







【AI】使用Azure OpenAI创建自己的AI应用!
目录
推荐超级课程:

这里将以 Azure 提供的 Openai 端口为例,并使用 OpenAI 提供的Python SDK进行模型的调用。
创建工作区
进入Azure首页,在搜索栏输入OpenAI,点击进入OpenAI页面。

点击创建。

选择订阅,资源组,工作区名称,工作区地区,点击创建。这里我们的地区选择“美东”,因为目前只有这个地区支持chatgpt对话模型。如果你需要对话模型,可以选择其他模型种类更多的“西欧”。

选择下一步,确认无误后点击创建。

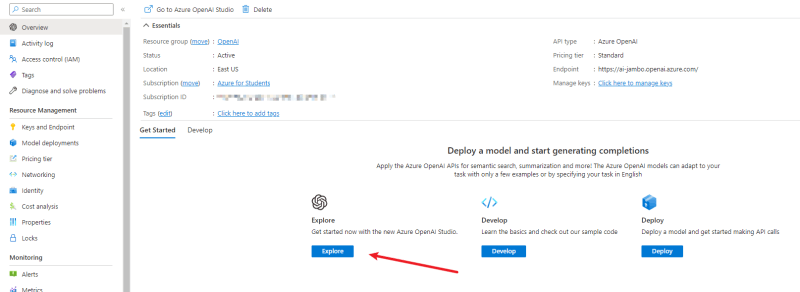
等他创建完成后,点击“探索”进入工作区。
模型介绍
在使用模型之前,我们先来了解一下Azure提供了哪些OpenAI模型。Azure提供的模型从功能上可以分为三大类:补全(completion)、对话(chat)、嵌入(embeddings)。
补全模型可以根据输入的文本,补全剩余的文本。这类模型顾名思义,就是根据前文续写后续的部分。他可以用来续写文章,补全程序。不仅如此,你其实也可以通过固定的文字格式来实现对话的效果。
对话模型相信用过ChatGPT的同学应该很熟悉。对话模型可以根据输入的文本方面,生成对话的回复。这类模型可以用来实现聊天机器人,也可以用来实现对话式的问答系统。在调用,对话模型与补全模型列表的区别是:你需要一个列表来存储对话的历史记录。
没有接触过NLP(自然语言处理)的同类可能会对“嵌入”这个词感到怀疑。“嵌入”显然就是将文本转换为支持的操作,而这个支持可以用来表示文本的语义信息,这样就可以方便地比较相似度的相似度。而嵌入模型就是用来实现这个操作的。
大多数模型拥有多个能力等级,能力越强处理的文字也计算复杂度,但相对的处理速度和使用成本调谐。通常有 4 个等级:达芬奇 > 居里 > 巴贝奇 > 阿达,其中达芬奇最强而Ada是最快的(有兴趣的同学可以查一下这4位名人)。在使用模型时,你可以根据自己的需求选择合适的等级。
具体的模型介绍可以参考Azure OpenAI 服务模型。
部署模型
在了解了模型的功能和等级之后,我们就可以开始使用模型了。在使用模型之前,我们需要先部署模型。在Azure OpenAI工作区中,进入“部署”页面。

选择模型,点击创建。这里我配置了一个补全模型和对话模型。
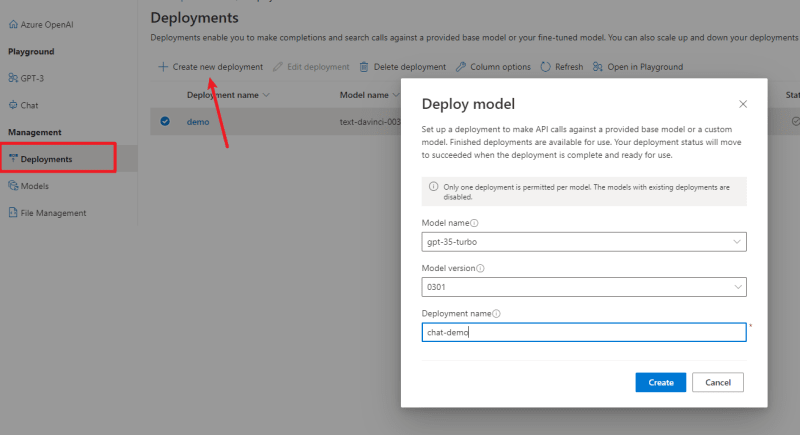
部署后你就可以用 API 调用模型了,当然你也可以现在 Playground 中测试一下。
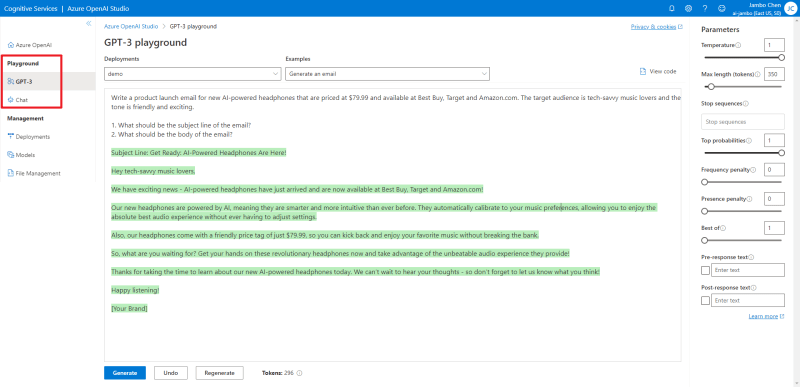
API参数
在 Playground 中测试模型时,我们可以看到 API 的参数。这里我们来介绍一下这些参数。具体的参数细节可以参考API 参考。
model指定使用的模型。prompt是输入给模型的文本。temperature控制了生成文本的随机程度,值越大,生成的文本越随机,值越小,生成的文本越稳定。这个值的范围在 0.0 到 2.0 之间(虽然在 Playground 中最高设置为 1) 。top_p与temperature类似,也是控制生成文本的随机程度。但这个参数简单的说是控制候选词的范围,值越大,候选词的范围越大,值越小,候选词的范围越小。这个值的范围在 0.0 到 1.0 之间。通常来说,这两个参数只需要设置一个就可以了。max_tokens是模型生成的文本的最大长度,这其中的“令牌”不是指字符长度,你可以理解为模型眼中的“词”。令牌与我们所使用的词不一定是一一对应的。stop是生成文本的条件停止,当生成的文本中包含这个字符串时,生成过程就会停止,最终生成的文本中将不包含这个字符串。这个参数可以是一个字符串,也可以是一个长度至多为4的字符串列表。presence_penalty控制生成文本的多样性。他会惩罚那些在生成文本中已经出现过的令牌,以减少未来生成这些令牌的概率。这个值的范围在 -2.0 到 2.0 之间。如果设为负值,那么惩罚就会奖励,这样就会增加生成这些Token的概率。frequency_penalty与presence_penalty类似,也是控制生成文本的多样性。但不同,presence_penalty是瞬时惩罚,而frequency_penalty累计惩罚。如果一个词在生成文本中出现了多次,那么这个词在未来生成的概率就会越来越多小。这个值的范围同样在 -2.0 到 2.0 之间。
计算Token
GPT 模型使用Token来表示文本,而不是使用字符。模型能处理的文本长度是有限的,而这个长度指的是Token的数量,而不是字符的数量,而 OpenAI 使用模型的乐器方式也按照生成方式token的数量计算。因此为了能够更好地使用模型,我们需要知道生成的文本到底有多少token。
OpenAI 提供了一个 Python 库tiktoken来计算Token。
pip install tiktoken
导入tiktoken库。
import tiktoken
不同的模型使用不同的编码来将转换为令牌。
| 编码名称 | OpenAI 模型 |
|---|---|
cl100k_base |
gpt-4, gpt-3.5-turbo,text-embedding-ada-002 |
p50k_base |
法典模型text-davinci-002,,text-davinci-003 |
r50k_base(或者gpt2) |
GPT-3 模型如davinci |
我们可以使用tiktoken.get_encoding()来获取编码对象。也可以使用tiktoken.encoding_for_model()通过模型名自动获取编码对象。
encoding = tiktoken.get_encoding("cl100k_base")
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
然后用.encode()方法将文本Token化。返回的Token列表的长度,就是文本的Token数量。
encoding.encode("tiktoken is great!")
[83, 1609, 5963, 374, 2294, 0]
我们还可以使用.decode()将令牌列表转换为文本。
encoding.decode([83, 1609, 5963, 374, 2294, 0])
'tiktoken is great!'
使用Python SDK
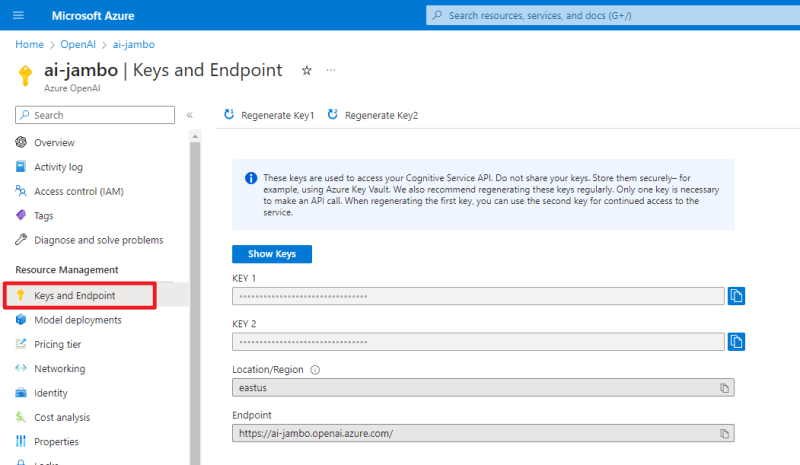
我们首先需要到Azure的“钥匙”页面获取钥匙和结束点,两个钥匙只要其中一个即可。
然后安装openai库。注意,Python版本需要大于等于3.7。我们这里使用官方提供的Python SDK,其他语言的SDK可以在OpenAI Libraries找到。
另外,因为这个库没有专门的文档参考,所以我们需要查看库的和API源码参考。
pip3 install openai
以上获取的密钥和终止点初始化SDK:
import openai
openai.api_key = "REPLACE_WITH_YOUR_API_KEY_HERE" # Azure 的密鑰
openai.api_base = "REPLACE_WITH_YOUR_ENDPOINT_HERE" # Azure 的終結點
openai.api_type = "azure"
openai.api_version = "2023-03-15-preview" # API 版本,未來可能會變
model = "" # 模型的部署名
调用补全模型
补全模型的使用openai.Completion.create方法,使用的参数在上面已经介绍过了,但是因为我使用的是 Azure 的 API,所以指定模型的参数名是engine。下面是一个简单的例子:
prompt = "1, 2, 3, 4, "
response = openai.Completion.create(
engine 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 9088
9088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











