




一直在搞工作流(activiti),总结一下关于工作流(activiti)中同时并发处理多个子流程的操作方法。
先说下我要实现的业务:
1、办公室发通知(在系统申报页面上,勾选科室,被选中的科室执行第二步)
2、科室科员填报数据
3、科室科长做审核(注意这里的科长审核是对应第二步的科室,本科科长去审核本单位填报完的任务)
4、办公室编制立项书,汇总数据
好,需求就先这样,这里主要是给讲解一下关于子流程的使用,所以其他的需求就不往上写了。
先看一眼画好后的流程图:
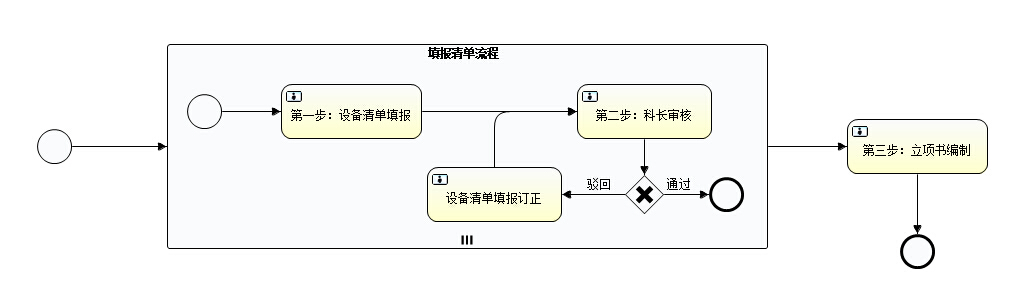
可以看到任务发起时(启动流程实例时)就进入了子流程中,这里需要关心的是怎么才能生成多个子流程呢,请看:
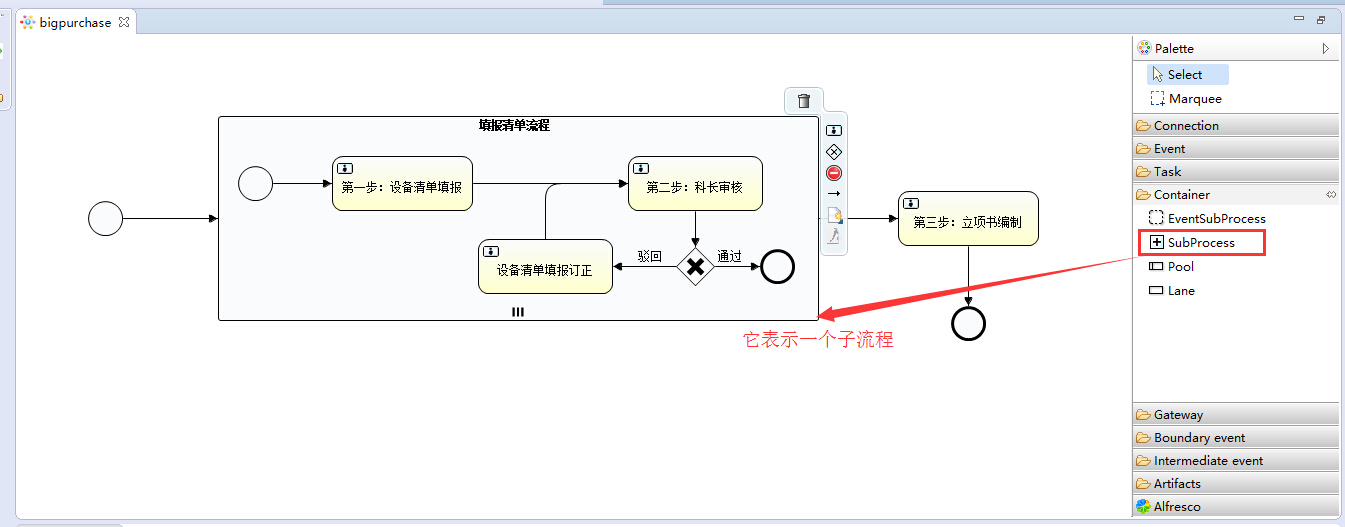
接下来我们对这个子流程进行配置:
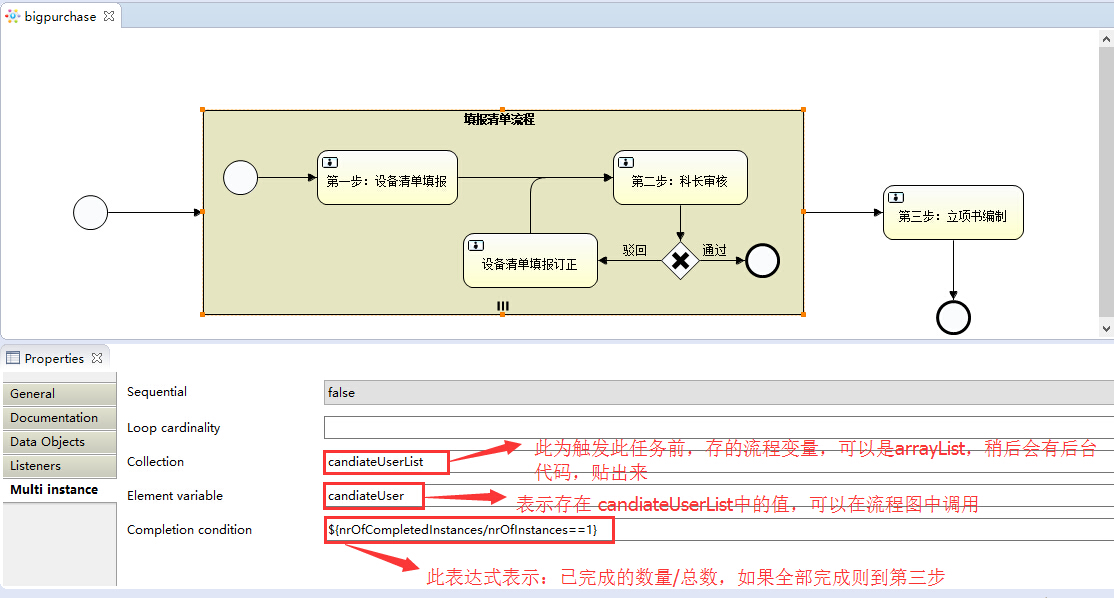
注:1、Collection:可以存放集合,集合中可以存任意值,工作流会根据你集合里的值个数,去生成对应的子流程,
例如:我这里存的是3个科室code,{0001,0002,0003},那么就会生成出3个子流程,
其实这里我简单说明一下,如果只传入1个值会生成4个流程实例,
传2个会生成出6个流程实例(多出的两个,一个是子流程subprocess的,一个是流程中第一个任务的),以此类推。
2、Element variable:顾名思义就是节点流程变量,用于在流程图中代替集合中表示当前子流程的变量(我这存的是科室code,所以表示的就是科室code)。
这个节点流程变量可以在当前子流程中任意的task中使用,例如 子流程中的任务我就用到了这个变量,稍后会有图详细说明
3、Completion condition:顾名思义就是完成条件,这里写的表达式如果满足即可到(第三步:立项书编制)这个任务,关于这里的配置,
给大家推荐一个网址介绍:http://my.oschina.net/winHerson/blog/139267?fromerr=ApnxMXj5
接下来继续配置,我的业务需求是 选中的科室做填报,并且有这个科室的科长去审核,那么我们接着去配置具体的用户任务(userTask)
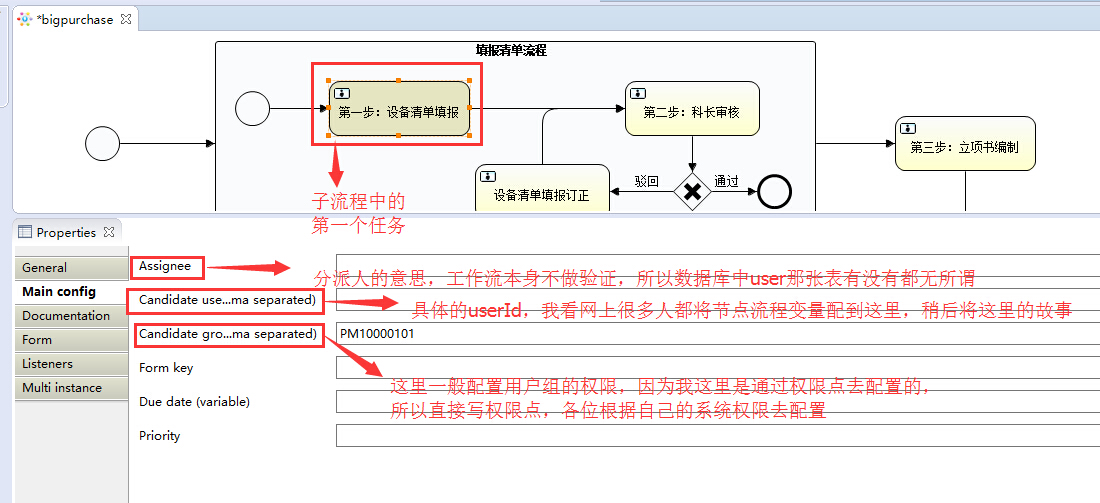
这里简单讲一下我做的这个项目的权限控制,我这里是通过权限点去控制显示每个任务的待办的权限,假如张三 有PM10000101权限点,
他就能看到任务中配置了PM10000101的待办,因为我的系统是三级树权限控制,用户--角色--权限点(功能点),
所以我在工作流Candiate groups中配置的是功能点,各位可以根据自己系统的需要去合理配置。
顺便在讲一下将${candiateUser}配置到Candidate users或者Candidate groups的后果,
它会根据你集合中存的变量个数生成出任务来比较恶心的是这种形式,例如:
candiateUserList中存了{001,002,003},按照规则会生成出3个子流程(A、B、C),
但是在生成任务的时候会生成出这种A(001)、A(002)、A(003)、B(001)、B(002)、B(003)、C(001)、C(002)、C(003)
问题是我这里不需要这么生成任务,只需要一个流程对应1个任务就OK,所以我将${candiateUser}配置到了userTask的描述信息中
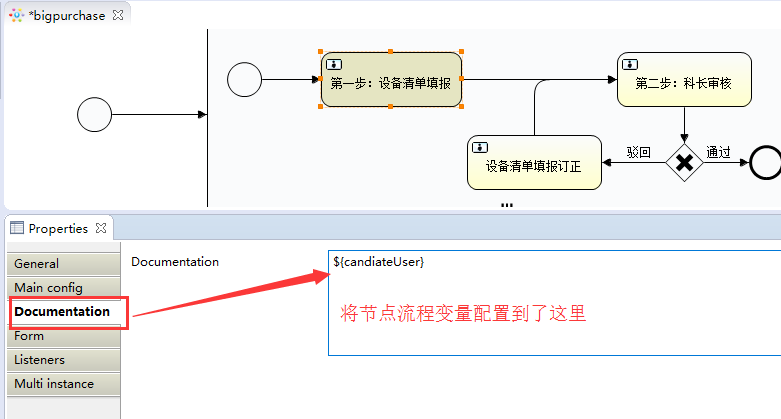
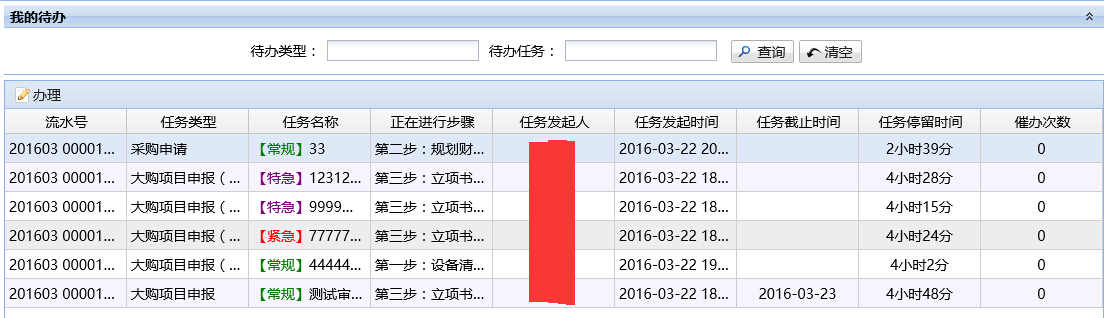
配置到了这一步基本告一段落,下面我将我的查询待办sql贴出来,相信大家都懂了
 我的待办
我的待办
再贴一张系统图:
接下来将启动流程时的代码贴出来:
//工作流
String targetFilePath = ServletActionContext.getRequest().getSession().getServletContext()
.getRealPath("/") + IcmisModels.TEMP_FOLD+ "/";//获取项目临时文件目录
//得到当前系统用户对象
UserView u = (UserView) ServletActionContext.getRequest().getSession().getAttribute(FrameConstant.SESSION_USERVIEW);
Map<String, Object> map=new HashMap<String, Object>();//要在启动流程中存的流程变量map
map.put(WorkFlowConstant.START_USER, u.getUsername());//设置发起人
List<String> candiateUserList=new ArrayList<String>();//创建多个子流程用的集合
//获取从前台传过来的科室code,并将其解析出来存入集合
if(result.getAddinfoDep()!=null&&!"".equals(result.getAddinfoDep())){
String strs[]=result.getAddinfoDep().split(",");//将1,2,3,4..拼接的科室code字符串解析到数组里
for (String s : strs) {
candiateUserList.add(s);//将科室code存入集合中
}
}else{
candiateUserList.add("流程错误,无效任务"); //纯粹扯淡,这种情况根本不存在
}
map.put("candiateUserList", candiateUserList);//多个子流程集合
map.put(WorkFlowConstant.TASK_NAME, result.getProjectName()+"设备清单填报");//任务名称
map.put(WorkFlowConstant.DEADLINE,IcmisUnit.date2str(result.getDepDeadline()));//任务截止时间
map.put(WorkFlowConstant.IS_URGENCY,result.getTaskUrgency());//任务紧急度
//发起流程
String piId=wfservice.getWorkflowBaseService().startProcess("bpApply", map,targetFilePath);
service层save方法中调用的工作流代码public String startProcess(String processDefinitionKey,
Map<String, Object> vMap,String targetFilePath) {
RuntimeService rs = this.processEngine.getRuntimeService(); //得到运行时的service
//设置发起人,这个方法是通过线程判断是一个了流程实例的
this.processEngine.getIdentityService().setAuthenticatedUserId(vMap.get(WorkFlowConstant.START_USER).toString());
//根据传入的用户名得到工作流内置的用户表对象
User user = this.processEngine.getIdentityService().createUserQuery()
.userId(vMap.get(WorkFlowConstant.START_USER).toString())
.singleResult();
vMap.put("ac", processDefinitionKey);//设置流程定义key,存到流程变量中
//根据流程定义key得到流程定义对象
ProcessDefinition processDefinition = this.getProcessDefinitionByKey(processDefinitionKey);
//vMap.put(WorkFlowConstant.VIEW_URL, processDefinition.getDescription());
Map<String,Object> map=getSeqFlowByBpmn(processDefinition.getDeploymentId(),targetFilePath);//得到所有连线驳回的任务节点的map
vMap.put(WorkFlowConstant.SEQUENCEFLOW, map);//将连线驳回的任务节点map存入流程变量中
// 保存日志
ProcessInstance instance = rs.startProcessInstanceByKey(
processDefinitionKey, vMap);
TaskMarkModel taskMarkModel = new TaskMarkModel();
taskMarkModel.setAuditRemark("发起任务");
//排序使用
taskMarkModel.setCreateDate(new Date(new Date().getTime()-100000));
taskMarkModel.setDoDate(new Date(new Date().getTime()-100000));
taskMarkModel.setDoResult("发起任务");
taskMarkModel.setDoUserName(user.getFirstName());
taskMarkModel.setPid(instance.getProcessInstanceId());
taskMarkModel.setpName(processDefinition.getName());
taskMarkModel.setTaskName("发起任务");
this.saveTaskMark(taskMarkModel);
// 保存日志结束
return instance.getProcessInstanceId();
}
启动流程的方法startProcess(流程定义key,流程变量Map)/**
* 获取每个任务的连线.
*
* @Title: getSeqFlowByBpmn
* @author liufei12581@sinosoft.com.cn
* @param deploymentid 部署id
* @param targetFilePath 路径
* @return
*/
public Map getSeqFlowByBpmn(String deploymentid,String targetFilePath){
Map<String,List<String>> map=new HashMap<String, List<String>>();
Map<String,String> taskmap=new HashMap<String, String>();
Map allmap=new HashMap();
try {
InputStream in=null;
List<String> list = getProcessEngine().getRepositoryService()//
.getDeploymentResourceNames(deploymentid);
//定义图片资源的名称
String resourceName = "";
if(list!=null && list.size()>0){
for(String name:list){
if(name.indexOf(".bpmn")>=0){
resourceName = name;
}
}
}
//获取数据库里部署的bpmn文件
in = getProcessEngine().getRepositoryService()
.getResourceAsStream(deploymentid, resourceName);
//将bpmn文件另存到本地并写入xml文件
String fileName=resourceName.substring(0,resourceName.indexOf("."))+".xml";
File file = new File(targetFilePath+fileName);
// if(file.exists()){//判断文件是否存在
System.out.println(targetFilePath);
file.delete();//如果存在则先删除
file.createNewFile(); //创建文件
OutputStream output = new FileOutputStream(file);
BufferedOutputStream bufferedOutput = new BufferedOutputStream(output);
bufferedOutput.write(IcmisUnit.toByteArray(in));
bufferedOutput.flush();
// }
//获取dom工厂得到dom对象
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();//步骤1
DocumentBuilder builder = factory.newDocumentBuilder();//步骤2
//将保存的xml解析成dom树
Document doc = builder.parse(file);//步骤3
//获取连线的所有node
NodeList sequenceFlow = doc.getElementsByTagName("sequenceFlow");
//获取网关的所有node
NodeList exclusiveGateway = doc.getElementsByTagName("exclusiveGateway");
//获取任务的所有node
NodeList userTask = doc.getElementsByTagName("userTask");
//循环任务节点
for (int i = 0; i < userTask.getLength(); i++) {
//获取任务节点的id属性
String id=userTask.item(i).getAttributes().getNamedItem("id").getNodeValue();
//获取任务节点的name属性
String name=userTask.item(i).getAttributes().getNamedItem("name").getNodeValue();
taskmap.put(id, name);
}
//循环连线节点
for (int i = 0; i < sequenceFlow.getLength(); i++) {
//获取连线的起始节点
String sourceTask=sequenceFlow.item(i).getAttributes().getNamedItem("sourceRef").getNodeValue();
//获取连线的目标节点
String targetTask=sequenceFlow.item(i).getAttributes().getNamedItem("targetRef").getNodeValue();
boolean bool=true;//用来判断是否是通过的连线,下面的操作是为了过滤描述通过的连线
//获取连线节点下的配置信息节点,一个连线应该只有一个配置节点
NodeList nl= sequenceFlow.item(i).getChildNodes();
for (int j = 0; j <nl.getLength(); j++) {
if(nl.item(j).getNodeType()==Node.ELEMENT_NODE){
//找到配置节点,并得到配置的值
if("conditionExpression".equals(nl.item(j).getNodeName())){
//这里要注意一下:配置通过的连线一定要写成${flag=='1'}或"${flag==\"1\"}
String flag=Util.nulltostr(nl.item(j).getFirstChild().getNodeValue());
if("${flag=='1'}".equals(flag)||"${flag==\"1\"}".equals(flag)){
//表示是通过的连线,如果是通过的连线则不做处理,这里用到了上面的boolean变量,通过变量来控制过滤节点
bool=false;
}
}
}
}
//通过变量过滤已通过的连线节点
if(bool){
//存连线的开始任务
if(map.containsKey(sourceTask)){
//表示存在
map.get(sourceTask).add(targetTask);
}else{
//表示不存在
List<String> targetlist=new ArrayList<String>();
targetlist.add(targetTask);
map.put(sourceTask, targetlist);
}
}
}
//默认取出来的连线针对网关记录的是网关的节点,但是实际操作中想要得到网关的节点id是不可能的,所以加了一步处理,获取连接网关的上个节点
//这里要说明一下,连接到网关的连线 也就是targetRef肯定是只有一条连线,所以顺藤摸瓜找到了连接网关的任务节点,这样在实际项目中
//通过任务节点即可找到驳回连线的targetRef任务节点,即可展示到前台让客户去选择驳回的连线啦
//循环网关node
for (int i = 0; i < exclusiveGateway.getLength(); i++) {
//得到网关id
String exclusiveGatewayid=exclusiveGateway.item(i).getAttributes().getNamedItem("id").getNodeValue();
//通过循环所有的连线,比对得到那条唯一连接网关的连线将数据重新防止到map当中
for (String key : map.keySet()) {
for (String target : map.get(key)) {
if(exclusiveGatewayid.equals(target)){
map.put(key, map.get(exclusiveGatewayid));
}
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
allmap.put(WorkFlowConstant.SEQ, map);
allmap.put(WorkFlowConstant.USERTASK, taskmap);
return allmap;
}
获取驳回的连线任务节点getSeqFlowByBpmn(部署id,临时存放文件路径)
转载:https://www.cnblogs.com/mycifeng/p/5309150.html

















 2968
2968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









