







paper:Bootstrap your own latent: A new approach to self-supervised Learning
third-party implementation:https://github.com/open-mmlab/mmpretrain/blob/main/mmpretrain/models/selfsup/byol.py
本文的创新点
本文提出了一种新的自监督学习方法,Bootstrap Your Own Latent(BYOL),和以往需要大量负样本的对比学习方法如SimCLR不同,BYOL不依赖于负样本对。此外,和之前需要精心设计增强策略的对比方法相比,BYOL对图像增强的敏感度较低。BYOL在ImageNet上的linear evaluation取得了新的SOTA,并且在迁移学习和半监督学习的基准测试中表现优异。
方法介绍
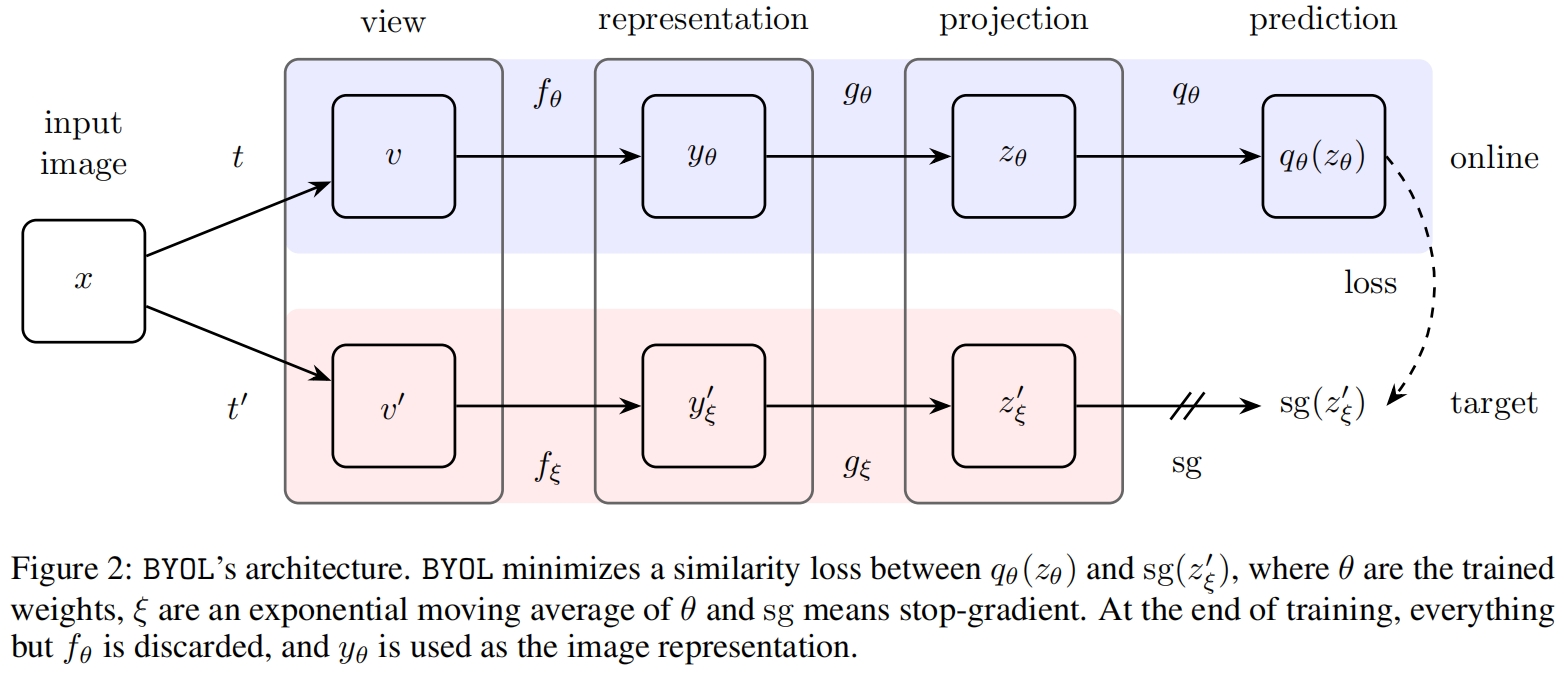
BYOL的目标是学习一个可以用于下游任务的表示 \(y_{\theta}\)。BYOL使用online和target两个神经网络来学习。在线网络由一组权重 \(\theta\) 定义并由三个阶段组成:encoder \(f_{\theta}\)、projector \(g_{\theta}\)、predictor \(q_{\theta}\)。如图2所示。目标网络和在线网络的架构相同,但使用不同的权重 \(\xi\)。目标网络提供了用于训练在线网络的regression target,其参数 \(\xi\) 是在线网络参数 \(\theta\) 的指数移动平均值。给定一个衰减率 \(\tau \in[0,1]\),在每个训练step后,我们执行如下更新
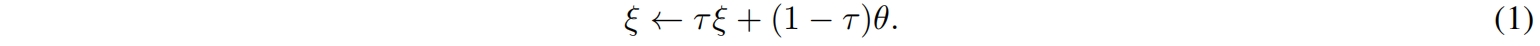
给定一组图片 \(\mathcal{D}\),从 \(\mathcal{D}\) 中均匀采样得到一张图片 \(x\sim\mathcal{D}\),以及两组增强分布 \(\mathcal{T}\) 和 \(\mathcal{T}'\),BYOL通过对 \(x\) 分别应用增强 \(t\sim\mathcal{T}\) 和 \(t'\sim\mathcal{T}'\) 得到两个增强视图 \(v \triangleq t(x)\) 和 \(v' \triangleq t'(x)\)。从第一个增强视图 \(v\) 来看,在线网络输出一个表示 \(y \triangleq f_{\theta}(v)\) 和一个映射 \(z_{\theta} \triangleq g_{\theta}(y)\)。目标网络从第二个增强视图 \(v'\) 输出 \(y_{\xi} \triangleq f_{\xi}(v')\) 和目标映射 \(z_{\xi}' \triangleq g_{\xi}(y')\)。然后输出一个 \(z'_{\xi}\) 的预测 \(q_{\theta}(z_{\theta})\) 并对 \(q_{\theta}(z_{\theta})\) 和 \(z'_{\xi}\) 进行 \(\ell_2\) 标准化得到 \(\overline{q_\theta}\left(z_\theta\right) \triangleq q_\theta\left(z_\theta\right) /\left\|q_\theta\left(z_\theta\right)\right\|_2\) 和 \(\bar{z}_{\xi}^{\prime} \triangleq z_{\xi}^{\prime} /\left\|z_{\xi}^{\prime}\right\|_2\)。注意这个预测网络只应用在在线分支,使得在线和目标分支是非对称的结构。最后我们定义标准化预测和目标映射之间的均方根误差
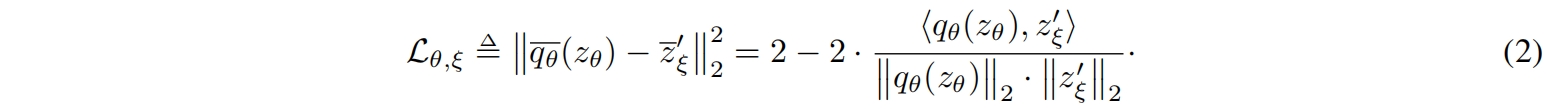
然后我们再将 \(v'\) 输入在线网络,将 \(v\) 输入目标网络得到式(2)中 \(\mathcal{L}_{\theta, \xi}\) 的对称损失 \(\widetilde{\mathcal{L}}_{\theta, \xi}\)。在每个训练step,通过梯度下降根据 \(\mathcal{L}^{BYOL}_{\theta, \xi}=\mathcal{L}_{\theta, \xi}+\widetilde{\mathcal{L}}_{\theta, \xi}\) 来优化 \(\theta\),但不更新 \(\xi\)。如图2中的stop-gradient所示,BYOL的整体优化如下
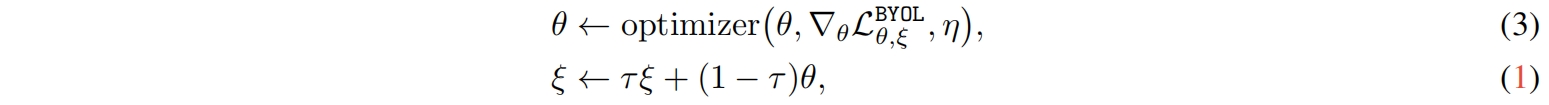
在训练完成后,我们只保留 \(f_{\theta}\)。
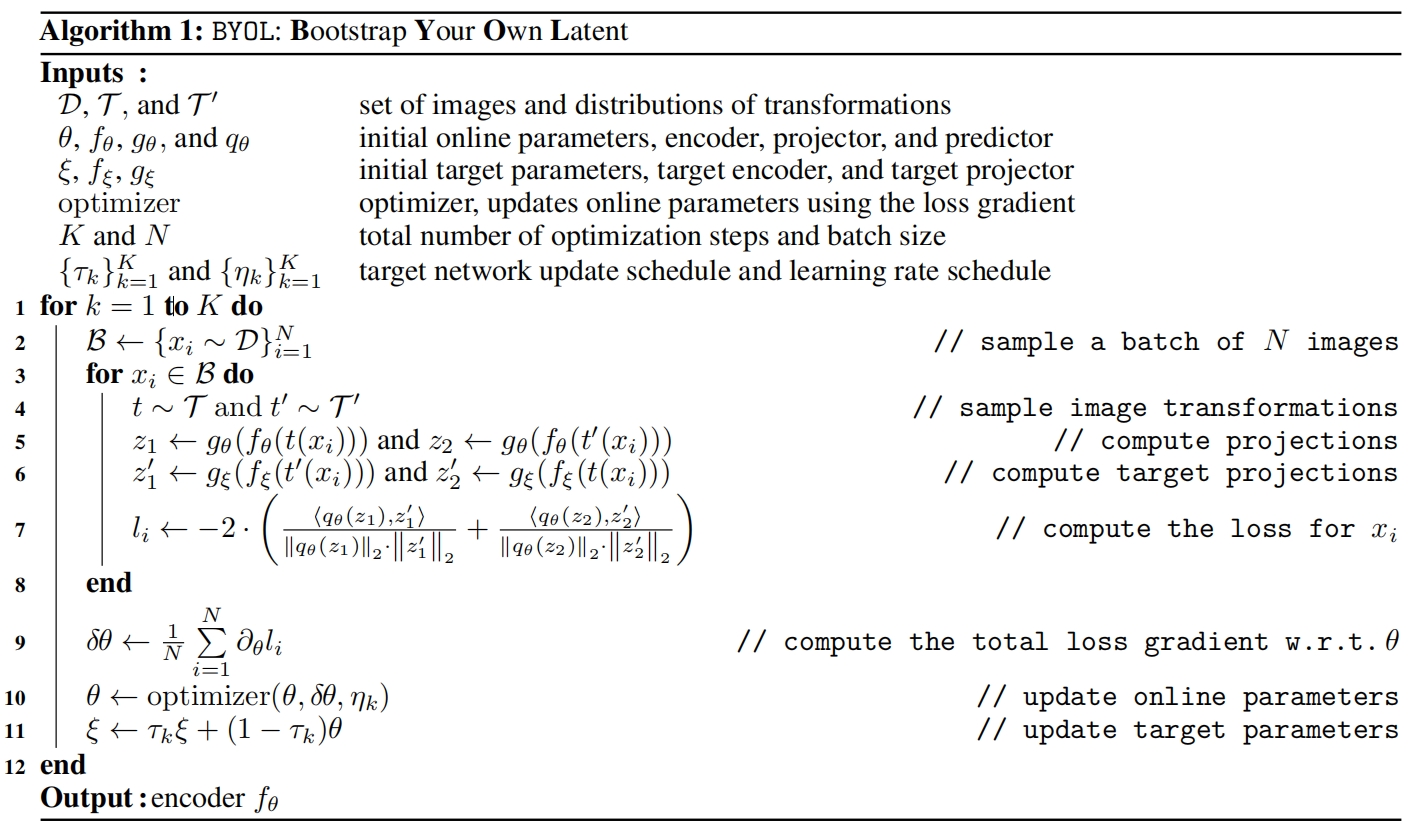
BYOL的伪代码如下
实验结果
在ImageNet上的linear evaluation如下,可以看到BYOL取得了SOTA的表现。

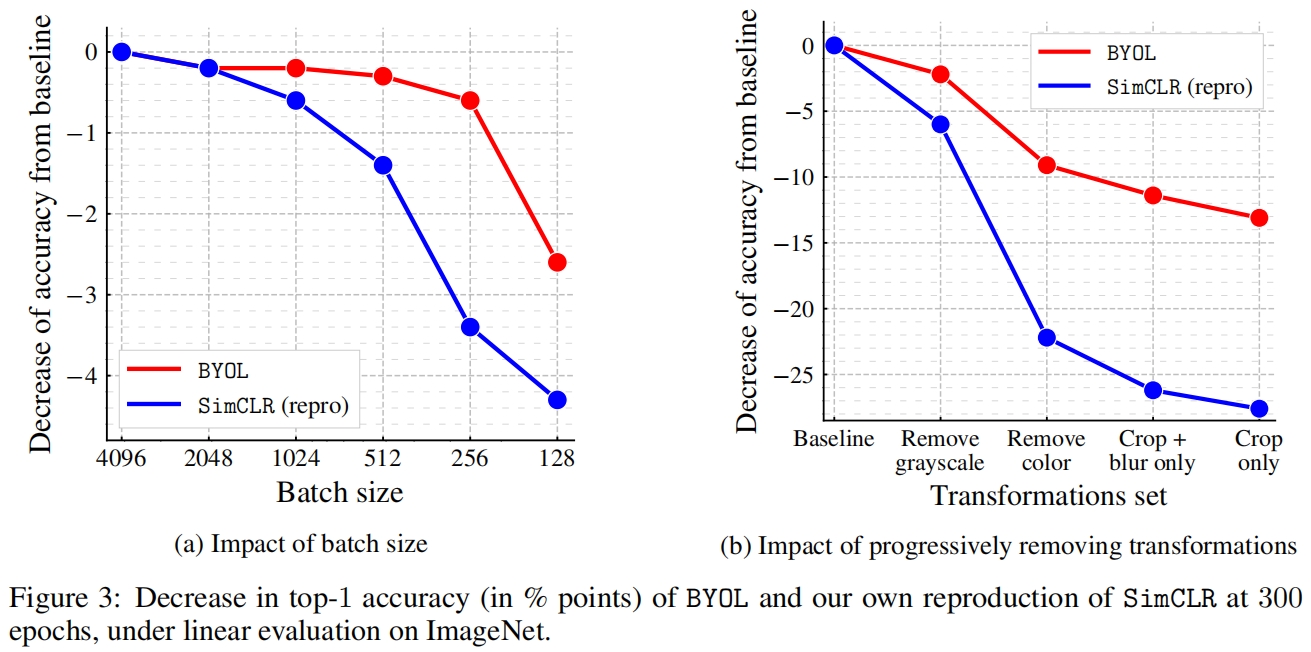
作者还比较了减小batch size以及减少增强方法时BYOL和SimCLR性能。可以看到,BYOL比SimCLR性能下降的更慢,尤其是在减少数据增强时,表明BYOL对batch size和数据增强的不敏感。
代码解析
class BYOL(BaseSelfSupervisor):
"""BYOL.
Implementation of `Bootstrap Your Own Latent: A New Approach to
Self-Supervised Learning <https://arxiv.org/abs/2006.07733>`_.
Args:
backbone (dict): Config dict for module of backbone.
neck (dict): Config dict for module of deep features
to compact feature vectors.
head (dict): Config dict for module of head functions.
base_momentum (float): The base momentum coefficient for the target
network. Defaults to 0.004.
pretrained (str, optional): The pretrained checkpoint path, support
local path and remote path. Defaults to None.
data_preprocessor (dict, optional): The config for preprocessing
input data. If None or no specified type, it will use
"SelfSupDataPreprocessor" as type.
See :class:`SelfSupDataPreprocessor` for more details.
Defaults to None.
init_cfg (Union[List[dict], dict], optional): Config dict for weight
initialization. Defaults to None.
"""
def __init__(self,
backbone: dict,
neck: dict,
head: dict,
base_momentum: float = 0.004,
pretrained: Optional[str] = None,
data_preprocessor: Optional[dict] = None,
init_cfg: Optional[Union[List[dict], dict]] = None) -> None:
super().__init__(
backbone=backbone,
neck=neck,
head=head,
pretrained=pretrained,
data_preprocessor=data_preprocessor,
init_cfg=init_cfg)
# create momentum model
self.target_net = CosineEMA(
nn.Sequential(self.backbone, self.neck), momentum=base_momentum)
def loss(self, inputs: List[torch.Tensor], data_samples: List[DataSample],
**kwargs) -> Dict[str, torch.Tensor]:
"""The forward function in training.
Args:
inputs (List[torch.Tensor]): The input images.
data_samples (List[DataSample]): All elements required
during the forward function.
Returns:
Dict[str, torch.Tensor]: A dictionary of loss components.
"""
assert isinstance(inputs, list)
img_v1 = inputs[0]
img_v2 = inputs[1]
# compute online features
proj_online_v1 = self.neck(self.backbone(img_v1))[0]
proj_online_v2 = self.neck(self.backbone(img_v2))[0]
# compute target features
with torch.no_grad():
# update the target net
self.target_net.update_parameters(
nn.Sequential(self.backbone, self.neck))
proj_target_v1 = self.target_net(img_v1)[0]
proj_target_v2 = self.target_net(img_v2)[0]
loss_1 = self.head.loss(proj_online_v1, proj_target_v2)
loss_2 = self.head.loss(proj_online_v2, proj_target_v1)
losses = dict(loss=2. * (loss_1 + loss_2))
return losses


















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











