






OKIO源码分析
概述
从okio在github上的README我们知道okio主要有四个东西,分别是Sink, Source,Buffer,ByteString。
-Sink:类似java中输出流OutputStream
- Source:类似java中的输入流InputStream
- Buffer:看名字就知道就是一个缓冲区,看到这个Buffer 是不是想起了我们平时写io流时都会创建一个byte[] 作为缓存区,写入时,将这个缓存区的数据写入流,读取时,将流中的数据读入这个缓存区。往下看就会知道Buffer 的内部其实就是byte 数组。
- ByteString:顾名思义,这个类跟byte 和 String 有关。
Sink 和 Source
Sink, Source 都是接口,定义了一些行为,供子类实现。
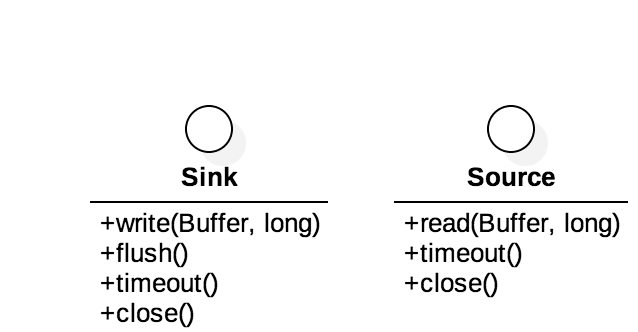
可以看到它们的内部定义了非常简单的方法。也可以看出它们必须配合Buffer 来使用才行。
BufferSink 也是接口,继承了Sink 并提供了更多的write 方法使其能处理byte, short, String 等类型,同理BufferSource 也是接口,继承了Source 并提供了更多的read 方法。
Buffer
接下来就来看看实现了BufferSink和BufferSource 的类RealBufferdSink, RealBufferdSource。这两个类的内部write 方法或者 read 方法的实现都是通过Buffer 类,重头戏来了。
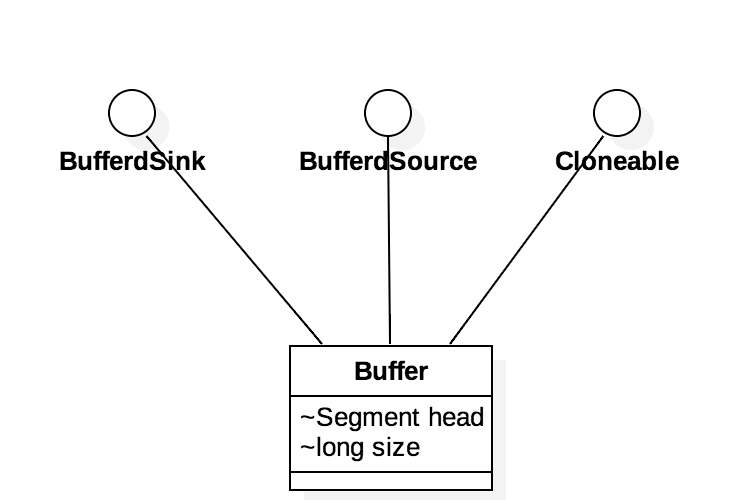
Buffer 类实现了BufferedSource, BufferdSink, Cloneable 接口,具有两个属性long size和 Segment head。long size 表示其内部所存储的数据的长度,它存储的数据其实本质上就是byte[]。Segment 内部有一个大小为2048的byte[] 保存着Buffer 需要存储的数据。
那Buffer 只能存储2048byte 么? 当然不是,Segment 的实现方式是一个循环双线链表,当一个Segment 存满了,往链尾添加一个新的Segment 就又可以存储更多的数据了。
那为什么不直接在Buffer 中写一个byte[] 来保存数据,还要弄一个什么循环链表Segment 来存储数据呢?答案就在数据的转移。当一个Source 要读取一个Sink 中的数据时,其实就是把数据从Source 的Buffer 转移到Sink 的Buffer 中。此时如果Buffer 中是用byte[] 实现的,那么我们势必需要进行byte 数组拷贝的工作,但是用一个链表实现的情况下,我们可以直接把Sink 中的 Segment 节点的指针指到Source 中的Segment 链表尾就OK了,而不用进行数组拷贝,更高效。
Segment
上面收到Segment 是链表的实现方式, 分析该类就从Buffer 的方法wite(byte[] source, int offset, int byteCount) 开始吧。
@Override public Buffer write(byte[] source, int offset, int byteCount) {
if (source == null) throw new IllegalArgumentException("source == null");
checkOffsetAndCount(source.length, offset, byteCount);
int limit = offset + byteCount;
while (offset < limit) {
Segment tail = writableSegment(1);
int toCopy = Math.min(limit - offset, Segment.SIZE - tail.limit);
System.arraycopy(source, offset, tail.data, tail.limit, toCopy);
offset += toCopy;
tail.limit += toCopy;
}
size += byteCount;
return this;
}checkOffsetAndCount 方法就是检查下参数对不对。检查完下面有个while 循环将数据拷贝到Segment中,那该Segment 是怎么来的呢,我们看下writableSegment(int minmumCapacity) 方法。
Segment writableSegment(int minimumCapacity) {
if (minimumCapacity < 1 || minimumCapacity > Segment.SIZE) throw new IllegalArgumentException();
if (head == null) {
head = SegmentPool.take(); // Acquire a first segment.
return head.next = head.prev = head;
}
Segment tail = head.prev;
if (tail.limit + minimumCapacity > Segment.SIZE || !tail.owner) {
tail = tail.push(SegmentPool.take()); // Append a new empty segment to fill up.
}
return tail;
}该方法根据你提供的容量返回一个能存的下你声明的容量的Segment 当作容器供你使用。当Buffer 的内部没有存储数据时,它会调用SegmentPool.take() 方法获取到一个Segment ,SegmentPool 是一个Segment 的缓存池, 最多可以缓存64 * 1024KiB也就是32个Segment 。这种缓冲方式跟Message 很像。Buffer 的内部有存储数据时会先查看链尾节点的存储空间符不符合你的要求,符合就返回,不符合就调用Segment.push(Segment segment) 方法添加一个新的节点在末尾供你存储数据。 拿到Segment 容器后,就可以拷贝数据了,如此反复直到数据都写入到Buffer 中。
ForwardingSink、 ForwardingSource
这两个类网络上有人说它们是装饰着 但是我觉得它们更像是代理,用法就是继承它们,然后override它们的方法。
GzipSink、 GzipSource、 DeflaterSink、 InflaterSource
GzipSink和GzipSource 实现了gzip 压缩,解压缩。其实就是弄个头,体,尾。头跟尾详情见GZIP。 体的话是调用DeflaterSink跟InflaterSource 实现的。而这两个类的内部又是调用java的API Deflater和Inflater 类实现压缩和解压的。关于这两个类的使用方式,不必google了。直接看这两个的头部注释就够了,在这里我也贴出来吧。
Inflater用法
byte[] compressedBytes = ...
int decompressedByteCount = ... // From your format's metadata.
Inflater inflater = new Inflater();
inflater.setInput(compressedBytes, 0, compressedBytes.length);
byte[] decompressedBytes = new byte[decompressedByteCount];
if (inflater.inflate(decompressedBytes) != decompressedByteCount) {
throw new AssertionError();
}
inflater.end();
Deflater用法
byte[] originalBytes = ...
Deflater deflater = new Deflater();
deflater.setInput(originalBytes);
deflater.finish();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buf = new byte[8192];
while (!deflater.finished()) {
int byteCount = deflater.deflate(buf);
baos.write(buf, 0, byteCount);
}
deflater.end();
byte[] compressedBytes = baos.toByteArray();
ByteString
说了半天还没有说ByteString 呢,看到这个名字就知道跟Byte 和String 有关。内部有一个byte[] 用来保存数据, 主要的作用就是将字符串转成byte[] 保存起来,并提供将byte[] 转成字符串的方法,也提供了一些将字符串加密编码的方法。
Okio
最后说下最常用的大Boss, Okio 类。我们使用Okio库都要用到这个类,该类是一个大工厂, 为我们创建出各种各样的Sink、Source 对象。提供了三种数据源InputStream/OutputStream、Socket、File, 我们可以把本应该对这三类数据源的IO操作通过Okio库来实现,更方便,更高效。
说到这里也就差不多了,还有不明白的,还是去看下源码,也不多,也不难!















 989
989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









