







文章目录
Spark编程基础-搭配Jupyter
Spark MLlib
1.1 Spark MLlib简介
- 机器学习的概念就不在这里介绍了,我们详细介绍一下MLLIB
- MLLIB是Spark机器学习库,旨在简化机器学习的工程实践工作,并方便扩展到更大规模。传统的机器学习由于技术和单机存储的限制,只能在少量数据使用,而在spark中,分布式大数据前提下运用的机器学习,如此大规模的数据跑出来的模型将会达到一个比较不错的通用性是适配性,可以尽快的达到应用落地的结果
- MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。具体来说,其主要包括以下几方面的内容:
- 算法工具:常用的学习算法,如分类、回归、聚类和协同过滤;
- 特征化工具:特征提取、转化、降维,和选择工具;
- 管道(Pipeline):用于构建、评估和调整机器学习管道的工具;
- 持久性:保存和加载算法,模型和管道;
- 实用工具:线性代数,统计,数据处理等工具。
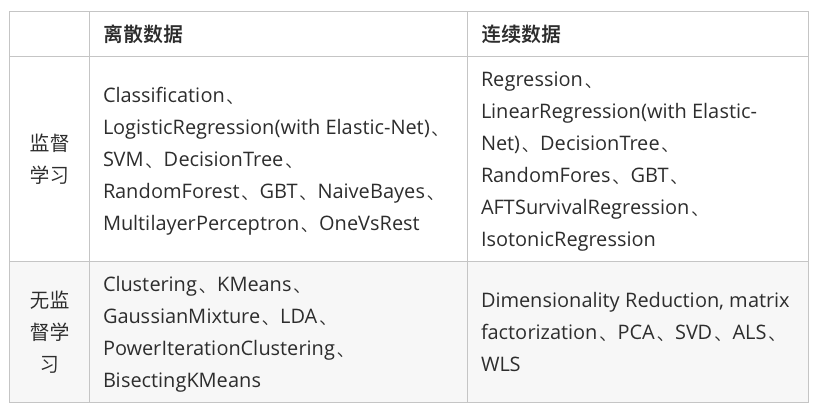
纵观所有基于分布式架构的开源机器学习库,MLlib可以算是计算效率最高的。MLlib目前支持4种常见学习问题:分类、回归、聚类和协同过滤。下图列出了目前MLlib支持的主要机器学习算法:
1.2 机器学习工作流
一个典型的机器学习过程从数据收集开始,要经历多个步骤,才能得到需要的输出。这非常类似于流水线式工作,即通常会包含源数据ETL(抽取、转化、加载),数据预处理,指标提取,模型训练与交叉验证,新数据预测等步骤。
1.2.1 机器学习工作流(ML Pipelines)
1.2.1.1 重要概念
在介绍工作流之前,我们先来了解几个重要概念:
- DataFrame:使用Spark SQL中的DataFrame作为数据集,它可以容纳各种数据类型。 较之 RDD,包含了 schema 信息,更类似传统数据库中的二维表格。它被 ML Pipeline 用来存储源数据。例如,DataFrame中的列可以是存储的文本,特征向量,真实标签和预测的标签等。
- Transformer:翻译成转换器,是一种可以将一个DataFrame转换为另一个DataFrame的算法。比如一个模型就是一个 Transformer。它可以把 一个不包含预测标签的测试数据集 DataFrame 打上标签,转化成另一个包含预测标签的 DataFrame。技术上,Transformer实现了一个方法transform(),它通过附加一个或多个列将一个DataFrame转换为另一个DataFrame。
- Estimator:翻译成估计器或评估器,它是学习算法或在训练数据上的训练方法的概念抽象。在 Pipeline 里通常是被用来操作 DataFrame 数据并生产一个 Transformer。从技术上讲,Estimator实现了一个方法fit(),它接受一个DataFrame并产生一个转换器。如一个随机森林算法就是一个 Estimator,它可以调用fit(),通过训练特征数据而得到一个随机森林模型。
- Parameter:Parameter 被用来设置 Transformer 或者 Estimator 的参数。现在,所有转换器和估计器可共享用于指定参数的公共API。ParamMap是一组(参数,值)对。
- PipeLine:翻译为工作流或者管道。工作流将多个工作流阶段(转换器和估计器)连接在一起,形成机器学习的工作流,并获得结果输出。
1.2.1.2 工作机制
要构建一个 Pipeline工作流,首先需要定义 Pipeline 中的各个工作流阶段PipelineStage,(包括转换器和评估器),比如指标提取和转换模型训练等。有了这些处理特定问题的转换器和 评估器,就可以按照具体的处理逻辑有序的组织PipelineStages 并创建一个Pipeline。比如:
1.2.2 构建一个机器学习工作流
1.2.2.1 传统流程
import os
from pyspark import SparkContext
from pyspark.ml.linalg import Vectors
from pyspark.ml.classification import LogisticRegression
from pyspark.sql.session import SparkSession
# pipeline 模式
from pyspark.ml import Pipeline
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.feature import HashingTF,Tokenizer
os.environ['JAVA_HOME']
sc = SparkContext( 'local', 'test')
spark = SparkSession(sc)
# 导入向量和模型
# from pyspark.ml.linalg import Vectors
# from pyspark.ml.classification import LogisticRegression
# from pyspark.sql.session import SparkSession
# 准备训练数据
# Prepare training data from a list of (label, features) tuples
# spark = SparkSession(sc)
training = spark.createDataFrame([
(1.0,Vectors.dense([0.0,1.1,0.1])),
(0.0,Vectors.dense([2.0,1.0,-1.0])),
(0.0,Vectors.dense([2.0,1.3,1.0])),
(1.0,Vectors.dense([0.0,1.2,-0.5]))],["label","features"])
# 创建回归实例,这个实例是Estimator
# Create a LogisticRegression instance.This instance is an Estimator.
lr = LogisticRegression(maxIter=10, regParam=0.01)
# print("LogisticRegression parameters:\n" + lr.explainParams() + '\n')
# 使用lr中的参数训练出model
# Learn a LogisticRegression model.This uses the parameters stored in lr.
model1 = lr.fit(training)
# Since model1 is a Model (i.e., a transformer produced by an Estimator),
# we can view the parameters it used during fit().
# This prints the parameter (name: value) pairs, where names are unique IDs for this
# LogisticRegression instance.
#查看model1在fit()中使用的参数
# print("Model 1 was fit using parameters: ")
# print(model1.extractParamMap())
paramMap = {lr.maxIter: 20}
paramMap[lr.maxIter] = 30
paramMap.update({lr.regParam: 0.1, lr.threshold: 0.55})
# You can combine paramMaps, which are python dictionaries.
# 新的参数,合并为两组参数对
paramMap2 = {lr.probabilityCol: 'myProbability'}
paramMapCombined = paramMap.copy()
paramMapCombined.update(paramMap2)
# paramMapCombined
# 重新得到model2并拿出来参数瞅瞅
model2 = lr.fit(training, paramMapCombined)
# print('Model 2 was fit using parameters: ')
# print(model2.extractParamMap())
# 准备测试的数据
# Prepare test data
test = spark.createDataFrame([
(1.0,Vectors.dense([-1.0,1.5,1.3])),
(0.0,Vectors.dense([3.0,2.0,-0.1])),
(1.0,Vectors.dense([0.0,2.2,-1.5]))],["label","features"])
prediction = model2.transform(test)
selected = prediction.select('features', 'label', 'myProbability', 'prediction')
for row in selected.collect():
print(row)
>>> Row(features=DenseVector([-1.0, 1.5, 1.3]), label=1.0, myProbability=DenseVector([0.0571, 0.9429]), prediction=1.0)
>>> Row(features=DenseVector([3.0, 2.0, -0.1]), label=0.0, myProbability=DenseVector([0.9239, 0.0761]), prediction=0.0)
>>> Row(features=DenseVector([0.0, 2.2, -1.5]), label=1.0, myProbability=DenseVector([0.1097, 0.8903]), prediction=1.0)
上面这段代码是用jupyter运行,简易的模型,没有用到pipeline,是传统的机器学习的顺序逻辑,这中间有很多方法和函数需要大家去官网学习,笔者也在学习中,心得尚缺。
1.2.2.2 Pipeline
这里直接上jupyter中的代码:
import os
from pyspark import SparkContext
from pyspark.ml.linalg import Vectors
from pyspark.ml.classification import LogisticRegression
from pyspark.sql.session import SparkSession
# pipeline 模式
from pyspark.ml import Pipeline
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.feature import HashingTF,Tokenizer
os.environ['JAVA_HOME']
sc = SparkContext( 'local', 'test')
spark = SparkSession(sc)
#准备测试数据
# Prepare training documents from a list of (id, text, label) tuples.
training = spark.createDataFrame([
(0,"a b c d e spark",1.0),
(1,"b d",0.0),
(2,"spark f g h",1.0),
(3,"hadoop mapreduce",0.0)],["id","text","label"])
#构建机器学习流水线
# Configure an ML pipeline, which consists of three stages: tokenizer, hashingTF, and lr.
tokenizer = Tokenizer(inputCol="text", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
print('What pipeline is : \n', pipeline.params)
#训练出model
# Fit the pipeline to training documents.
model = pipeline.fit(training)
print('What model is :\n', model)
#测试数据
# Prepare test documents, which are unlabeled (id, text) tuples.
test = spark.createDataFrame([
(4,"spark i j k"),
(5,"l m n"),
(6,"mapreduce spark"),
(7,"apache hadoop")],["id","text"])
#预测,打印出想要的结果
# Make predictions on test documents and print columns of interest.
prediction = model.transform(test)
selected = prediction.select("id","text","prediction")
for row in selected.collect():
print(row)
期间遇到挺多问题,首先就是内存问题,由于服务器是1G的垃圾服务器(腾讯云真的很差劲),所以经常CPU卡死,这里又引发一个linux内核换页处理的 就是图中的kswapd0,这里大家如果遇到相同问题可以去百度搜搜怎么设置,反正最后我的pipeline没有跑出来。

1.3 特征抽取、转化和选择
这一部分我们主要介绍和特征处理相关的算法,大体分为以下三类:
- 特征抽取:从原始数据中抽取特征
- 特征转换:特征的维度、特征的转化、特征的修改
- 特征选取:从大规模特征集中选取一个子集
1.3.1 特征抽取:TF-IDF
TF-IDF (HashingTF and IDF)
“词频-逆向文件频率”(TF-IDF)是一种在文本挖掘中广泛使用的特征向量化方法,它可以体现一个文档中词语在语料库中的重要程度。
词语由t表示,文档由d表示,语料库由D表示。词频TF(t,d)是词语t在文档d中出现的次数。文件频率DF(t,D)是包含词语的文档的个数。如果我们只使用词频来衡量重要性,很容易过度强调在文档中经常出现,却没有太多实际信息的词语,比如“a”,“the”以及“of”。如果一个词语经常出现在语料库中,意味着它并不能很好的对文档进行区分。TF-IDF就是在数值化文档信息,衡量词语能提供多少信息以区分文档。其定义如下:

在Spark ML库中,TF-IDF被分成两部分:TF (+hashing) 和 IDF。
- TF: HashingTF 是一个Transformer,在文本处理中,接收词条的集合然后把这些集合转化成固定长度的特征向量。这个算法在哈希的同时会统计各个词条的词频。
- IDF: IDF是一个Estimator,在一个数据集上应用它的fit()方法,产生一个IDFModel。 该IDFModel 接收特征向量(由HashingTF产生),然后计算每一个词在文档中出现的频次。IDF会减少那些在语料库中出现频率较高的词的权重。
上一节中我们创建了ML-Pipeline工作流,我们重用上节的代码
sentenceData = spark.createDataFrame([(0, "I heard about Spark and I love Spark"),(0, "I wish Java could use case classes"),(1, "Logistic regression models are neat")]).toDF("label", "sentence")
tokenizer = Tokenizer(inputCol="sentence", outputCol="words")
wordsData = tokenizer.transform(sentenceData)
hashingTF = HashingTF(inputCol="words", outputCol="rawFeatures", numFeatures=20)
featurizedData = hashingTF.transform(wordsData)
# 之后就需要创建IDF对象了
idf = IDF(inputCol="rawFeatures", outputCol="features")
idfModel = idf.fit(featurizedData)
rescaledData = idfModel.transform(featurizedData)
rescaledData.select("label", "features").show()
上面通过调用Estimator调用fit()将词频向量传入之后即可得到IDFModel,然后在transform(),就可以得到每个单词对应的TF-IDF度量值了。
1.3.4 特征变换:标签和索引的转化
在机器学习处理过程中,为了方便相关算法的实现,经常需要把标签数据(一般是字符串)转化成整数索引,或是在计算结束后将整数索引还原为相应的标签。
Spark ML包中提供了几个相关的转换器,例如:StringIndexer、IndexToString、OneHotEncoder、VectorIndexer。
用于特征转换的转换器和其他机器学习算法一样,也属于ML Pipeline模型的一部分,可以构建机器学习流水线,以StringIndexer为例,其存储这进行标签数值化过程的相关超参数,是一个Estimator,对其调用fit()方法就可以生成模型StringIndexerModel类。存储了用于DataFrame进行相关处理的参数,也是一个Transformer
1.3.5 特征选取:卡方选择器
特征选择(Feature Selection)指的是在特征向量中选择出那些“优秀”的特征,组成新的、更“精简”的特征向量的过程。它在高维数据分析中十分常用,可以剔除掉“冗余”和“无关”的特征,提升学习器的性能。
特征选择方法和分类一样,分监督学习和无监督学习,卡方选择器是统计学上一种有监督特征选择方法,有兴趣的朋友可以了解一下卡方校验的具体含义
卡方校验主要由ChiSqSelector和ChiSqSelectorModel两个类来实现。
- 直接上代码:
# 启动sc、spark都在前面已经创建好了
from pyspark.ml.feature import ChiSqSelector
from pyspark.ml.linalg import Vectors
# 创建一个具有3个样本,四个特征维度的数据集,标签分别为1/0:
df = spark.createDataFrame([
(7, Vectors.dense([0.0, 0.0, 18.0, 1.0]), 1.0,),
(8, Vectors.dense([0.0, 1.0, 12.0, 0.0]), 0.0,),
(9, Vectors.dense([1.0, 0.0, 15.0, 0.1]), 0.0,)], ["id", "features", "clicked"])
# 为了观察地更明显,我们设置只选择和标签关联性最强的一个特征可以通过numTopFeatures参数方法进行设置
selector = ChiSqSelector(numTopFeatures=1, featuresCol="features", outputCol="selectedFeatures", labelCol="clicked")
用训练出模型对原数据集进行处理,可以看出第三列特征被选出作为最有用的特征列:
| id | features | clicked | selectedFeatures |
|---|---|---|---|
| 7 | [0.0,0.0,18.0,1.0] | 1.0 | [18.0] |
| 8 | [0.0,1.0,12.0,0.0] | 0.0 | [12.0] |
| 9 | [1.0,0.0,15.0,0.1] | 0.0 | [15.0] |














 407
407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









