







文章目录
前言
Mybatis 可以单独使用,也可以搭配 Spirng 使用,本文是基于单独使用 Mybatis 的版本进行 加载 和 执行 SQL 流程的梳理。基于 Spring 的流程会在其他文章中记录。
Mybatis 加载原理
使用 Mybatis,首先得让 Mybatis 加载我们的 全局配置文件 和 mapper 文件(或 Mapper 接口)。
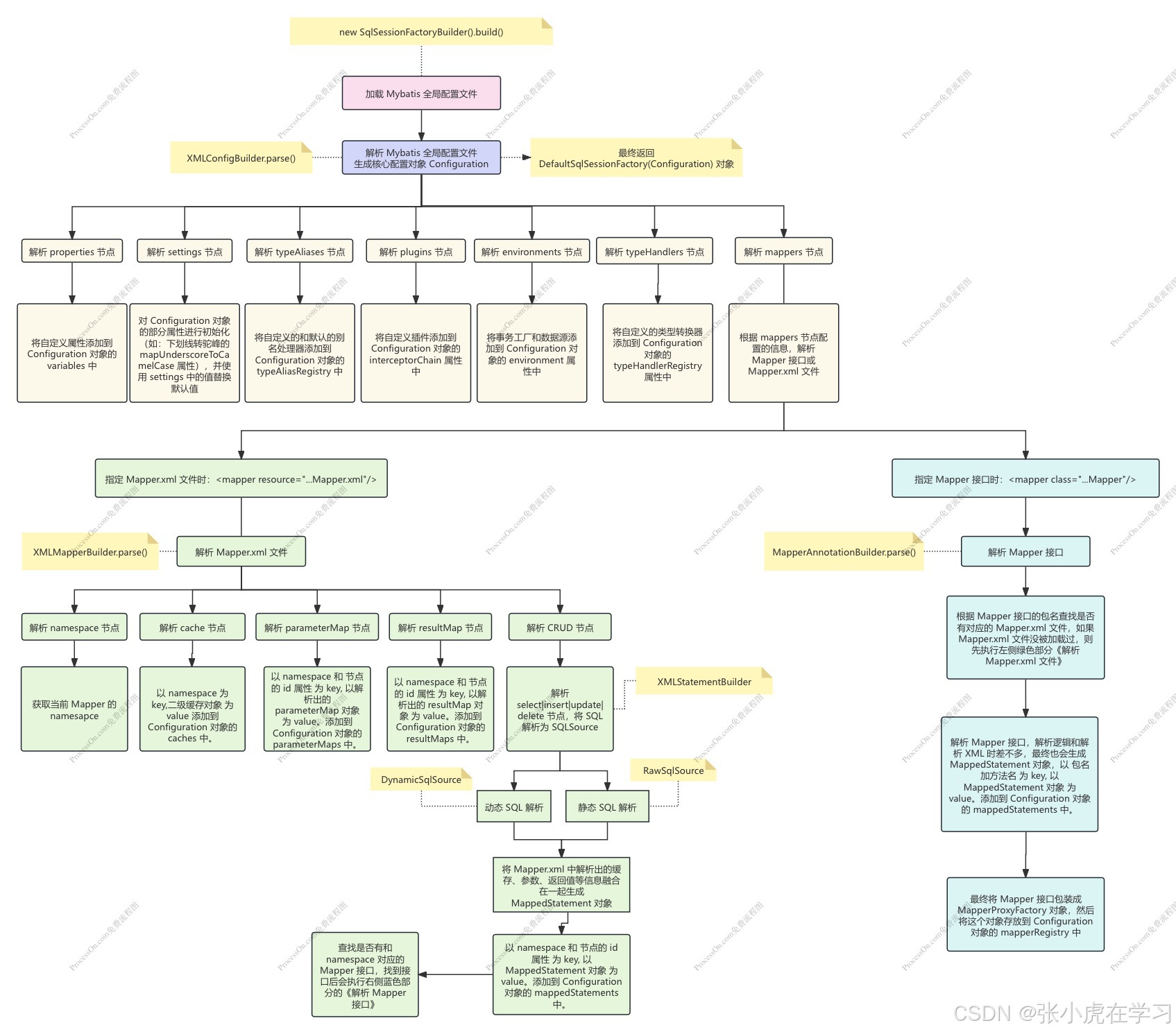
- 通过
new SqlSessionFactoryBuilder().build()方法来加载 Mybatis 全局配置文件,作为整个加载流程的入口。 - 在
build()方法中,会利用XMLConfigBuilder.parse()进行全局配置文件的解析。解析的过程就是不停的向Configuration对象中添加内容。解析完成后,最终会返回一个包含Configuration对象的DefaultSqlSessionFactory对象 - 在
XMLConfigBuilder.parse()中,首先会解析全局配置文件中的 properties 节点,这个节点的内容是我们自定义的属性,解析后会将自定义属性添加到 Configuration 对象的 variables 中 - 其次会解析 settings 节点,settings 节点中的内容不能随意写,只能写 Configuration 对象中定义的部分属性(如:下划线转驼峰的 mapUnderscoreToCamelCase 属性等)。settings 节点解析后会对 Configuration 对象的部分属性的初始值进行替换。
- 然后会解析 typeAliases 节点,这个节点用来定义别名和类型的对应关系。解析后会将自定义的和默认的别名处理器添加到 Configuration 对象的 typeAliasRegistry 中。
- 然后会解析 plugins 节点,这个节点用来定义自定义插件(插件只能拦截四种类型:Executor、StatementHandler、ParameterHandler、ResultSetHandler )。解析后会将自定义插件添加到 Configuration 对象的 interceptorChain 属性中
- 然后会解析 environments 节点,这个节点记录着事务和数据源信息。解析后会将事务工厂对象和数据源对象添加到 Configuration 对象的 environment 属性中
- 然后解析 typeHandlers 节点,这个节点的内容用来自定义类型处理器,其作用是定义如何处理 PreparedStatement 的传参以及 如何处理 ResultSet 的返回值。解析后会将自定义的和默认的类型转换器添加到 Configuration 对象的 typeHandlerRegistry 属性中。
- 最后就是解析 mappers 节点,这个节点非常重要,其和真正执行的 SQL 息息相关。一般可以通过
resource指定mapper.xml的路径, 也可以通过package或class指定 mapper 接口的位置。
解析package和class时的逻辑是一样的,解析resource时逻辑则不同。也不能说是逻辑不同,只能说是逻辑执行的顺序不同,因为不管是resource还是package和class最后的逻辑都会互相融合在一起。- 指定
resource时的逻辑:- 通过
XMLMapperBuilder来解析resource指定的mapper.xml文件 - 解析 namespace 节点,获取当前
mapper.xml中设置的 namesapce,这个步骤很重要,后面会经常用到这个 namespace - 解析 cache 节点,当我们在
mapper.xml中开启了二级缓存时,会根据 cache 节点的配置来生成缓存对象,生成缓存对象时,会使用装饰器模式。最后会以 namespace 为 key,生成的缓存对象为 value 添加到 Configuration 对象的 caches 中。这也解释了为什么说二级缓存是 mapper 级别的,因为其用 namespace 当 key,而一个 mapper 只有一个 namespace - 解析 parameterMap 节点,parameterMap 现在已经很少使用了,在 Mybatis 3.x 中已经被标记为废弃了,未来可以会移除。这个节点的主要功能是对 动态SQL 中的参数进行映射。解析完成后会以 namespace 和 节点的 id 属性 为 key, 以解析出的 parameterMap 对象 为 value。添加到 Configuration 对象的 parameterMaps 中。
- 解析 resultMap 节点,这个节点的作用是,SQL 执行后,对 JDBC 返回的 ResultSet 进行映射。解析完成后会以 namespace 和 节点的 id 属性 为 key, 以解析出的 resultMap 对象 为 value。添加到 Configuration 对象的 resultMaps 中。
- 最后就是解析
mapper.xml中的 CRUD 节点,既(Select、Update、Insert、Delete 四个节点),这四个节点真正的记录了 SQL 语句。
Mybatis 会利用XMLStatementBuilder来解析这四个节点,并将每个 SQL 都按照 动态 SQL 和 静态 SQL 封装成不同子类型的 SqlSource 对象。然后会把 SqlSource 对象及mapper.xml解析出的其他属性融合在一起,创建出 MappedStatement 对象。最后以 namespace 和 CRUD 节点的 id 属性 为 key, 以 MappedStatement 对象 为 value。添加到 Configuration 对象的 mappedStatements 中。这样我们使用时调用sqlSession.selectList("namespace + id")就可以找到对应的 MappedStatement 了,这个 MappedStatement 对象包含了我们要执行的 SQL,SQL 入参,SQL 返回值,二级缓存等信息。 - 当
mapper.xml全部解析完成后,会根据 namespace 的路径查找是否有对应的 Mapper 接口。如果有 Mapper 接口,就会继续执行解析 Mapper 接口的逻辑(既指定package或class时的逻辑)
- 通过
- 指定
package或class时的逻辑:- 通过
MapperAnnotationBuilder来解析package或class指定的 Mapper 接口 - 首先会根据 Mapper 接口的包名查找是否有对应的 Mapper.xml 文件,如果有对应的 Mapper.xml 文件,并且 Mapper.xml 文件没被加载过,则先执行解析 Mapper.xml 文件的逻辑(既指定
resource时的逻辑) - 然后会真正的开始解析 Mapper 接口,解析逻辑和解析 XML 时差不多,最终也会生成 MappedStatement 对象,最后以 包名加方法名 为 key, 以 MappedStatement 对象 为 value,添加到 Configuration 对象的 mappedStatements 中。其实
sqlSession.getMapper(UserMapper.class).getUser()的底层逻辑就是sqlSession.selectList("包名 + 方法名")。
- 通过
- 指定
Mybatis 执行 SQL 原理
获得 SqlSession 对象 - openSession
在前面的步骤中,已经将 Mybatis 全局配置文件 和 Mapper 信息都加载到了 Configuration 中,并返回了包含 Configuration 对象的 SqlSessionFactory 对象。
接下来就是使用 Mybatis 执行 SQL,但是在执行 SQL 之前,需要先通过 SqlSessionFactory 获取 SqlSession 对象。这节就是介绍获取 SqlSession 对象的流程。SqlSession 其实就是内部包含了 Executor 对象,真正执行 SQL 的是 Executor 对象。
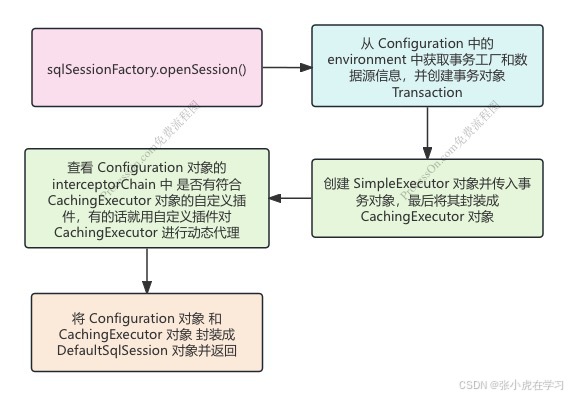
- 通过
sqlSessionFactory.openSession()开启调用 - 从 Configuration 中的 environment 中获取事务工厂对象和数据源对象,然后创建事务对象 Transaction
- 创建 Executor 对象,并通过构造方法传入事务对象 Transaction,这里默认会创建 SimpleExecutor 对象,然后通过装饰器模式将其包装成 CachingExecutor 对象。当使用二级缓存时,就先会在 CachingExecutor 中进行查找。
- 创建 Executor 对象后,会在 Configuration 对象的 interceptorChain 中查找是否有针对 Executor 的自定义插件,如果有的话就会对 Executor 进行动态代理,将自定义插件与其进行绑定。
- 最后会创建一个 DefaultSqlSession 对象,并将 Executor 对象和 Configuration 对象通过构造函数传入,最后返回这个 DefaultSqlSession 对象。
执行 SQL - selectList 方式
得到 SqlSession 对象之后,就可以真正的执行 SQL 了。执行 SQL 有两种方式,第一种是通过 sqlSession.selectList 这种方式, 另一种是通过 sqlSession.getMapper 这种方式。本节先记录第一种方式,下一节记录第二种方式。
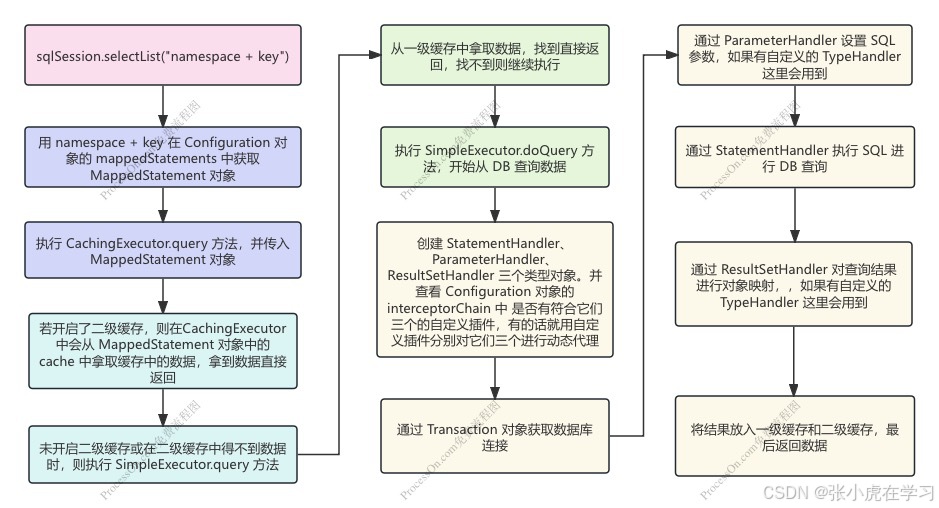
- 通过
sqlSession.selectList("namespace + id")进入到 DefaultSqlSession,开启整个流程 - 在 SqlSession 内用 namespace + id 在 Configuration 对象的 mappedStatements 中获取对应的 MappedStatement 对象。
- 用 SqlSession 内部的执行器执行 query 方法,因为之前获取 SqlSession 存入的执行器是 CachingExecutor,所以这里执行 CachingExecutor.query 方法,并传入 MappedStatement 对象。
- 若开启了二级缓存,则在 CachingExecutor 中会从 MappedStatement 对象中的 cache 中拿取缓存中的数据。拿到数据则直接返回。
- 未开启二级缓存或在二级缓存中得不到数据时,则执行装饰器模式中的 SimpleExecutor.query 方法
- 在 SimpleExecutor.query 方法中,先从一级缓存中拿取数据,找到直接返回,找不到则继续执行。
- 执行 SimpleExecutor.doQuery 方法,开始从 DB 查询数据。
- 创建 StatementHandler、ParameterHandler、ResultSetHandler 三个类型对象。并查看 Configuration 对象的 interceptorChain 中 是否有符合它们三个的自定义插件,有的话就用自定义插件分别对它们三个进行动态代理。
- 然后通过 Transaction 对象获取数据库连接
- 通过 ParameterHandler 设置 SQL 参数,如果有自定义的 TypeHandler 这里会用到。
- 通过 StatementHandler 执行 SQL,进行真正的 DB 查询。
- 通过 ResultSetHandler 对查询结果进行对象映射,如果有自定义的 TypeHandler 这里会用到。
- 将结果放入一级缓存和二级缓存,最后返回数据。
执行 SQL - getMapper 方式
sqlSession.getMapper 与 sqlSession.selectList 这两种方式相比,其实就是刚开始的流程有点区别,sqlSession.getMapper 最终还是会走进 sqlSession.selectList 的流程中。
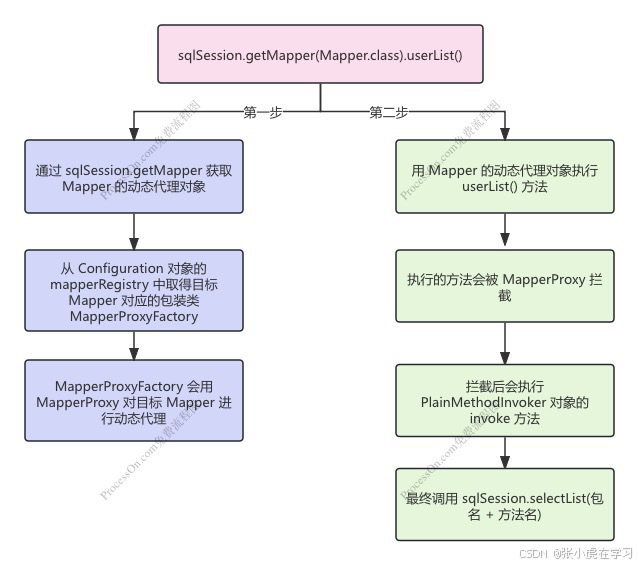
总共分两个大步骤执行:
- 通过 sqlSession.getMapper(Mapper.class) 获取 Mapper 的动态代理对象
- 从 Configuration 对象的 mapperRegistry 中取得目标 Mapper 对应的包装类 MapperProxyFactory
- MapperProxyFactory 会用 MapperProxy 对目标 Mapper 进行动态代理
- 用 Mapper 的动态代理对象执行 userList() 方法
- 执行的方法会被动态代理 MapperProxy 拦截
- 拦截后会创建 PlainMethodInvoker 对象,并传入 Configuration 对象。
- 执行 PlainMethodInvoker 的 invoke 方法,在方法内会通过 Configuration 对象拿到对应的 MappedStatement 对象(方式就是通过 目标接口的包名 + 方法名 ),并根据 MappedStatement 对象中保存的 sqlCommandType 来选择要执行的方法,比如 sqlCommandType 为 Select 时,就会执行 sqlSession.selectList(包名 + 方法名) 。之后就和执行 selectList 的流程一样了。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









