







模型描述
det_10g是insightface 人脸框图和人脸关键点的分类,最终能够得到人脸框图bbox,分值还有人脸五官(眼x2、鼻子x1、嘴巴x2)
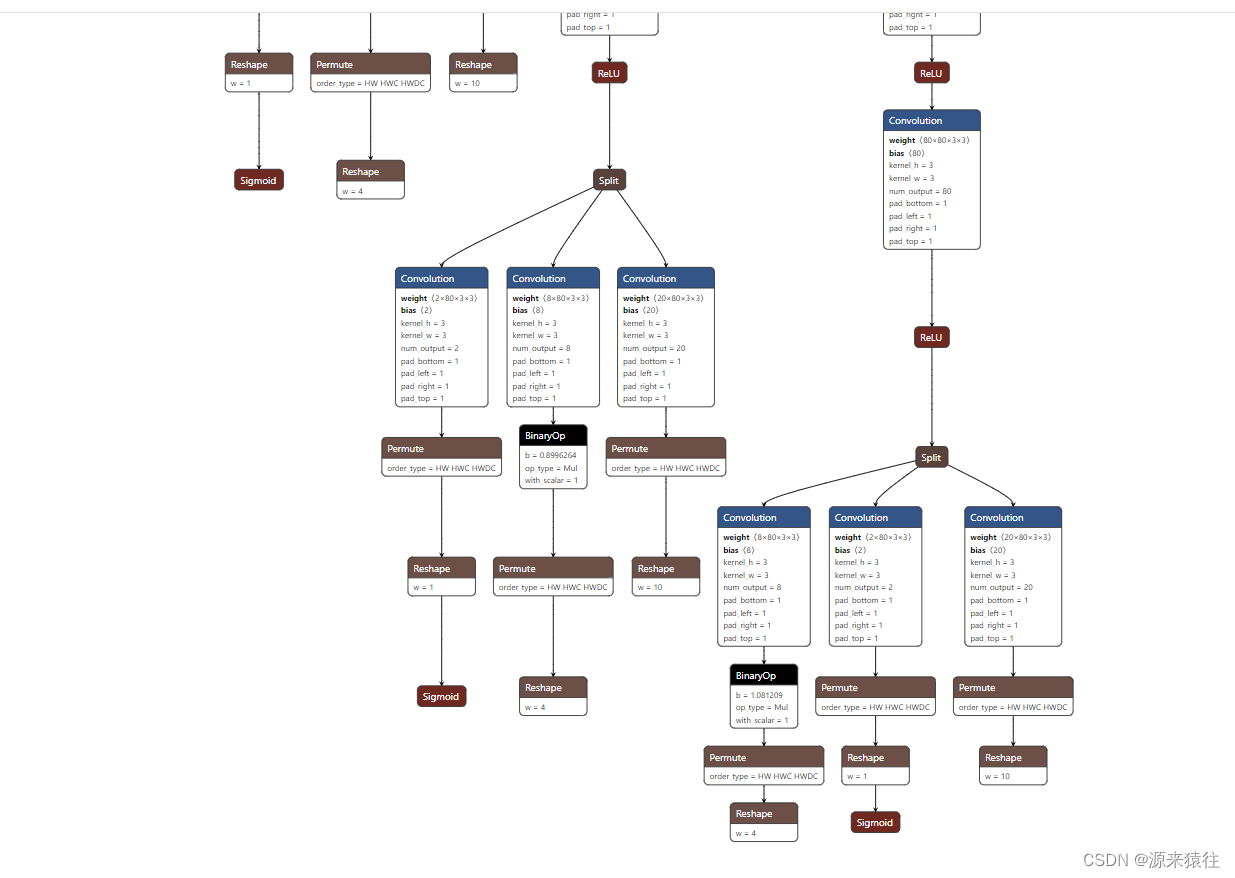
由于我这里没有采用最终结果,通过onnx转换为ncnn,所以后面的步骤结果丢弃了,具体可以看另外一篇博文:模型onnx转ncnn小记-CSDN博客
输入处理
在python的时候输入和ncnn(c++)入参还是有些区别
由于模型的输入是我这边选择的是1x3x640x640,所以针对输入的图片需要进行处理,首先进行等比缩放和数据的差值和归一化处理
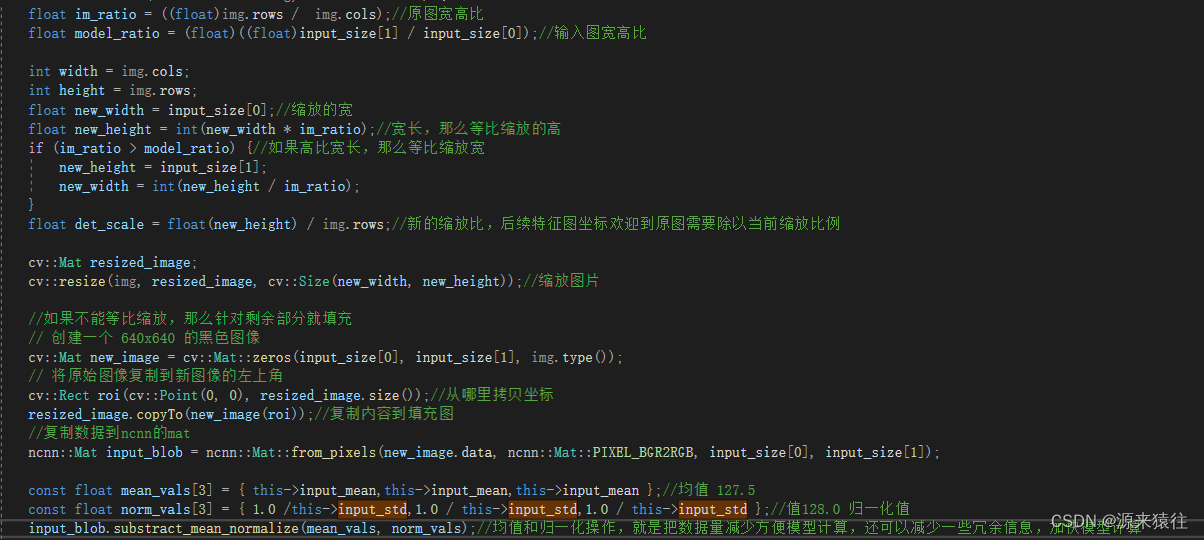
获取结果
把输入得到如下,9个结果
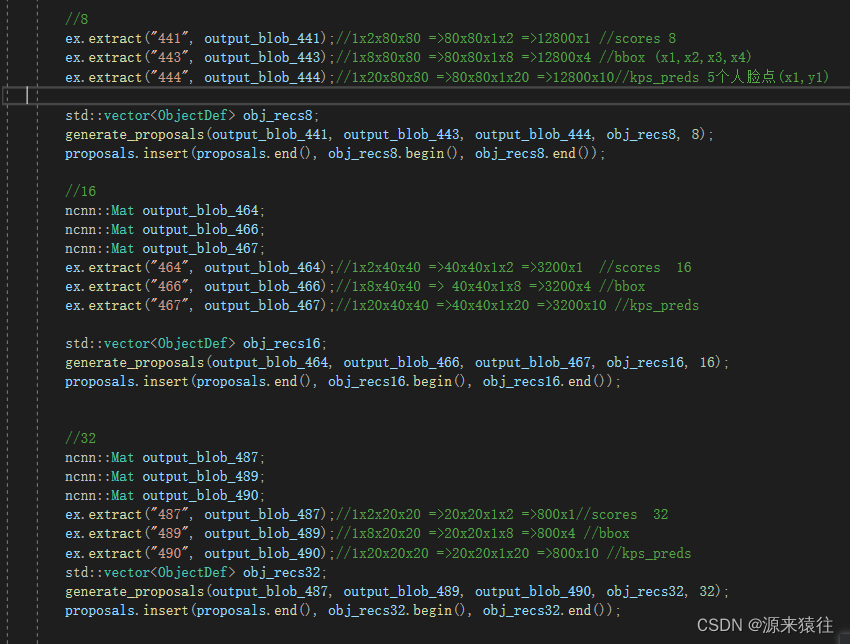
通过获取(441,443,444),(464,466,467),(487,489,490)
可以分别得到步长8, 16, 32 的三组数据,可以先了解下,目标候选框bbox的基础知识
计算坐标值和过滤
需要分别计算步长8、16和32的目标数据,下面是步骤
步骤一:结果变换维度
变换维度,方便处理和理解。
他的一组数据是(441,443,444),获取的大小是:scores=》1x2x80x80、bboxs=>1x8x80x80、kps=>1x20x80x80
通过insightface的源码可以看到,num_anchors = 2,每个位置的目标框是两组,正常来说是黑白图两种,既然是同一个位置,那么可以合并一起,所以。
1、scores:1x2x80x80 意思就是有2张图 ,每张图大小是80x80,有这么多分值,我们可以通过阈值把大多数的点过滤出去,默认的阈值是0.5.
2、bboxs: 1x8x80x80 每一个分数对应的四个点(x1,y1,x2,y2)*注意这个点是距离原点的相对值,还是需要计算的,这里1x8 前面1~4 是一个矩形框的点,后面的4~8是另一张图的矩形框坐标点,就是黑白图。
3、kps:1x20x80x80 每一个分数对应的五官坐标点(x,y)*注意这个点是距离原点的相对值,还是需要计算的,这里1~10 是一组坐标点,另外的10~20是另外一张图的一组坐标点,分开计算就行。
这里获取的分数scores 需要做一个sigmoid,让他映射到0~1,方便后面和阈值比较。
具体c++的sigmoid
inline float fast_exp(float x)
{
union {
uint32_t i;
float f;
} v{};
v.i = (1 << 23) * (1.4426950409 * x + 126.93490512f);
return v.f;
}
inline float sigmoid(float x)
{
return 1.0f / (1.0f + fast_exp(-x));
}步骤二:求出坐标值
1、坐标放大
这里的bbox和kps都需要乘以8 变换为原有的,之前处理特征值做了压缩处理,压缩了8倍
每个坐标值都x8 得到原有特征图的坐标点。
bbox= bbox * 8
kps = kps * 8
2、求出真正的缩放值
bbox,这里的点都是一个偏移值,那么真正的坐标是怎么样的了,这里我们的这里返回特征图是80x80,由于这里的步长都是8,那么每个点就是这样排序下去,具体如下:
| [0,0] | [8,0 | [16,0] | ... | [632, 0] |
| [0,8] | [8,8] | [16,8] | ... | [632, 8] |
| ... | ... | ... | ... | |
| [0,632] | [8,632] | [16,632] | ... | [632,632] |
总共就是80x80的数据格式点
把每个点的坐标减去bbox[0]和bbox[1]得到左上角的(x1,y1)
把每个点的坐标减去bbox[2]和bbox[3]得到右上角的(x2,y2)
这样就得到了整个的bbox的坐标值
kps:其实也是一样,他是kps 5组x和y,分别添加上特征图的坐标点就行了,这里不需要减去
类似:bbox[0] + kps[n],bbox[1] + kps[n+1]
这样就求出kps的五个坐标点
其实应该先求出分数,然后再根据分数是否符合再求出坐标点,这样效率高点,这里为了理解过程就没有考虑效率问题了。
步骤三:分值过滤出
1、根据scores所有的分值进行过滤,过滤出大于等于0.5的阈值,得到一个分值列表
2、根据过滤的列表,把kps和bbox 也过滤下,去掉分值较低的
步骤四:重复上面的步骤
重复上面步骤,依次求出步长16和32的值,然后把结果放到一个列表,按得分份排序,方便后面的NMS计算,最终一个目标对应一个方框。
步骤五:NMS非极大值抑制
1、通过分值得到了不少的坐标点bbox,但是这些框很有可能是有重复的,这里需要用NMS进行过滤
过滤的规则就是通过IOU进行合并,当计算出的IOU大于阈值这里的阈值是默认0.4,那么就合并候选框,当然是把分值低的合并给高的,所以为啥前面要进行排序了。
IOU其实就计算两个框相交的面积
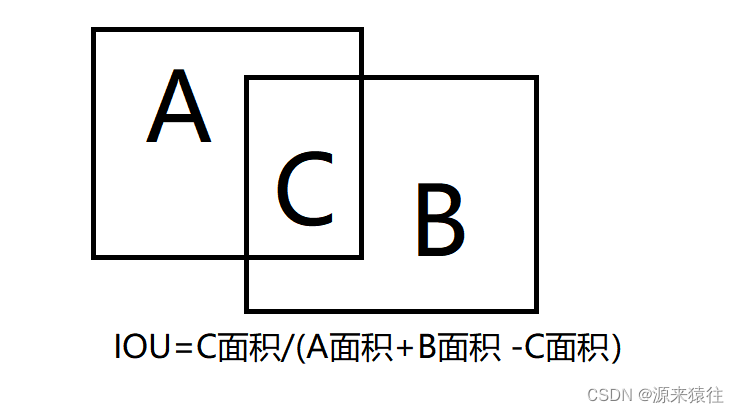
看着复杂,其实计算还是挺简单的,比如
假设:A坐标(x1,y1)(x2,y2) B坐标(x3,y3)(x4,y4)
上面的坐标都是左上角和右下角坐标,几个坐标可以合并成一个矩形框
A的面积:(x2-x1) *(y2-y1)
B的面积:(x4-x3)*(y4-y3)
根据上面可以求出C的宽和高:x4=(Min(x4,x2) - Max( x3,x1)) *( Min(y4,y2)-Max(y3,y1))
当然如果求出C的宽和高小于0,那么说明A和B没有相交不需要合并。
IOU=C面积/(A面积+B面积-C面积)
如果这个IOU大于我们设置的阈值这里是0.4,那么就进行合并选择得分高的
通过轮询把所有的候选框都过滤出来,就得到了最终的候选框。
具体可以查询文章 睿智的目标检测1——IOU的概念与python实例-CSDN博客
过滤坐标计算核心代码
核心部分代码:(这里没有进行转换了,直接采用mat计算,通过分值过滤,最后计算出人脸关键点和bbox边框)这样效率会稍微高点。
记得模型得出来的bbox和特征值,都是一个偏离值,最后需要乘以步长,然后如果需要再原图进行展示的话,还需要对应特征图640x640和原图的比例展示,后面才可以得出原图的坐标
下面是得出特征图的坐标值
//bbox 1x8x80x80 1x8x40x40 kps:1x20x80x80 1x20x40x40 scores:1x2x80x80 1x2x40x40
int FaceDef::generate_proposals(ncnn::Mat& scores_blob, ncnn::Mat& bboxes_blob, ncnn::Mat& kps_blob,
std::vector<ObjectDef>& objects,int stride, float threshold,int num_class) {
const int dot_num = 4;//两组坐标
int w = bboxes_blob.w;
int h = bboxes_blob.h;
int d = bboxes_blob.d;
int channels = bboxes_blob.c;
int dims = bboxes_blob.dims;
if (channels * num_class % dot_num != 0)//通道数不正确,必须为4个坐标
return -100;
if (scores_blob.w != w || scores_blob.h != h)//如果形状不一致,必须形状一直
return -101;
if (kps_blob.w != w || kps_blob.h != h)//如果形状不一致,必须形状一直
return -101;
#pragma omp parallel for num_threads(net.opt.num_threads)
for (int i = 0; i < w; i++)
{
for (int j = 0; j < h; j++)
{
for (int k = 0; k < num_class; k++) {//2组坐标
float* scores = scores_blob.channel(k).row(i);
scores[j] = sigmoid(scores[j]);
if (threshold > 0 && threshold > scores[j]){
scores[j] = 0;//阈值判断
continue;//已经被剔除,此轮无需计算
}
//得分
ObjectDef se_info;
se_info.bbox.label = se_info.mat.c = k % dot_num; se_info.mat.w = i; se_info.mat.h = j;
se_info.bbox.prob = scores[j];
//由于坐标点是(0,0)(8,0),(16,0) ,对应我们for循环的坐标为坐标点为(j * stride,i *stride)
//x
float* arry = bboxes_blob.channel(k * dot_num).row(i);
arry[j] = se_info.bbox.rect.x = (stride * j) - (arry[j] * stride);//得出边框左上角的x
//y
arry = bboxes_blob.channel(k* dot_num +1).row(i);
arry[j] = se_info.bbox.rect.y = (stride * i) - (arry[j] * stride);//得出边框左上角的y
//w
arry = bboxes_blob.channel(k * dot_num +2).row(i);
arry[j] = ((stride * j) + (arry[j] * stride));//得出边框右下角的x
se_info.bbox.rect.width = arry[j] - se_info.bbox.rect.x;
//h
arry = bboxes_blob.channel(k * dot_num + 3).row(i);
arry[j] = ((stride * i) + (arry[j] * stride));//得出边框右下角的y
se_info.bbox.rect.height = arry[j] - se_info.bbox.rect.y;
for (int q = 0; q < 10; q+=2) {//5坐标 人脸关键点
//x1
float* kps_arry = kps_blob.channel(k * 10 + q).row(i);
kps_arry[j] = (stride * j) + (kps_arry[j] * stride);
se_info.kps.points[q / 2].x = kps_arry[j];
//y1
kps_arry = kps_blob.channel(k * 10 + q + 1).row(i);
kps_arry[j] = (stride * i) + (kps_arry[j] * stride);
se_info.kps.points[q / 2].y = kps_arry[j];
}
objects.push_back(se_info);
}
}
}
return 0;
}
其他极大值可以采用其他的我这里是采用的yolo的,得到最终效果如下
运行效果
获取得到了人脸框图和人脸关键点

















 1394
1394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









