







 这篇博客探讨了C++中处理汉字字符的问题,包括引入的问题、解决所需的知识、汉字编码方式(如GB2312、Unicode)以及vc/c++中的MutiByte Charater Set和Wide Character Set。博客指出,vc/c++使用GB2312编码,而Unicode是一种统一的编码方式,Java和C#等语言支持Unicode。同时,文章介绍了内码的转换方法,并分析了错误的编码处理可能导致的问题。
这篇博客探讨了C++中处理汉字字符的问题,包括引入的问题、解决所需的知识、汉字编码方式(如GB2312、Unicode)以及vc/c++中的MutiByte Charater Set和Wide Character Set。博客指出,vc/c++使用GB2312编码,而Unicode是一种统一的编码方式,Java和C#等语言支持Unicode。同时,文章介绍了内码的转换方法,并分析了错误的编码处理可能导致的问题。
问题:实现Apriori算法时的数据集为中文,所以需要用到汉字字符处理。现搜集整合如下。
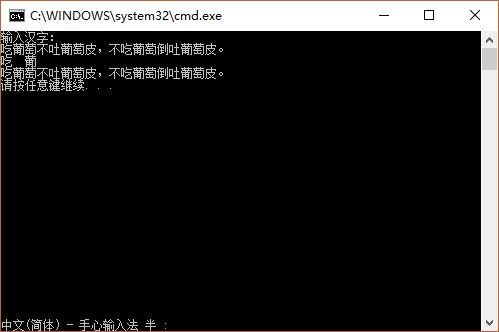
#include <stdio.h>
void main(void){
char str[100];
printf("输入汉字:\n");
scanf("%s",str);
printf("%c%c %c%c\n", str[0],str[1],str[2],str[3]);
printf("%s\n",str);
}测试结果:
转载1 关于C++中文字符的处理
一 引入问题
代码 wchar_t a3=L”中国”,编译时出错,出错信息为:数组越界。但wchar_t 是一个宽字节类型,数组a的大小应为6个字节,而两个汉字的的unicode码占4个字节,再加上一个结束符,最多6个字节,所以应该不会越界。难道是编译器出问题了?
二 解决引入问题所需的知识
主要需两方面的知识
1. 字符尤其是汉字的编码,以及语言和工具的支持情况
2. vc/c++中MutiByte Charater Set 和 Wide Character Set有关内存分配的情况.
三 汉字的编码方式及在vc/c++中的处理
1.汉字编码方式的介绍
对英文字符的处理,7位ASCII码字符集中的字符即可满足使用需求,且英文字符在计算机上的输入及输出也非常简单,因此,英文字符的输入、存储、内部处理和输出都可以只用同一个编码(如ASCII码)。
而汉字是一种象形文字,字数极多(现代汉字中仅常用字就有六、七千个,总字数高达5万个以上),且字形复杂,每一个汉字都有”音、形、义”三要素,同音字、异体字也很多,这些都给汉字的的计算机处理带来了很大的困难。要在计算机中处理汉字,必须解决以下几个问题:首先是汉字的输入,即如何把结构复杂的方块汉字输入到计算机中去,这是汉字处理的关键;其次,汉字在计算机内如何表示和存储?如何与西文兼容?最后,如何将汉字的处理结果从计算机内输出?
为此,必须将汉字代码化,即对汉字进行编码。对应于上述汉字处理过程中的输入、内部处理及输出这三个主要环节,流程如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









