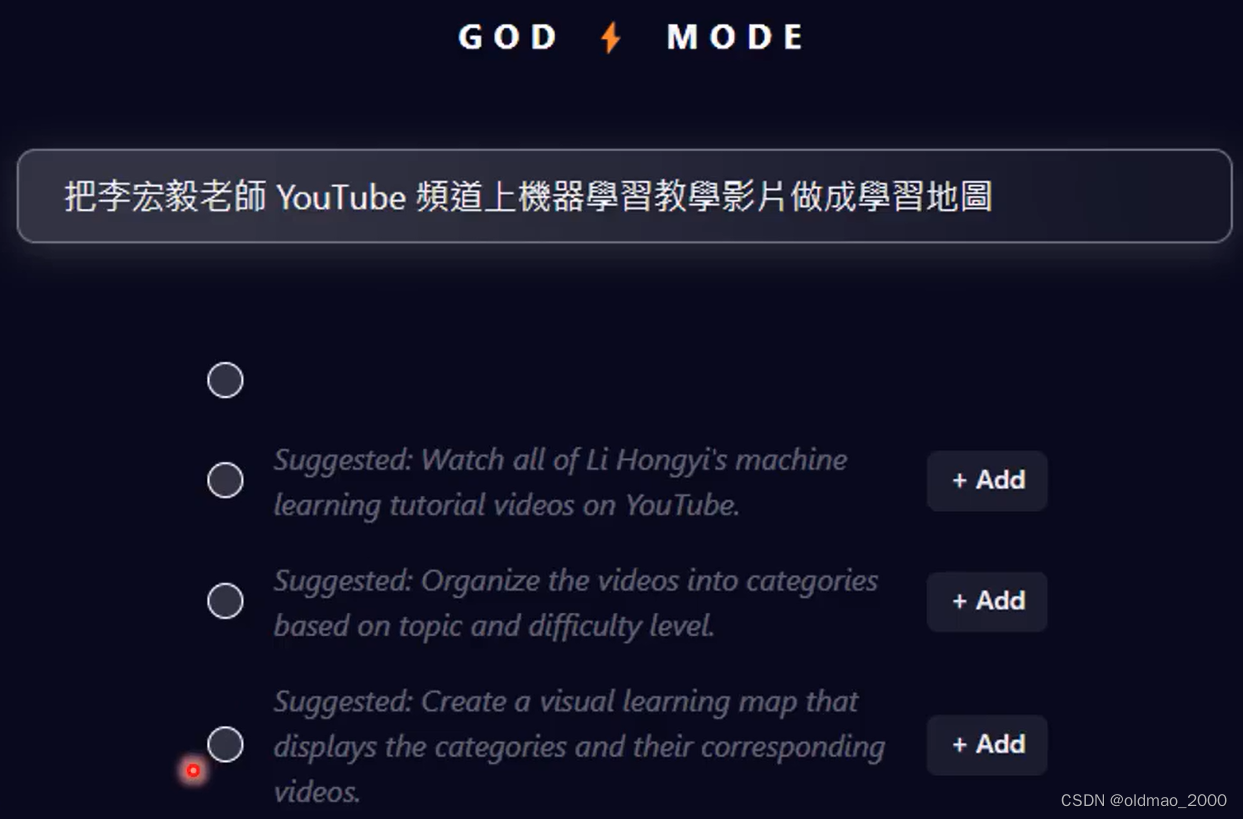
用户可以根据自己的需要决定是否将子任务加入执行清单,当然在后续步骤中还可以对子任务的描述进行修订。将以上子任务都选中,开始执行后,左侧会显示子任务列表,右边显示执行状态:

可以看到,执行状态中会显示模型的执行思路和理由。
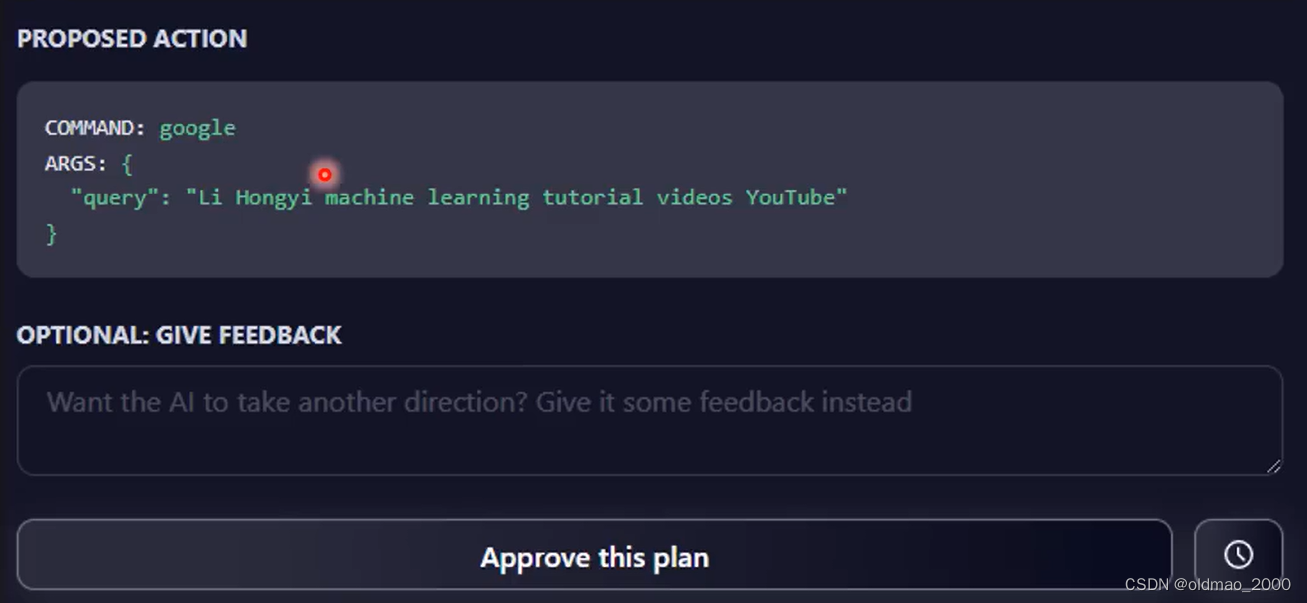
还会有执行的具体指令,可以看到,模型打算使用谷歌在油管上搜索相关视频。再下面可以对指令进行修正,例如将Hongyi改成正确的Hungyi。
下面的【Approve this plan】按钮是开始执行这个子任务,右下角的时钟按钮可以以10分钟为单位来执行这个子任务(按一次执行10分钟)。当然实际上执行效果不一定如你所愿,在上例中模型认为需要先写一个Video summarize的工具,结果写的代码无法执行,一直处于死循环状态。
概念
用AI运行AI就是将要执行的任务进行拆解,得到每个子任务后再来执行,当然每个工具拆解程度不一样,Godmode如下图所示,只拆解一次,而AutoGPT会将子任务继续拆分,这样做虽然可执行性会变高,但是拆解的任务会有重复,则会陷入循环之中。
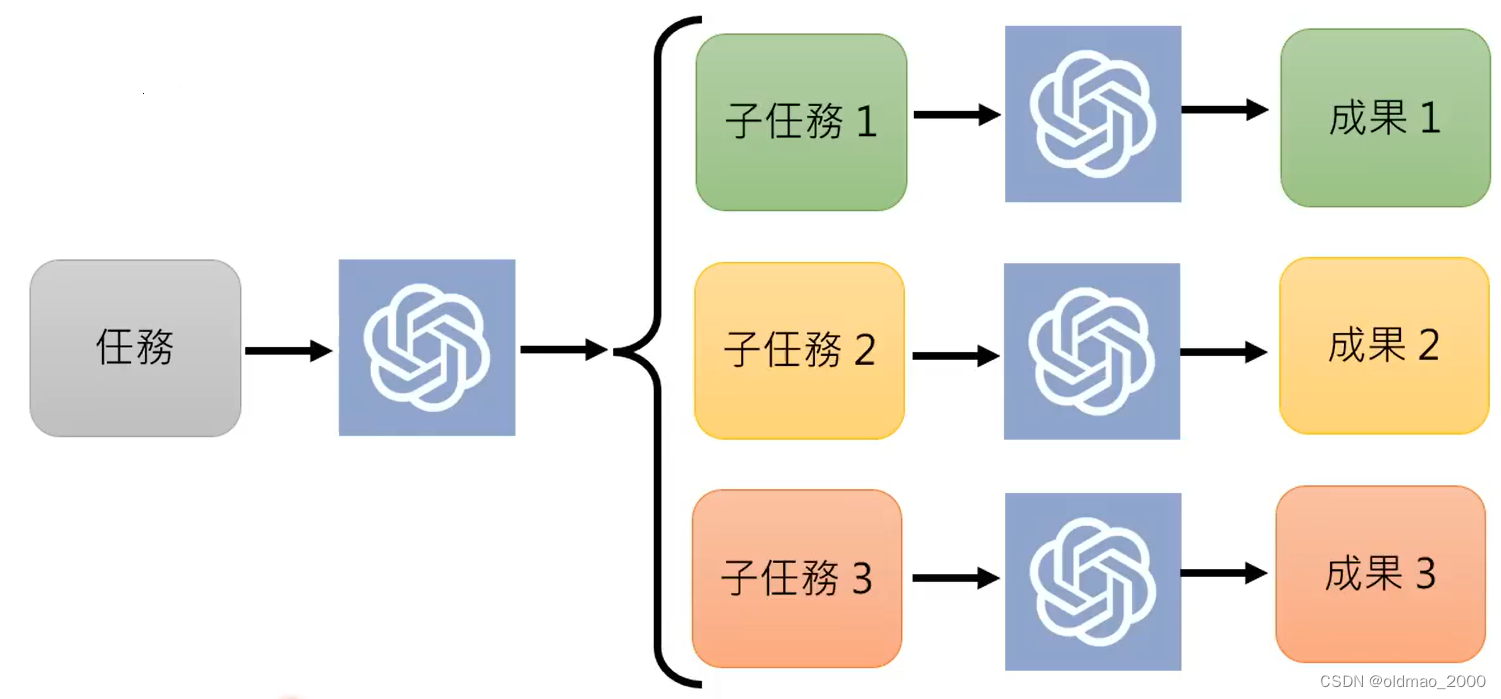
当然,用AI运行AI有不同的实现方式,下面通过几篇论文来讲解他们的思路。
Recursive Reprompting and Revision(Re3)
注:应该是
Re
3
\text{Re}^3
Re3
这个模型主要用于完成故事的编写。文章本身只有10来页,但是后面的故事示例就长得离谱,共计有86页。模型总体思路如下:
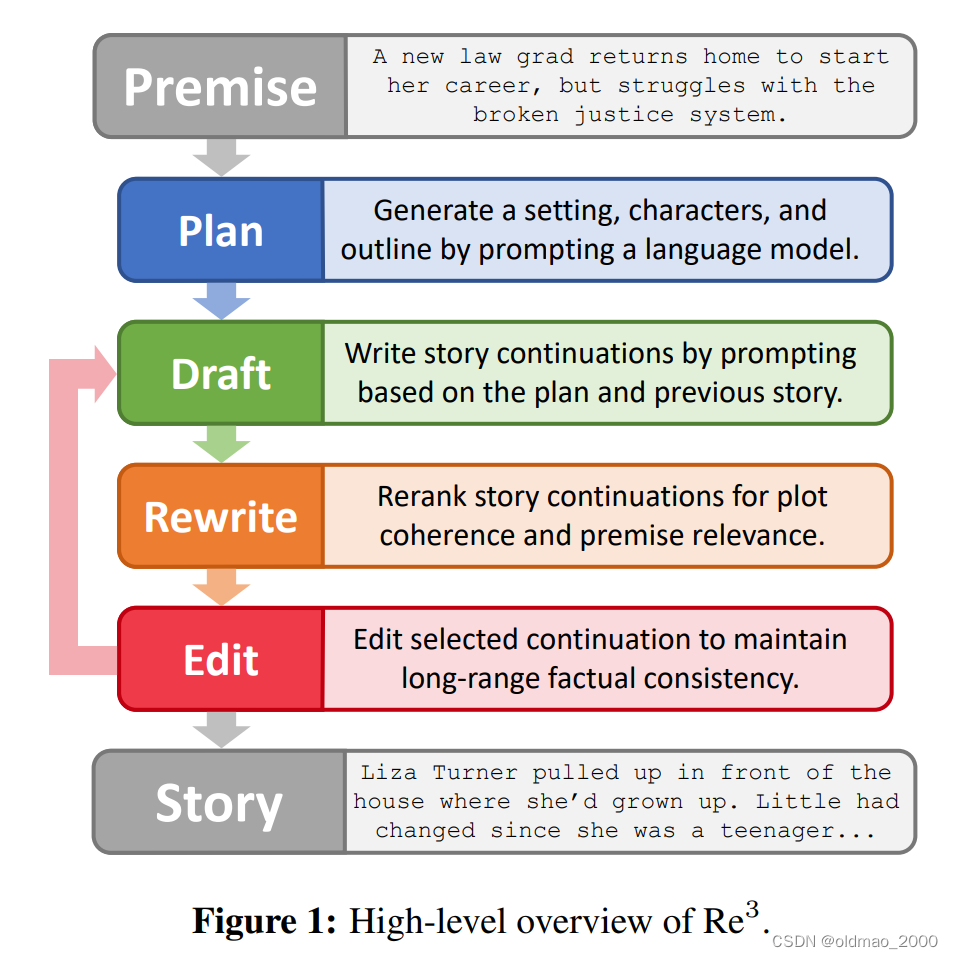
先是给出故事发生的情境(Premise)
然后模型要给出计划(Plan),主要包括:地点、人物(名字、年龄,人物关系等)、故事大纲等。

然后根据故事大纲,每一点都按Draft,Rewrite,Edit的步骤走一遍。Draft是写草稿:
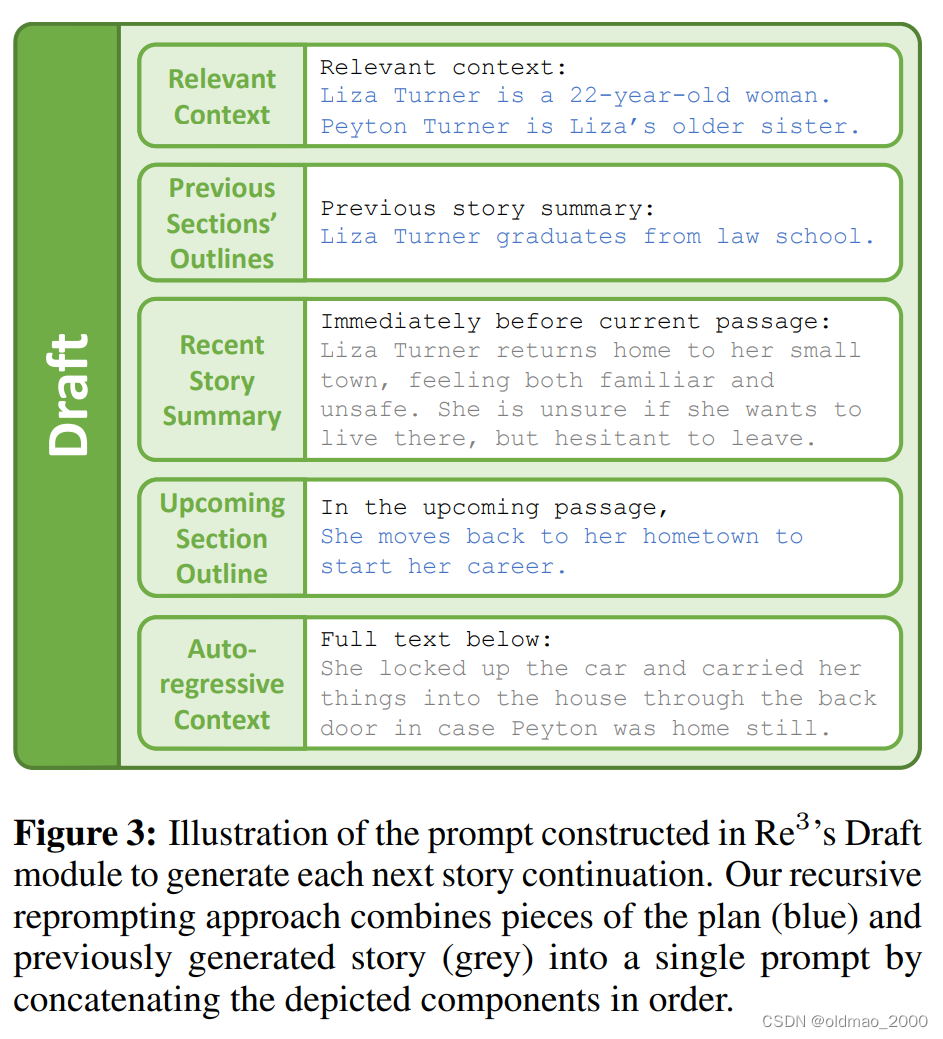
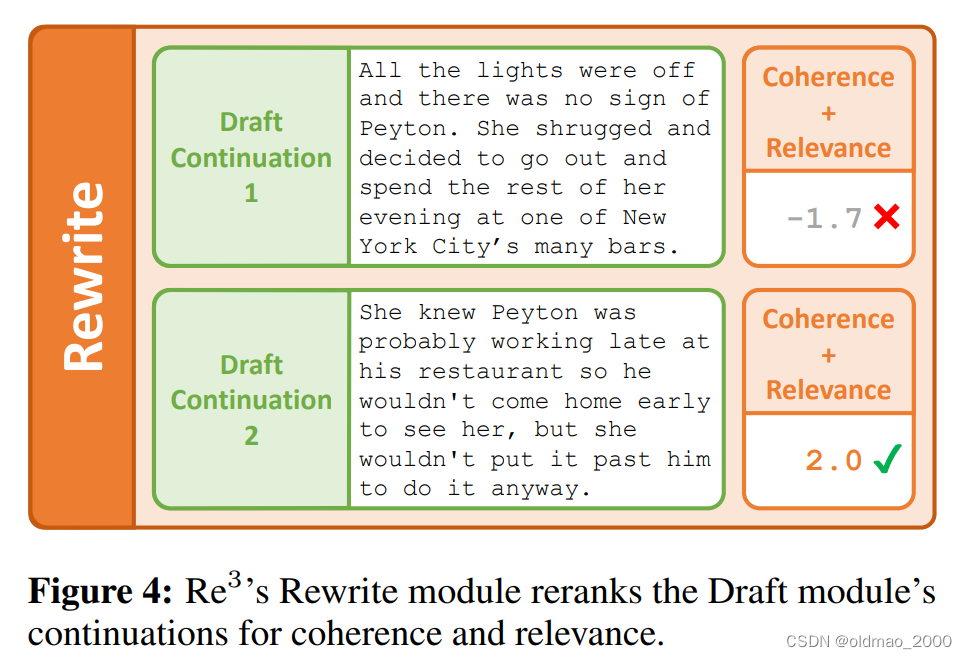
Rewrite主要保证草稿要有一定的连贯性和相关性。
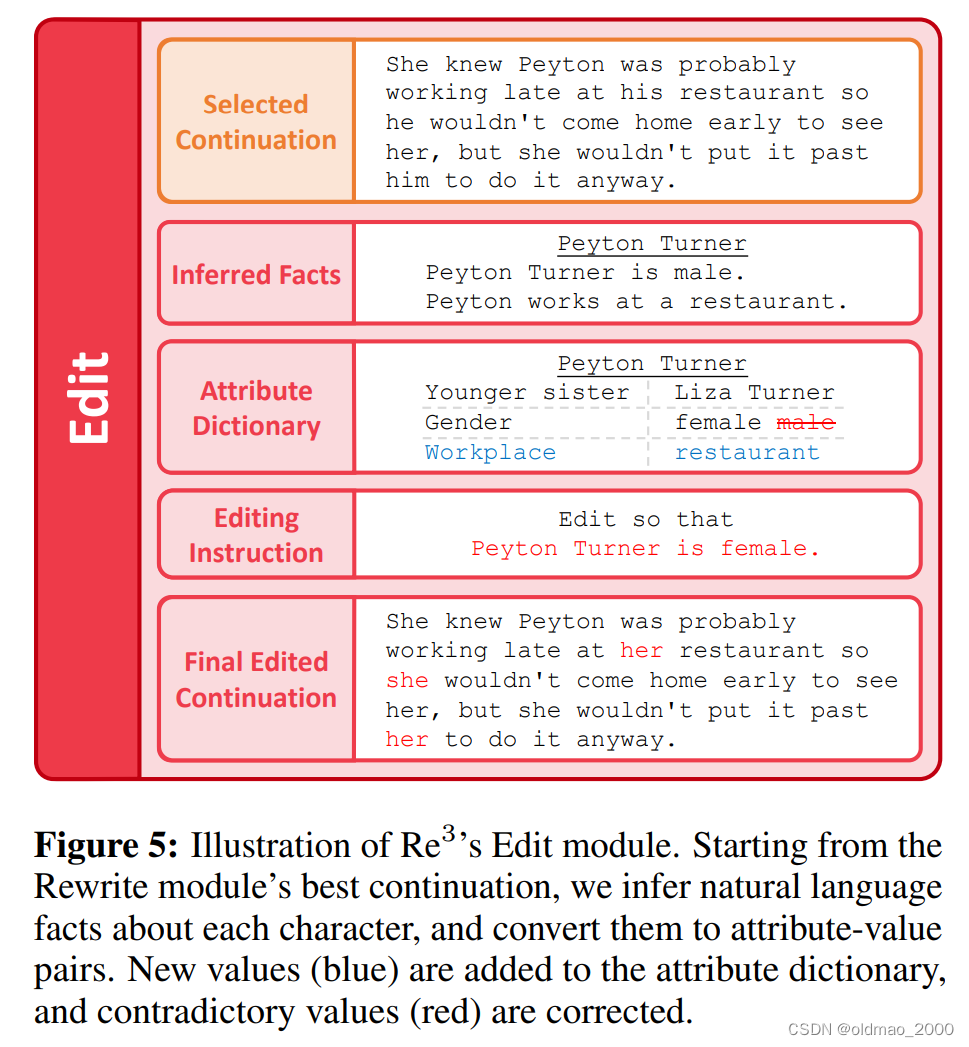
Edit将草稿的内容与Plan中的设定做一些比较,查看是否出现偏差,例如性别、姓名之类的。当然还要保证整体连贯性。
Language Models as Zero-Shot Planners
这是一篇来自UC伯克利的文章:Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents

主要是让语言模型与虚拟世界的人物角色进行交互,上图中下达的指令为:获取一杯牛奶。这里涉及到两个难点:
1.如何自动根据大任务规划一系列子任务;
2.如何把子任务对应到可执行的动作。
模型整体框架如下:

第一步:动作规划
动作规划直接用LLM来完成,如上图左侧所示,先给出一个示例,告诉模型刮胡子分三个步骤,然后让大模型生成擦乳液需要什么步骤。下图给出了一些大模型生成步骤的例子:

当时GPT-3是最新的大模型,图中GPT-2表现最差,只生成了一个步骤就over了。
第二步:翻译步骤
由于生成的步骤在虚拟世界中不一定能够识别,因此需要进行将其翻译成虚拟角色可以识别的指令。做法很简单,就是将虚拟角色可以执行的指令全部列出来,将生成的步骤与指令列表做匹配 ,挑选相似度最高的来执行。例如框架图中的例子生成的步骤为:
Step 1: Squeeze out a glob of lotion
匹配到的指令为:
Step 1: Pour lotion into right hand
实验结果如下:
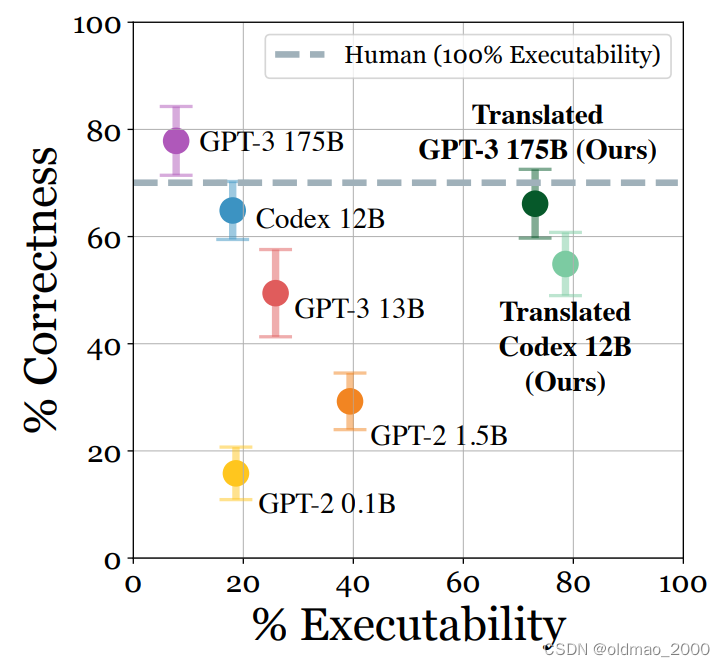
纵轴是步骤的正确性,横轴是步骤的可执行性。
步骤的正确性上GPT-3已经超过了人类灰色虚线,但其可执行性不行。
经过翻译后(实际上是匹配指令列表)的Translated GPT-3在正确性上有小许下界,但可执行性大大提高。
HuggingGPT
浙大的文章(但是严格说是微软的东东):HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
看文章题目就知道挺有意思。整体框架如下:

大体路线也是分解任务,执行任务,得到结果,但是在执行任务这块,这里使用了HuggingFace的外挂模型来帮忙,所以多了Model Selection这个步骤。
例子:

任务是:Please generate an image where a girl is reading a book, and her pose is the same as the boy in the image example.jpg, then please describe the new image with your voice.
一看这个任务就是精心设计的,分别涉及到人体姿势识别,图片生成,语音生成等子任务。
第一步:计划任务
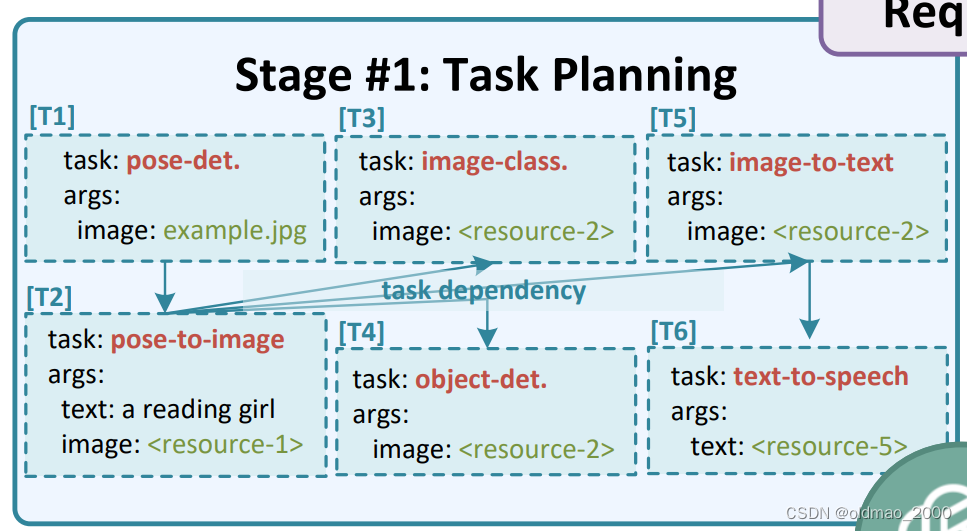
从图中可以看到,每个子任务都有任务和参数,如子任务T1要做的是姿势检测,参数是example.jpg。
当然这些子任务不一定合理,例如T3和T4其实没有必要。
第二步:选择模型
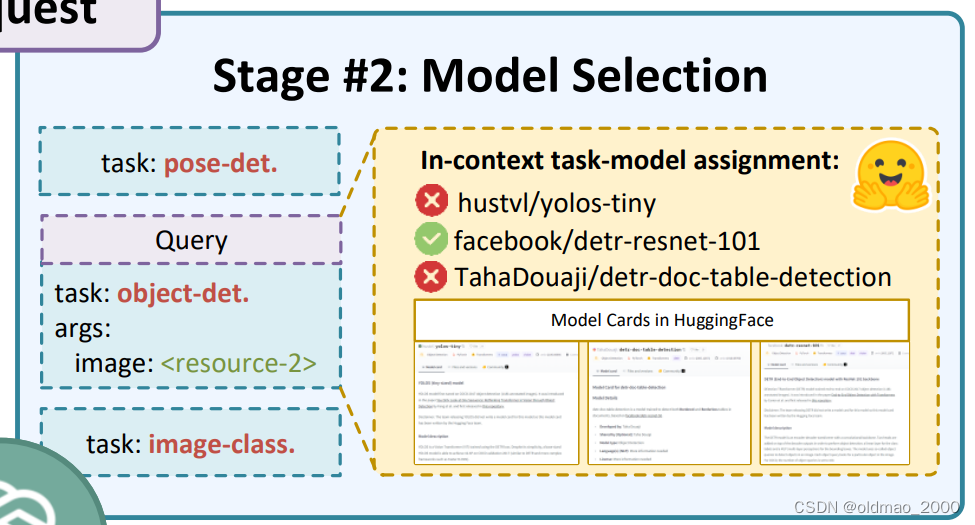
先从HuggingFace找一系列候选模型,这些模型都会有Model Cards来进行描述。然后就是可以根据任务Query来匹配具体的模型。
第三步:执行任务
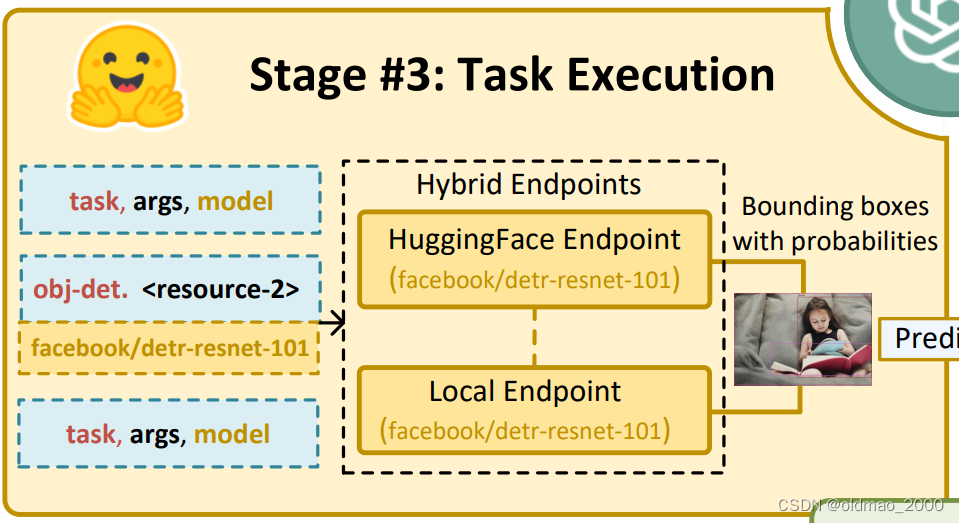
第四步:生成回答

将每个子任务的结果进行总结,让GPT生成最后的回答。

Language models can solve computer tasks
来自加州大学的文章:Language Models can Solve Computer Tasks,用语言模型来控制我们的电脑。

上图给出了很多例子,例如让鼠标点击灰色按钮,点赞,查询指定内容并选择某个查询结果,等等。
当然模型不可能像人一样用眼睛看屏幕,模型得到的输入是一个网页的HTML代码。模型的输出是控制鼠标、键盘完成相应动作。这里面涉及到控制鼠标、键盘的代码是用MiniWoB++(Mini World of Bits++)完成的。
从动作到具体鼠标键盘的指令是根据一段冗长的Prompt得到的(具体看原文的附录D):

例子:
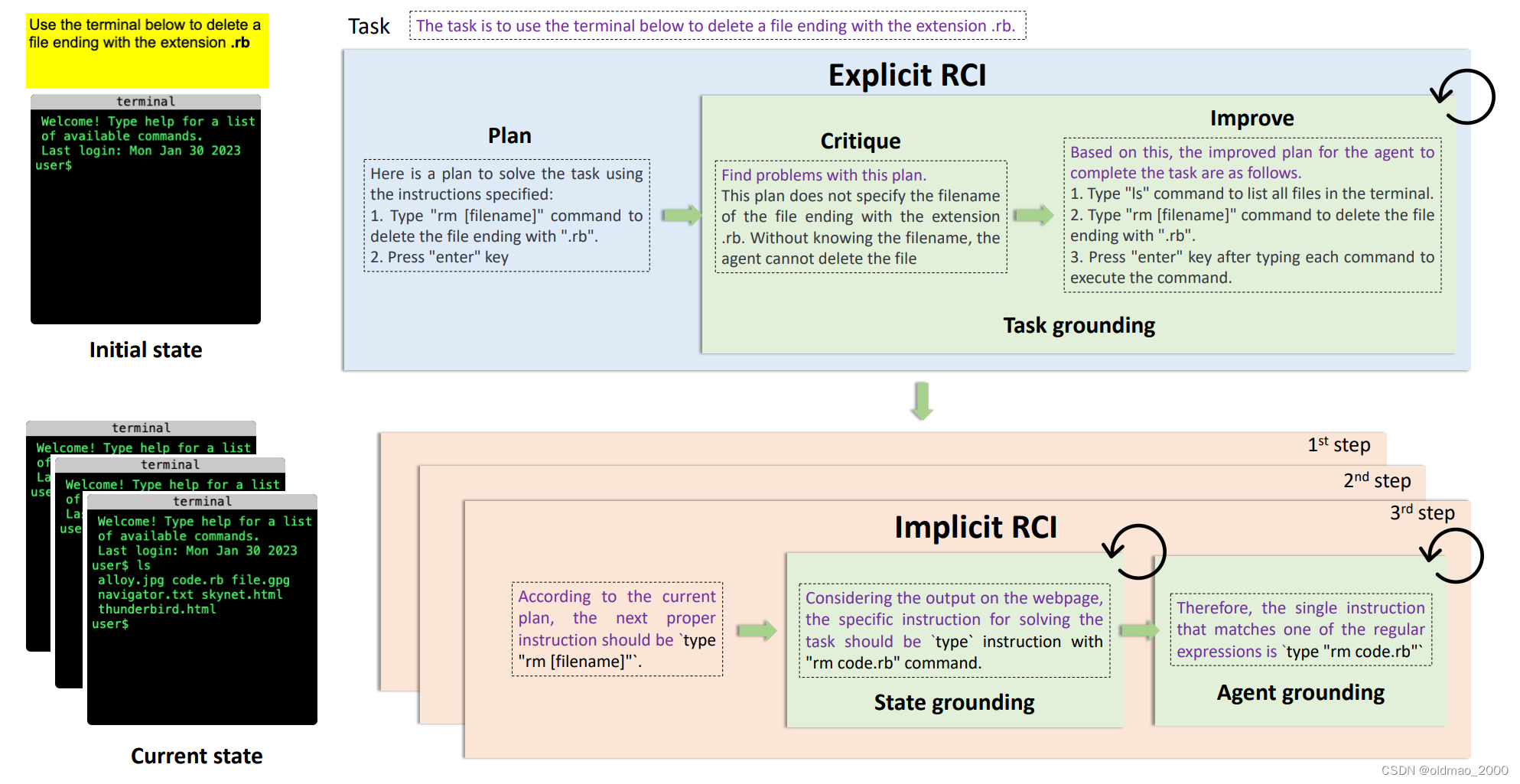
任务是要使用终端删除一个后缀为.rb的文件。
第一步:计划。模型给出的计划是:
Here is a plan to solve the task using the instructions specified:
- Type “rm [filename]” command to delete the file ending with “.rb”.
- Press “enter” key
第二步:反省(这个步骤前面的模型都没有)。自己给自己下Prompt:Find problems with this plan. 得到如下结果:
This plan does not specify the filename of the file ending with the extension .rb. Without knowing the filename, the agent cannot delete the file.
可以看到,模型找到bug,要有文件名才能删除文件
第三步:改进。自己给自己下Prompt:Based on this, the improved plan for the agent to complete the task are as follows.
- Type “ls” command to list all files in the terminal.
- Type “rm [filename]” command to delete the file ending with “.rb”.
- Press “enter” key after typing each command to execute the command.
可以看到,这里加了一个步骤,就是先用ls查看有哪些文件。
到这里任务分解完成,但是分解后的子任务不一定能够执行,因此就进入下面粉色框框的内容。
这里是以改进结果的步骤2进行举例:
第一步:先问模型要干嘛
According to the current plan, the next proper
instruction should be
‘type "rm [filename]"‘.
\text{According to the current plan, the next proper }\\ \text{instruction should be } \color{red}\text{`type "rm [filename]"`.}
According to the current plan, the next proper instruction should be ‘type "rm [filename]"‘.
第二步:根据当前的状态,判断要做的事情,获得State grounding
Considering the output on the webpage,
the specific instruction for solving the task should be
‘type‘ instruction with "rm code.rb" command
\text{Considering the output on the webpage, }\\ \text{the specific instruction for solving the task should be}\\ \color{red}\text{`type` instruction with "rm code.rb" command}
Considering the output on the webpage, the specific instruction for solving the task should be‘type‘ instruction with "rm code.rb" command
第三步:生成具体可以执行的指令,获得Agent grounding
Therefore, the single instruction that matches
one of the regular expressions is
‘type "rm code.rb"‘
\text{Therefore, the single instruction that matches}\\ \text{one of the regular expressions is } \color{red}\text{`type "rm code.rb"`}
Therefore, the single instruction that matchesone of the regular expressions is ‘type "rm code.rb"‘
可以看到,这个模型更加精致,不再像前面早期的模型在指令翻译上采用的匹配指令的方式。















 898
898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











