









Transformer简介
Transformer模型来自论文Attention Is All You Need。这个模型最初是为了提高机器翻译的效率,它的Self-Attention机制和Position Encoding可以替代RNN。因为RNN是顺序执行的,t时刻没有完成就不能处理t+1时刻,因此很难并行。但是后来发现Self-Attention效果很好,在很多其它的地方也可以使用Transformer模型。这包括著名的OpenAI GPT和BERT模型,都是以Transformer为基础的。BERT只使用了Transformer的Eecoder部分,没有Decoder,所以Eecoder只有Self-Attention而没有普通的Attention。OpenAI GPT使用的是Decoder部分,没有使用encoder部分。
transformer概述
我们先用一个机器翻译的例子来介绍transformer,首先把模型看成一个黑盒子,输入与输出如下图所示。
把黑盒子稍微打开一点,Transformer(或者任何的NMT系统)都可以分成Encoder和Decoder两个部分,如下图所示。
再展开一点,Encoder由很多(6个)结构一样的Encoder堆叠(stack)而成,Decoder也是一样。如下图所示。注意:每一个Encoder的输出是下一层Encoder输入,最底层Encoder的输入是原始的输入(法语句子);Decoder也是类似,但是最后一层Encoder的输出会输入给每一个Decoder层,这是Attention机制的要求。

每一层的Encoder都是相同的结构,它由一个Self-Attention层和一个前馈网络(全连接网络)组成,如下图所示。
每一层的Decoder也是相同的结构,它除了Self-Attention层和全连接层之外还多了一个普通的Attention层,这个Attention层使得Decoder在解码时会考虑最后一层Encoder所有时刻的输出。它的结构如下图所示。
Self-Attention简介
self-attention做的是当对词做编码的时候,不仅仅要考虑当前这个词,还要考虑当前词所处的上下文语境。要将整个上下文语境融入到词向量当中。
比如我们要翻译如下句子”The animal didn’t cross the street because it was too tired”(这个动物无法穿越马路,因为它太累了)。这里的it到底指代什么呢,是animal还是street?要知道具体的指代,我们需要在理解it的时候同时关注所有的单词,重点是animal、street和tired,然后根据知识(常识)我们知道只有animal才能tired,而street是不能tired的。Self-Attention用Encoder在编码一个词的时候会考虑句子中所有其它的词,从而确定怎么编码当前词。如果把tired换成narrow,那么it就指代的是street了。
而LSTM(即使是双向的)是无法实现上面的逻辑的。为什么呢?比如前向的LSTM,我们在编码it的时候根本没有看到后面是tired还是narrow,所有它无法把it编码成哪个词。而后向的LSTM呢?当然它看到了tired,但是到it的时候它还没有看到animal和street这两个单词,当然就更无法编码it的内容了。
当然多层的LSTM理论上是可以编码这个语义的,它需要下层的LSTM同时编码了animal和street以及tired三个词的语义,然后由更高层的LSTM来把it编码成animal的语义。但是这样模型更加复杂。

Self-Attention的计算方法
从宏观上看
在输入句子后,将每一个词都编码过Embedding把它变成一个连续稠密的向量。下图是embedding后的向量。
Embedding之后的序列会输入Encoder,首先经过Self-Attention层然后再经过全连接层,如下图所示。
我们在计算zi时需要依赖所有时刻的输入x1,…,xn,不过我们可以用矩阵运算一下子把所有的zizi计算出来(后面介绍)。而全连接网络的计算则完全是独立的,计算i时刻的输出只需要输入zi就足够了,因此很容易并行计算。下图更加明确的表达了这一点。图中Self-Attention层是一个大的方框,表示它的输入是所有的x1,…,xn,输出是z1,…,zn。而全连接层每个时刻是一个方框(但不同时刻的参数是共享的),表示计算ri只需要zi。此外,前一层的输出r1,…,rn直接输入到下一层。
详细介绍
对于输入的每一个向量(第一层是词的Embedding,其它层是前一层的输出),我们首先需要生成3个新的矩阵Q、K和V。Q表示为了编码当前词,需要去注意(attend to)其它(其实也包括它自己)的词,我们需要有一个查询向量。而Key向量可以认为是这个词的关键的用于被检索的信息。而Value向量是真正的内容,可以理解为特征信息。下图中的W是训练得到的权重矩阵。

具体的计算过程如下图所示。比如图中的输入是两个词”thinking”和”machines”,我们对它们进行Embedding(这是第一层,如果是后面的层,直接输入就是向量了),得到向量x1,x2。接着我们用3个矩阵分别对它们进行变换,得到向量q1,k1,v1和q2,k2,v2。比如q1=x1WQ,图中x1的shape是1x4,WQ是4x3,得到的q1是1x3。其它的计算也是类似的,为了能够使得Key和Query可以内积,我们要求WK和WQ的shape是一样的,但是并不要求WV和它们一定一样(虽然实际论文实现是一样的)。

每个时刻t都计算出Qt,Kt,Vt之后,我们就可以来计算Self-Attention了。以第一个时刻为例,我们首先计算q1和k1,k2的内积,得到score。接下来使用softmax把得分变成概率,注意这里把得分除以8(根号下dk)之后再计算的softmax,根据论文的说法,这样计算梯度时会更加稳定(stable)。向量纬度不同计算的內积大小自然会受影响,所以除以根号dk还有一个作用就是排除向量纬度的影响。计算过程如下图所示。
接下来用softmax得到的概率对所有时刻的V求加权平均,这样就可以认为得到的向量根据Self-Attention的概率综合考虑了所有时刻的输入信息,计算过程如下图所示。
这整个过程就是self-Attention的计算过程。
当然在真正计算的过程中并不是一个一个向量的计算的,而是直接进行矩阵计算的。一个一个向量代表一个词语,一个矩阵则代表整个句子的编码。第一步还是计算Q、K和V,不过不是计算某个时刻的qt,kt,vt了,而是一次计算所有时刻的Q、K和V。计算过程如下图所示。这里的输入是一个矩阵,该矩阵是整个句子向量表示,矩阵的第i行表示第i个时刻的输入xi。
接下来就是计算Q和K得到score,然后除以根号dk,然后再softmax,最后加权平均得到输出。全过程如下图所示。
Multi-Head机制
Multi-Head Attention的概念是指前面定义的一组Q、K和V可以让一个词attend to相关的词,我们可以定义多组Q、K和V,它们分别可以关注不同的上下文。计算Q、K和V的过程还是一样,这不过现在变换矩阵从一组(WQ,WK,WV)变成了多组(WQ0,WK0,WV0),(WQ1,WK1,WV1),…。如下图所示。
对于输入矩阵(time_step, num_input),每一组Q、K和V都可以得到一个输出矩阵Z(time_step, num_features)。如下图所示。
通常情况下做8组特征提取。此过程类似于卷积神经网络中的卷积操作。

然后通过乘上一个全连接层进行降维。后面的全连接网络需要的输入是一个矩阵而不是多个矩阵,因此我们可以把多个head输出的Z按照第二个维度拼接起来,但是这样的特征有一些多,因此Transformer又用了一个线性变换(矩阵WO)对它进行了压缩。这个过程如下图所示。
上面的步骤涉及很多步骤和矩阵运算,我们用一张大图把整个过程表示出来,如下图所示。

下图中红色的先和绿色的先分别是不同的头得到的结果。会发现没个词会跟自己附近的词注意力越大。

堆叠多层
下图中输入是向量,输出也是向量。刚开始的x1和x2分别只是表示自己,通过一个self-attention之后,得到的z1融入了x1和x2的信息,z2融入了x1和x2 的信息。在下图中暂时没有画出多头(multi-head)机制,然后输入到全连接中进行降维,得到了一组新的向量r1和r2。由于得到的还是向量,所以依然可以在上面加上一层encoder,计算方法和第一层一样。

位置编码(Positional Encoding)
在self-attention中每个词都会考虑整个序列的加权,所以其出现位置并不会对结果产生什么影响,相当于放哪都无所谓,但是这跟实际就有些不符合了,我们想模型对位置有额外的认识。这是Transformer原始论文使用的位置编码方法,而在BERT模型里,使用的是简单的可以学习的Embedding,和Word Embedding一样,只不过输入是位置而不是词而已。
我们的目的是用Self-Attention替代RNN,RNN能够记住过去的信息,这可以通过Self-Attention“实时”的注意相关的任何词来实现等价(甚至更好)的效果。RNN还有一个特点就是能考虑词的顺序(位置)关系,一个句子即使词完全是相同的但是语义可能完全不同,比如”北京到上海的机票”与”上海到北京的机票”,它们的语义就有很大的差别。我们上面的介绍的Self-Attention是不考虑词的顺序的,如果模型参数固定了,上面两个句子的北京都会被编码成相同的向量。但是实际上我们可以期望这两个北京编码的结果不同,前者可能需要编码出发城市的语义,而后者需要包含目的城市的语义。而RNN是可以(至少是可能)学到这一点的。当然RNN为了实现这一点的代价就是顺序处理,很难并行。
为了解决这个问题,我们需要引入位置编码,也就是t时刻的输入,除了Embedding之外(这是与位置无关的),我们还引入一个向量,这个向量是与t有关的,我们把Embedding和位置编码向量加起来作为模型的输入。这样的话如果两个词在不同的位置出现了,虽然它们的Embedding是相同的,但是由于位置编码不同,最终得到的向量也是不同的。
位置编码有很多方法,其中需要考虑的一个重要因素就是需要它编码的是相对位置的关系。比如两个句子:”北京到上海的机票”和”你好,我们要一张北京到上海的机票”。显然加入位置编码之后,两个北京的向量是不同的了,两个上海的向量也是不同的了,但是我们期望Query(北京1)Key(上海1)却是等于Query(北京2)Key(上海2)的。位置编码加入后的模型如下图所示。
归一化(LayerNorm)
在此可以对比一下Batch Normalization,这个技巧能够让模型收敛的更快。但是Batch Normalization有一个问题——它需要一个minibatch的数据,而且这个minibatch不能太小(比如1)。另外一个问题就是它不能用于RNN,因为同样一个节点在不同时刻的分布是明显不同的。当然有一些改进的方法使得可以对RNN进行Batch Normalization,比如论文Recurrent Batch Normalization,有兴趣的读者可以自行阅读 。Transformer里使用了另外一种Normalization技巧,叫做Layer Normalization。
假设我们的输入是一个minibatch的数据,我们再假设每一个数据都是一个向量,则输入是一个矩阵,每一行是一个训练数据,每一列都是一个特征。BatchNorm是对一行数据进行处理,而LayerNorm是对一列数据进行计算的。使得这一列数据的均值为0,标准差为1。

BachNorm的计算公式如下所示:

layerNorm 的计算公式如下所示

残差连接
每个Self-Attention层都会加一个残差连接,然后是一个LayerNorm层。
基本的残差连接方式:保留原来一份x,避免x做完一系列运算得到的F(x)效果不如以前,简称留一手准备。
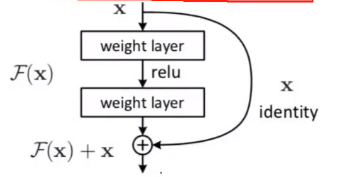
那么在transformer中的残差连接如下如所示。输入x1,x2经self-attention层之后变成z1,z2,然后和残差连接的输入x1,x2加起来,然后经过LayerNorm层输出给全连接层。全连接层也是有一个残差连接和一个LayerNorm层,最后再输出给上一层。
最终结果

整体架构图
Decoder和Encoder是类似的,如下图所示,区别在于它多了一个Encoder-Decoder Attention层,这个层的输入除了来自Self-Attention之外还有Encoder最后一层的所有时刻的输出。Encoder-Decoder Attention层的Query来自下一层,而Key和Value则来自Encoder的输出。
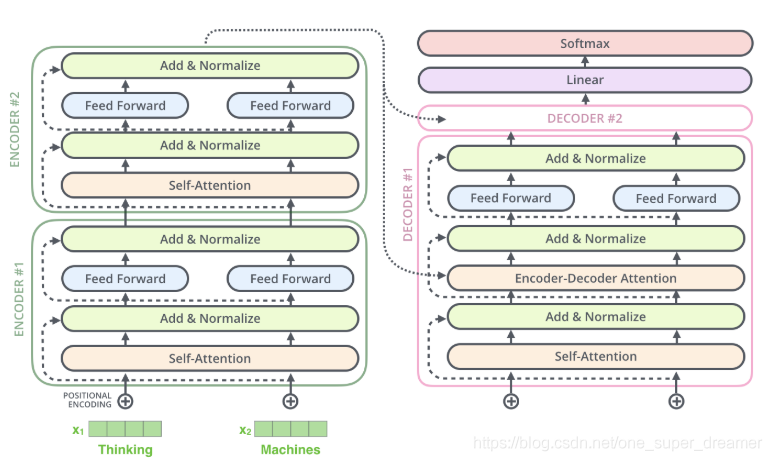
在decoder的self-attention中加入了mask机制,在对每个词做编码的时候,只能用之前已有的,后面没出结果的不能利用。

本文是学习这篇文章的学习笔记Transformer图解 - 李理的博客,大家可以前去阅读,博主写的挺好的。我在本文中加了一些自己的理解。














 786
786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









