







文章目录
公式输入请参考: 在线Latex公式
·什么是NLP?
NLP=NLU+NLG
·NLU(Nature language understanding):语音/文本一>意思(meaning),这个是下面NLG的基础。
·NLG(Nature language generation):意思一>文本/语音
现在的问题:
1、Multiple Ways to Express(多种表达方式)
例如:
这个训练营还不坏。
这个训练营还不错。
2、Ambiguity(一词多义)
今天参观了苹果公司
现在正好是苹果季节
How to Solve Ambiguity?
第一种按统计,例如A词有三个意思X,Y,Z。那么在一个文章里面X意思出现7次,Y意思出现2次,Z意思出现1次,那么当出现A词的时候,我们按照统计的结果去猜这个词的意思。
第二种就是根据上下文context来判断。
Case Study:Machine Translation
根据统计信息,例如要翻译这句话:
farok crrrok hihok yorok clok kantok ok-yurp
我们有如下语料:
1a.ok-voon ororok sprok.
1b.at-voon bichat dat.
2a.ok-drubel ok-voon anok plok sprok.
2b.at-drubel at-voon pippat rrat dat.
3a.erok sprok izok hihok ghirok.
3b.totat dat arrat vat hilat.
4a.ok-voon anok drok brok jok.
4b.at-voon krat pippat sat lat.
5a.wiwok farok izok stok.
5b.totat jat quat cat.
6a.lalok sprok izok jok stok.
6b.wat dat krat quat cat.
7a.lalok farok ororok lalok sprok izok enemok.
7b.wat jjat bichat wat dat vat eneat.
8a.lalok brok anok plok nok.
8b.iat lat pippat rrat nnat.
9a.wiwok nok izok kantolk ok-yurp.
9b.totat nnat quat oloat at-yurp.
10a.lalok mok nok yorok ghirok clok.
10b.wat nnat gat mat bat hilat.
11a.lalok nok crrrok hihok yorok zanzanok.
11b.wat nnat arrat mat zanzanat.
12a.lalok rarok nok izok hihok mok.
12b.wat nnat forat arrat vat gat.
通过语料就可以找到每个单词对应的翻译
用算法来实现这个统计的过程就是模型,他吃进去语料,吐出来每个词对应的意思。
但是这个方法有很大缺陷:
- 慢(这个可以改进模型来解决)
- 没有考虑一词多义
- 没有结合上下文
- 没有考虑语法What a lovely day! 用统计方法翻译就是什么一个可爱的白天。
- 统计规则需要大量work
针对第四个缺点,下面看一个模型例子如何解决:
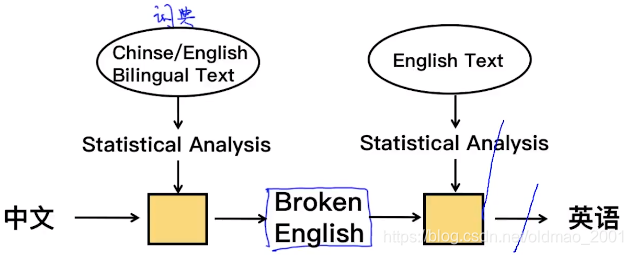
输入的语句为:
今晚的课程有意思
经过分词:{今晚 | 的 | 课程 | 有意思}
得到的集合就是上图中的词典
然后丢到我们之前提到的直接翻译的模型里面(就是上图中左边的黄色方块,称为translation model)得到:
tonight,of,course,interesting
由于忽略了语法,想要加上语法咋整?把翻译结果排列组合,求概率最大那个组合(这里应该是概率分布,累加概率为1)
tonight,the course,interesting,of
tonight,interesting,of,the course
of,the course,tonight,interesting
of,tonight,interesting,the course
of,interesting,the course,tonight
the course,of,interesting,tonight
the course,of,tonight,interesting这个组合就不错。
the course,tonight,of,interesting
the course,interesting,tonight,of
the course,interesting,of,tonight
4个单词的组合有
4
!
4!
4!种。如果有n个单词,光排列组合算法就是n的阶乘种可能,复杂度就是(
O
(
2
n
)
O(2^n)
O(2n)),这个是不可能玩的(NP hard的问题)。
上面把排列组合经过概率计算得到翻译的黄色方块就是language model简称LM。
下面我们把模型中的两个黄色方块进行合并。合并考虑的依据如下:
翻译的数学描述是:
把中文记为
C
C
C,把英文记为
E
E
E,翻译的目标就是求在给定中文
C
C
C的条件下,翻译为英文
E
E
E的最大概率:
E
=
a
r
g
m
a
x
e
P
(
e
∣
c
)
E=arg\underset{e}{max}P(e|c)
E=argemaxP(e∣c)
根据贝叶斯概率公式
P
(
A
∣
B
)
=
P
(
B
∣
A
)
P
(
A
)
P
(
B
)
P(A|B)=\cfrac{P(B|A)P(A)}{P(B)}
P(A∣B)=P(B)P(B∣A)P(A)可知:
E
=
a
r
g
max
e
P
(
e
∣
c
)
=
a
r
g
max
e
P
(
c
∣
e
)
P
(
e
)
P
(
c
)
E=arg\underset{e}{\max}P(e|c)=arg\underset{e}{\max}\cfrac{P(c|e)P(e)}{P(c)}
E=argemaxP(e∣c)=argemaxP(c)P(c∣e)P(e)
由于翻译前后都是基于
P
(
c
)
P(c)
P(c),所以分母可以算是一个常量,对于求最大值没有影响,可以拿掉:
E
=
a
r
g
max
e
P
(
c
∣
e
)
P
(
e
)
E=arg\underset{e}{\max}P(c|e)P(e)
E=argemaxP(c∣e)P(e)
P
(
c
∣
e
)
P(c|e)
P(c∣e)就是对应之前的翻译模型(translation model),
P
(
e
)
P(e)
P(e)就是对应的后面的语言模型(language model)
a
r
g
max
e
P
(
c
∣
e
)
P
(
e
)
arg\underset{e}{\max}P(c|e)P(e)
argemaxP(c∣e)P(e)就是合并起来的模型拉。
算这个玩意有个动态规划算法,就是李宏毅笔记struct learning里面最后一课提到过的维特比算法。
小结
- 语言模型(Language Model),用来判断是否符合语法规则,是不是人话。这个模型是提前建立起来的。
·给定一句英文e,计算概率(e)
·如果是符合英文语法的, P ( e ) P(e) P(e)会高
·如果是随机语句, P ( e ) P(e) P(e)会低 - 翻译模型,就像是词典,给一个原文,得到一个翻译后的结果。
·给定一对<c,e>,计算 P ( c ∣ e ) P(c|e) P(c∣e)
·语义相似度高,则 P ( c ∣ e ) P(c|e) P(c∣e)高
·语义相似度低,则 P ( c ∣ e ) P(c|e) P(c∣e)低 - Decoding Algorithm
·给定语言模型,翻译模型和c,找出最优的使得 P ( c ∣ e ) P ( e ) P(c|e)P(e) P(c∣e)P(e)最大
这里使用的维特比算法,作用就是将原来计算复杂度为 O ( 2 n ) O(2^n) O(2n),简化为 n p n^p np。
Language Model(语言模型)
·对于一个好的语言模型:(这个模型是预先训练好的,直接可以拿来进行判断)
p
(
He is studying AI
)
>
p
(
He studying AI is
)
p(\text{He is studying AI})>p(\text{He studying AI is})
p(He is studying AI)>p(He studying AI is)
p
(
nlp is an interesting course
)
>
p
(
interesting course nlp is an
)
p(\text{nlp is an interesting course})>p(\text{interesting course nlp is an})
p(nlp is an interesting course)>p(interesting course nlp is an)
下面看看如何计算这个概率p
把每个单词看做一个独立变量。
如果x和y独立,他们的联合概率为:
p
(
x
,
y
)
=
p
(
x
)
p
(
y
)
p(x,y)=p(x)p(y)
p(x,y)=p(x)p(y)
把每个单词看做有关系的变量
如果x和y不独立,他们的联合概率为:
p
(
x
,
y
)
=
p
(
x
)
p
(
y
∣
x
)
或
者
p
(
x
,
y
)
=
p
(
y
)
p
(
x
∣
y
)
p(x,y)=p(x)p(y|x)或者p(x,y)=p(y)p(x|y)
p(x,y)=p(x)p(y∣x)或者p(x,y)=p(y)p(x∣y)
所以有下面的推导。
第一种unigram模型:
p
(
He is studying AI
)
=
p
(
H
e
)
p
(
i
s
)
p
(
s
t
u
d
y
i
n
g
)
p
(
A
I
)
p(\text{He is studying AI})=p(He)p(is)p(studying)p(AI)
p(He is studying AI)=p(He)p(is)p(studying)p(AI)
第二种bigram模型:
p
(
He is studying AI
)
=
p
(
H
e
)
p
(
i
s
∣
H
e
)
p
(
s
t
u
d
y
i
n
g
∣
i
s
)
p
(
A
I
∣
s
t
u
d
y
i
n
g
)
p(\text{He is studying AI})=p(He)p(is|He)p(studying | is)p(AI | studying)
p(He is studying AI)=p(He)p(is∣He)p(studying∣is)p(AI∣studying)
第三种trigram模型:
p
(
He is studying AI
)
=
p
(
H
e
)
p
(
i
s
∣
H
e
)
p
(
s
t
u
d
y
i
n
g
∣
h
e
i
s
)
p
(
A
I
∣
i
s
s
t
u
d
y
i
n
g
)
p(\text{He is studying AI})=p(He)p(is | He)p(studying | he\space is)p(AI | is\space studying)
p(He is studying AI)=p(He)p(is∣He)p(studying∣he is)p(AI∣is studying)
类似,可以定义Ngram模型,具体可以看paper带读里面有相关论文。
语言模型就是要训练计算出右边每个元素的概率,例如:
p
(
H
e
)
p(He)
p(He)
p
(
i
s
∣
H
e
)
p(is|He)
p(is∣He)
联合概率(joint probability)的推导:
p
(
x
1
,
x
2
,
x
3
,
x
4
)
=
p
(
x
1
)
p
(
x
2
∣
x
1
)
p
(
x
3
∣
x
1
x
2
)
p
(
x
4
∣
x
1
x
2
x
3
)
(1)
p(x_1,x_2,x_3,x_4)\\ =p(x_1)p(x_2|x_1)p(x_3|x_1x_2)p(x_4|x_1x_2x_3)\tag1
p(x1,x2,x3,x4)=p(x1)p(x2∣x1)p(x3∣x1x2)p(x4∣x1x2x3)(1)
由于
p
(
x
1
,
x
2
)
=
p
(
x
1
)
p
(
x
2
∣
x
1
)
p(x_1,x_2)=p(x_1)p(x_2|x_1)
p(x1,x2)=p(x1)p(x2∣x1)
所以公式1中的前面两项可以简化为:
p
(
x
1
,
x
2
)
p(x_1,x_2)
p(x1,x2)
(
1
)
=
p
(
x
1
,
x
2
)
p
(
x
3
∣
x
1
x
2
)
p
(
x
4
∣
x
1
x
2
x
3
)
(1)=p(x_1,x_2)p(x_3|x_1x_2)p(x_4|x_1x_2x_3)
(1)=p(x1,x2)p(x3∣x1x2)p(x4∣x1x2x3)
这里把
x
1
,
x
2
x_1,x_2
x1,x2看做一个整体,带入公式(1),前面两项可以化简为:
p
(
x
1
,
x
2
,
x
3
)
p(x_1,x_2,x_3)
p(x1,x2,x3)
(
1
)
=
p
(
x
1
,
x
2
,
x
3
)
p
(
x
4
∣
x
1
x
2
x
3
)
(1)=p(x_1,x_2,x_3)p(x_4|x_1x_2x_3)
(1)=p(x1,x2,x3)p(x4∣x1x2x3)
同理,上式:
=
p
(
x
1
,
x
2
,
x
3
,
x
4
)
=p(x_1,x_2,x_3,x_4)
=p(x1,x2,x3,x4)
公式(1)得证。
unigram模型,不考虑条件概率:
p
(
x
1
,
x
2
,
x
3
,
x
4
)
=
p
(
x
1
)
p
(
x
2
)
p
(
x
3
)
p
(
x
4
)
p(x_1,x_2,x_3,x_4)=p(x_1)p(x_2)p(x_3)p(x_4)
p(x1,x2,x3,x4)=p(x1)p(x2)p(x3)p(x4)
bigram模型,只考虑前一个单词的条件概率:
p
(
x
1
,
x
2
,
x
3
,
x
4
)
=
p
(
x
1
)
p
(
x
2
∣
x
1
)
p
(
x
3
∣
x
2
)
p
(
x
4
∣
x
3
)
p(x_1,x_2,x_3,x_4)=p(x_1)p(x_2|x_1)p(x_3|x_2)p(x_4|x_3)
p(x1,x2,x3,x4)=p(x1)p(x2∣x1)p(x3∣x2)p(x4∣x3)
trigram模型,只考虑前两个单词的条件概率:
p
(
x
1
,
x
2
,
x
3
,
x
4
)
=
p
(
x
1
)
p
(
x
2
∣
x
1
)
p
(
x
3
∣
x
1
x
2
)
p
(
x
4
∣
x
2
x
3
)
p(x_1,x_2,x_3,x_4)=p(x_1)p(x_2|x_1)p(x_3|x_1x_2)p(x_4|x_2x_3)
p(x1,x2,x3,x4)=p(x1)p(x2∣x1)p(x3∣x1x2)p(x4∣x2x3)
可以看到这些模型都对原版的模型取了一些近似(考虑前n个单词,考虑越少越好算),因为条件概率真心不好算,这些近似的根据就是马尔科夫假设。
·NLP的应用场景
Question Answering(问答系统)
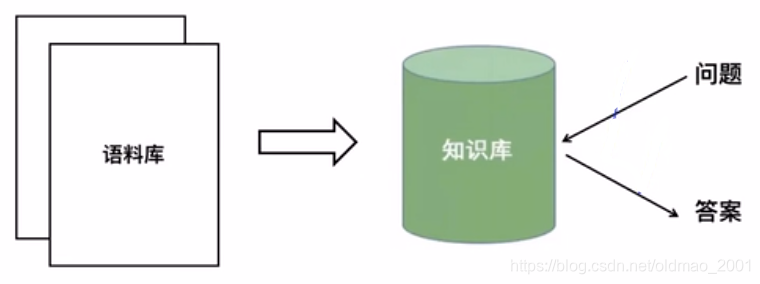
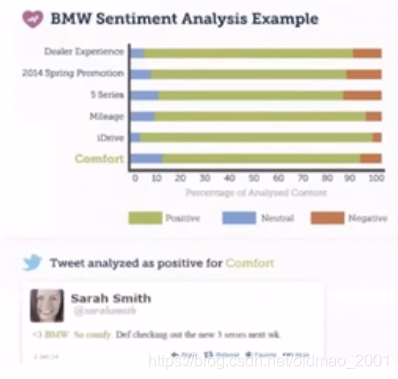
Sentiment Analysis(情感分析)
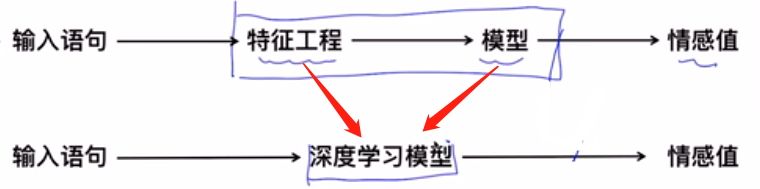
可以把上面的两个用深度学习模型替代
其他
·股票价格预测
·舆情监控
·产品评论
·事件监测
chatbot
Text Summarization(自动摘要)
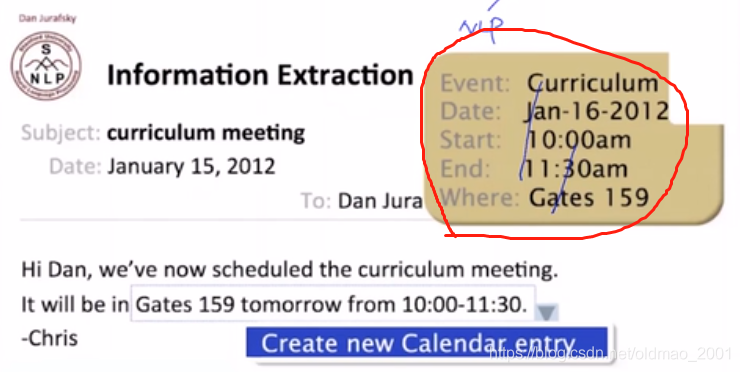
Information Extraction(信息抽取)
红圈里面就是抽取邮件的结果。
NLP领域关键技术
自然语言处理技术四个维度
从下到上:
Semantic(语义):最终目标
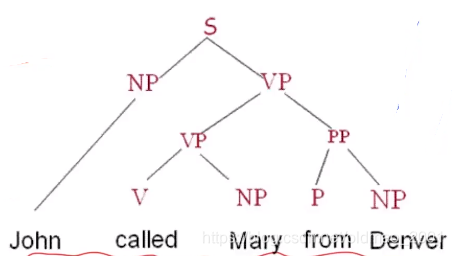
Syntax(句子结构):Parsing句法分析(主谓宾),依存分析(单词之间的关系)
句法分析例子:
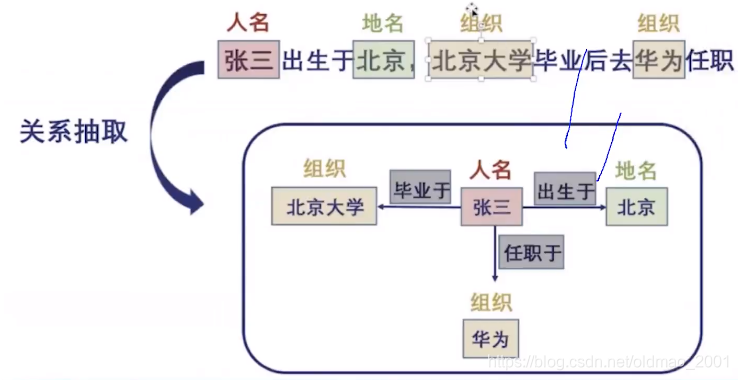
Relation Extraction(关系抽取)例子:
Morphology(单词):单词层面的技术:Word Segmentation分词、POS(Part-of-Speech词性分析)、Named Entity Recognition(命名实体识别)
Phonetics(声音):语音识别之类的,这里不做介绍,可以看下李宏毅2020的新课
https://www.quora.com/What-are-the-major-open-problems-in-natural-language-understanding


















 939
939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











