






MAPPO动作类型改进(一)——MAPPO+离散环境
说明
应广大学者的需求,针对GitHub上最新版本的light_mappo,给大家说明一下如何实现基于最新版代码+离散环境
代码地址:https://github.com/tinyzqh/light_mappo
环境地址:https://pettingzoo.farama.org/environments/mpe/simple_spread/
环境说明:多智能体训练通用环境,用最简单的MPE给大家做实例,方便大家加入自己的环境。下面所有代码更改都是基于原版代码,所以大家按照我的步骤来肯定能够复现跟我一样的结果。
新版light_mappo说明
先给大家说明一下最新版的light_mappo,新版的较之前的实质内容上没怎么改动,大家不用太纠结用新的还是旧的,新版多了env_continous.py和env_discrete.py,这两个是选择离散环境还是连续环境的,这两个不同改,主要改的还在env_core.py文件
第一步:设置为离散环境模式
在train文件中,def make_train_env(all_args)是设置训练时env相关的,默认的是from envs.env_continuous import ContinuousActionEnv即用的是连续的(连续环境的下期再出),这里需要给下,改成离散的
def init_env():
# TODO 注意注意,这里选择连续还是离散可以选择注释上面两行,或者下面两行。
# TODO Important, here you can choose continuous or discrete action space by uncommenting the above two lines or the below two lines.
# from envs.env_continuous import ContinuousActionEnv
#
# env = ContinuousActionEnv()
from envs.env_discrete import DiscreteActionEnv
env = DiscreteActionEnv()
env.seed(all_args.seed + rank * 1000)
return env
第二步:接入离散环境
import numpy as np
from pettingzoo.mpe import simple_spread_v3
class EnvCore(object):
"""
# 环境中的智能体
"""
def __init__(self):
self.env = simple_spread_v3.parallel_env(render_mode="human", N=3, local_ratio=0.5, max_cycles=30,
continuous_actions=False)
#智能体个数N=3,
# local_ratio:适用于本地奖励和全球奖励的权重。全局奖励权重将始终为 1 - 本地奖励权重。
# max_cycles:游戏终止前的帧数(每个代理一个步骤)
# continuous_actions:代理操作空间是离散的(默认)还是连续的
self.agent_num = 3 #环境simple_spread_v3中Agents = 3 = N
self.obs_dim = 18 #环境simple_spread_v3中Observation Shape = 18
self.action_dim =5 #环境simple_spread_v3中Action Shape = 5
def reset(self):
"""
# 重置环境,simple_spread_v3环境自带了reset函数,可直接使用
"""
sub_agent_obs = []
observations, infos = self.env.reset()
for agent in self.env.agents:
sub_agent_obs.append(observations[agent])
return sub_agent_obs
def step(self, actions):
sub_agent_obs = []
sub_agent_reward = []
sub_agent_done = []
sub_agent_info = []
i = 0 # 初始化计数器
actions_step = {} # 创建一个空字典来存储动作
# 假设env.agents是一个包含所有智能体的列表
# 并且actions是一个包含所有动作的列表
for agent in self.env.agents:
if i < len(actions): # 确保不会超出actions列表的索引范围
actions_step[agent] = actions[i][0] # 将智能体映射到对应的动作
i += 1 # 递增计数器
observations, rewards, terminations, truncations, infos = self.env.step(actions_step)
for agent in self.env.agents:
# 添加观察值
sub_agent_obs.append(observations[agent])
# 添加奖励
sub_agent_reward.append([rewards[agent]]) # 注意:确保rewards[agent]是单个值或一维数组
# 添加终止标志
sub_agent_done.append(terminations[agent])
# 添加附加信息
sub_agent_info.append(infos[agent])
# return [observations, rewards, terminations, infos]
return [sub_agent_obs, sub_agent_reward, sub_agent_done, sub_agent_info]
由于环境中智能体为3,因此train.py中需要改为:
parser.add_argument("--num_agents", type=int, default=3, help="number of players")
第三步:更改下action
由于源代码run时用的actions_env,用手段处理了action
# actions --> actions_env : shape:[10, 1] --> [5, 2, 5]
actions_env = np.squeeze(np.eye(self.envs.action_space[0].n)[actions], 2)
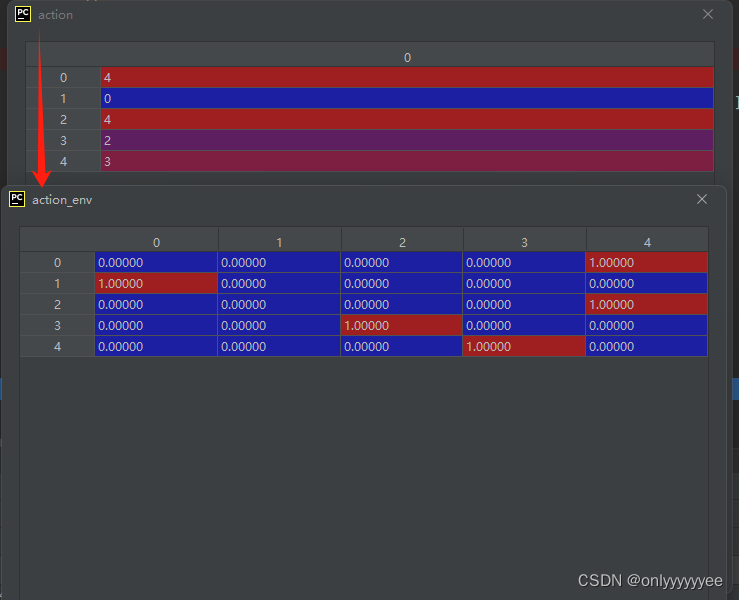
但是simple_spread_v3不需要处理就可以直接用,所以直接把run函数中step用的动作值给改为原始动作就行(env_runner.py的42行)
obs, rewards, dones, infos = self.envs.step(actions)
第四步:改下 self.warmup()位置
由于源代码中 self.warmup()在episode之前,为什么这样方我也不太理解,但是 self.warmup()里面会牵扯到环境的reset,所以把 self.warmup()放到episode循环里面环境才能正常运行
for episode in range(episodes):
self.warmup()
if self.use_linear_lr_decay:
for agent_id in range(self.num_agents):
self.trainer[agent_id].policy.lr_decay(episode, episodes)
for step in range(self.episode_length):
第五步:改下config.py中episode_length
由于环境中max_cycles=30,因此必须满足episode_length<30才不会报错
parser.add_argument("--episode_length", type=int, default=25, help="Max length for any episode")
第六步:增加结果打印相关
由于新版的env_runner中没有打印加过相关的,因此我把旧版本的奖励打印给复制过来了,同时也加了画图的代码,改动如下:
def run(self):
episode_rewards = []
start = time.time()
episodes = int(self.num_env_steps) // self.episode_length // self.n_rollout_threads
for episode in range(episodes):
self.warmup()
if self.use_linear_lr_decay:
self.trainer.policy.lr_decay(episode, episodes)
然后for step in range(self.episode_length):里面的这一步不改
在if episode % self.log_interval == 0后添加
train_infos["average_episode_rewards"] = np.mean(self.buffer.rewards) * self.episode_length
print("average episode rewards is {}".format(train_infos["average_episode_rewards"]))
self.log_train(train_infos, total_num_steps)
# self.log_env(env_infos, total_num_steps)
average_reward = train_infos["average_episode_rewards"]
episode_rewards.append(average_reward)
在for episode in range(episodes):结束后添加执行:
self.plot_episode_rewards(episode_rewards)
def plot_episode_rewards(self, episode_rewards):
plt.figure(figsize=(10, 5))
plt.plot(episode_rewards, label='Average Episode Rewards')
plt.xlabel('Episode')
plt.ylabel('Average Reward')
plt.title('Rewards Over Episodes')
plt.legend()
plt.grid(True)
plt.show()
训练结果
把上面的改完就可以正式运行了,训练结果如下:
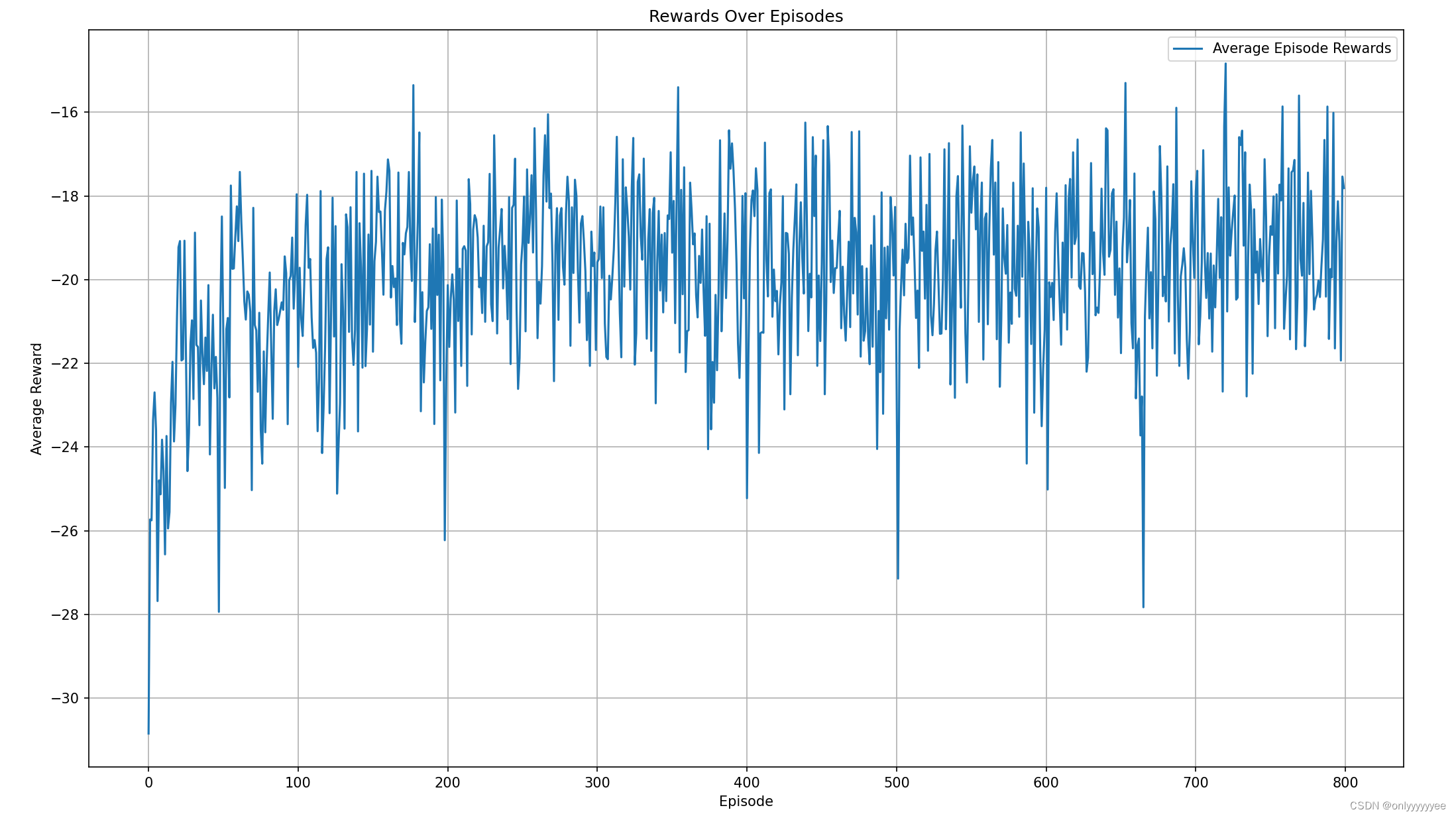
结果不太好,可能是我训练步数不够,这里只是做个实例给大家看
结语
以上改进都来自个人经验,正确性还有需要结合具体环境验证,如有错误,欢迎指正
同时大家有疑问可评论留言,如 同时大家有疑问可评论留言,如 想要已经改好的代码可联系本人(可提供指导),邮箱2360278536@qq.com
下期再出基于连续环境的
对MAPPO算法代码总体流程不太了解,可以参考多智能体强化学习MAPPO源代码解读
对MAPPO算法理论知识不太了解,可以参考多智能体强化学习之MAPPO理论解读和多智能体强化学习(二) MAPPO算法详解

















 8065
8065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









