






一、项目背景
1、项目背景与意义
在当今互联网时代,互联网行业作为一个充满活力和不断创新的领域,吸引着无数求职者的目光。随着科技的迅猛发展,互联网行业不仅为人们提供了丰富的职业机会,同时也呈现出多样性和复杂性的特点。面对互联网行业的广泛选择,求职者往往陷入选择困难,而企业也需要更精准的招聘策略来适应不断变化的行业需求。因此,本项目旨在通过构建个性化行业适配模型,为求职者提供更准确的职业规划建议,同时为企业提供智能招聘决策支持。
个性化职业规划:传统的职业规划往往依赖于一般性的能力评估和就业市场分析,忽略了个体差异性的考量。在互联网行业的多元发展背景下,个体的技能和兴趣对于职业发展至关重要。本项目的意义之一在于通过构建个性化行业适配模型,为求职者提供更为精准的职业规划,帮助其更全面地了解自己的优势和劣势,从而更好地定位未来职业发展方向。
提高就业成功率:互联网行业的竞争激烈,求职者需要更具针对性的简历和求职策略。通过本项目的模型预测分析,求职者能够更有针对性地选择适合自己技能集的互联网行业领域,从而提高求职的成功率,减少不必要的时间和精力浪费。同时,求职者也能够对自己应该获得的薪酬有一个基本了解,大大增加了求职者在薪酬谈判过程中的筹码。
企业招聘流程优化:对于企业而言,招聘一直是一项复杂而关键的任务。了解互联网行业各个领域的技能需求,匹配合适的人才对企业的长期发展至关重要。通过本项目,企业可以更好地理解互联网行业人才市场,优化招聘流程,提高招聘效率,降低招聘成本。这样的优化不仅有助于企业更好地满足自身的发展需求,也对整个互联网行业的人才生态产生积极影响。
2、项目目标
本项目的核心目标是构建个性化行业适配模型和薪酬预测模型。个性化行业适配模型通过深度挖掘招聘信息中对于技能和工作的要求,为求职者提供个性化的职业规划建议,同时为企业提供优化招聘流程的智能决策支持。薪酬预测模型通过综合分析各个岗位的具体信息,实现岗位的薪酬预测。具体而言,我们希望达到以下几个方面的目标:
实现对招聘信息的深度挖掘,包括薪酬、城市、要求等方面的信息。
构建精准的个性化行业适配模型,通过机器学习技术,实现对个体适应不同互联网行业领域的预测。该模型主要利用了招聘信息训练,由于招聘信息中包含了大量对于求职者的技能要求,我们可以利用其分析求职者简历中的内容,从而实现个性化行业适配。
构建薪酬预测模型,通过机器学习技术,结合岗位以及技能等各方面的信息预测未来可能的薪酬。
二、数据获取
本项目的数据获取主要使用python爬虫技术爬取BOSS直聘网站上的招聘信息。BOSS直聘是一个拥有海量招聘信息的在线招聘平台,无论用户在哪个行业或领域,BOSS直聘都能够满足您用户的招聘需求。此外,BOSS直聘还提供了一系列实用的筛选功能,让用户能够根据自己的需求和条件筛选出最合适的职位。
图2-1BOSS直聘官网
由于BOSS直聘提供了筛选功能,所以本次爬取数据主要通过该功能获取互联网不同行业的招聘信息。主要根据以下关键词进行筛选:
后端:Java、C/C++、PHP、.NET
前端、移动开发:前端、Android、iOS、U3D
测试:测试、软件测试、自动化测试
运维:DBA、IT技术、网络安全
人工智能:nlp、机器学习、深度学习、图像算法、语音算法
BOSS直聘进行筛选后的职位列表页面和具体职位信息页面都不是静态界面,而是采用了动态加载的方法。使用传统的python爬虫代码爬取,只能获得关于加载的动态链接。所以本次爬虫主要使用 pyppeteer 库进行基于 Chrome的浏览器自动化,该技术可以模拟用户浏览网页的行为,从而实现网页的打开、操作、数据抓取等功能。该爬虫首先打开Chrome浏览器访问BOSS直聘的网站,接着在输入框输入搜索的关键词并返回搜索结果。然后抓取结果列表中的数据,并且打开每一个招聘连接抓取具体的招聘信息。当抓取完一个页面后,会自动翻页,一个关键词限制爬取10页的内容,共300条数据。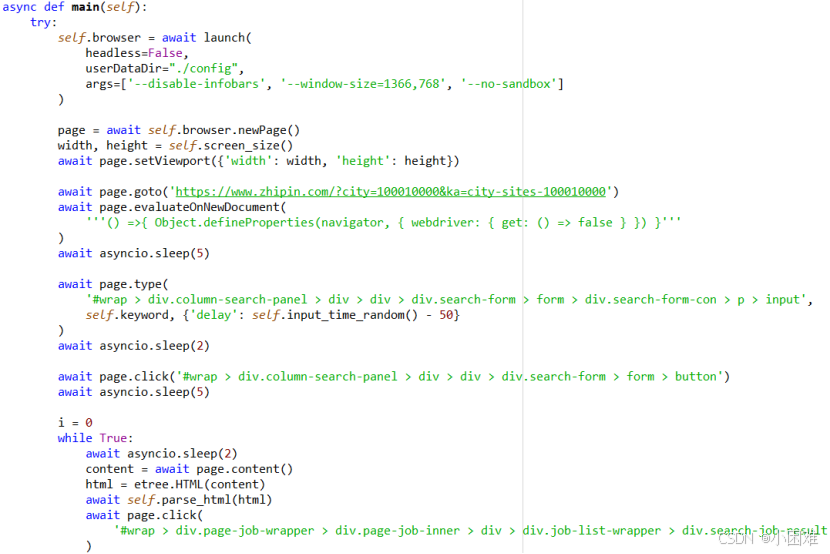
图2-2爬虫核心代码
图2-3爬虫结果展示
主要爬取了工作名称、薪水、地址、工作经验、学历、公司名称、公司类型、公司规模、职位要求、福利待遇、工作描述11列数据。
三、数据理解与数据准备
上面爬取数据主要是根据筛选条件分别爬取,所以这里要先做合并数据的操作。为了方便最后的行业预测,这里将数据按照类别分为后端、前端_移动开发、测试、运维、人工智能5类。在合并数据前给每一个数据添加一个class列存放类别。
图3-1添加类别
图3-2合并数据并保存
汇总之后一共有4949条数据,先使用自动探索性数据分析快速查看数据大致分布情况。
图3-3自动探索性数据分析
通过自动探索性分析,我们可以大致看到数据中“job_exp”、“job_edu”、“compan_type”、“company_scale”、“class”列有明显的分布情况,其他的数据多为离散数据,仍需进一步处理。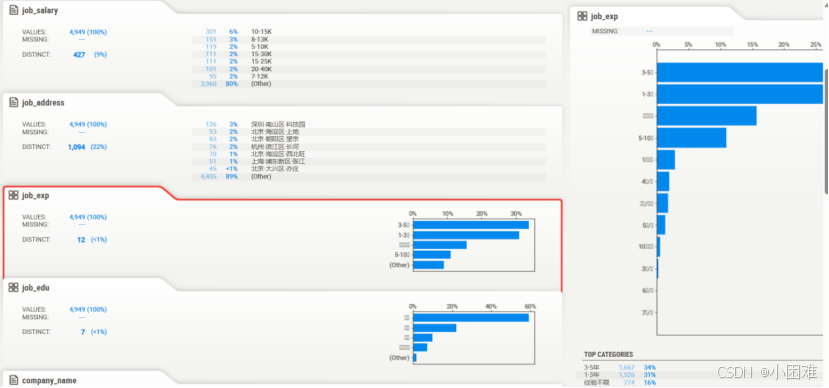
图3-4自动探索性数据分析结果
先处理“job_salary”列,该列的数据大致分为“15-30K”、“6-9K·14薪”、“150-300元/天”三种情况。我们可以利用字符串的函数提取出最低薪水和时间,计算年工资储存在“year_salary”列中。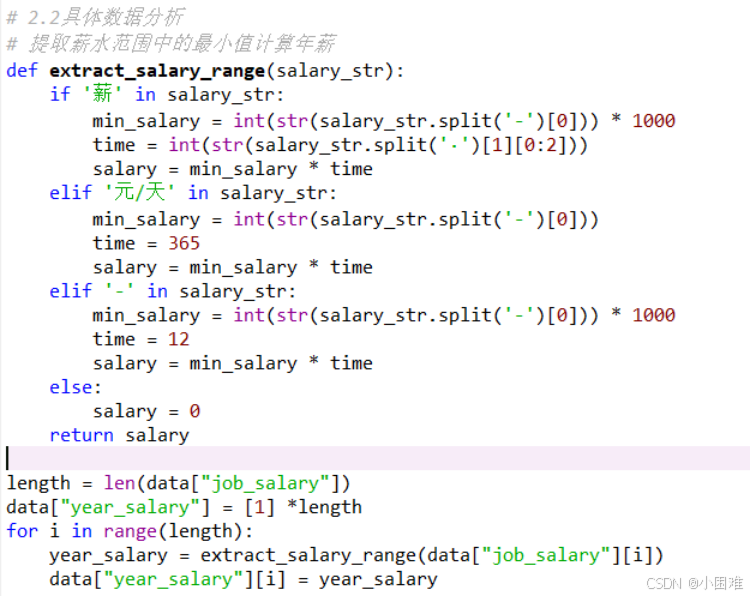
图3-5处理薪水列代码
然后是地址列,我们只关心工作所在的城市,数据大致呈“深圳·南山区·蛇口”这样的形式。同样是利用字符串函数提取出其中的城市信息储存在“city”列中。
由于最后建立的模型是用来分析求职者的简历的,所以我们使用的数据应该更偏于职位的描述和技能的要求,所以我们创建“text”列,将“demand”、“job_description”中的文本连接后储存在“text”列中,用作最后的建模使用。
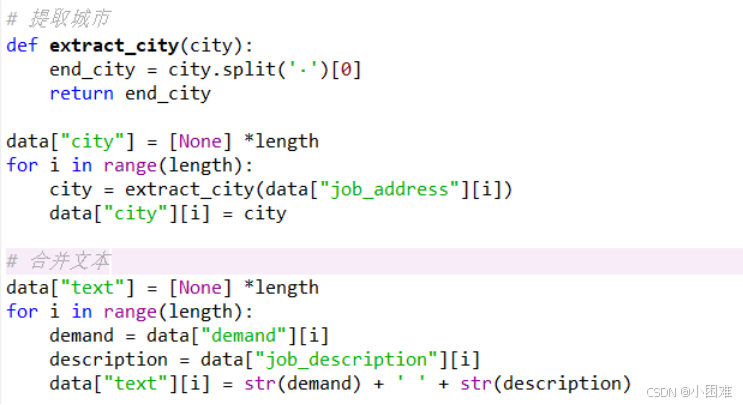
图3-6提取城市和合并文本
然后绘制关于城市数据的直方图,通过直方图我们可以发现就业城市分布还是较为广泛的。为了方便后续处理,我们只取样本量为前四的数据,其余数据转化为“其他”。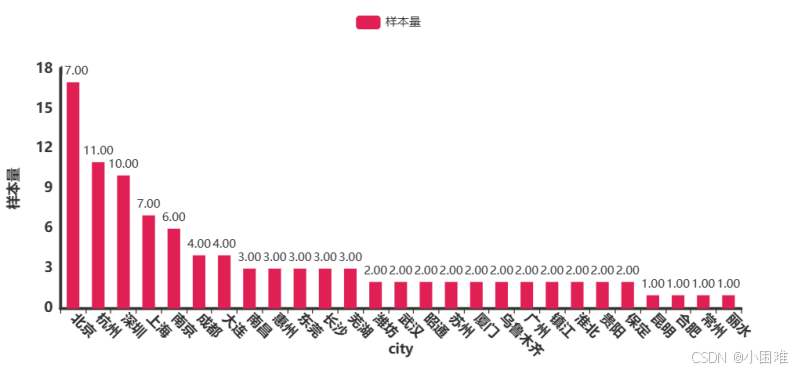
图3-7城市数据直方图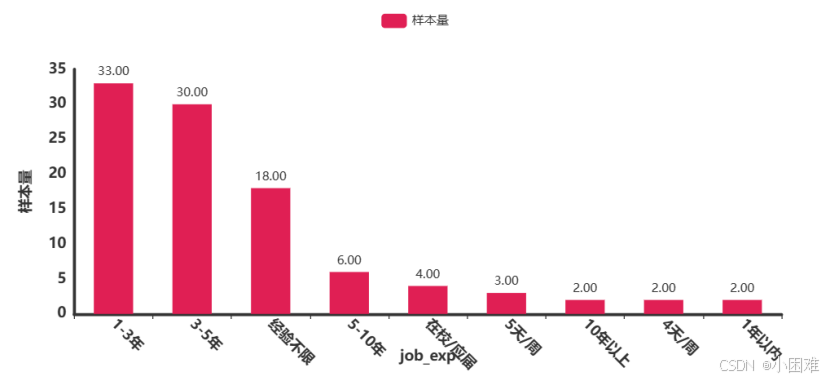
图3-8工作经验分布图
接着绘制如上图所示的工作经验分布图,可以看到其中有错误数据“5天/周”,“4天/周”,我们将其转化为“其他”。
工作经验图数据比较明显,本科是招聘需求量最大的。
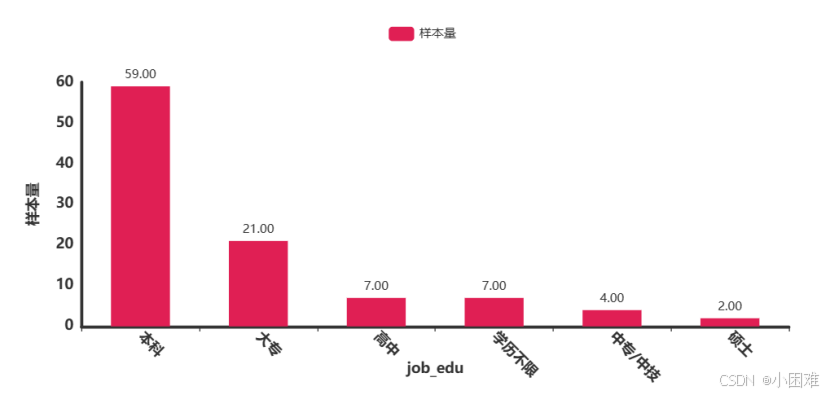
图3-9工作经验图
接下来先为行业分类模型准备数据,因为该模型最后希望的效果是处理文本数据,所以我们使用之前处理好的“text”列数据作为x, “class”列数据作为y。不过此时他们都还是文本数据,我们要先做一些处理。
先对“text”列文本进行分词、去停操作。
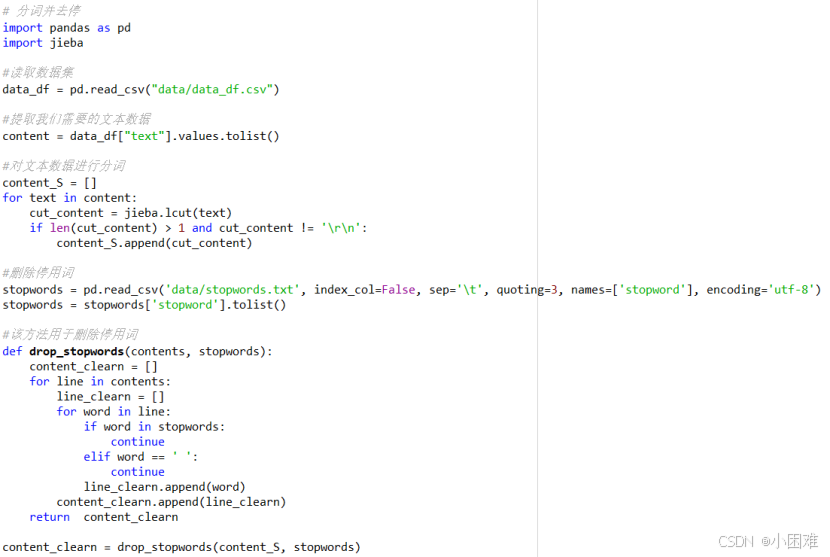
图3-10分词、去停
然后根据上面处理的结果构建词向量模型,方便后续根据词向量模型将文本数据转化为向量数据。这里构建特向量的维度为15,后面将一个文本数据转化为15列向量数据。

图3-11构建词向量
然后使用词向量模型将文本数据转化为向量数据。

图3-12文本数据转化
当然,最后预测的“class”列也需要使用标签编码转化。

图3-13标签编码
最后,将“class”列和“text”列处理后的结果汇总,得到data1作为行业分类模型的建模数据。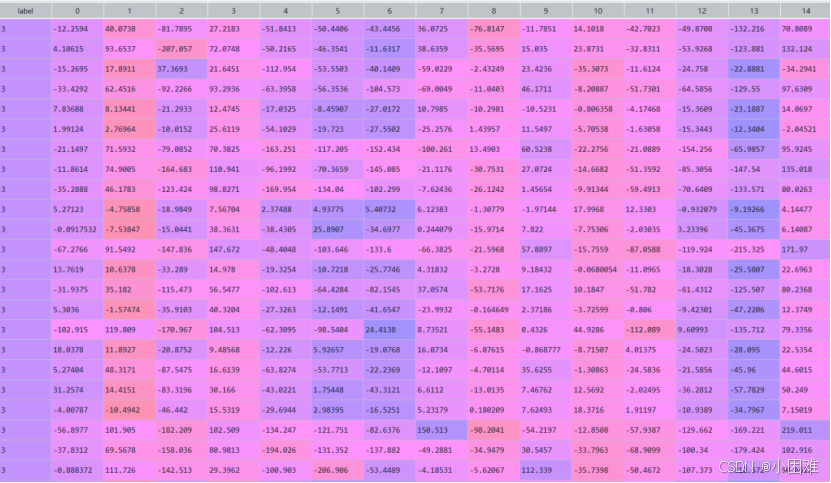
图3-14 data1
准备工资预测模型的数据,选择“class”,“city”,“job_exp”,“job_edu”,“text”列数据做x,“year_salary”列数据为y。
先将“class”,“city”,“job_exp”,“job_edu”都标签化处理,然后“text”的处理和之前一样,将变量数据汇总后做标准化处理。然后结合y得到data2。
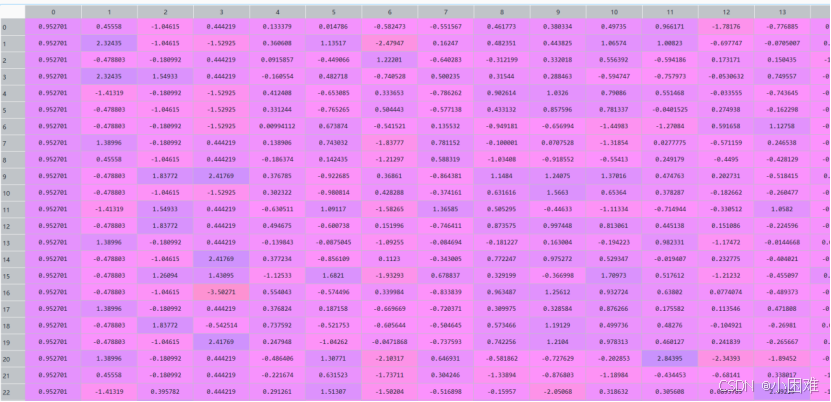
图3-15标准化后的数据
四、数据挖掘模型建立与评估
1、行业分类模型
行业分类模型建模部分,我以逻辑回归模型为例讲解。
首先,使用data1,划分训练集和测试集,然后用训练集拟合逻辑回归模型。该模型为分类模型,我主要使用以下评估指标:
精确率(Accuracy): 指分类正确的样本数占样本总数的比例,精确率越高模型效果越好。
查准率(Precision): 表示在模型识别为正类的样本中,真正为正类的样本所占的比例;查准率越高,说明模型的效果越好。
召回率(Recall): 模型正确识别出为正类的样本的数量占总的正类样本数量的比值;召回率越高,模型的效果越好。
F1-Score: 综合考虑 Precision 与 Recall的指标,F1值较高时则说明模型性能较好。
AUC Score: ROC 曲线下面积,正样本的预测结果大于负样本的预测结果的概率,本质是AUC反应的是分类器对样本的排序能力。AUC值越接近1,ROC曲线越接近左上角,则该分类器的性能越好。
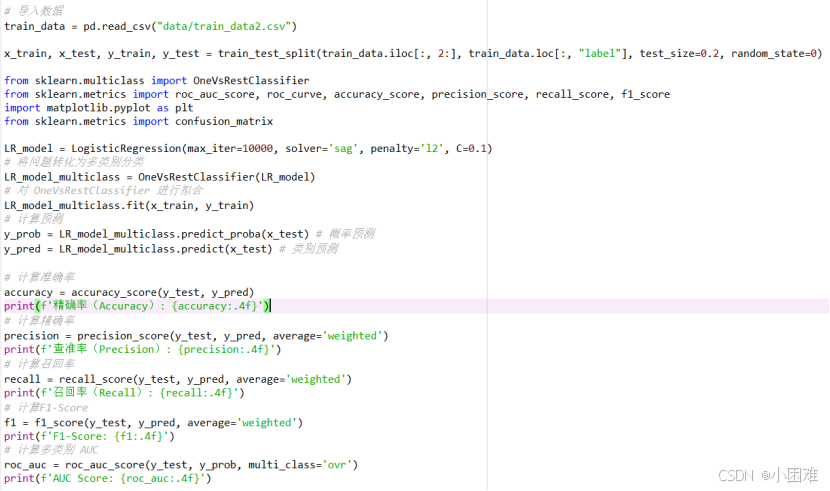
图4-1建模代码
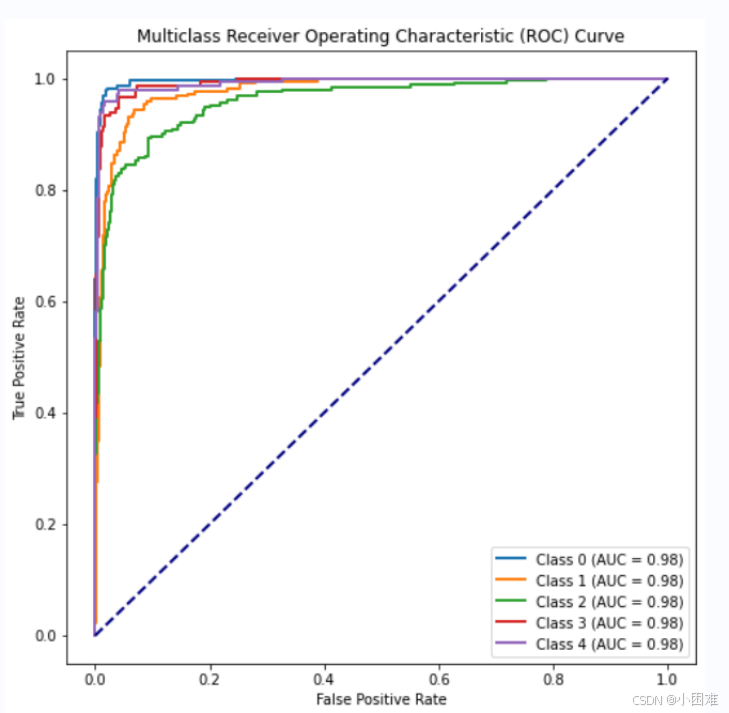
图4-2ROC曲线
最后得出精确率为0.9091,查准率为0.9098,召回率为0.9091,F1-Score为0.9088,AUC为0.9836。通过这些评估指标,我们可以得出该模型的效果比较好,
同时ROC曲线也接近左上角,表明该分类器的性能较好。
由于模型的效果较好,此处没有做超参数调优。不过,为了验证模型在不同数据集上的效果相同,使用了交叉验证,以精确度为评估指标。
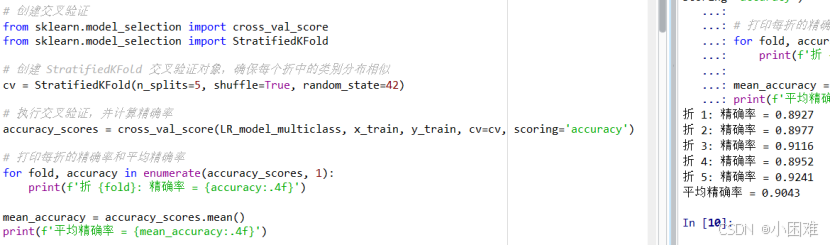
图4-3五折交叉验证
使用了5折交叉验证,最后结果如上图所示,证明模型在不同的数据集上表现效果接近,模型泛化能力较强。
然后,我又尝试了以下三种常见的分类算法。最后结果如下表所示:
表4-1分类算法结果汇总
| 算法 | 精确率 | 查准率 | 召回率 | F1-score | AUC |
| 逻辑回归 | 0.9091 | 0.9098 | 0.9091 | 0.9088 | 0.9836 |
| KNN | 0.8980 | 0.8988 | 0.8980 | 0.8979 | 0.9859 |
| xgboost | 0.9758 | 0.9758 | 0.9758 | 0.9758 | 0.9982 |
该结果中xgboost算法的结果明显不正常,属于过拟合的情况。可能是由于该数据集过小,导致数据在较复杂的模型上容易过拟合。逻辑回归和KNN算法实现的模型效果较好。
2、薪酬预测模型
薪酬预测模型建模部分,我以决策树回归模型为例讲解。
首先,使用data2,划分训练集和测试集,然后用训练集拟合决策树回归模型。该模型为回归模型,我主要使用以下评估指标:
平均绝对误差 (MAE):预测误差的绝对值的平均值。较小的MAE表示模型的预测误差相对较小,对异常值不敏感。
平均绝对百分误差 (MAPE):预测误差的百分比的平均值。低百分比表示模型的百分比误差相对较小。
均方误差 (MSE):预测误差的平方的平均值。较小的MSE表示模型的预测误差相对较小,对较大误差更为敏感。
均方根误差 (RMSE):RMSE是MSE的平方根。较小的RMSE表示模型的预测误差相对较小,与MSE相似,但更容易解释。
决定系数 (R^2):R^2衡量了模型对总方差的解释程度,取值范围在0到1之间。较接近1的R^2表示模型能够很好地解释目标变量的变化。
图4-4回归算法代码
最后我尝试了几种主要的回归算法,得到下表:
表4-2回归算法结果汇总
| 算法 | MAE | MAPE | MSE | RMSE | R^2 |
| 线性回归 | 290064.1025 | 1.5084 | 5851347721761.2227 | 2418955.9156 | 0.0051 |
| 决策树回归 | 21144.8990 | 0.1427 | 6928485719.6970 | 83237.5259 | 0.9988 |
| 支持向量机回归 | 231400.3775 | 0.6583 | 5914708620447.3213 | 2432017.3972 | -0.0057 |
| K近邻回归 | 178274.0606 | 0.6081 | 3886798940046.4648 | 1971496.6244 | 0.3391 |
| 随机森林回归 | 116698.7222 | 0.6982 | 1205227825188.4092 | 1097828.6866 | 0.7951 |
通过算法结果汇总,我们可以发现,决策树回归算法实现的模型效果最好,MAPE误差只有0.1427。

















 2573
2573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









