







文章目录
前言
从为什么用CNN来处理图像开始进行分析,然后得出三个重要原因,然后 分析了CNN的构架,然后从构架分析了对应的原因,最后用Keras来实践构建CNN网络进行训练。
在线Latex公式
为什么要用CNN来处理图像?
可以用上节课的知识直接构建fully connected神经网络来进行训练,例如做图像分类:

每一层都是不同的分类器,前面的分类器做的事情会基础一些,例如第一个蓝色神经元判断是不是又绿色,第二蓝色神经元判断是不是又橙色,橙色神经元判断条纹类型。
问题是如果我们使用fully connected神经网络来进行图像分类,往往需要很多参数,举个栗子,上面的猫咪图片分辨率大小是100100的,每个分辨率用RGB表示,拉伸为vector后就变成1001003个,就是有3万个输入,第一层蓝色如果有1000个神经元,那么需要调整的参数就变成10010031000。
重点:CNN做的事情就是简化神经网络的架构。So,CNN is simpler than DNN. 我们使用pre knowledge把DNN中的一些神经元拿掉。
为什么CNN可以去掉一些神经元后仍然可以工作?
第一个原因
如下图所示,有些特征是不需要看整张图片才能判断,例如鸟嘴(应该叫:喙hui)只要看红色框区域就ok了

第二个原因
同样的特征(原文是pattern,翻译为特征不知道是否正确,硬翻应该是模式)可能出现在图片的不同位置,不需要分别针对不同位置的特征进行训练,可以减少参数的量。原话是:太冗了

第三个原因
Subsampling(这里也不能硬翻成缩放)百度了一下可以翻成:子抽样; 下采样; 子采样; 分段抽样; 二次抽样;
Subsampling不改变图片中的目标,进行Subsampling可以减小图片大小,从而使得网络的参数减少。

CNN长什么样?
前面的convolution 和Max Pooling可以重复很多次,然后接Flatten,然后再接Fully Connected的神经网络,最后输出类别。

上一小节提到了三个原因,convolution 处理的是前面两个原因,Max Pooling处理第三个原因。

Convolution
先来看convolution操作,如下图所示,左边是我们要识别的图像,右边的是Filter,内含一个Matrix,实际上对应的就是神经网络的一个神经元,Matrix里面的每一个数字都是需要学习的参数,就相当于神经元需要训练的
w
w
w和
b
b
b。Matrix是要用来干什么,学习什么特征都是训练出来的。

注意:每个matrix都能检测3×3的特征(不用看整张图),这个和第一个原因对应。
接下来看filter与图像的操作,以Filter1为例,先从图像的左上角开始,把图像的3×3的9个值与Filter1的9个值做内积。这里求出来是:3
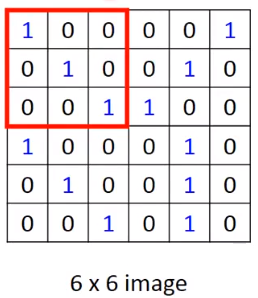
然后把红色框往右边挪动一下,挪动的距离学名叫:stride,这个值要自己设置。
如果stride=1,那么内积秒算:-1
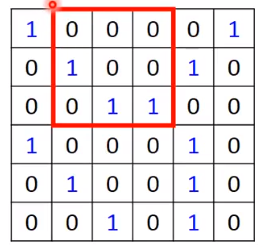
如果stride=2,那么内积秒算:-3

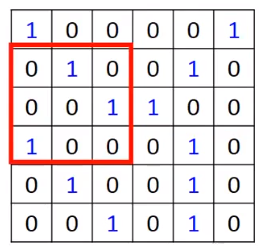
现在使用stride=1进行操作,前面三行覆盖完成后可以得到:
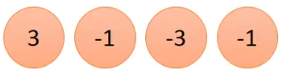
然后往下一行,在进行内积操作:
以此类推,最后可以得到的内积放一起就是这样:

经过convolution的操作,图片6×6大小的向量就变为4×4的了,而且这个4×4的矩阵(暂时叫这个名)还包含了Filter1提取出来的特征信息,因为Filter1要提取的特征就是↘方向都为1的特征:
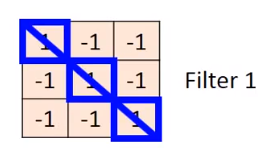
从图像上看,有两个地方满足这个条件(蓝色斜线部分),在4×4的矩阵里面就是3,这里的原理对于上一小节的第二个原因(同一个神经元可以在不同地方检测出特征,不用不同的Filter来干这个事情)。

当然,我们还有很多个Filter,例如:
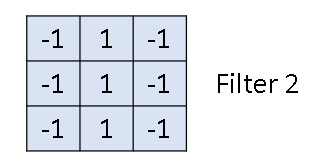
它们都做convolution操作:

上面橙色和蓝色的4×4的矩阵合起来就称为:Feature Map
学生提问
问题:鸟嘴在不同图片里面大小不一样,我们在做convolution操作的Filter大小是事先固定的,那么如何处理?
如果提前知道鸟嘴大小的比例(这个当然不可能),可以归一化解决。
某学术文章里面有解决方案,在CNN前面再接一个NN,NN输出一些scalar用于处理图片的哪些位置需要旋转、缩放,这样得到的效果更好(这不就是和数据增强的思想一样吗)。
彩色图片的处理
彩色图片比上面的例子要复杂,RGB有三个chanel,这个时候的Filter也设置成三个(层),同时对RGB进行处理。(这里讲的有点错,看了CS231n后明白了,无论你的输入图片有几个channel,和一个filter进行convolution操作后,dimension就是1,filter有几个dimension就有几个。)

Convolution v.s. Fully Connected
上面讲CNN的convolution操作貌似和Fully Connected神经网络没有什么关系,其实不然。
重点:convolution就是Fully Connected神经网络中的输入权重+隐藏层,且把其中的一些权重拿掉的结果;Feature Map相当于隐藏层的输出。
接下来是整节课最精彩的部分,老师的ppt也花了很多功夫。

左边复现convolution操作,红框里面有9个pixels,这9个pixels在整张图像拉直后的编号是1、2、3、7、8、9、13、14、15,右上角是Filter1,注意每个位置都有不同颜色,这个颜色和右边的颜色对应,最后输出的3,左边是convolution操作,右边是等同该操作的神经网络,3是这个神经网络中某个神经元的输出。本来在这个神经网络里面应该连接36个输入,这里只有9个输入(第一个原因),这样做的时候用的参数比较少。
往下看一个stride:

此时框里面有9个pixels在整张图像拉直后的编号是2、3、4、8、9、10、14、15、16,输出为-1。同样的颜色代表同样weight。
总结下来是两个特点:
1、Filter操作参数减少了;
2、强制神经元使用相同的权重,导致参数更加少。
编程实现咋整?老师大概讲了一下,没听懂。。。还好老师安慰说没听懂没关系,基本会调包就ok。
Max Pooling
在刚才convolution操作之后得到如下的Feature Map,然后把4×4的Feature Map4个一组,通过求最大、或平均等操作(看自己喜好)

如果用最大值:

也就是做完一套convolution+Max Pooling后,变成这样:

上图中的2×2的image的深度与Filter个数有关,如果有50个Filter,深度就是50,也叫有50个channel,不知道这里的channel和图片的RGB的channel是不是一个东西。
老师答疑:不是一个东西!可以理解为组或者维度
彩色图片的例子,固定就是带有3个channel的filter来处理,如果50个Filter进行convolution,处理后就是50个维度×图片分辨率,这里不用再×3。
Convolution+Max Pooling小结

每次convolution操作就会生成一个比原来要小的图像,每次convolution+Max Pooling一套下来输出的维度是可变的,例如:第一次convolution+Max Pooling有50个filter参与,输出的图像也是50个维度,第二次convolution+Max Pooling有25个filter参与,输出的图像还是是25个维度。
Flatten + Fully Connected Feedforward network
Flatten 就是把矩阵拉直,没啥讲的,上图:

实操CNN with Keras

Convolution2D中3,3代表3×3的Filter,其他的看图都知道了。
蓝色框的说明就是这个例子需要修改之前的DNN代码很少,只需要吧之前输入是Vector改为3D tensor,3D tensor就是还有一个图像的channel在里面,黑白是1,彩色是3。
下一步:

原始图像大小是1×28×28的,第一次convolution,Filter大小是3×3,(参数个数是3×3=9,因为相当于只有一个channel),共有25个Filter,所以这里有边边没有办法被FIlter处理,如果想要处理也可以把原始图像加些空白(支书说可以用padding),这里由于有25个Filter,得到,25×26×26((28×28变26×26)是固定变小的,因为之前6×6的用3×3filter会变4×4,就是小2),然后第一次Max Pooling。4个里面取一个最大值,25×26/2×26/2=25×13×13。
第二次convolution,用了50个Filter,每个Filter大小是3×3(参数个数是3×3×25=225,因为前面已经有25维,相当于有25个channel),得到50×11×11(这里又小2),然后第一次Max Pooling,4个里面取一个最大值,得到50×5×5。(这里貌似又丢了一些)
后面就是Flatten和连接到Fully Connected NN。

















 405
405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











