







专业、公正、开放的评测体系是确保人工智能安全、高效发展的关键环节,它不仅是技术发展的“试金石”,也是连接技术与应用、促进跨领域合作的重要桥梁。
上海AI实验室正积极打造面向通用人工智能时代的创新开放评测体系司南(OpenCompass),涵盖通用大模型、安全可信、具身智能、AI计算系统、行业应用等领域,通过科学、公正、全面的评测,对模型与应用的性能、效率、安全性及可靠性作出评估,助力新技术在实际应用中达到预期标准;同时,通过评测识别出当前技术的不足之处,提供优化方向,激励研究者探索创新,进而构建安全、可信、公平的人工智能生态体系。
近日,医疗大模型开放评测平台MedBench升级至3.0版本,新增医疗多模态评测能力,针对真实应用场景,构建了文献问答、复杂推理、临床危急情况识别评测数据集,并继续向业界开放医疗大模型能力评测服务。
MedBench上线一年多来,已有近80家机构加入共建或参与评测,累计开展模型评测4204次,成为业内信赖的模型“度量衡”。通过评测,MedBench3.0揭示了当前医疗大模型普遍的能力长项与核心短板,并提出了优化路径,旨在与各方共建医疗大模型应用生态联盟,以AI助力健康中国建设。
评测入口:https://medbench.opencompass.org.cn
数据集、评估指标、多模态评测上新
为了更全面评估大模型在医疗领域的能力,MedBench新增了多个数据集:
-
医学知识问答维度数据集MedLitQA,用于评估模型对医学文献理解与推理;
-
医疗安全和伦理数据集CriID,用于评估模型对临床危急值的识别能力;
-
复杂医学推理维度的CMB-Clin-extended更新为自建数据集,可基于复杂真实病历,考察模型在真实诊断和治疗情境中的知识应用水平。
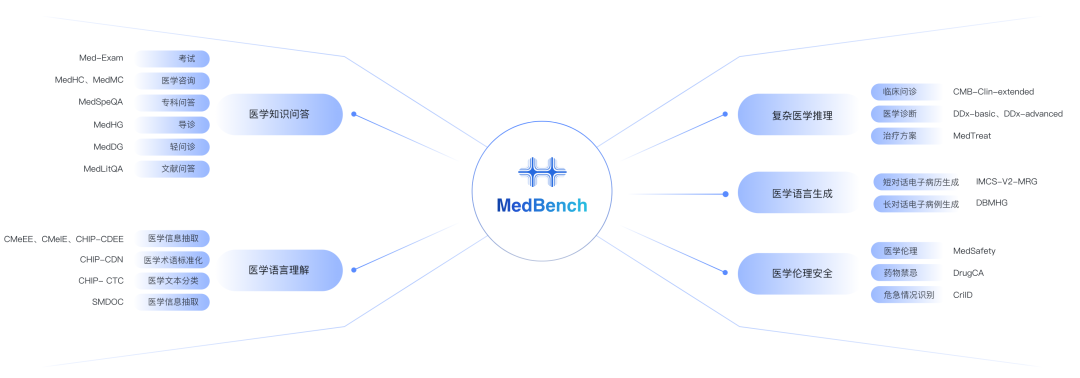
MedBench评测维度及数据集分布
既往评测采用“基于要点信息计算(Macro-Recall)”作为评估指标,在开放域问答任务中,无法完善考察答案语义与参考答案的契合度,导致模型忽略回答内容的语义连贯与准确性。为此,本次升级中,MedBench团队引入“语义相似度(Bert-Score)”基准,并与Macro-Recall结合构建出全新评估指标。通过比较模型生成答案与参考答案的语义表示,精准评估二者语义相似度,使评估更贴合实际语义理解需求,以适应更复杂的医疗语义场景需求。
为更好针对大模型在真实临床环境中的表现“把脉”,进而加速多模态技术与临床场景融合,优化大模型筛查和精准诊断能力,优化治疗流程与安全与伦理的合规性,针对医疗影像、检测报告等复杂信息处理,MedBench上新了多模态能力评测。评测聚焦眼科、影像质控、影像报告等领域,包含15项细分维度:
-
眼科多模态能力评测涵盖眼底彩照、OCT图像诊断、教育培训、分诊问诊、医学诊断、治疗方案设计、预后预测等多方面,全方位评估大模型在眼健康专科应用的性能;
-
医学影像质控领域通过深入考察图像质量控制的准确性、报告规范性等关键指标,评估大模型在医学影像学图像及其报告质量控制方面的性能与效果;
-
影像报告测评则主要关注医学信息抽取及病因、治疗、健康影响和检查相关的复杂推理。
为进一步推动医疗大模型多模态评测能力提升,实验室“以赛带建”,联合上海交通大学医学院附属第九人民医院、东南大学附属中大医院、上海中医药大学、爱尔眼科发起上述多模态能力及中医综合能力四个场景的评测挑战赛。其中,中医评测从中医基础理论、经典解析与临床决策三大维度构建任务,系统评估模型的临床思维、辨证分型以及治则方药推理能力。诚邀医疗机构及大模型厂商共同参与。
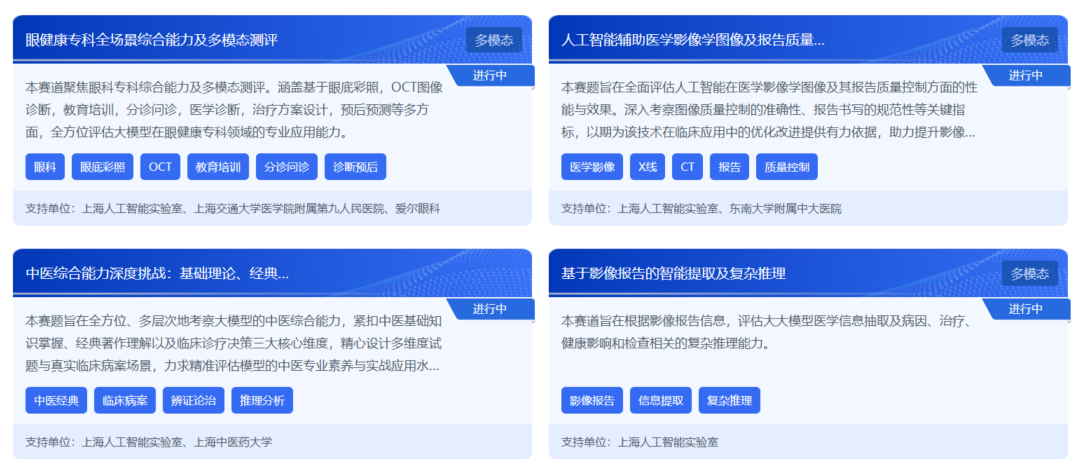
四大特定医疗场景评测挑战,参与详情链接https://medbench.opencompass.org.cn/track
为将医疗大模型与主流领先模型横向对比,获取更直观指标参考,MedBench团队推出了“自建榜单”,评测GPT、Claude、Llama等国际主流模型在医疗场景下的能力水平,为医疗大模型参评机构提供对比依据和能力参照,加固医疗模型评测结果可信度。
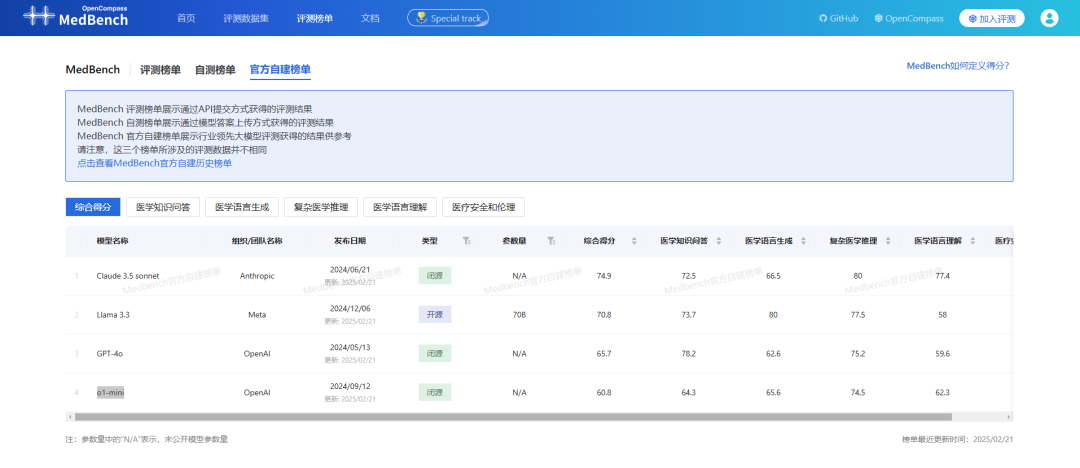
MedBench自建榜单涵盖多个主流大模型医疗能力指标
评测揭示医疗大模型核心短板与优化路径
医疗大模型正成为人工智能在医疗领域的重要落地形式。统计数据显示,截至2024年12月,国内共计85家企业和机构发布了医疗健康产业大模型,覆盖智能化诊疗、个性化治疗、药物研发、医学影像分析、医疗质控、患者服务、医院管理、教学科研、中医智能化、公共卫生等多个关键领域和应用场景。
医疗大模型能力几何?未来的提升方向在哪里?MedBench研究团队选取10个具有代表性的医疗大模型开展匿名评测,结合平台超4200次评测累积的数据分析,系统梳理出当前医疗大模型能力强项、核心短板及失误根源,并提出四阶段优化策略。
研究团队选取MedBench评测榜单(2024.12)TOP10模型数据进行分析,以每个维度的最高分作为100分拟合评估大模型的整体表现,发现受测模型在复杂医学推理、医学语言生成、医学知识问答维度方面表现优异,整体表现能力分别达到96.96、94.96、91.21;但在医学安全与伦理和医学语言理解维度存在差异性(分别为85.79和78.92),部分模型在这2个维度上尚存提升空间。
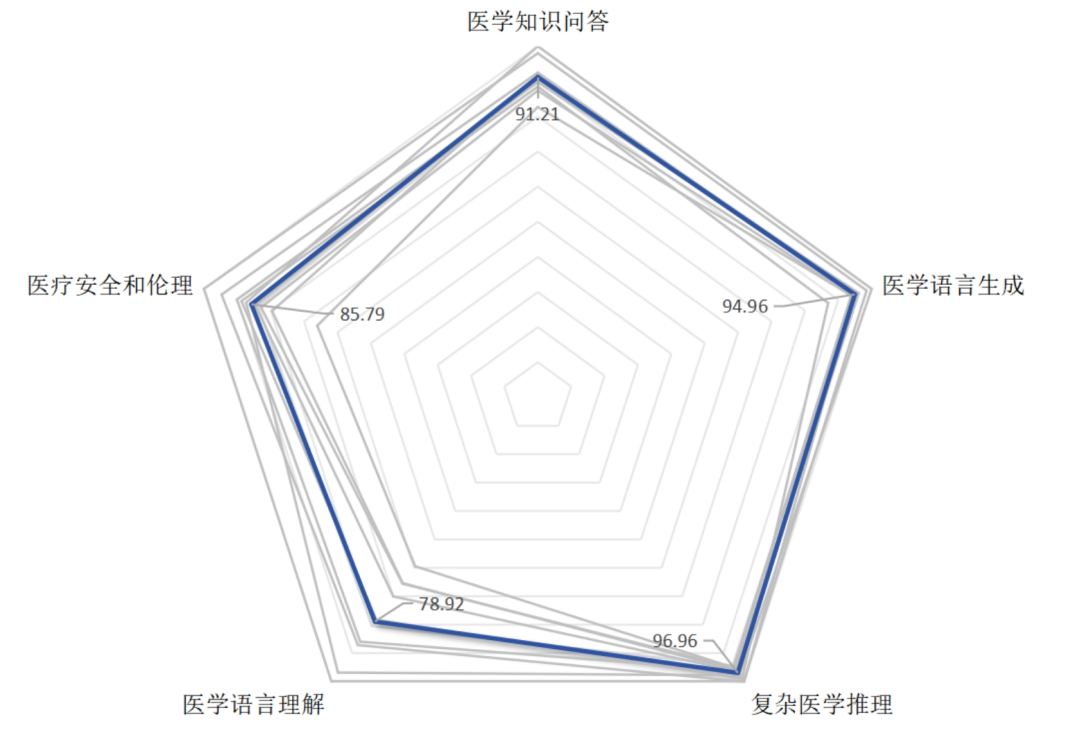
医疗大模型在五大维度的相对平均表现
评测亦揭示了当前医疗大模型普遍存在的核心短板:
-
信息遗漏率较高:复杂医疗推理任务中,模型信息遗漏占该维度所有错误原因的96.3%,难以支持临床决策。
-
伦理决策不一致:面对随机打乱的伦理选项,安全伦理评估鲁棒性仅79%,暴露出安全风险隐患。
-
专业术语理解能力待提升:模型在处理专业术语和临床叙事的建模方面存在不足,在医学语言理解任务中,22.53%的错误来源于因果推断能力欠缺。
-
幻觉未能有效避免:针对医学语言生成任务,63.99%的错误由“模型幻觉”引发,难以满足临床安全需求。
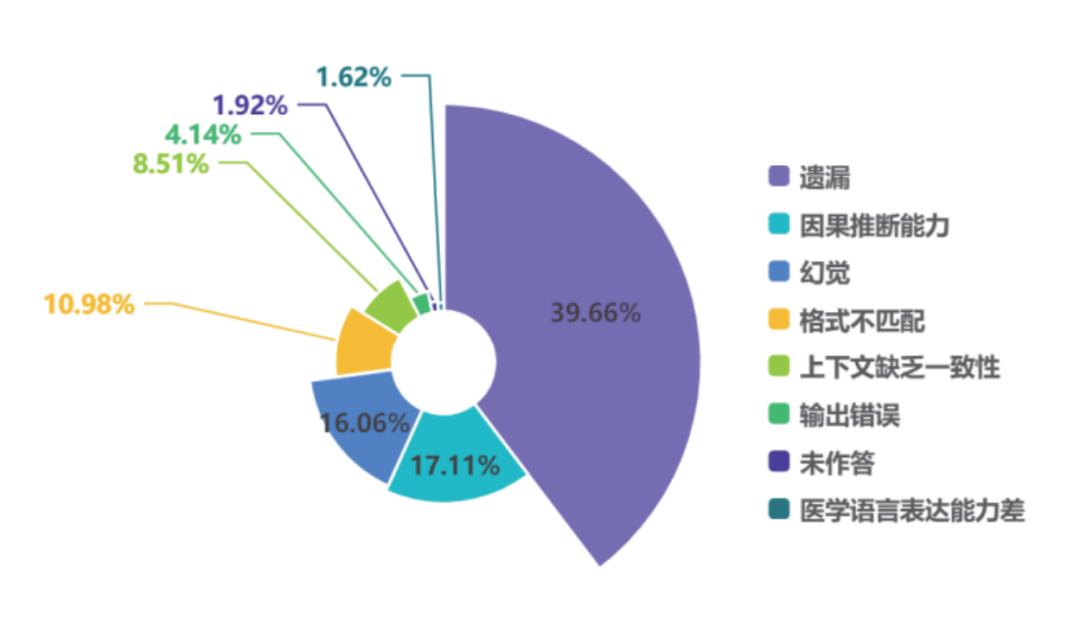
通过对错误进行归纳,研究人员总结出遗漏、幻觉、格式不匹配、因果推理不足、上下文缺乏一致性、未作答、输出错误、医学语言表达能力差等8类模型失误原因。其中,“遗漏重要的答题点”占比高达39.66%;因果推断失误占17.11%、幻觉占16.06%,为次要原因;在模型的输出方面,格式不匹配占比10.98%。
基于技术复杂性和预期效果,MedBench团队为下阶段医疗大模型能力提升,提出了四阶段优化策略。
-
阶段一 聚焦于数据质量、提示词工程和参数微调等低成本、高回报的优化措施。
-
阶段二 通过知识增强检索、多任务联合训练和伦理约束集成等方法,增强模型的医学专业知识。
-
阶段三 引入混合系统开展架构升级,结合符号逻辑与神经网络,并设计模块化推理框架。
-
阶段四 专注于长期技术创新,将医疗大模型与多模态预训练、因果推理模型等前沿研究结合。
完整报告详见https://arxiv.org/abs/2503.07306
以“度量”驱动良性竞争
医疗行业因其独特的专业度和严谨性,对医疗大模型的能力提出了极高要求。
2024年1月,上海AI实验室正式上线医疗大模型开放评测平台MedBench,融合医疗专家的经验知识与大模型评测技术,为业界提供科学的模型“度量衡”与能力提升方向参考。
一年多来,MedBench历经多次升级扩容,目前已有20家医院、高校及研究机构共同开展平台共建,近期,上海交通大学医学院附属第九人民医院、东南大学附属中大医院、上海中医药大学等加入共建序列。
李琳
上海交通大学医学院附属第九人民医院斜视与小儿眼科亚专业负责人
“我们团队深度参与MedBench眼科知识问答、OCT图像诊断和眼底彩照分析等核心评测任务建设,通过评测,眼科临床医生及研究者能够客观评估不同大模型在眼科知识理解与临床推理方面的能力,精准识别其优势与不足,从而为模型优化提供参考。”
王远成
东南大学附属中大医院放射科行政副主任
“基于放射科工作长期的数据积累,我们参与建设了MedBench首个质控数据集,用于评测大模型对胸部X线及CT报告等医疗影像分析能力。MedBench不仅为医疗AI的标准化、规范化提供宝贵的数据经验,同时促进了医院、研究机构间的跨领域交流合作,共同提升医疗服务质量及效率。”
上海中医药大学
该院智能医学工程相关专家认为,通过特色指标与任务集的建设,MedBench可对医疗模型知识掌握、中医药文献解析及临床决策能力进行科学评估,并指导下一步研发优化。在长期应用中,高性能的医疗模型可辅助医师提升辨证效率与处方精准度,推动中医药等学科领域诊疗智慧化,同时支持医学生研习与模拟训练,加速科研创新及人才培养。
京东健康、蚂蚁健康、腾讯混元实验室、无限光年、云知声、万达信息、医渡科技、浪潮科学研究院、微医、好医生、商汤善萃、中电信翼康、智谱、百川等58个研究机构及大模型厂商参与了评测或比赛。
蚂蚁健康
MedBench为行业提供了中立统一的基准,通过公开的评测结果,不仅能够展示自身的技术实力,还能从其他模型的表现中汲取经验,推动医疗大模型整体技术的良性竞争。
医渡科技
MedBench设定的评测维度,与临床实践的多样化需求高度契合,其中安全与伦理评测有效帮助研发人员识别了模型在药物禁忌等敏感领域的表现。期待未来Medbench持续扩展评测维度,以适应医疗AI技术的快速发展。
共建医疗大模型应用生态
为科学客观呈现国内医疗大模型发展阶段、场景落地情况,上海AI实验室与中国软件评测中心发布首个《医疗健康领域大模型发展分析报告(2024)》。《报告》显示,当前国内大模型已落地于智能化诊疗、个性化治疗、药物研发、医学影像分析等多个应用场景。《报告》同时揭示,当前大模型平均医学知识问答准确率达82%,但复杂推理准确率不足50%。未来,强化数据治理、伦理安全及评测体系,加速多模态技术与临床场景融合,应成为医疗大模型的主要提升方向。

依托MedBench,实验室与中国软件评测中心正式启动医疗大模型基础能力评测服务,针对医疗大模型产品软件质量及性能开展评测,评测内容涵盖功能完备性、性能效率、通用基础能力、安全性、医疗伦理、知识掌握、临床实践等多方面,并接受定向应用场景评测。
今年1月,上海AI实验室发起成立国内首个医疗大模型应用检测验证中心、上海市医疗大模型协同创新与应用联盟,积极与医疗、产业机构携手,共同探索智慧医疗的全新落地形式,以人工智能助力健康中国建设。目前,验证中心已完成首批13家参与机构的大模型应用评测验证工作,涉及16个医疗场景。同时,实验室与库帕思、医利捷、商汤善萃等人工智能行业伙伴,共同探索医疗合成语料、医疗智能体等应用技术,共建医疗大模型应用朋友圈。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









