








AlfredCheung
| |
| 其它翻译版本(1) |

AlfredCheung
| |
| 其它翻译版本(1) |
AlfredCheung
|


knarfytrebil
|
knarfytrebil
|
AlfredCheung
|
AlfredCheung
|
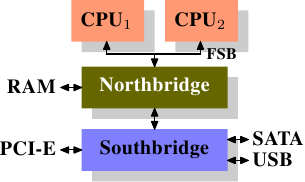
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|

AlfredCheung
|
AlfredCheung
|

AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|

AlfredCheung
|

![[Formulas]](https://i-blog.csdnimg.cn/blog_migrate/84174c168f64229b9432be4b5c02fd90.png)

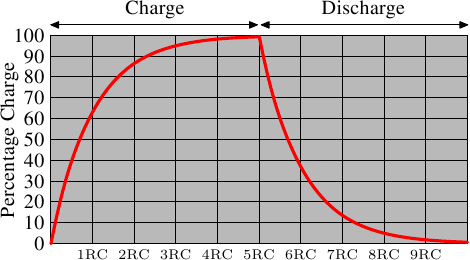



AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
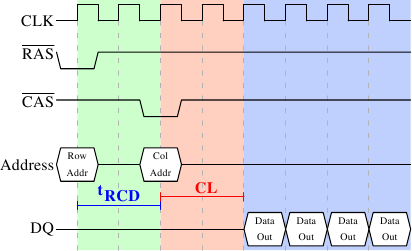
AlfredCheung
|
AlfredCheung
|

AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
| |
| 其它翻译版本(1) |
AlfredCheung
|


AlfredCheung
|
AlfredCheung
|

AlfredCheung
|
AlfredCheung
|

AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|

AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
| |
| 其它翻译版本(1) |
AlfredCheung
|

AlfredCheung
|
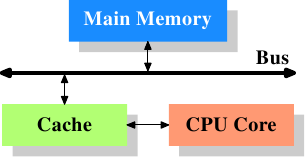
AlfredCheung
|

AlfredCheung
|


AlfredCheung
|
AlfredCheung
|

AlfredCheung
|





daleshen128
|
AlfredCheung
|

AlfredCheung
|
daleshen128
| |
| 其它翻译版本(1) |
daleshen128
| |
| 其它翻译版本(1) |

daleshen128
|
daleshen128
|

daleshen128
|
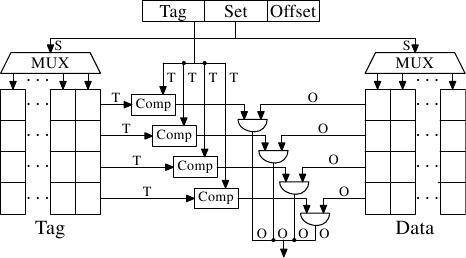
daleshen128
|
daleshen128
|
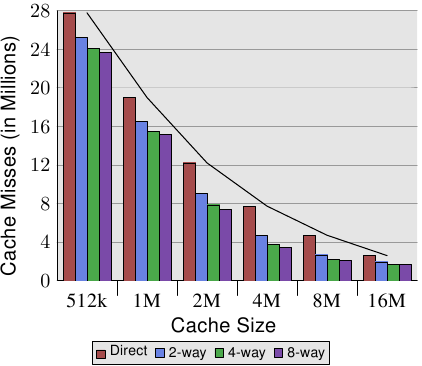
daleshen128
|
AlfredCheung
|
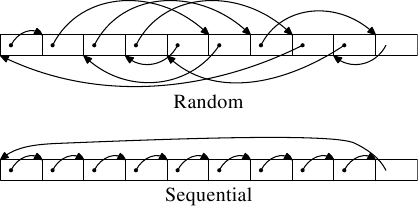


AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
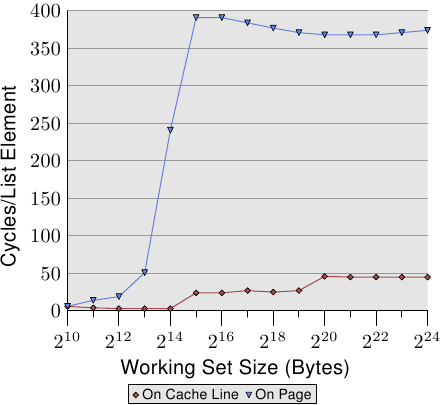

artistjuran
|
artistjuran
|
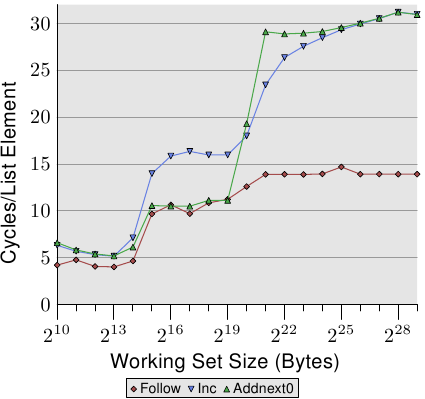
AlfredCheung
|
AlfredCheung
|
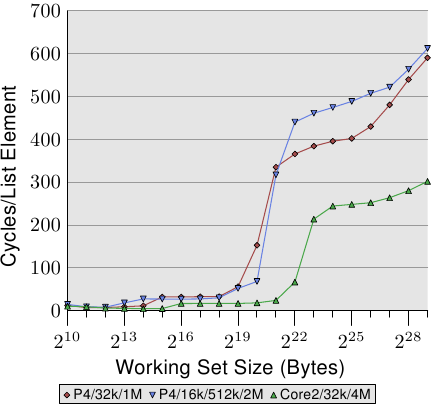
AlfredCheung
|
AlfredCheung
|
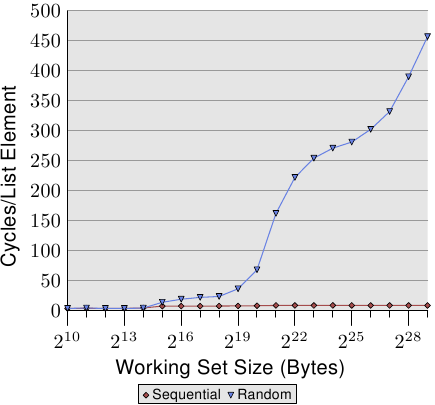
AlfredCheung
|
AlfredCheung
|
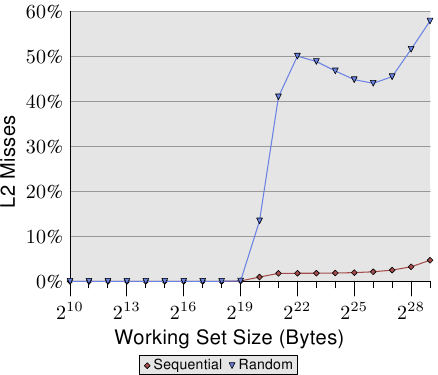

AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|

AlfredCheung
|
AlfredCheung
|

AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
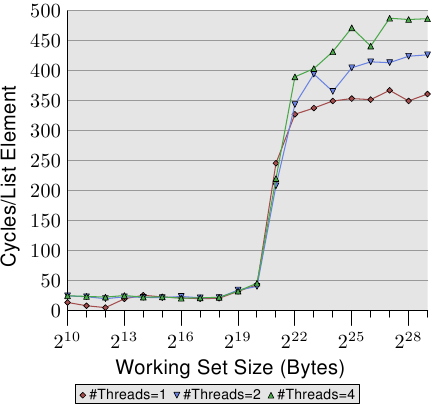
AlfredCheung
|
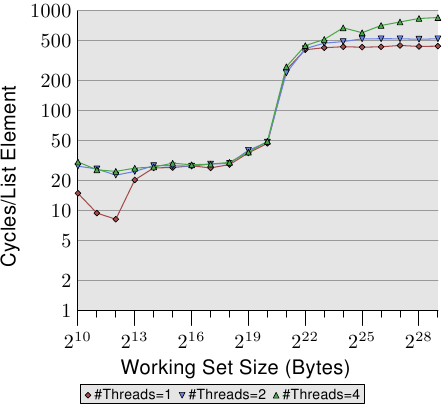
AlfredCheung
|

AlfredCheung
|

AlfredCheung
|
AlfredCheung
|


AlfredCheung
| |
| 其它翻译版本(1) |
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|

AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|

AlfredCheung
|
AlfredCheung
|

AlfredCheung
|

AlfredCheung
|

AlfredCheung
|
AlfredCheung
|

AlfredCheung
|
AlfredCheung
|


AlfredCheung
|
AlfredCheung
|


AlfredCheung
|
AlfredCheung
|

AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
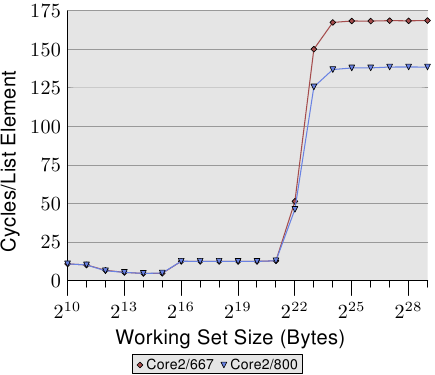



















 3490
3490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









