






介绍
在之前讲解获取静态词向量的方法中,都是在context_size下用到了word和context的共现关系。要么word预测context words,要么context words预测word。本质上都是利用文本中词与词在局部上下文中的共现信息作为自监督学习信息。
还有一种是通过矩阵分解的方式,比如LSA,然后使用SVD进行奇异值分解,对该矩阵进行降维,获得词的低维表示。
这部分可以参考【词的分布式表示】点互信息PMI和基于SVD的潜在语义分析。
那glove的提出就是就是结合了这两者的特点。
实现
其loss函数如下所示:
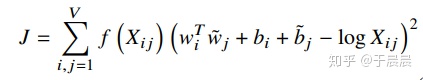
嘿嘿,hexo貌似公式还要额外折腾,懒的搞了~
这个公式分成两部分:
- 获取样本权重,这个是根据context_size内的共现次数来确定的,但是加上了距离衰减。

- WiWj为词两者的向量,Bi和Bj分别代表各自的偏置,logXij表示共现。
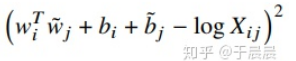
1. 数据处理
同样加载reuters数据集,但是不同之处在Dataset那里。代码如下:
| |
在共现次数随距离衰减那里,glove考虑了w与c的距离,即词w和上下文c在受限窗口大小内的共现次数与距离,越远的词的贡献程度越低。
下面在计算loss时有多个地方引用这个共现矩阵,所以注意。
2. 模型
| |
整体模型和其他求静态词向量的模型基本一致,只是多了求偏置部分。
3. 过程
模型的输出就代表了下面这部分。
具体的实现代码如下所示。
| |
剩下log那项就是对共现矩阵求log。完整代码如下所示:
| |
剩下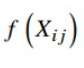 这项,即是求样本权重,完整代码如下:
这项,即是求样本权重,完整代码如下:
| |
乍一看其实和求log(count)那部分没有本质区别。只不过是对其进行了分段加权处理。
本质是共现次数越少那么含有的有用信息越少,因此给予较低的权重,相反,对于高频出现的样本,那么也要避免给予过高的权重。
使用
关于静态词向量使用上可以有两个方向。一是计算词语之间的相似度(similar),二是根据一组词来类推相似的词(analogy)。
比如和哥哥相似的词是兄长,这个叫做相似度。
根据国王和皇后,来类推和男人相似的是女人。
总之这两者本质上来讲都是计算空间距离,具有相同语义的词的空间距离会更近。
完整测试代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49# Defined in Section 5.4.1 and 5.4.2
import torch
from utils import load_pretrained
def knn(W, x, k):
"""
W为所有embed
x为输入的vector
k为topK
"""
similarities = torch.matmul(x, W.transpose(1, 0)) / (torch.norm(W, dim=1) * torch.norm(x) + 1e-9)
knn = similarities.topk(k=k)
return knn.values.tolist(), knn.indices.tolist()
def find_similar_words(embeds, vocab, query, k=5):
"""
获取与vocab相似的词组列表
"""
knn_values, knn_indices = knn(embeds, embeds[vocab[query]], k + 1)
knn_words = vocab.convert_ids_to_tokens(knn_indices)
print(f">>> Query word: {query}")
for i in range(k):
print(f"cosine similarity={knn_values[i + 1]:.4f}: {knn_words[i + 1]}")
# 获取相似的词
word_sim_queries = ["china", "august", "good", "paris"]
vocab, embeds = load_pretrained("glove.vec")
for w in word_sim_queries:
find_similar_words(embeds, vocab, w)
def find_analogy(embeds, vocab, word_a, word_b, word_c):
"""
根据word_a, word_b,来类推与word_c相似的词
"""
vecs = embeds[vocab.convert_tokens_to_ids([word_a, word_b, word_c])]
x = vecs[2] + vecs[1] - vecs[0]
knn_values, knn_indices = knn(embeds, x, k=1)
analogies = vocab.convert_ids_to_tokens(knn_indices)
print(f">>> Query: {word_a}, {word_b}, {word_c}")
print(f"{analogies}")
word_analogy_queries = [["brother", "sister", "man"],
["paris", "france", "berlin"]]
vocab, embeds = load_pretrained("glove.vec")
for w_a, w_b, w_c in word_analogy_queries:
find_analogy(embeds, vocab, w_a, w_b, w_c)
参考文档

完整实现
| |















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









