







 该文提出了一种使用两个级联的CNN(LNet和ANet)进行面部定位和属性预测的方法。LNet通过大规模物体分类预训练,然后用属性标签微调,用于面部定位;ANet则通过人脸识别预训练,再用属性预测任务微调,用于属性预测。研究发现,预训练和微调策略能显著提升模型性能,且ANet的高层神经元能自动发现语义概念。整个框架包括LNet粗略定位头部和肩部,再精细定位脸部,ANet表达并预测面部属性,最后通过SVM进行分类。
该文提出了一种使用两个级联的CNN(LNet和ANet)进行面部定位和属性预测的方法。LNet通过大规模物体分类预训练,然后用属性标签微调,用于面部定位;ANet则通过人脸识别预训练,再用属性预测任务微调,用于属性预测。研究发现,预训练和微调策略能显著提升模型性能,且ANet的高层神经元能自动发现语义概念。整个框架包括LNet粗略定位头部和肩部,再精细定位脸部,ANet表达并预测面部属性,最后通过SVM进行分类。

文章要解决的问题
Predicting face attributes from web images
方法的主要想法
It cascades two CNNs (LNet and ANet) forface localization and attribute prediction respectively.
贡献(吹牛逼)
(1) It shows how LNet and ANet can be improved by different pre-trainingstrategies.
(2) It reveals that although filters of LNet are fine-tuned by attributelabels, their response maps over the entire image have strong indication offace’s location.
(3)It also demonstrates that the high-level hidden neurons of ANetautomatically discover semantic concepts after pretraining, and such concepts aresignificantly enriched after fine-tuning.
pre-train andfine-tuned
LNet and ANet are first pretrained differently and then jointly trainedwith attribute labels.
LNet is pre-trained by classifying massive general object categories.Thus, its pre-trained features have good generalization capability on handlingvarious background clutters. LNet is then fine-tuned by predicting attributes.
ANet is pre-trained by classifying massive face identities, to obtaindiscriminative face representation. Then it is fine-tuned by the attributeprediction task.
Pre-train的原因和人脸定位的理论:
A filter (or a group of filters) functions as a detector of an attribute. Whena subset of neurons are activated, they indicate the existence of face images,which have a particular attribute configuration. The neurons at differentlayers can form many activation patterns, implying that the whole set of face imagescan be divided into many subsets based on attribute configurations, and eachactivation pattern corresponds to one subset (e.g. ‘pointy nose’, ‘rosy cheek’, and‘smiling’). Therefore, it is not surprising that filters learned by attribute predictionlead to effective representations for face localization. By simply averagingand thresholding response maps, good face localization is achieved.
With this strategy, each face attribute is well explained by a sparselinear combination of these sematic concepts. By analyzing the coefficients ofsuch combinations, attributes show clear grouping patterns, which could be wellinterpreted semantically.
Structure Of Framework
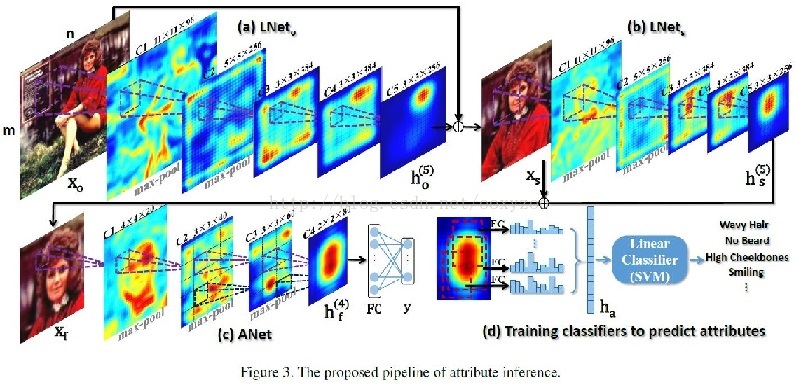

再加上最后的SVM分类器,一共四个过程
1 LNeto定位头部和肩部

2 LNets定位脸(更准确的定位)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3001
3001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









