






作者:李禹锋,重庆芝诺大数据分析有限公司数据挖掘工程师。

原本想在基础篇完结之后给大家一个修整学习吸收查资料的时间,但是……被基友催更了,也确实有点久没有更新了,于是……我即使是死了,钉在棺材里了,也要在墓里,用这腐朽的声带喊出,“我要更新!!”

在进入爬虫讲解之前,先讲两篇爬虫需要用到的基础知识,第一篇讲解关系型数据库,第二篇是前端设计基础。解释一下为什么要讲解这两篇看似和python毫无关系的内容。
首先呢,虽然关系型数据库也有很多的弊端,但是在百万级数据量以下,使用关系型数据库要比非关系型数据库还好一些。相信部分读本文的朋友存储数据是使用excel或csv,大体上来看,在千这个级别的数据量在excel中进行处理,excel的卡顿还可以接受,但上万之后卡顿现象就会越发明显(还是太吃电脑性能了)。而且还有很重要的一点是,excel中的处理,只能通过录制宏的方法来将整个流程记录下来,而录制宏对于萌新来说不太友好。但是关系型数据库可以通过编写SQL脚本来记录流程,使得整个过程自动化。
然后是下一篇前端设计基础,我们讲解的爬虫主要有两个思路,第一个是通过解析网页源码,第二个是直接获取异步加载的数据。更常用、适用性更强的是前一种,那么既然要解析网页源码,还是得先了解网页源码是什么东西——前端设计。
接下来讲解关系型数据库中的小清新MySQL。SQL语句都是差不多的,学会一种关系型数据库,其他的数据库SQL语句变动不多,所以学会MySQL基本上就学会了SQL Server、Oracle、SQLite等等关系型数据库(的使用)。
本文导读
01
安装服务端和客户端
链接:https://pan.baidu.com/s/1cJJPgE 密码:y89f
MySQL是Oracle旗下的产品,首先安装数据库的服务端,因Oracle官方的版权控制,现在在Oracle官网进行下载需要登录账号,故使用百度云链接(挂了请留言,会在留言区放出新链接)。不同版本间没什么太大的区别,核心的SQL基本没啥变化。解压完成后会有如下目录和文件。
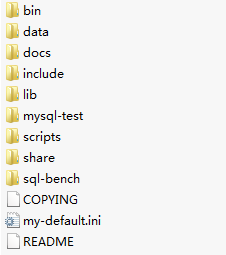
完了,又懵逼了,咋没有setup.exe或者install.exe,怎么不是傻瓜式安装了?以前我还是萌新的时候,一位老前辈就经常和我吐槽mysql卸载不干净,后来心里就一直有这个印象,而且也尽量在避免使用mysql,但是后来发现卸载不干净是因为使用了傻瓜式安装,官方提供的傻瓜式安装包会含有mysql其他的一些组件,想要每个组件都卸载干净确实很麻烦。而本文使用的安装包只提供服务的安装,理解为绿色安装即可。
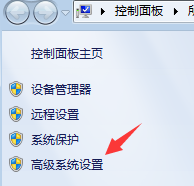
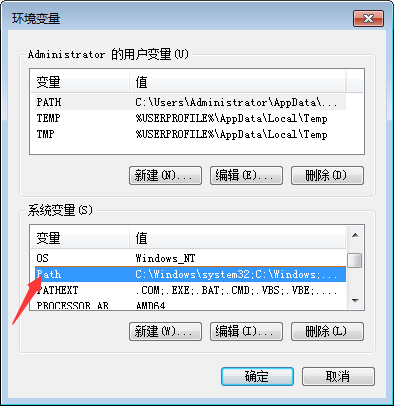
第一步,将bin目录复制到环境变量中。下以win7为例。
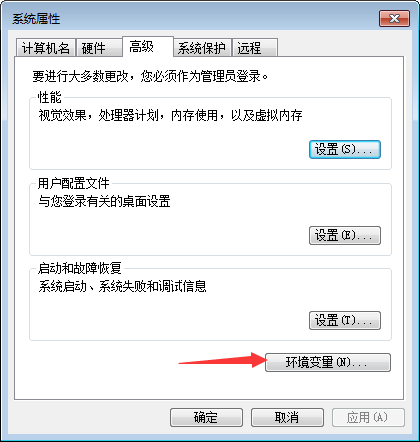
右键计算机,属性--->高级系统设置--->高级,环境变量--->系统变量,Path,编辑,在变量值中将bin目录的完整路径复制进去,每个路径间以英文分号进行分隔,在安装其他一些软件时通常会自动生成一些环境变量,但一般情况其他的环境变量值并不会在结尾加上分号,故一定要注意进行分隔。另再提醒一个事,环境变量中的值不要轻易进行删改,否则系统很多命令无法使用,现在是在系统层面进行操作,如果不是自己添加的环境变量,最好不要删。(python的环境变量也这样添加)
第二步,打开cmd,输入指令,mysqld –install(两根横线)
等待安装结束后,再输入指令net start mysql。
可以看到服务启动成功的提示。安装启动mysql服务端完毕。
介绍一下服务器和客户端的关系。
首先一点,有一种超级电脑叫做服务器,通称物理机,这种“电脑”性能相比普通电脑好很多,所以可以充当各种软件、程序、服务运行的地方,而指示如何运行的地方叫做客户端。但我们讲解的服务器并不是物理服务器,那部分由我的搭档来进行讲解。
我们介绍的是服务、程序、软件的服务端和客户端。上文安装的就是mysql的服务端,而且是在本地进行安装,程序的服务端其实就是这个程序的本体、大脑,处理都在服务端进行的。而客户端是发出指令的地方,以及对结果进行展示的地方。mysql的客户端非常之多,青菜萝卜各有所爱,如果读者以前有倾心的客户端也并不需要更改,下面提供一个轻量级的客户端sqlyog。
链接:https://pan.baidu.com/s/1i5pJrlN 密码:yir4
安装过程略,注册序列码帮各位整理了一些。在进行连接时,因未设置root密码,所以全部默认即可连接到本地的数据库服务器。连接主机地址为localhost,用户名root,密码为空,端口3306,连接后可看到如下界面。
在询问中编写SQL语句,并可保存成SQL脚本。
02
sql入门
SQL(Structured Query Language,结构化查询语言),主要的核心四字是增删改查。先来介绍语法,在文末会有一个完整的查询示例。
增
(1)增加数据库:CREATE DATABASE (IF NOT EXISTS) 数据库名 CHARSET=UTF8
该语句将创建一个一个字符集为utf-8的数据库,if not exists不是必须要的,charset是指定字符集,对于中文来说是必须指定的,因为mysql默认是一种拉丁文的字符集,很容易出现乱码的问题。乱码问题全是因为编码导致的。一个服务器会有多个数据库,一个库会有多个数据表,一个数据表会有多个数据列。
(2)增加表:CREATE TABLE (IF NOT EXISTS) 表名(列名1 列类型1,列名2,列类型2,…) CHARSET=UTF8
该语句将在指定数据库中创建出一张新表,字符集如若不指定则继承数据库的字符集。注意一点!在sqlyog中,可通过点击数据库来进行库的指针切换(我建一张表在哪个库里的呢?在创建的语句里没有指定啊),普遍是使用USE关键词来进行库的切换,USE 数据库名来进行切换。
列类型有几十种,但仅需记住四种即可
INT:整数
FLOAT:小数
VARCHAR(255):可变长度的字符型
TEXT:长文本
(3)增加数据:INSERT 表名(列名1,列名2,…) VALUES(列1数据,列2数据,…)
表名后的括号可省略,但在VALUES中的列数据需要完全按照列的顺序、个数来进行书写,必须做到不重不漏。
删
(1)删数据库:DROP DATABASE 数据库名
(2)删表:DROP TABLE (IF EXISTS) 表名
改
主要讲改表,数据库建立好之后尽可能不改动数据库,而权限、管理员等的改动也是运维工程师该做的事情。前面的所有操作除了INSERT语句,其他的语句都可以在sqlyog中鼠标操作,不过需要各位自行发现功能。改动表结构以ALTER作为关键词起始
ALTER TABLE 表名 操作
例如增加列为:ALTER TABLE 表名 ADD COLUMN 列名 列类型;
删除列为:ALTER TABLE 表名 DELETE COLUMN 列名
查
最最最核心的部分来了,查询语句是SQL语句的核心,SQL就是结构化查询语言嘛,所以查询语句是重中之重。以SELECT为关键词。顺带一提,查询出的结果将是一个新的临时表,针对查询结果表的查询称为嵌套查询,只是本文不涉及。
本篇仅是SQL入门,所以只讲一点基础中的基础中的基础中的单表查询的方法。如果有需求后面会专门针对SQL来写一个完整的系列。(还曾记得两个月前一个朋友在上海应聘数据分析师的岗位,薪资15k,面试前的笔试竟!然!是!写SQL语句)
SELECT 查询内容 FROM 表名 WHERE 查询条件 (GROUP BY 分组列) (ORDER BY 排序列 (DESC))
这是一个完整的单表查询语句。
查询内容若直接为列的内容,填写列名即可,如果需要进行处理,则要使用对应的处理函数(例如字符的截取、拼接,数值求和,数个数等),可使用AS关键词对查询的结果列取一个别名。查询结果之间使用英文逗号进行分隔。部分列名使用了mysql自带关键词(例如time等),在查询时会出错,故尽量使用---> `列名` <---这种方式,这个不是引号,是键盘上1左边,tab键上面那个反引号。如果是查询所有结果使用---> * <---来表示。
查询条件在整个查询中算是一个核心,不过我们要读取到python中的数据大部分不需要做太多的处理,数据预处理部分可通过编写SQL脚本自动化处理。本文只介绍使用最多的两个查询条件,1.数值型的大于小于等于,2.字符型,使用like关键词,可查询出在哪些行里有目标的词汇、段落,例如我数据库里是有这一个月新华网的所有新闻,我想查询出哪些新闻中出现了“大数据”这个词,就需要使用like(和excel中的find函数很相似,具体使用方法见文末案例)。
GROUP BY就是根据哪些数据列进行分组,查询结果每一个组只有一行。也可以在GROUP BY中使用对应的处理函数,按照多个条件进行分组时,使用英文逗号进行分隔。值得一提的是,大数据一个核心基础算法叫做MapReduce,而MR的本质是一个分组规约。MR的部分我搭档会详细进行讲解。后面本系列可能会讲解一些非关系型数据库例如MongoDB,那部分也会讲解MongoDB中的MapReduce如何使用。
ORDER BY就是根据哪些数据列进行排序,默认升序,加上DESC表示降序,多个排序条件间使用英文逗号分隔。
最后一句,当多条语句想要一起执行时,需要在语句末尾加上英文的分号表示结束(最好全给加上)。
03
一个小案例
原本想上传至GitHub的,后来考虑部分朋友不会使用GitHub,故将sql脚本上传到百度网盘,使用文本编辑器即可打开。创建了一个数据库tutorial,创建了一张数据表test,有如下列。

自己造一些数据来供查询教学。(我是现在excel里模拟的数据,然后插入到数据库中的)
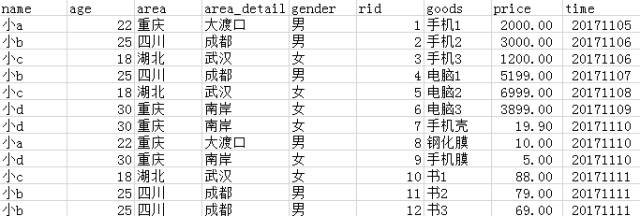
提供五个题目。
0、查询所有数据,默认排序;
1、查询出所有重庆的人购买了什么,查询结果中要name、age、gender、rid、goods、price、time,按照name列升序排序;
2、查询出全国各地的人总支出,查询结果中要area、总价,根据area分组,按照总价降序排列,总价保留两位小数;
3、查询出全国各地在双十一期间有购买记录的人数,查询结果中要area、area_detail、人数,根据area_detail和name分组,按照area和area_detail进行排序;
4、查询出每一天的各地的总交易额,查询结果中要time,area,总价,根据area和time分组,按照时间升序排序。
详细SQL语句看脚本。
链接:https://pan.baidu.com/s/1gf1sIWj 密码:ouve
在python2中使用MySQLDB库作为接口,python3中使用pymysql作为接口。两个库使用方法差不太多。

人生苦短,我选python。最近朋友圈被python进入高考刷屏了,但是个人感觉不能仅拘泥于一门语言,也并不是学会python就能走遍天下。做数据分析、数据挖掘,python仅仅是其中一种工具,但其他的工具也并不是就没用了,各有优劣。














 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









