







 本文提出了一种新型自蒸馏架构,通过直接训练学生模型,显著减少训练时间,提高精度。实验显示,与传统蒸馏和深度监督网络相比,自蒸馏在CIFAR100和ImageNet上效果显著,尤其在深度网络中表现更优。
本文提出了一种新型自蒸馏架构,通过直接训练学生模型,显著减少训练时间,提高精度。实验显示,与传统蒸馏和深度监督网络相比,自蒸馏在CIFAR100和ImageNet上效果显著,尤其在深度网络中表现更优。
paper:Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation
official implementation: https://github.com/luanyunteng/pytorch-be-your-own-teacher
前言
知识蒸馏作为一种流行的压缩方法,通过让参数较少的学生模型学习参数量更大的教师模型的知识,可以有效提高学生模型的性能,甚至比教师模型更好,在实际应用中用学生模型替代教师模型从而实现压缩和加速的效果。
但是存在两个问题,一是知识传递的效率较低,学生模型很难学习到教师模型的所有知识,通过蒸馏后性能优于教师模型的情况仍是极少数。二是如何设计和训练合适的教师模型仍是一个难题,现有的蒸馏方法需要大量的实验来找到教师模型的最优架构,非常耗时。
本文的创新点
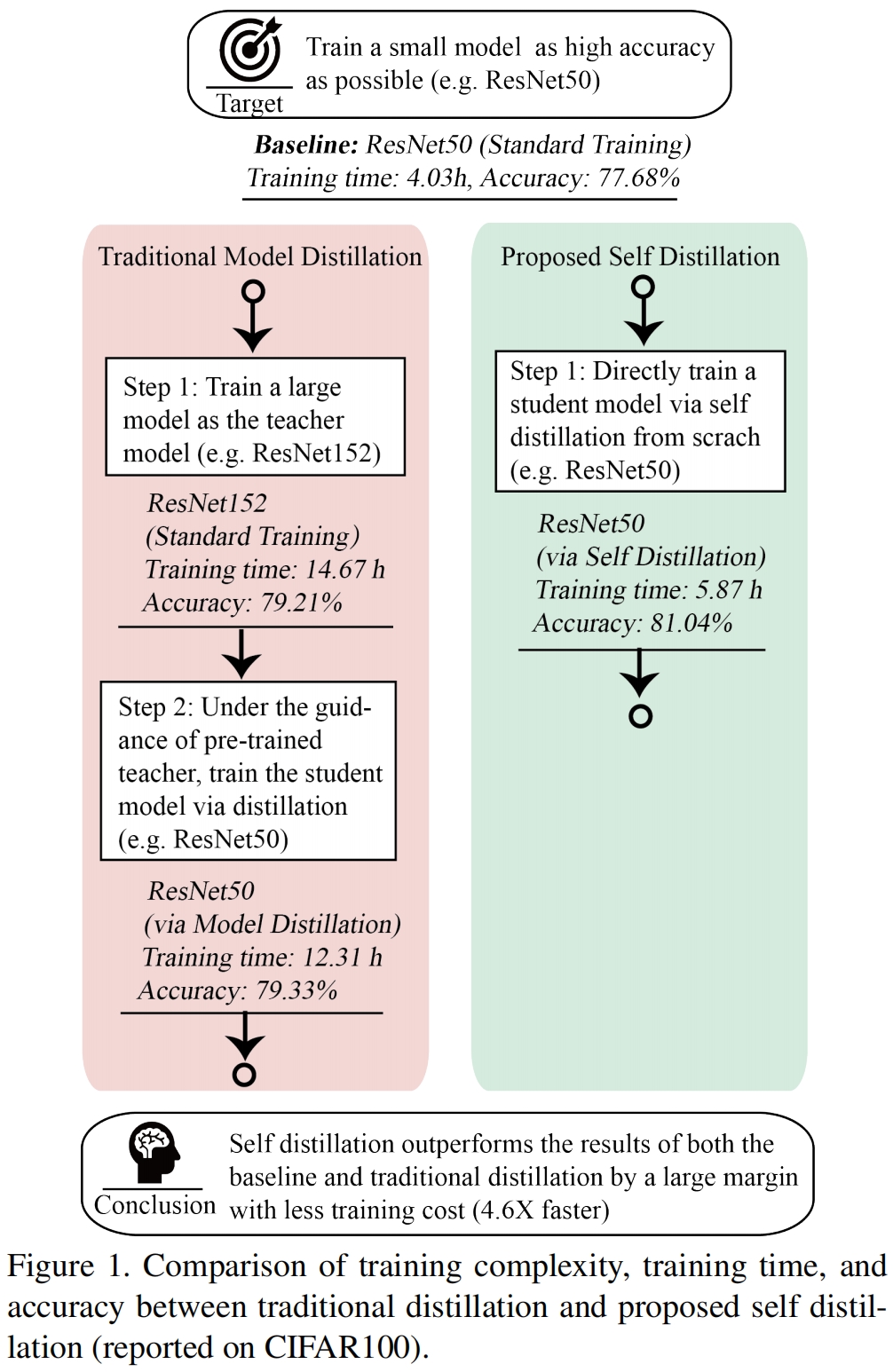
为了克服传统蒸馏的缺点,本文提出了一种新的自蒸馏架构。和传统蒸馏需要两个步骤即首先训练一个教师模型,然后将知识从教师模型蒸馏到学生模型的方法不同,本文提出的方法只需要一步,训练点直指学生模型,大大减少了训练时间(比如在CIFAR100上,从26.98个小时到5.87个小时,速度快了4.6倍),同时获得了更高的精度(比如ResNet50从传统蒸馏的79.33%的精度提升至81.04%)。
方法介绍
完整的架构如下图所示
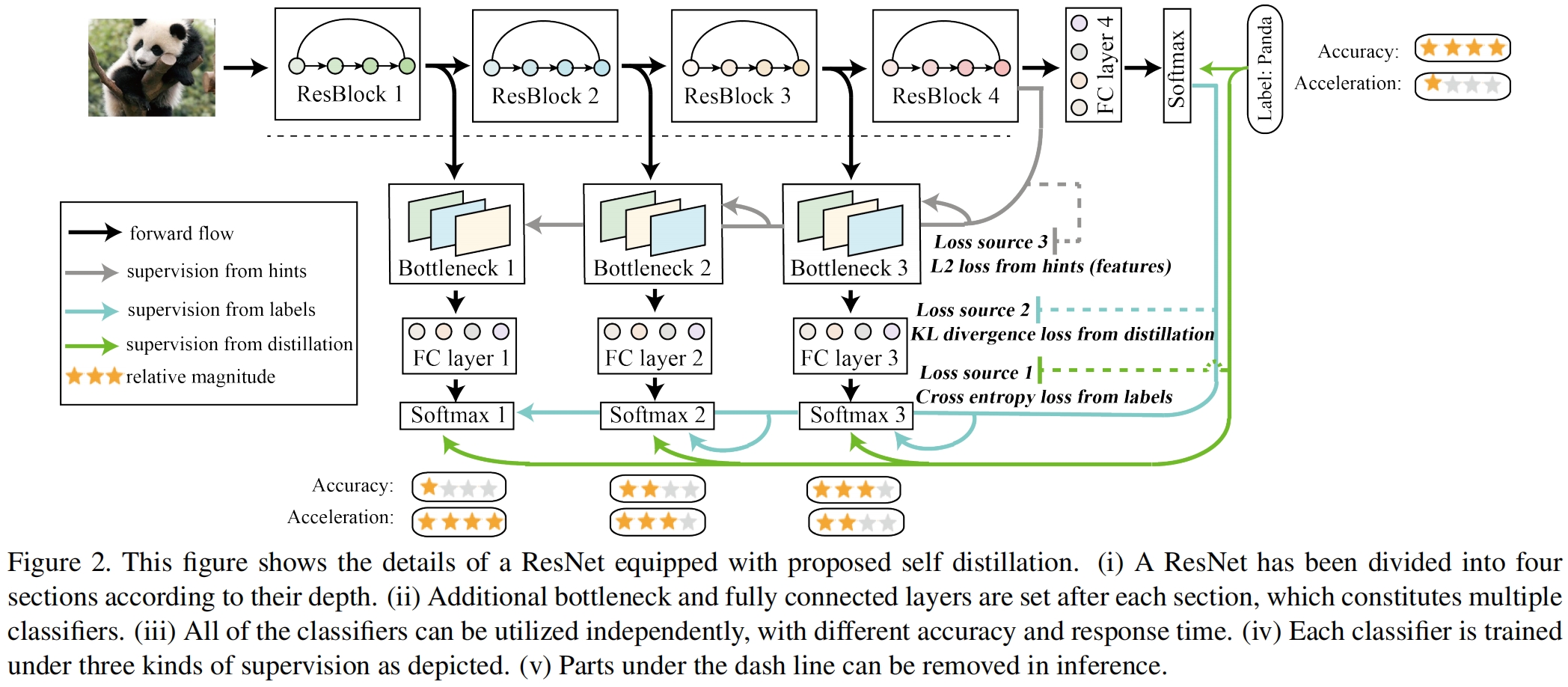
以 ResNet50为例,根据深度将其分为四个部分,在每部分后接一个分类器,这个分类器由一个bottleneck、一个全连接层、一个softmax层构成,该分类器只在训练时使用,推理时可以去掉。bottleneck的作用是为了减轻每个浅层分类器之间的影响,并与hints(即特征图)之间计算L2损失。在训练阶段,每个浅层的分类器可以当做学生模型,深层的当做教师模型,从而实现知识的蒸馏。
训练过程中一共有三种损失:
-
标签之间的交叉熵损失。不仅是最深层即原本模型最终的分类输出,每个浅层分类器的softmax输出也与标签计算CE损失,通过这种方式,隐含在数据集中的知识直接从标签引入到所有的分类器中。
-
KL散度损失。计算学生和教师softmax之间的散度损失。注意教师只有一个,即最深层的输出。
-
和hints之间的L2损失。通过计算最深层分类器和每个浅层分类器特征之间的L2损失,引入feature map中的implicit knowledge,使得每个浅层分类器的bottleneck中的特征图都去拟合最深层分类器bottleneck中的特征图。
完整的损失如下所示
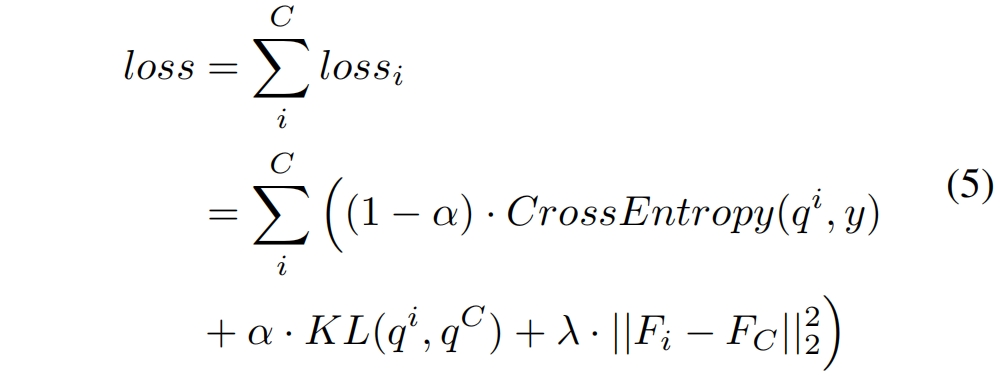
其中 \(\lambda\) 和 \(\alpha\) 是平衡各项损失的权重超参,对于最深层分类器 \(\lambda\) 和 \(\alpha\) 都为0。
实验结果
Compared with Standard Training
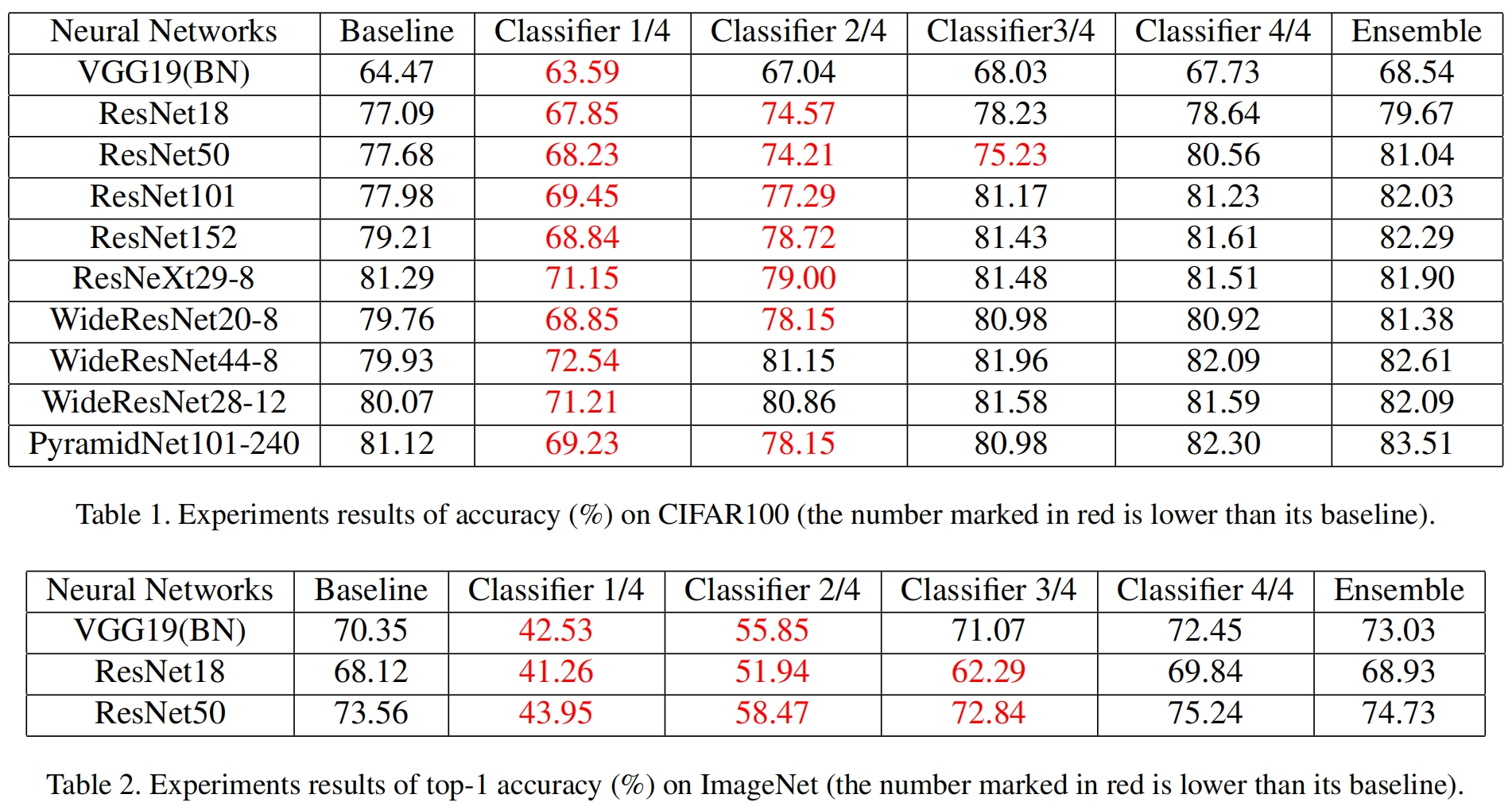
在CIFAR100和ImageNet上的结果分别如表1、2所示,其中集成结果通过对各个分类器输出加权求和得到。
从结果可以看出
- 通过自蒸馏,所有网络的精度都得到了提升。CIFAR100上评价提升了2.65%,ImageNet上平均提升了2.0.%。
- 网络越深,性能提升越大。比如ResNet101提升了4.05%,ResNet18提升了2.58%。
- 一般来说集成结果在CIFAR100上提升较大,在ImageNet上提升较小,这可能是由于浅层分类器的精度损失较大。
- 分类器的深度在ImageNet中起着更重要的作用,这表明对于复杂任务网络的冗余较小。
Compared with Distillation
与其他蒸馏方法的对比如表3所示,可以看出本文提出的自蒸馏获得了最高的精度。同时如图1所示,因为不用通过实验选择合适的教师模型以及训练教师模型,整个训练时长也大大减小。

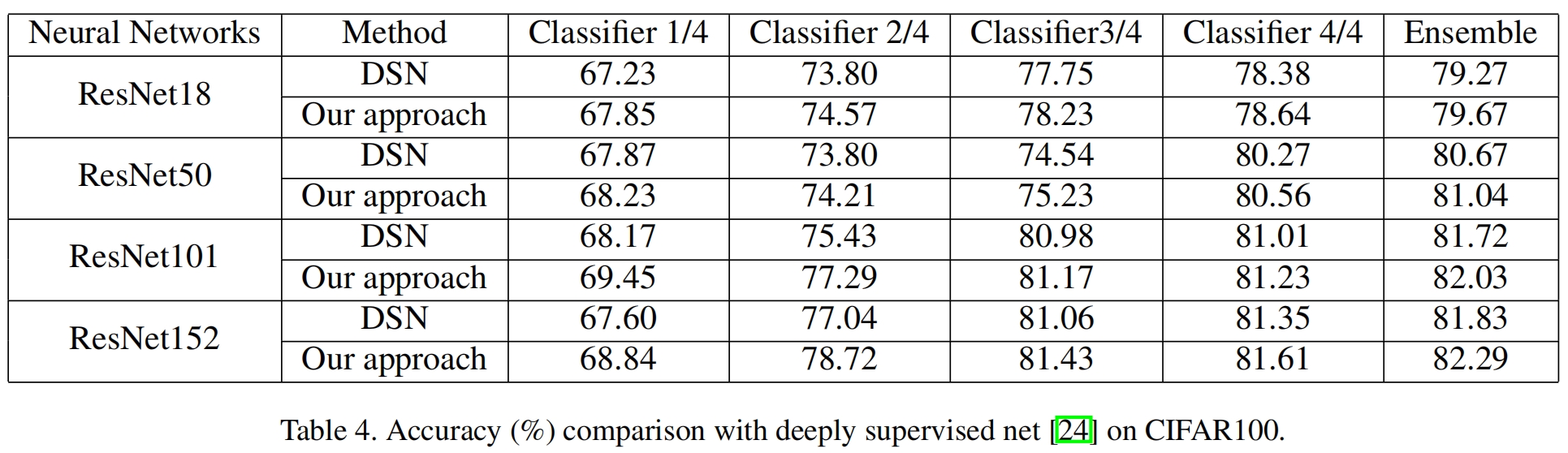
Compared with Deeply Supervised Net
深度监督网络和自蒸馏的最大区别是,自蒸馏不仅是用标签训练浅层分类器,还以深层分类器作为教师模型进行知识的蒸馏。结果对比如表4所示,可以看出,自蒸馏在每个分类器的结果都优于深度监督。


















 544
544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











