







深度自动编码器(Deep Auto-encoder)
本文是学习B站上李宏毅老师的机器学习笔记。
Auto-encoder
它做的事情和PCA、t-SNE一样,都是要降维。只是这里用网络结构来降维,降维的网络被称为Encoder,这个Encoder就是很多个隐层网络的网络结构,输入一张图片后会输出降维以后的结果。这个结果比PCA的结果复杂是因为它不是一个线性的东西。
通用有一个Decoder也是网络结构,输入降维的图片会输出原来的图片。
由于encoder和decoder独自存在的时候无法学,所以将它们连接在一起后就可以学了。

PCA:
输入一个vector X,乘上一个W得到c,再乘上W的转置。
可以将PCA的过程当做网络结构来看

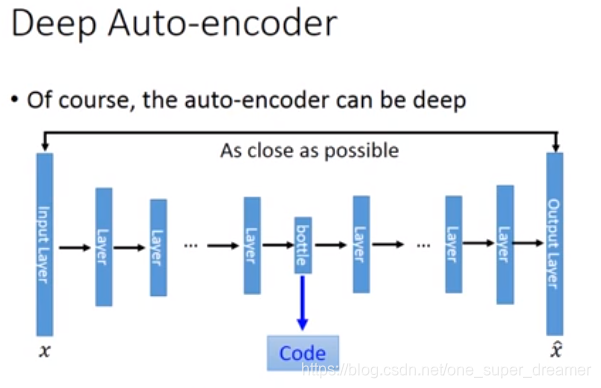
Deep Auto-encoder:
它和PCA比起来可以理解为多加了几个隐藏层网络。
PCA和Deep Auto-encoder的结果比较:

我们主要是看coder做的有多好,可以看到不同的方法降维到2维后的区别。

De-noising auto-encoder可以让Auto-encoder训练的更好
它会在input上面加上noise,然后进行编码和解码。还必需解码到加noise前的图片。

Auto-encoder被用在文字上的例子:搜索引擎上查找功能
Vector Space Model:把每一个document和query用一个vector 来描述,接下来计算每一个query和document的相似度,看query和哪个document的相似度比较高,那它就是搜索的结果。
那如何将一个document描述成一个vector呐?最常用的就是词袋(Bag-of-Word),它是将每一个句子都表示成一个列向量,列向量的维数就是现有所有词汇的个数。 如果现在世界上有10w个词,那vector的维数就是10w。这样的话一个句子中出现的词处的数值是1,其他的都是0。但是它的坏处就是没有考虑到词语的语义。

一个搜索引擎要想做好的话就必须考虑到语义。
现在有一个方法就是叠一个auto-encoder,假设有2000个词,将这两千个词降维到2维。也就是说每一个文章都是2维空间上的一个点。同样将一个query也降维到2维空间,然后把这些点可视化。计算query和那些点的相似度。这样就可以找到与query相同的同类文章。
每一个点代表一个新闻,不同颜色的点代表不同类别的新闻。

Auto-encoder也可以做影像搜寻
计算输入的图片和数据集中图片的相似度。
先学习一个encoder和decoder,进行解码和编码。

CNN来处理
使用CNN来处理更有效。

在做Pool的时候是在filter的输出中四个一组选最大的,除了选最大的以外,我们还要知道谁是最大的。在做Unpooling的时候就是把每一个像素扩展成四个像素,其实就是max pooling的相反。max Pooling取出最大所放的位置在扩展成四个像素后依然在对应的位置,对于那个max Pooling丢掉的值不知道是多少就补0。
所以Pooling会把图片变小,而Unpooling会把图片变大。

Convolution是把同一个filter乘上不同的input和一样的weight得到输出。
Deconvolution就反过来,原来是三个value乘上不同的weight得到一个输出,而这里则是一个输入乘上不同的weight得到三个输出。做完后会有一部分输出的位置重叠,然后再把重叠的地方加起来。
上面的Deconvolution就相当于给除了那三个输入外补上0,然后在做卷积(Convolution)
















 4537
4537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









