







一、前言:我们已经讲了 MLLM 能力,但它到底是怎么实现“看图说话”的?
在之前文章中,我们已经提到了MLLM可以看图说话以及文生图等能力,ViT统一图文多模态架构。那模型是如何处理图文信息以及不同处理所带来的能力是怎样?
针对这个问题,我们今天简单讲解三个模型:CLIP、ViLT和LLaVA。也相当是从历史角度来看模型的发展。
本篇还是遵循以往风格,不讲深入原理,也如本篇文章可爱活泼的配图,尽可能把这三个大块用大白话与轻松语言串起来。后续有需要可以更为细致来单独讲解。
二、CLIP:图文对齐的起点,擅长“找图”不擅长“说话”
百度搜图
假设我们现在想实现一个搜图功能,如上图百度搜图,该如何实现?CLIP可以。
CLIP由OpenAI提出,用于图文联合理解。其技术核心是文本Encoder+图像Encoder ,通过对比学习做匹配。
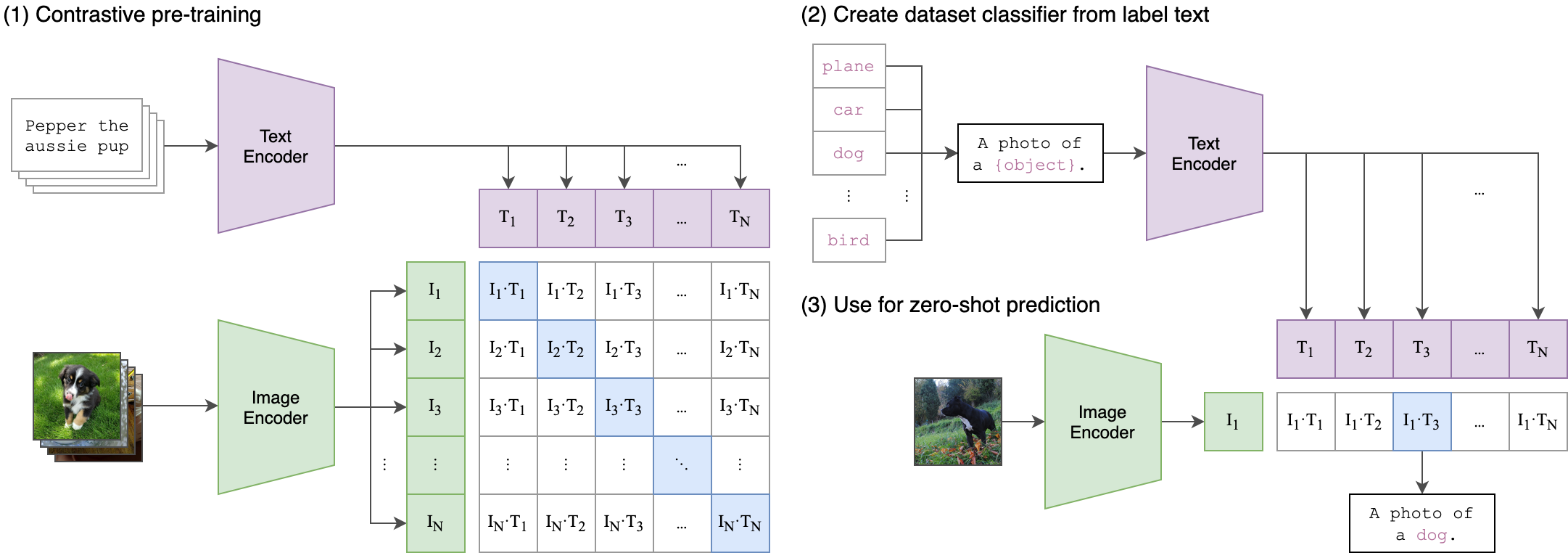
CLIP架构图
按照对之前文章的理解,文本Encoder可使用Bert [CLS],图像Encoder亦是可以通过ViT增加[CLS]。
就好比是:
-
输入“狗狗”文本 →Text Encoder →[1.232,0.23432, ..... 1.0023]向量A
-
输入“狗狗”图片→Image Encoder→[0.332,0.352, ..... 0.0043]向量B
如上图,向量A和向量B维度通过对比学习即可将二者关联至一起。
那什么是“对比学习”?
还记得最开始讲Word2Vec吗,语义相似的词空间分布也是临近的。按照这个假设,“狗狗文本”和“狗狗图片”也是如此,而针对“猫咪文本/图片”、“雨伞文本/图片”是不临近的,这些也被称为Negative Sample。
如果你把 Word2Vec 看作“词向量”,CLIP 就是“图文向量”。
对比学习概念在RAG中做Recall和Rerank也是存在和相通的。
后续有需要可以单开一篇来进行讲解。
从上面可以看到,CLIP可以文搜图/图搜文,但是它不能生成语言,只会匹配。
但同时一个最大的突破点在于:用超大规模图文对训练,做到了“零样本”的通用匹配能力。你几乎不用标注新数据,就能在各类任务上迁移使用。
三、ViLT:图文都看,但轻量
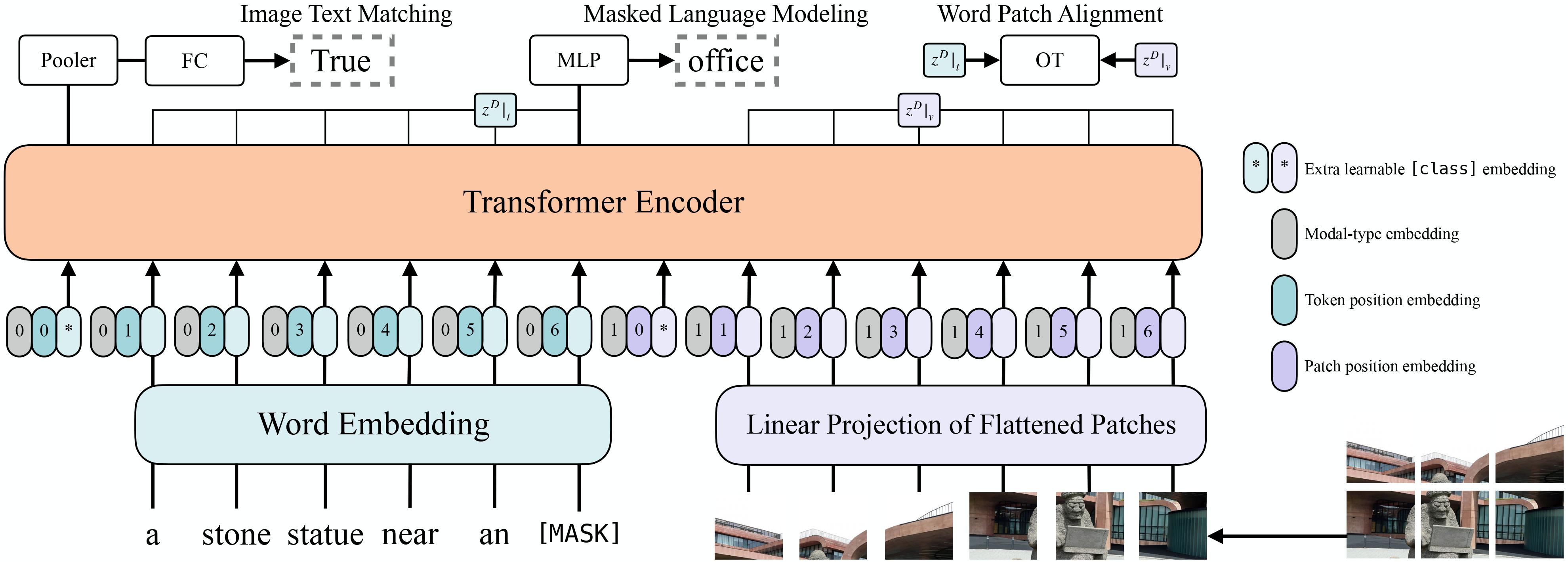
ViLT架构图
CLIP 的做法是“图片一个模型,文本一个模型,最后对齐两个向量”,就像是两个学生分别看了一张图和一段话,然后一起交头接耳说:“你说的‘狗狗’,和我看到的图片,好像是同一只。”
那 ViLT 想干嘛?ViLT 想要一个学生同时读图又读文。
ViLT(Vision-and-Language Transformer)尝试把patch token跟文本 token 混在一起统一输入 Transformer,也就是说:
-
图片不再单独走ViT,而是先转成 patch embedding,然后直接和文本 embedding 混起来;
-
全部进 Transformer 之后统一建模,注意力机制能直接捕捉图文之间的联系。
举个不严谨但有趣的比喻:
-
CLIP 是两位学生各自读图读文后讨论;
-
ViLT 是一个学生自己把图文都看了,然后理解两者之间的关系;
但是,由于ViLT将图文 token 混在一起送进同一个 Transformer,靠自注意力机制互相“看”,导致其整体理解能力有限。所以ViLT更适合做分类这种比较轻量级的任务。
另外因为CLIP和ViLT架构上用的是Transformer Encoder,所以也不具备生成能力。
四、LLaVA:图像理解+对话能力合体,看图还能说话
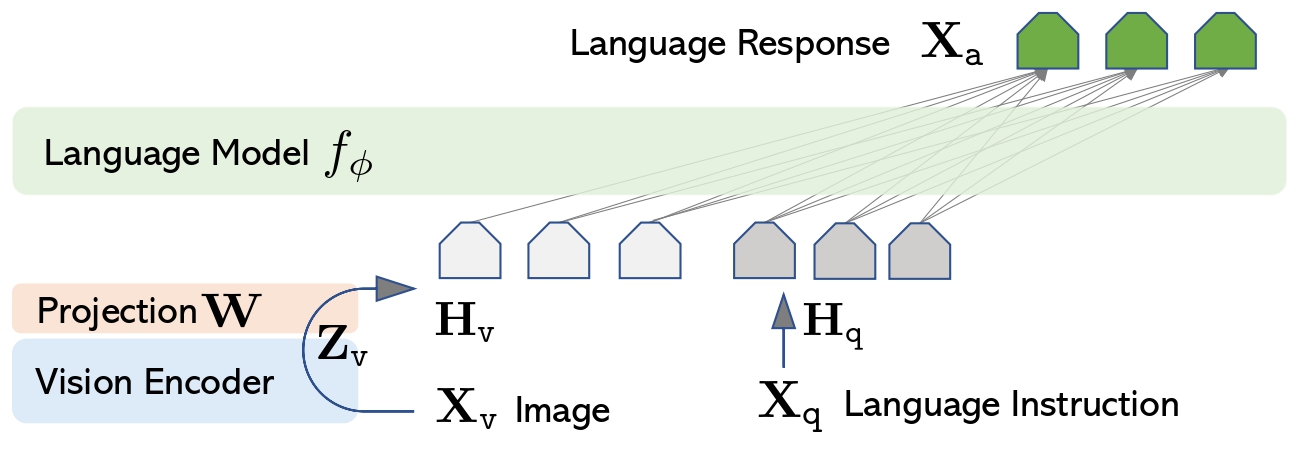
LLaVA架构图
上图很好表明了LLaVA的架构和流程,其整体由三部分组成:
-
Vision Model(负责图片处理)
-
Projection(将图片Embed映射到Language Model)
-
Language Model(实现看图说话,例如Llama)
针对更具体的,可看最后附录部分。
同样我们也可以注意到,Vision Model和Language Model分别对应CLIP和Llama,这两个模型是可以独立分开优化的,然后通过Projection将这两者连接到一起,起到“桥梁”作用。
例如vision_model的输出维度是1024,而language_model 的输入维度是 4096,所以必须做“投影变换”,这就是 projection 的作用。
另外你可能会问,技术流程上我大概看懂了,那图片是插在哪里的呢?
答案是可以自己指定,通过占位符<image>。
例如:prompt = "USER: <image>\nWhat's the content of the image? "
五、总结:从对齐到融合,从匹配到生成
这三种模型可以形成一条多模态的发展路径:
| 模型 | 图文处理方式 | 能力 | 优点 | 不足 |
|---|---|---|---|---|
| CLIP | 图文分开编码 + 对比学习 | 图文检索、匹配 | 训练数据丰富、表现稳定 | 不会说话,只能匹配 |
| ViLT | 图文融合 + Transformer | 图文匹配、分类 | 模型轻巧、统一结构 | 图像理解能力弱,不生成语言 |
| LLaVA | 图像理解 + LLM生成 | 图像问答、对话 | 能看图说话、回答灵活 | 拼接结构、效率较低 |
至此,我们大致初步讲清楚了多模态的历史发展,以及从能力角度和痛点来进行还原与分析。目前多模态的发展也是很快的,例如国内的Qwen-VL系列,MiniCPM-V系列,甚至是文本+图像+语音统一融合的多模态。以及针对视频也可以直接处理。也可以看到目前国内快速的进步与超越!
讲到这里,我们也大致屡清了NLP→大模型→CV→多模态大模型,但是针对具体方向,我们可以聊的还有很多。
附录:LLaVA的模型架构
LlavaForConditionalGeneration(
(vision_tower): CLIPVisionModel(
(vision_model): CLIPVisionTransformer(
(embeddings): CLIPVisionEmbeddings(
(patch_embedding): Conv2d(3, 1024, kernel_size=(14, 14), stride=(14, 14), bias=False)
(position_embedding): Embedding(577, 1024)
)
(pre_layrnorm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(encoder): CLIPEncoder(
(layers): ModuleList(
(0-23): 24 x CLIPEncoderLayer(
(self_attn): CLIPAttention(
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(layer_norm1): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp): CLIPMLP(
(activation_fn): QuickGELUActivation()
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
)
(layer_norm2): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
)
(post_layernorm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
(multi_modal_projector): LlavaMultiModalProjector(
(linear_1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELUActivation()
(linear_2): Linear(in_features=4096, out_features=4096, bias=True)
)
(language_model): LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(32064, 4096)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=11008, bias=False)
(up_proj): Linear(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=32064, bias=False)
)
)

















 384
384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











