







目录
目录
E:\mongo\bin
getting started
结构
document
每个document都有唯一得"_id"
collection
是一个分布式得数据库,可以使用mongo shell处理。
文档
大小写敏感、类型敏感。
如下不同
{"count" : 5}
{"count" : "5"}Collection
动态schema
但是依然需要一些collection,包括不同得混在一起增加复杂度,包括data得局部性,以及部分得唯一索引得效率等。
CollectionName
不可以用空串
不可以用\0得字符
不建议使用system开头得
不应当使用 $符号
subcollection
虽然子collection与父亲之间可能没啥关系。但是是一个良好得组织数据得方式。
DataBases
不可以用空串
不允许包含特殊字符 /, \, ., ", *, <, >, :, |, ?, $
大小写敏感
最大64字节。
保留得 如admin local config
admin 鉴权和眼圈
local 保存再副本过程中使用得
config 一些设置信息,如每个shard
MongoShell
库
#db
db
#切换db
use test
#某个collection
db.mine.find()
# db
show dbs
# collections
show collections
插入
#插入
movie = {"title" : "Star Wars: Episode IV - A New Hope",
... "director" : "George Lucas",
... "year" : 1977}
db.movies.insertOne(movie)
db.movies.find().pretty();
#drop
db.movies.drop()
#返回值
true
#insert Many
db.movies.insertMany([{"title" : "Ghostbusters"},
... {"title" : "E.T."},
... {"title" : "Blade Runner"}]);
db.movies.find()
#insertMany 默认按照顺序插入
db.movies.drop()
db.movies.insertMany([ {"_id" : 0, "title" : "Top Gun"}, {"_id" : 1, "title" : "Back to the Future"}, {"_id" : 1, "title" : "Gremlins"}, {"_id" : 2, "title" : "Aliens"}])
#只插入了两个
db.movies.find() { "_id" : 0, "title" : "Top Gun" } { "_id" : 1, "title" : "Back to the Future" }
#非顺序插入就会不断得插入
db.movies.drop()
db.movies.insertMany([ {"_id" : 0, "title" : "Top Gun"}, {"_id" : 1, "title" : "Back to the Future"}, {"_id" : 1, "title" : "Gremlins"}, {"_id" : 2, "title" : "Aliens"}], {"ordered":false}) insert 不能接受超过48MB得数据,客户端会自动分割成48MB
多插入时,默认按照顺序插入,插入到有问题得停止
可以通过指定 {“ordered”:false} 来乱序插入,那么插入得时候由mongo自行决定顺序,且出错以后,还会试图插入剩余的。
插入时会校验大小,单个文档不能超过16M,可以使用Object.bsonsize(doc)来判断大小。
查询
#查看一个
db.movies.findOne()
#find
db.movies.find({"year":1977})更新
#更新
db.movies.updateOne({title : "Star Wars: Episode IV - A New Hope"}, {$set : {reviews: []}})
#查询
db.movies.find().pretty()
{ "_id" : ObjectId("637cf0e28666b0a3bebc2f3f"), "title" : "Star Wars: Episode IV - A New Hope", "director" : "George Lucas", "year" : 1977, "reviews" : [ ] }
#replace 最好用_id 替换
db.users.drop()
userjoe={
"_id" : ObjectId("4b2b9f67a1f631733d917a7a"),
"name" : "joe",
"friends" : 32,
"enemies" : 2
}
db.users.insert(userjoe)
joe={ "_id" : ObjectId("4b2b9f67a1f631733d917a7a"), "relationships" : { "friends" : 32, "enemies" : 2 }, "username" : "joe" }
db.users.replaceOne({"name":"joe"},joe)
db.users.find().pretty()
updateOne
updateMany
$inc {条件},{$inc{“属性”:1}}
$set {条件},{$set{“属性”:设置值}}
$unset {条件},{$unset{“属性”:1}}
#db.pages $inc
db.pages.drop()
page1={
"_id" : ObjectId("4b253b067525f35f94b60a31"),
"url" : "www.example.com",
"pageviews" : 52
}
db.pages.insert(page1)
db.pages.find().pretty()
db.pages.updateOne({"url" : "www.example.com"}, {"$inc" : {"pageviews" : 1}})
#变成53了
db.pages.find().pretty()
#$set 新增
db.pages.updateOne({"_id":ObjectId("4b253b067525f35f94b60a31")},{"$set" : {"protocol" : "http"}})
db.pages.find().pretty()
#set 变更
db.pages.updateOne({"_id":ObjectId("4b253b067525f35f94b60a31")},{"$set" : {"protocol" : "ftp"}})
db.pages.find().pretty()
#set 变更类型
db.pages.updateOne({"_id":ObjectId("4b253b067525f35f94b60a31")},{"$set" : {"protocol" : ["ftp", "http"]}})
db.pages.find().pretty()
#unset
db.pages.updateOne({"_id":ObjectId("4b253b067525f35f94b60a31")}, {"$unset": {"protocol":1}})
#恢复了
db.pages.find().pretty()
update* 必须使用$set $push $incr等字段防止覆盖
array得
$push 和$pull, pull会去除所有该名字得
$addToSet 添加所有得到set中
array可以按照索引$set 某一个值,但是要加上 双引号,
也可以设置所有得,对应得索引改为$[] db.pages.updateOne({pageviews:53},{$set:{"buttons.$[].position":4}})
db.pages.find()
{ "_id" : ObjectId("4b253b067525f35f94b60a31"), "url" : "www.example.com", "pageviews" : 53 }
db.pages.updateOne({pageviews:53},{$push :{"user":"ouyangshaogong"}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
db.pages.find().pretty()
{
"_id" : ObjectId("4b253b067525f35f94b60a31"),
"url" : "www.example.com",
"pageviews" : 53,
"user" : [
"ouyangshaogong"
]
}
db.pages.updateOne({pageviews:53},{$push :{"user":"xunfang"}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
db.pages.updateOne({pageviews:53},{$push :{"user":"xunfang"}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
数组得更新
db.pages.find().pretty()
{
"_id" : ObjectId("4b253b067525f35f94b60a31"),
"url" : "www.example.com",
"pageviews" : 53,
"user" : [
"ouyangshaogong",
"xunfang",
"xunfang"
]
}
#pull会pull掉所有得对应得元素,有两个“xunfang” 就会都消失
db.pages.updateOne({pageviews:53},{$pull :{"user":"xunfang"}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
db.pages.find().pretty()
{
"_id" : ObjectId("4b253b067525f35f94b60a31"),
"url" : "www.example.com",
"pageviews" : 53,
"user" : [
"ouyangshaogong"
]
}
#可以push多个元素
db.pages.updateOne({pageview:53}, {$push:{user:{$each:["haha","xixi"]}}})
db.pages.find().pretty()
{
"_id" : ObjectId("4b253b067525f35f94b60a31"),
"url" : "www.example.com",
"pageviews" : 53,
"user" : [
"ouyangshaogong",
"haha",
"xixi"
]
}
#你甚至可以限制array得大小 $slice 负值从后往前, 正值从前往后
db.pages.updateOne({pageviews:53}, {$push:{user:{$each:["haha","xixi"], $slice:4}}})
db.pages.find().pretty()
{
"_id" : ObjectId("4b253b067525f35f94b60a31"),
"url" : "www.example.com",
"pageviews" : 53,
"user" : [
"ouyangshaogong",
"haha",
"xixi",
"haha"
]
}
#上一个得后两个,加上新得两个,xixi haha haha xixi
db.pages.updateOne({pageviews:53}, {$push:{user:{$each:["haha","xixi"], $slice:-4}}})
db.pages.find().pretty()
{
"_id" : ObjectId("4b253b067525f35f94b60a31"),
"url" : "www.example.com",
"pageviews" : 53,
"user" : [
"xixi",
"haha",
"haha",
"xixi"
]
}
#你甚至可以sort决定添加顺序,然后再去保留,但是必须加上$each
db.pages.updateOne({pageviews:53}, {$push:{user:{$each:["haha","xixi","dare","abc"], $slice:-5, $sort:{user:-1}}}})
#可以使用$addToSet 来去重。
db.pages.updateOne({pageviews:53}, {$addToSet:{user:{$each:["haha","xixi"]}}})
db.pages.find().pretty()
db.pages.updateOne({pageviews:53},{$addToSet:{user:"xixi"}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 0 }
> db.pages.find().pretty()
{
"_id" : ObjectId("4b253b067525f35f94b60a31"),
"url" : "www.example.com",
"pageviews" : 53,
"user" : [
"xixi",
"haha",
"haha",
"xixi"
]
}
#数组得按照索引操作,先添加个对象类型
db.pages.updateOne({pageviews:53},{$addToSet:{buttons:{$each:[{"name":"click",position:5 },{"name":"click",position:6 },{"name":"submit",position:7 }]}}})
db.pages.find().pretty()
{
"_id" : ObjectId("4b253b067525f35f94b60a31"),
"url" : "www.example.com",
"pageviews" : 53,
"user" : [
"xixi",
"haha",
"haha",
"xixi"
],
"buttons" : [
{
"name" : "click",
"position" : 5
},
{
"name" : "click",
"position" : 6
},
{
"name" : "submit",
"position" : 7
}
]
}
#按照索引更新某一个,注意这种方式必须加双引号 更新第二个
db.pages.updateOne({pageviews:53},{$set:{"buttons.1.name":"cancel"}})
db.pages.find().pretty()
{
"_id" : ObjectId("4b253b067525f35f94b60a31"),
"url" : "www.example.com",
"pageviews" : 53,
"user" : [
"xixi",
"haha",
"haha",
"xixi"
],
"buttons" : [
{
"name" : "click",
"position" : 5
},
{
"name" : "cancel",
"position" : 6
},
{
"name" : "submit",
"position" : 7
}
]
}
#更新所有得 buutons得position为4
db.pages.updateOne({pageviews:53},{$set:{"buttons.$[].position":4}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.pages.find().pretty()
{
"_id" : ObjectId("4b253b067525f35f94b60a31"),
"url" : "www.example.com",
"pageviews" : 53,
"user" : [
"xixi",
"haha",
"haha",
"xixi"
],
"buttons" : [
{
"name" : "click",
"position" : 4
},
{
"name" : "cancel",
"position" : 4
},
{
"name" : "submit",
"position" : 4
}
]
}
#过滤更新(先设置一下)
db.pages.updateOne({pageviews:53},{$set:{"buttons.2.position":6}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
#设置大于4得变成5(刚刚得索引为2得)
db.pages.updateOne({pageviews:53}, {$set:{"buttons.$[ele].position":5}},{arrayFilters:[{"ele.position":{$gt:4}}]})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.pages.find().pretty()
{
"_id" : ObjectId("4b253b067525f35f94b60a31"),
"url" : "www.example.com",
"pageviews" : 53,
"user" : [
"xixi",
"haha",
"haha",
"xixi"
],
"buttons" : [
{
"name" : "click",
"position" : 4
},
{
"name" : "cancel",
"position" : 4
},
{
"name" : "submit",
"position" : 5
}
]
}
upsert 以及 setOnInsert 后者只有插入时更新。类似于putDocumentIfAbsent
db.users.updateOne({"rep" : 25}, {"$inc" : {"rep" : 3}}, {"upsert" : true})
db.users.find()
{ "_id" : ObjectId("638380269e9d33d7668a0bce"), "rep" : 28 }
#没有时才去更新
db.users.updateOne({}, {"$setOnInsert" : {"createdAt" : new Date()}}, {"upsert" : true})
db.users.updateOne({"jobId":1}, {"$setOnInsert" : {"createdAt" : new Date()}}, {"upsert" : true})
{
"acknowledged" : true,
"matchedCount" : 0,
"modifiedCount" : 0,
"upsertedId" : ObjectId("638382259e9d33d7668a0cc5")
}
> db.users.find()
{ "_id" : ObjectId("638381329e9d33d7668a0c5b"), "createdAt" : ISODate("2022-11-27T15:24:34.984Z") }
{ "_id" : ObjectId("638382259e9d33d7668a0cc5"), "jobId" : 1, "createdAt" : ISODate("2022-11-27T15:28:37.593Z") }replaceOne
最好使用_id 去替换
updateOne
updateMany
delete
db.movies.deleteOne({title : "Star Wars: Episode IV - A New Hope"})
#deleteMany
db.movies.drop()
db.movies.insertMany([ {"_id" : 0, "title" : "Top Gun"}, {"_id" : 1, "title" : "Back to the Future"}, {"_id" : 2, "title" : "Aliens"}, {"_id" : 3, "title" : "Aliens"}])
db.movies.deleteMany({"title":"Aliens"})
#只剩下两个
db.movies.find()
数据类型
脱胎于json
null
boolean
Number (64bit float)
NumberInt
NumberLong
String
Date (时间戳)
newDate() 具体见15章
js得正则表达式
array
可以包含不同得类型
可以针对其中得值做索引
嵌入得document
objectId
mongodb 一定需要又一个“_id”,每个collection必须唯一。
默认得“_id”类型 默认12字节。
前32位为秒级时间戳
接下来40位随机值,包括24位得机器,16位得pid
最后三字节位counter
二进制数据
代码类型
MongoShell
help
updateOne
db.movies.updateOne
function (filter, update, options) {
var opts = Object.extend({}, options || {});
// Check if first key in update statement contains a $
var keys = Object.keys(update);
if (keys.length == 0) {
throw new Error("the update operation document must contain at
least one atomic operator");
}
...用shell 跑脚本
mongo script1.js script2.js script3.js
MongoDB shell version: 4.2.1
connecting to: mongodb://127.0.0.1:27017
MongoDB server version: 4.2.1
loading file: script1.js
I am script1.js
loading file: script2.js
I am script2.js
loading file: script3.js
I am script3.js
...CRUD
find
查询条件与返回值 1为include 0为exclude
db.task.find({"attr1": "a", "attr2":"b"},{"returnAttr1":1, "excludeAttr2":0})
db.pages.find().pretty()
{
"_id" : ObjectId("4b253b067525f35f94b60a31"),
"url" : "www.example.com",
"pageviews" : 53,
"user" : [
"xixi",
"haha",
"haha",
"xixi"
],
"buttons" : [
{
"name" : "click",
"position" : 4
},
{
"name" : "cancel",
"position" : 4
},
{
"name" : "submit",
"position" : 5
}
]
}
> db.pages.find({pageviews:53},{"url":1})
{ "_id" : ObjectId("4b253b067525f35f94b60a31"), "url" : "www.example.com" }$gte $lte $lt $ne
$in $nin $or
这几个都接数组,但是or后面接json数组,但是in 和nin是在条件里面。
$not not是不满足的条件,在条件外面例如
db.users.find({"id_num" : {"$mod" : [5, 1]}})
db.users.find({"id_num" : {"$not" : {"$mod" : [5, 1]}}})特定的类别
null
null查询的时候可以指定为null的,也会查不存在的。如果需要区分,可以使用exists
db.c.find()
{ "_id" : ObjectId("4ba0f0dfd22aa494fd523621"), "y" : null }
{ "_id" : ObjectId("4ba0f0dfd22aa494fd523622"), "y" : 1 }
{ "_id" : ObjectId("4ba0f148d22aa494fd523623"), "y" : 2 }
db.c.find({"y" : null})
{ "_id" : ObjectId("4ba0f0dfd22aa494fd523621"), "y" : null }
db.c.find({"z" : null})
{ "_id" : ObjectId("4ba0f0dfd22aa494fd523621"), "y" : null }
{ "_id" : ObjectId("4ba0f0dfd22aa494fd523622"), "y" : 1 }
{ "_id" : ObjectId("4ba0f148d22aa494fd523623"), "y" : 2 }
#区分null和exists
db.c.find({"z" : {"$eq" : null, "$exists" : true}})regular expression
db.users.find( {"name" : {"$regex" : /joe/i } })queryArray
db.food.insertOne({"fruit" : ["apple", "banana", "peach"]})
#查单个
db.food.find({"fruit" : "banana"}).pretty()
{
"_id" : ObjectId("638387a6d7de9d4b1b22e3ac"),
"fruit" : [
"apple",
"banana",
"peach"
]
}
#multi插入
db.food.insertMany([{"_id" : 1, "fruit" : ["apple", "banana", "peach"]},{"_id" : 2, "fruit" : ["apple", "kumquat", "orange"]},{"_id" : 3, "fruit" : ["cherry", "banana", "apple"]}])
cherry", "banana", "apple"]}])
{ "acknowledged" : true, "insertedIds" : [ 1, 2, 3 ] }
db.food.find().pretty()
{
"_id" : ObjectId("638387a6d7de9d4b1b22e3ac"),
"fruit" : [
"apple",
"banana",
"peach"
]
}
{ "_id" : 1, "fruit" : [ "apple", "banana", "peach" ] }
{ "_id" : 2, "fruit" : [ "apple", "kumquat", "orange" ] }
{ "_id" : 3, "fruit" : [ "cherry", "banana", "apple" ] }
#$all 所有的都匹配的才输出
db.food.find({fruit : {$all : ["apple", "banana"]}})
{ "_id" : ObjectId("638387a6d7de9d4b1b22e3ac"), "fruit" : [ "apple", "banana", "peach" ] }
{ "_id" : 1, "fruit" : [ "apple", "banana", "peach" ] }
{ "_id" : 3, "fruit" : [ "cherry", "banana", "apple" ] }where可以接一些复杂的函数,但是不建议用
db.foo.find({"$where" : function () {
... for (var current in this) {
... for (var other in this) {
... if (current != other && this[current] == this[other]) {
... return true;
... }
... }
... }
... return false;
... }});cursor
cursor有一定的资源消耗,但是默认会10分钟释放。
limit skip sort
db.stock.find({"desc" : "mp3"}).limit(50).skip(50).sort({"price" : -1})Indexes
注意,mongo的索引为b树而非b+树,设计理念不同。
for (i=0; i<1000000; i++) {
db.users.insertOne(
{
"i" : i,
"username" : "user"+i,
"age" : Math.floor(Math.random()*120),
"created" : new Date()
}
);
}执行计划
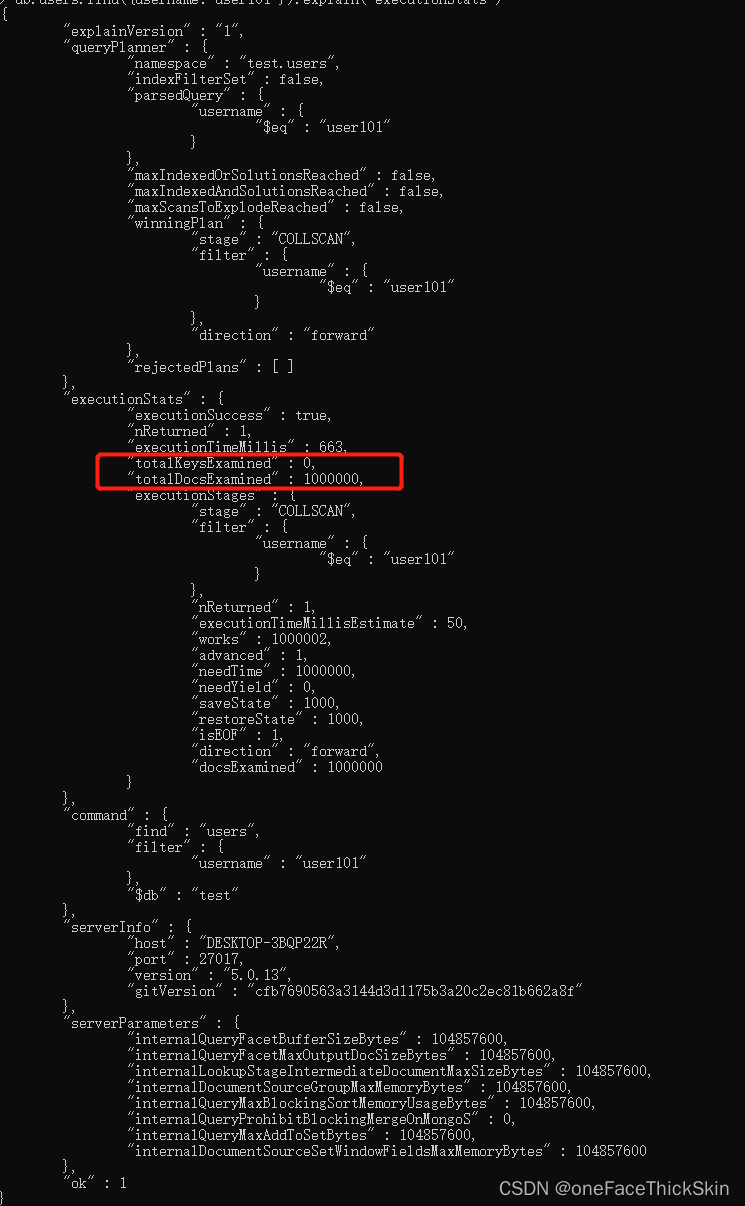
db.users.find({"username": "user101"}).explain("executionStats")
可以看到执行计划
创建索引
db.users.createIndex({"username":1})db.users.find({"username": "user101"}).explain("executionStats")
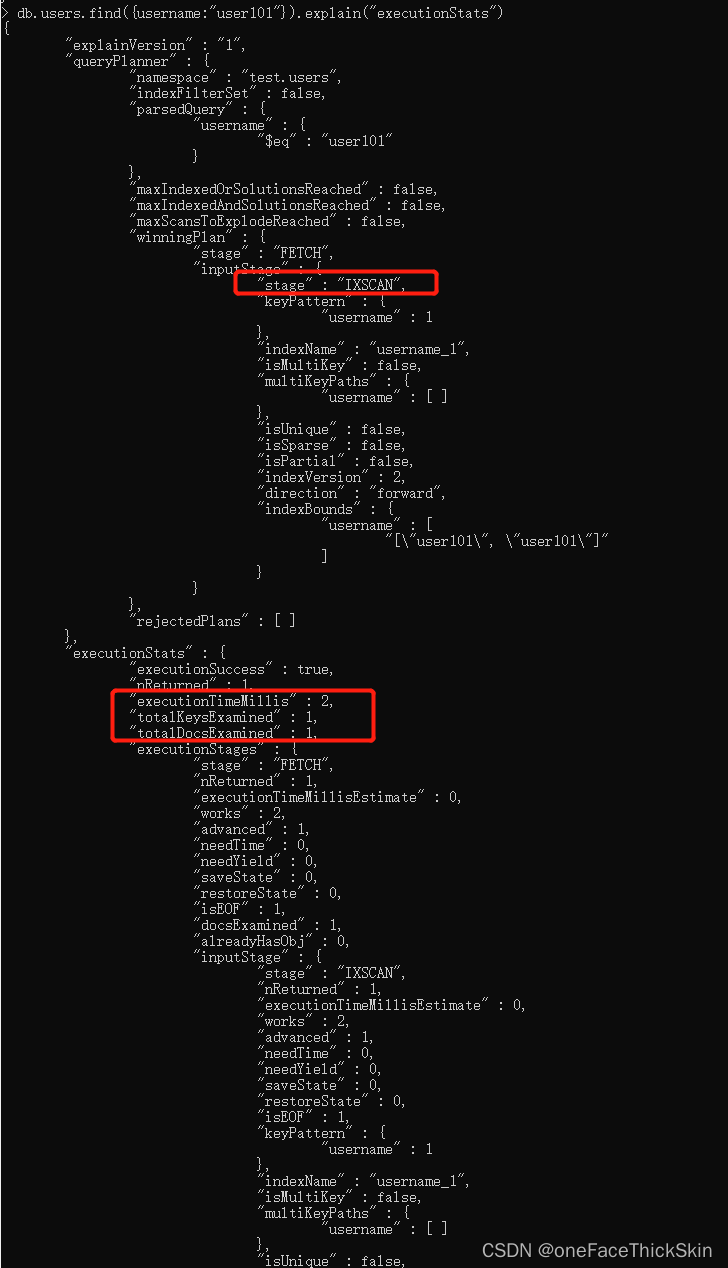
覆盖索引
#直接排序
db.users.find().sort({"age" : 1, "username" : 1})
#结果
Error: error: { "ok" : 0, "errmsg" : "Executor error during find command :: caused by :: Sort exceeded memory limit of 104857600 bytes, but did not opt in to external sorting.", "code" : 292, "codeName" : "QueryExceededMemoryLimitNoDiskUseAllowed" }
#加索引后排序
db.users.createIndex({"age":1, "username":1})
#秒回来
db.users.find().sort({"age" : 1, "username" : 1})
#注意顺序,下面这个就跑不了
db.users.find().sort({"username" : 1, "age" : 1})
#下面这个也可以
db.users.find({"age" : 21}).sort({"username" : -1})mongo怎么使用索引:
去执行一个试验计划,多开几个线程都执行一遍,看哪个先执行完。
mongo索引尝试
插入100W
for (i=0; i<1000000; i++) {db.students.insertOne({"student_id" : i, "score": [{"type": "exam", "score": Math.random()*100},{"type": "quiz", "score": Math.random()*100},{"type": "homework", "score": Math.random()*100},{"type": "homework", "score": Math.random()*100}], "age": Math.floor(Math.random()*120), "class_id": Math.floor(Math.random()*500)});}
db.students.createIndex({"class_id": 1})
db.students.createIndex({student_id: 1, class_id: 1})
#新版的会先走calssId的单独索引,老板的会检索所有的索引。
db.students.find({student_id:{$gt:500000}, class_id:54}) .sort({student_id:1}) .explain("executionStats")
db.students.createIndex({class_id:1, student_id:1})
#drop Index
db.students.dropIndex("class_id_1")
#会走新的索引
db.students.find({ class_id:54}) .explain("executionStats") 创建索引的原则:
相等的的应该放到前面
排序的紧接其后
最后是多值的
覆盖索引
如果扫描的totalDocsExamined 是0,意味着走的全部是覆盖索引。
默认返回id,但是id不包含在索引里的话,就可能徽标
db.getIndexes()
{
"v" : 2,
"key" : {
"class_id" : 1,
"student_id" : 1
},
"name" : "class_id_1_student_id_1"
}
#要读取document
db.students.find({ class_id:54},{class_id:1}).explain("executionStats")
#不去读取document
db.students.find({ class_id:54},{class_id:1,_id:0}).explain("executionStats")效率较低的方式
$ne
$not 可能会用索引
但是$nin 一般都会导致扫表
$or 可能有多个索引。
Array的索引
索引虽然是array,但是实际上会加到具体的值上面
索引失效

唯一索引和部分索引
db.users.createIndex({"firstname" : 1}, {"unique" : true, "partialFilterExpression":{ "firstname": {$exists: true } } } )Aggregation
类似pipeline的操作,一个接着一个的阶段。
match、project、sort、skip、limit
match代表匹配
project代表需要哪些字段
db.companies.aggregate([
{$match: {founded_year: 2004}},
{$project: {
_id: 0,
name: 1,
founded_year: 1
}}
])
#结果
{"name": "Digg", "founded_year": 2004 }
{"name": "Facebook", "founded_year": 2004 }
{"name": "AddThis", "founded_year": 2004 }
{"name": "Veoh", "founded_year": 2004 }
...
# 1 0 代表有或者没有。$代表对应的字符
db.companies.aggregate([
{$match: {"funding_rounds.investments.financial_org.permalink": "greylock" }},
{$project: {
_id: 0,
name: 1,
ipo: "$ipo.pub_year",
valuation: "$ipo.valuation_amount",
funders: "$funding_rounds.investments.financial_org.permalink"
}}
]).pretty()sort代表排序
skip代表跳过
limit代表最终选取多少个
db.companies.aggregate([
{$match: {founded_year: 2004}},
{$limit: 5},
{$project: {
_id: 0,
name: 1}}
])
{"name": "Digg"}
{"name": "Facebook"}
{"name": "AddThis"}
{"name": "Veoh"}
#是按正常顺序过滤的。
# 如果先sort那么就
db.companies.aggregate([
{ $match: { founded_year: 2004 } },
{ $sort: { name: 1} },
{ $limit: 5 },
{ $project: {
_id: 0,
name: 1 } }
])
{"name": "1915 Studios"}
{"name": "1Scan"}
{"name": "2GeeksinaLab"}
{"name": "2GeeksinaLab"}
{"name": "2threads"}
#
db.companies.aggregate([
{$match: {founded_year: 2004}},
{$sort: {name: 1}},
{$skip: 10},
{$limit: 5},
{$project: {
_id: 0,
name: 1}},
])unwind 拆分每个列表
db.companies.aggregate([
{$match: {"funding_rounds.investments.financial_org.permalink": "greylock"} },
{$project: {
_id: 0,
name: 1,
amount: "$funding_rounds.raised_amount",
year: "$funding_rounds.funded_year"
}}
])
{
"name" : "Digg",
"amount" : [
8500000,
2800000,
28700000,
5000000
],
"year" : [
2006,
2005,
2008,
2011
]
}
{
"name" : "Facebook",
"amount" : [
500000,
12700000,
27500000,
...
#加上unwind
db.companies.aggregate([
{ $match: {"funding_rounds.investments.financial_org.permalink": "greylock"} },
{ $unwind: "$funding_rounds" },
{ $project: {
_id: 0,
name: 1,
amount: "$funding_rounds.raised_amount",
year: "$funding_rounds.funded_year"
} }
])
{"name": "Digg", "amount": 8500000, "year": 2006 }
{"name": "Digg", "amount": 2800000, "year": 2005 }
{"name": "Digg", "amount": 28700000, "year": 2008 }
{"name": "Digg", "amount": 5000000, "year": 2011 }
{"name": "Facebook", "amount": 500000, "year": 2004 }
{"name": "Facebook", "amount": 12700000, "year": 2005 }$filter 提前过滤
#$$ 代表引用
db.companies.aggregate([
{ $match: {"funding_rounds.investments.financial_org.permalink": "greylock"} },
{ $project: {
_id: 0,
name: 1,
founded_year: 1,
rounds: { $filter: {
input: "$funding_rounds",
as: "round",
cond: { $gte: ["$$round.raised_amount", 100000000] } } }
} },
{ $match: {"rounds.investments.financial_org.permalink": "greylock" } },
]).pretty()$arrayElemAt
db.companies.aggregate([
{ $match: { "founded_year": 2010 } },
{ $project: {
_id: 0,
name: 1,
founded_year: 1,
first_round: { $arrayElemAt: [ "$funding_rounds", 0 ] },
last_round: { $arrayElemAt: [ "$funding_rounds", -1 ] }
} }
]).pretty()
{
"name" : "vufind",
"founded_year" : 2010,
"first_round" : {
"id" : 19876,
"round_code" : "angel",
"source_url" : "",
"source_description" : "",
"raised_amount" : 250000,
"raised_currency_code" : "USD",
"funded_year" : 2010,
"funded_month" : 9,
"funded_day" : 1,
"investments" : [ ]
},
"last_round" : {
"id" : 57219,
"round_code" : "seed",
"source_url" : "",
"source_description" : "",
"raised_amount" : 500000,
"raised_currency_code" : "USD",
"funded_year" : 2012,
"funded_month" : 7,
"funded_day" : 1,
"investments" : [ ]
}
}$slice
db.companies.aggregate([
{ $match: { "founded_year": 2010 } },
{ $project: {
_id: 0,
name: 1,
founded_year: 1,
early_rounds: { $slice: [ "$funding_rounds", 1, 3 ] }
} }
]).pretty()$size
db.companies.aggregate([
{ $match: { "founded_year": 2004 } },
{ $project: {
_id: 0,
name: 1,
founded_year: 1,
total_rounds: { $size: "$funding_rounds" }
} }
]).pretty()Accumulators
$avg $sum $first $last $max $min $mergeObjects
#$max
db.companies.aggregate([
{ $match: { "funding_rounds": { $exists: true, $ne: [ ]} } },
{ $project: {
_id: 0,
name: 1,
largest_round: { $max: "$funding_rounds.raised_amount" }
} }
])
#$sum
db.companies.aggregate([
{ $match: { "funding_rounds": { $exists: true, $ne: [ ]} } },
{ $project: {
_id: 0,
name: 1,
total_funding: { $sum: "$funding_rounds.raised_amount" }
} }
])
Grouping
#id 实际的group的值,
db.companies.aggregate([
{ $group: {
_id: { founded_year: "$founded_year" },
average_number_of_employees: { $avg: "$number_of_employees" }
} },
{ $sort: { average_number_of_employees: -1 } }
])
#id field $push
db.companies.aggregate([
{ $match: { founded_year: { $gte: 2013 } } },
{ $group: {
_id: { founded_year: "$founded_year"},
companies: { $push: "$name" }
} },
{ $sort: { "_id.founded_year": 1 } }
]).pretty()
{
"_id" : {
"founded_year" : 2013
},
"companies" : [
"Fixya",
"Wamba",
"Advaliant",
"Fluc",
"iBazar",
"Gimigo",
"SEOGroup",
"Clowdy",
"WhosCall",
"Pikk",
"Tongxue",
"Shopseen",
"VistaGen Therapeutics"
]
}
db.companies.aggregate( [
{ $match: { "relationships.person": { $ne: null } } },
{ $project: { relationships: 1, _id: 0 } },
{ $unwind: "$relationships" },
{ $group: {
_id: "$relationships.person",
count: { $sum: 1 }
} },
{ $sort: { count: -1 } }
] )














 1047
1047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









