







【0】README
0.1) 本文描述转自 core java volume 2, 旨在理解 java流与文件——对象流和序列化 的相关知识;
0.2) for source code , please visit https://github.com/pacosonTang/core-java-volume/blob/master/coreJavaAdvanced/chapter1/ObjectStreamTest.java and https://github.com/pacosonTang/core-java-volume/blob/master/coreJavaAdvanced/chapter1/SerialCloneTest.java
【1】对象流和序列化
1.1)problem + solution
- 1.1.1)problem: 当你需要存储相同类型的数据时, 使用固定长度的记录格式是一个不错的选择。在面向对象程序中创建的对象很少全部都具有相同的类型; (如父类指针指向子类对象)
- 1.1.2)solution : Java的 对象序列化(Object serialization)是非常通用的机制; 它可以将对象写出到流中, 并在之后将其读回;
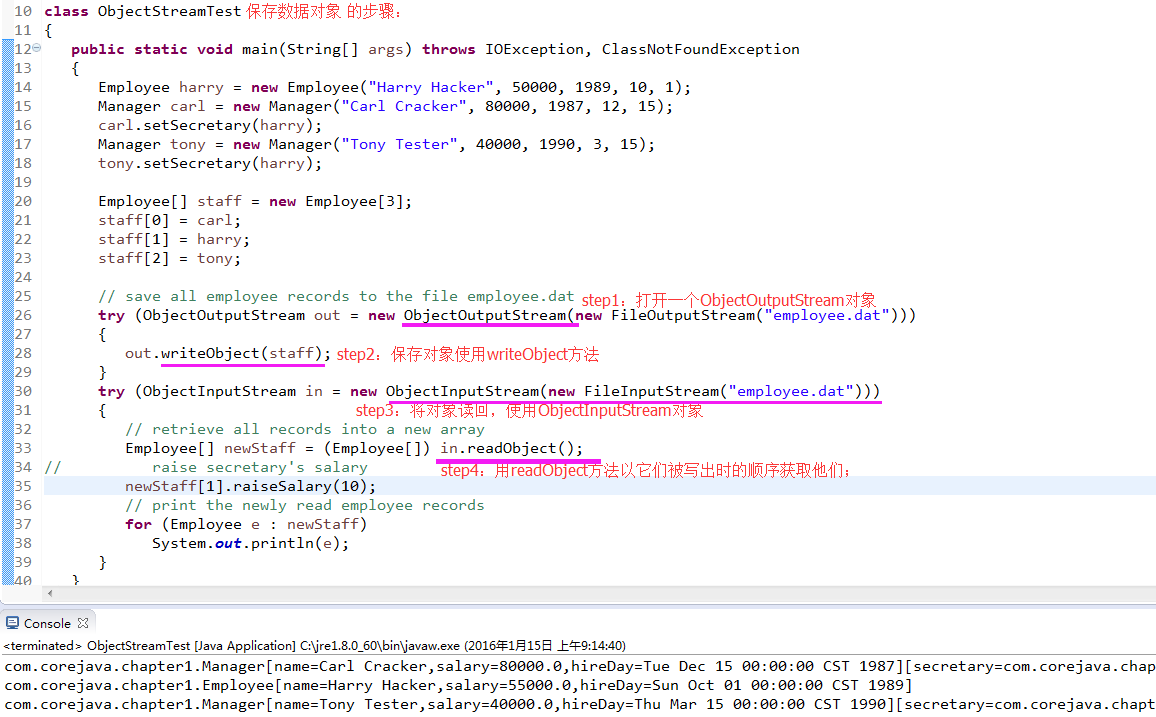
1.2)保存数据对象 的步骤:
- step1)打开一个 ObjectOutputStream 对象:
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(“employee.dat”)); - step2)为保存对象,直接使用 ObjectOutputStream 的 writeObject方法;
Employee harry = new Employee("Harry Hacker", 50000, 1989, 10, 1);
Manager carl = new Manager("Carl Cracker", 80000, 1987, 12, 15);
oos.writeObject(harry);
oos.writeObject(carl);- step3)为将对象读回,需要获得一个 ObjectInputStream 对象:
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(“employee.dat”)); - step4) 用readObject方法以这些对象被写出时的顺序获取他们:
Employee e1 = (Employee)ois.readObject();
- 1.2.1)但是,对希望在对象流中存储或恢复的所有类都应该进行一次修改, 这些类必须实现 Serializable 接口:
Attention)
- A1) Serializable 接口 没有任何方法, 你不需要做任何改动, 这一点和 Cloneable 接口很相似;
- A2)你只有在写出对象时 才能用 writeObject/readObject 方法; 对于基本类型,使用writeInt/readInt 或writeDouble/readDouble 这样的方法(对象流类都实现了 DataInput/DataOutput 接口)
- A3)在后台,是ObjectOutputStream 在浏览对象的所有域, 并存储它们的内容;
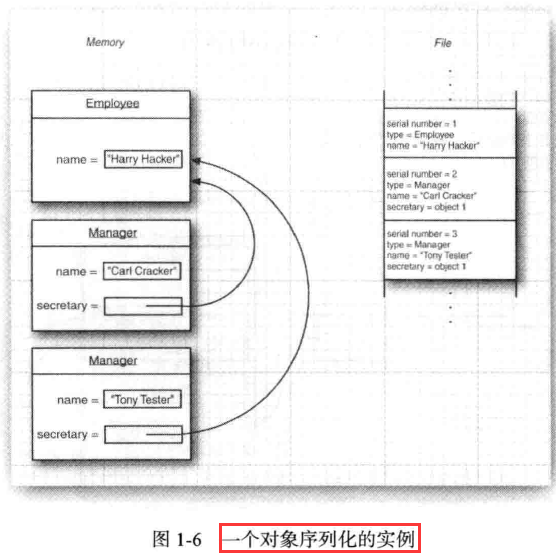
1.3)有一种case 需要考虑: 当一个对象被多个对象共享时, 作为它们各自状态的一部分,会发生什么呢?(如两个经理共用一个秘书harry, 上面的源代码就是这种 case )
Employee harry = new Employee("Harry Hacker", 50000, 1989, 10, 1);
Manager carl = new Manager("Carl Cracker", 80000, 1987, 12, 15);
carl.setSecretary(harry);
Manager tony = new Manager("Tony Tester", 40000, 1990, 3, 15);
tony.setSecretary(harry);1.3.1)solution: 每个对象都是用一个序列号保存的, 这就是这种机制称为对象序列化的原因。 下面是其算法(Alg):
A1)对你遇到的每一个对象引用都关联一个序列号;
- A2)对于每个对象, 当第一个遇到时,保存其对象数据到流中;
- A3)如果某个对象之前已经被保存过, 那么只写出“与之前保存过的序列号为x的对象相同”, 在读回对象时,过程是相反的;
- A4) 对于流中的对象,在第一次遇到其序列号时, 构建它, 并使用流中数据来初始化它, 然后记录这个顺序号和新对象之间的关系;
A5) 当遇到 “与之前保存过的序列号为x的对象相同”标记时, 获取与这个顺序号相关联的对象引用;
Attention)序列化的另一种重要应用是: 通过网络将对象集合传送到另一台计算机上。 正如文件中保存原生的内存地址毫无意义一样, 这些地址对于在不同处理器之间的通信也毫无意义的。因为序列化用序列号代替了内存地址, 所以它允许将对象集合从一台机器传送到另一台机器;(干货——序列化应用于代替内存地址来表示对象集合 便于对象集合在网络间的传输)
【2】理解对象序列化的文件格式
2.1)当存储一个对象时,这个对象所属的类也必须存储。这个类的描述(Descriptions)包含:
- D1)类名;
- D2)序列化的版本唯一的ID, 它是数据域类型和方法签名的指纹;
- D3)描述序列化方法的标志集;
- D4)对数据域的描述;
(干货——序列化版本ID 就是 指纹, 而指纹是包含于对象描述内容中的)
2.2)指纹: 是通过对类、超类、接口、域类型和方法签名按照规范方式排序的, 然后将安全散列算法(SHA) 应用于这些数据而获得的;(干货——指纹定义)
- 2.2.1)指纹比对: 在读入一个对象时, 会拿其指纹与它所属的类的当前指纹进行比对, 如果不匹配, 那么就说明这个类的定义在该对象被写出之后发生过变化, 因此会产生一个异常;
(干货——指纹比对) - 2.2.2)类标识符是如何存储的? (干货——类标识符是如何存储的,了解而已)
72
2 字节的类名长度
类名
8字节长的指纹
1字节长的标志
2字节长的数据域描述符的数量
数据域描述符
78(结束标记)
超类类型(如果没有就是70)
标志字节是由在 java.io.ObjectStreamConstants 中定义的3位掩码构成的;- 2.2.3)每个数据域描述符的格式如下: (干货——每个数据域描述符的格式)
1 字节长的类型编码
2 字节长的域名长度
域名
类名(如果域是对象)
其中类型编码是下列取值之一:
B byte
C char
D double
F float
I int
J long
L 对象
S short
Z boolean
[ 数组Attention)你应该记住: (干货——需要记住的对象流的key point)
- A1)对象流输出中包含所有对象的类型和数据域;
- A2)每个对象都被赋予一个序列号;
- A3) 相同对象的重复出现将被存储为对这个对象的序列号的引用;
【3】修改默认的序列化机制
3.1)problem+solution (干货——某些数据域及其所属类是不可以序列化的)
- 3.1.1)problem:某些数据域是不可以序列化的, 如, 只对本地方法有意义的存储文件句柄或窗口句柄的整数值; 这种域的值如果不恰当,还会引起本地方法崩溃;
- 3.1.2)solution: java 将他们标记为 transient;如果这些域属于不可序列化的类, 那么类也需要标记为 transient; (干货——transient关键字的意义, transient==瞬变现象,过往旅客,候鸟;短暂的,路过的)
3.2)序列化机制为单个类提供了一种方式,去向默认的读写行为添加验证或任何其他想要的行为, 可序列化的类可以定义具有下列签名的方法:readObject 和 writeObject;
- 3.2.1)之后数据域就再也不会被自动序列化了, 取而代之的是调用这些方法;
- 3.2.2)除了让序列化及直接来保存和恢复对象数据, 类还可以定义它自己的机制。为了做到这一点,必须要实现 Externalizeble 接口, 这需要它定义两个方法:readExternal 和 writeExternal 方法;
Warning)
- W1) readObject 和 writeObject是私有的, 并且只能被序列化机制调用;
- W2)与此不同的是, readExternal 和 writeExternal 方法是公共的, 特别地, readExternal 还潜在地允许修改现有对象的状态;
【4】序列化单例和类型安全的枚举
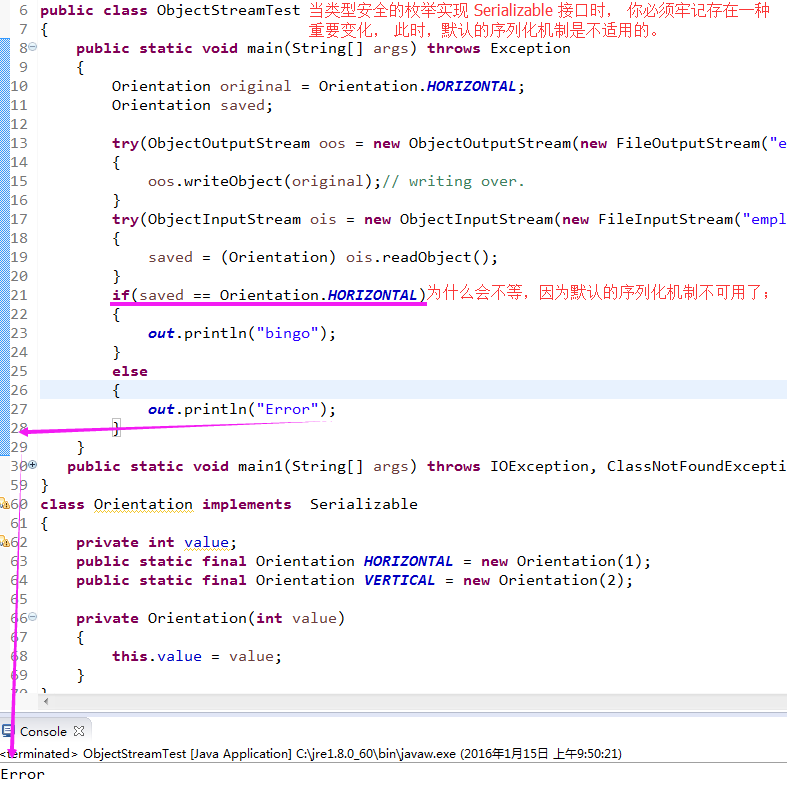
4.1) 当类型安全的枚举实现 Serializable 接口时, 你必须牢记存在一种重要变化, 此时,默认的序列化机制是不适用的。 假设我们写出一个 Orientation 类型的值, 并将其再次读回:
Orientation original = Orientation.HORIZONTAL;
ObjectOutputStream oos = ..;
oos.write(original);
oos.close();
ObjectInputStream ois = ...;
Orientation saved = (Orientation) ois.read();4.2)problem: 下面的测试 if(saved === Orientation.HORIZONTAL) 将失败;
4.3)solution:为解决这个问题,必须定义一种称为 readResolve 的特殊序列化方法。 如果定义了 readResolve 方法, 在对象被序列化后就会调用它。 它必须返回这个对象, 而该对象之后会成为 readObject 的返回值;
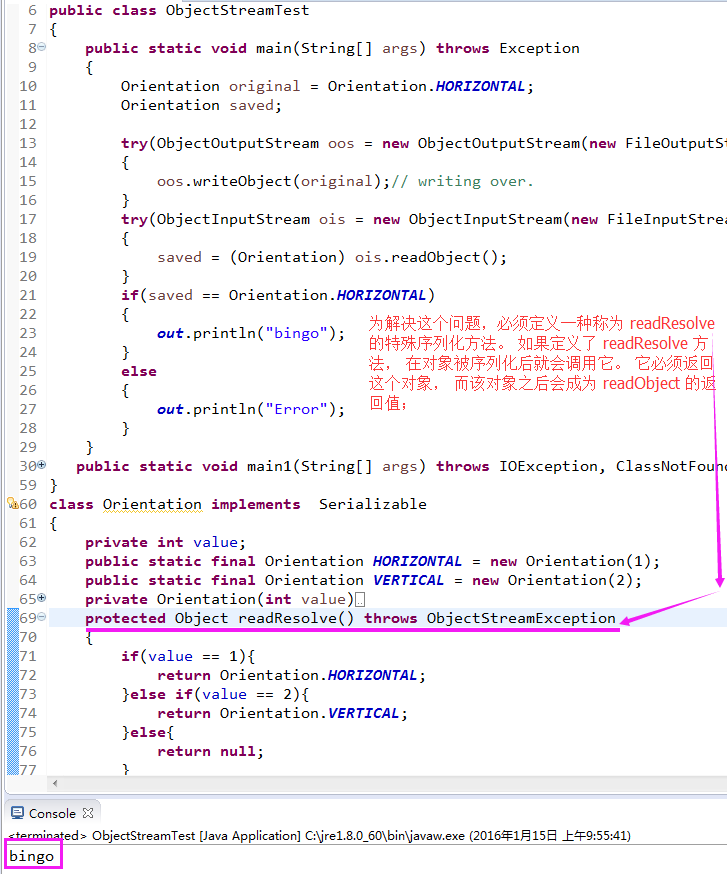
Attention)向遗留代码中所有类型安全的枚举以及向所有支持单例设计模式的类中添加readResolve 方法; (干货——添加readResolve方法的条件)
【5】版本管理 (干货——存储在磁盘上version1的对象与内存中version2的对象的输入输出问题)
5.1)如果使用序列化来保存对象,就要考虑在程序演化时会有什么问题?
5.2)无论类的定义产生什么样的变化,它的SHA指纹也会跟着变化, 而我们都知道对象流将拒绝读入具有不同指纹的对象。但是类可以表明它对其早期版本保持兼容, 要想这样做, 就必须先获得这个类的早期版本的指纹。
- 5.2.1)我们可以使用JDK中的单机程序 serialver 来获得这个数字, 如:serialver Employee 会打印出

- 5.2.2)如果一个类具有名为 serialVersionUID 的静态数据成员, 它就不需要再人工地计算其指纹了,而只需要直接使用这个值;
- 5.2.3)一旦该静态成员( serialVersionUID) 被设置在某个类的内部, 那么序列化系统就可以读入这个类的对象的不同版本;
5.3)如果这个类只有方法产生了变化,那么在读入新对象数据时是不会有任何问题的。但是, 如果数据域发生了变化, 那么就有可能有问题了;
5.4)对象流会将这个类当期版本的数据域和流中版本的数据域进行比较;
- 5.4.1)如果这两部分数据域之间名字匹配而类型不匹配, 那么对象流不会尝试将一种类型转换为另一种类型, 因为这两个对象不兼容;
- 5.4.2)如果流中的对象具有在当前版本中所没有的数据域, 那么对象流会忽略这些额外的数据;
- 5.4.3)如果当期版本具有在流化对象中所没有的数据域,那么这些新添加的域将被设置为它们的默认值(对象设置为null, 数组设置为0, 而boolean 设置为false)
5.5)看个荔枝:
- 5.5.1)假设我们已经用雇员类的1.0version 在磁盘上保存了大量的雇员记录, 现在我们在 Employee 上添加了 department的数据域,从而将其演化到 version2.0;
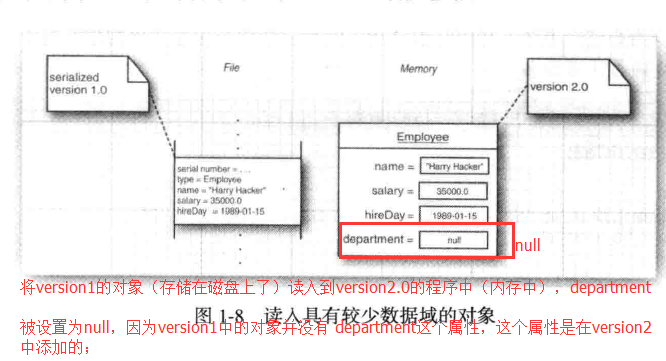
- 5.5.2)将version2的磁盘对象读入到version1的程序中(内存中),直接将department 数据域忽略掉;因为version1 中的类描述内容没有关于department的描述;
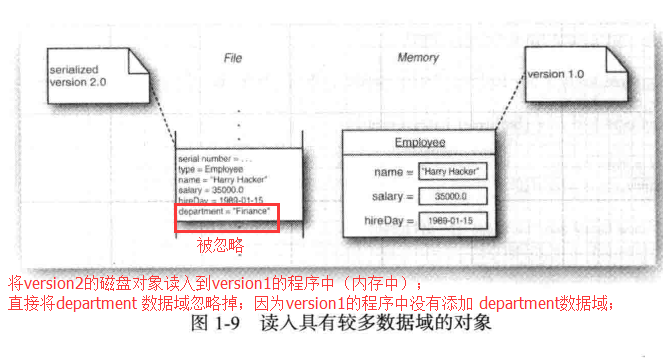
5.5.3)以上的忽略和置空真的安全吗? 视情况而定;
5.5.3.1)丢掉数据域看起来是无害的, 因为接收者仍然可以拥有它知道如何处理的所有数据, 但是将数据域设置为null, 却可能并不那么安全了;
- 5.5.3.2) 这个问题取决于类的设计者是否能够在 readObject方法中实现额外的代码区订正版本不兼容问题, 或者是否能够确保所有的方法在处理null 数据时都足够健壮;
【6】为克隆使用序列化
6.1)序列化是一种很有用 的用法: 提供了一种克隆对象的简便途径, 只要对应的类是可序列化的即可;
6.2)做法很简单:直接将对象序列化到输入流中, 然后将其读回。
- 6.2.1)这样产生的新对象是对现有对象 的一个深拷贝。
- 6.2.2)在这个过程中, 我们不必将对象写出到文件中, 因为可以用 ByteArrayOutputStream 将数据保存到字节数组中;
6.3)看个荔枝: 要想得到 clone 方法, 只需要扩展 SerialCloneable 类就可以了; (干货——为克隆使用序列化,需要实现SerialCloneable )
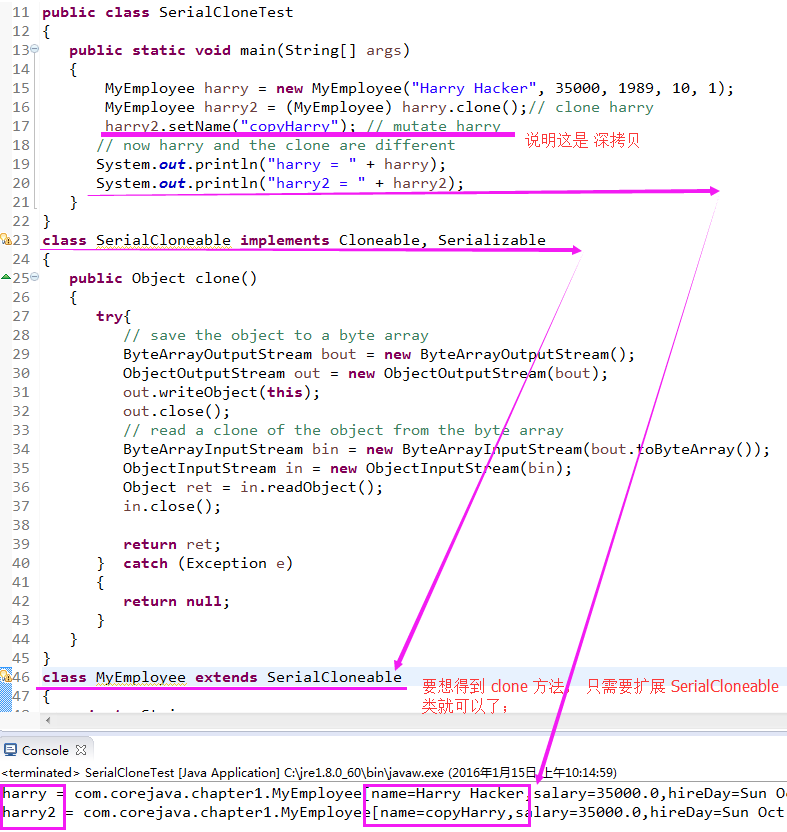














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









