







一、前置条件
1. linux,已经搭建好的logstash+es+kibana【系列版本7.0X】,es 的plugs中安装ik分词器
ES版本:
Logstash版本:
(以上部署,都是运维同事搞的,我不会部署,同事给力)
二、编写Logstash.sh 执行文件
1、在Logstash安装目录下【/usr/share/logstash】,新建XX.sh,内容如下:
/usr/share/logstash/bin/logstash --path.data /usr/share/logstash/case-conf -e 'input {
jdbc {
jdbc_driver_library => "/var/local/logstash/etc/lib/mysql-connector-java-8.0.15.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://IP:端口号/数据库?serverTimezone=Asia/Shanghai&autoReconnect=true&allowMultiQueries=true&zeroDateTimeBehavior=convertToNull&characterEncoding=utf8&useSSL=false&tinyInt1isBit=false"
jdbc_user => "用户名"
jdbc_password => "密码"
schedule => "* * * * *"
use_column_value => true
tracking_column => "update_at"
tracking_column_type => "numeric"
last_run_metadata_path => "/usr/share/logstash/case-last"
statement_filepath => "/usr/share/logstash/case_.sql"
}
}
output {
elasticsearch {
hosts => ["es1:9206","es2:9207","es3:9208"]
action=>"index"
index => "case"
document_id => "%{case_id}"
template => "/usr/share/logstash/template-case.json"
template_name=>"template-case.json"
template_overwrite=>true
}
}'
2. 在Logstash安装目录下【/usr/share/logstash】,新建case.sql文件:查询字段,根据业务要求书写,不需要全字段查询
SELECT * FROM 表名称 where update_at > :sql_last_value
where条件中的,update_at 是表更新时间,与case.sh 中的 tracking_column 强关联;默认logstash 每分钟执行一次case.sql ,执行后会生成一个case-last文件,里面记录最后一次执行时间;
3. 关于output,配置项,使用了自定义创建索引的模板方式,在表中有数据为前提,执行case.sh 会用到模板创建索引;如果不配置,es会默认给创建mapping,默认的话,分词都是英文分词器; 执行效果如下:sh case.sh后:
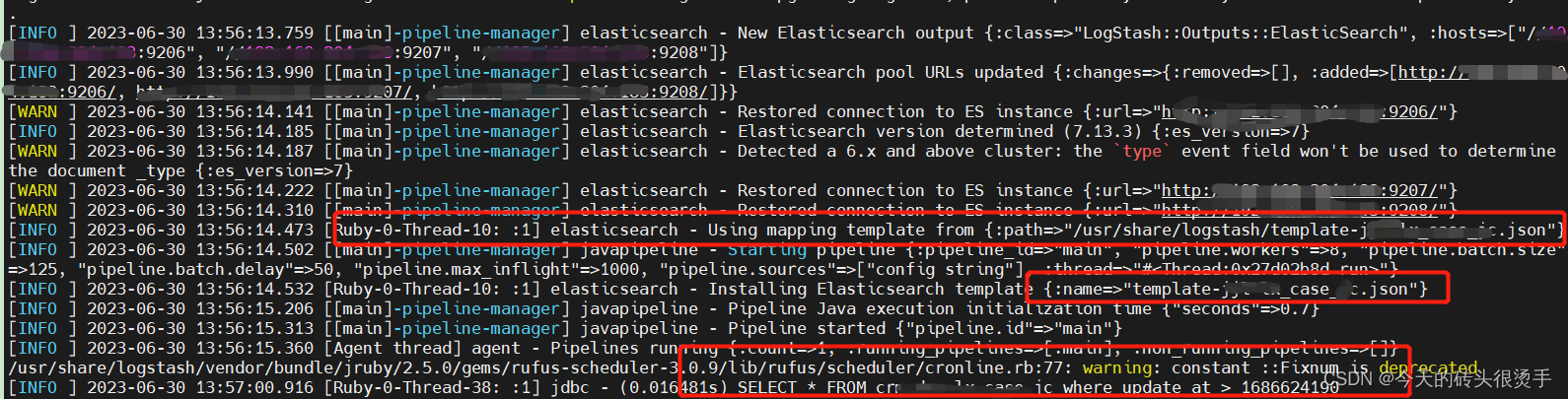
注意细节:
output {
elasticsearch {
hosts => []
action=>"index"
index => "case" //索引名称
document_id => "%{case_id}" //动态数据,数据ID
template => "/usr/share/logstash/template-case.json" //模板文件路径
template_name=>"template-case.json" //模板名称
template_overwrite=>true
}
}
4. 在Logstash安装目录下【/usr/share/logstash】,新建template-case.json,内容如下:
{
"template" : "case*",
"settings" : {
"index.refresh_interval" : "5s",
"number_of_replicas":"1",
"number_of_shards":"1"
},
"mappings": {
"date_detection": false,
"numeric_detection": false,
"dynamic_templates": [
{
"integers": {
"match_mapping_type": "long",
"mapping": {
"type": "integer"
}
}
},
{
"strings": {
"match_mapping_type": "string",
"unmatch": "*_en",
"mapping": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 100
}
}
}
}
}
]
}
}
注意:
1、模板名称和case.sh 中的index 匹配;模板中的名称后必须带个*: "template" : "case*",
2、模板比较简单,关闭了日期动态检测和数字格式动态检测;不然创建索引的时候格式会乱;尤其是日期;比如数据库中字段是varchar,但是存的是yyyy-MM-dd hh:mm:ss 日期格式的话,es创建索引是date格式的;
"date_detection": false,
"numeric_detection": false,
3、string格式的字段,默认给转出text, 并且使用ik分词器;排除了_en结尾的字段,存英文的字段建表的时候注意下,使用默认分词就好;
"unmatch": "*_en"
三、Kibana验证
1、GET case_/_mapping:
{
"case" : {
"mappings" : {
"dynamic_templates" : [
{
"integers" : {
"match_mapping_type" : "long",
"mapping" : {
"type" : "integer"
}
}
},
{
"strings" : {
"unmatch" : "*_en",
"match_mapping_type" : "string",
"mapping" : {
"analyzer" : "ik_max_word",
"fields" : {
"raw" : {
"ignore_above" : 100,
"type" : "keyword"
}
},
"search_analyzer" : "ik_smart",
"type" : "text"
}
}
}
],
"date_detection" : false,
"numeric_detection" : false,
"properties" : {
"@timestamp" : {
"type" : "text",
"fields" : {
"raw" : {
"type" : "keyword",
"ignore_above" : 100
}
},
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart"
},
"@version" : {
"type" : "text",
"fields" : {
"raw" : {
"type" : "keyword",
"ignore_above" : 100
}
},
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart"
},
"apply_education" : {
"type" : "text",
"fields" : {
"raw" : {
"type" : "keyword",
"ignore_above" : 100
}
},
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart"
},
"apply_major_en" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"apply_school_name" : {
"type" : "text",
"fields" : {
"raw" : {
"type" : "keyword",
"ignore_above" : 100
}
},
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart"
},
"apply_school_name_en" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"begin_learn_time_at" : {
"type" : "integer"
},
"case_id" : {
"type" : "integer"
},
"case_result_time_at" : {
"type" : "integer"
},
"country_name" : {
"type" : "text",
"fields" : {
"raw" : {
"type" : "keyword",
"ignore_above" : 100
}
},
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart"
},
"school_id" : {
"type" : "integer"
},
"update_at" : {
"type" : "integer"
}
}
}
}
}查看,映射字段是否满足要求;
2. 验证索引分词结果:
GET case/_analyze
{
"field": "apply_education",
"text": "马斯特里赫特大学"
}
分词结果:
{
"tokens" : [
{
"token" : "马斯特里赫特",
"start_offset" : 0,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "马斯",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "特里",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "赫",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "特大",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "大学",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 5
}
]
}验证完成;
四、相关资料
1. Elastic:开发者上手指南_elastic.show_Elastic 中国社区官方博客的博客-CSDN博客
2. Mutate filter plugin | Logstash Reference [8.8] | Elastic
五、注意事项
1. 此种方法,只能针对表数值为逻辑删除的情况,若业务是物理删除,则需要同步删除索引中的数据;
2. 所有update 操作,都需要同时修改 update_at 字段














 5121
5121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









