







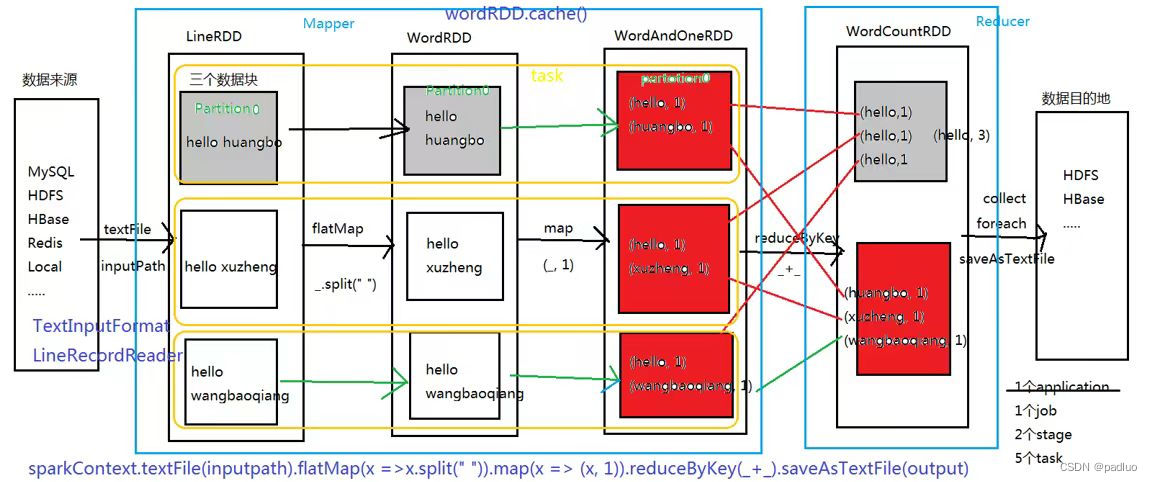
这里有一张 Spark 的 WordCount 的执行流程图,我们来看一下这张图当中给我们展示出来的四个概念, application 、 job 、 stage 、task 。
首先,我们初始化了一个 SparkContext ,通过 textFile 这个函数读 HDFS 中的数据,得到一个 LineRDD ,用 textFile 相当于是用普通的默认一行一行读取的方式,所以这个 RDD 里面的数据是一行一行的。
LineRDD 分成了三个分区,分别为 partition0 、 partition1 、 partition2 , partition0 里面装的是一行一行的字符串,接下来执行 flatMap 操作把里面的一行一行变成一个一个的单词,执行完 flatMap 操作之后, LineRDD 的 partition0 变成了 WordRDD 的 partition0 ,同理, LineRDD 的 partition1 变成了 WordRDD 的 partition1 , LineRDD 的 partition2 变成了 WordRDD 的 partition2 ,这两个 RDD 之间的关系是一种一对一的关系, LineRDD 的 Partition 跟 WordRDD 的 Partition 之间的运算没有 shuffle 的关系, WordRDD 中的每一个分区都只依赖于上一个 RDD 的某一个分区,三个分区依然跟上一个 RDD 中的三个分区是一对一的关系。
WordRDD 执行 map 操作之后,把一个一个的单词变成一个一个的单词对,每一个分区里面的逻辑,也没有进行 shuffle 操作,所以 WordRDD 跟 WordAndOneRDD 也是一一对应的。
如果我们最终要统计每个单词出现多少次,我们必须要去做一个 shuffle ,把所有的 hello 拉到一起,同理,其他单词也拉到一起,只要是相同的单词对,我们最终都需要把他拉到一个任务里面去执行汇总,所以,我们中间执行一个 reduceByKey 的操作,就是先执行 shuffle ,再执行 reduce 操作,图上的红色块,跟 MapReduce 中的 map 很像, WordAndOneRDD 最终输出的结果,跟 MapReduce 编程模型中 map 阶段输出的结果类似。在 Spark 当中, LineRdd 、 WordRDD 、 WordAndOneRDD 这些东西我可以认为不存在,因为在 MapReduce 中的 map 阶段,我们读了一行,直接把它变成单词对输出,而在 Spark 当中, 有 LineRdd 、 WordRDD 、 WordAndOneRDD ,我们可以认为这三个 RDD 当中的运算可以放在同一个地方来运行,我们可以认为它是 MapReduce 的 map 阶段,图上的蓝色框,标了一个 map 阶段,相当于我们这里事实上是由一个 LineRDD 、 WordRDD 、WordAndOneRDD 最终组成了一个 stage ,这个 stage 的内部没有 shuffle ,上一个 RDD 跟下一个 RDD 当中的多个分区之间,是一对一的关系,所以,我们可以把三个 RDD 放在一起,变成一个 stage 。为什么把他们变成一个 stage 呢?在 Mapreduce 编程模型中,我们可以认为 map 阶段是第一个阶段, reduce 阶段是第二个阶段,第一个阶段、第二个阶段之间要执行 shuffle 操作,同理,在 Spark 应用程序中,或者说在所有的分布式计算应用程序当中,必然都会有 shuffle 这个操作,所以,我们把多个 RDD 放在一起,如果说没有 shuffle 操作,我们把它放在一起就变成一个 stage ,如果中间有 shuffle ,我们就把它切分,前面是上一个 stage ,后面是下一个 stage 。所以 Spark 当中的应用程序在运行的时候,会把一个应用程序切割成多个 stage ,每个 stage 就类似于 Mapreduce 编程模型当中的 map 阶段或者 reduce 阶段,多个 stage 之间会有 shuffle 操作,切分 stage 标准就是看有没有 shuffle 依赖。以 WordCount 的执行流程图为例,这里面有 textFile 、 flatMap 、 map 、 reduceByKey 。其中, flatMap 、 map 都不是 shuffle 的,而 reduceByKey 是 shuffle 算子,我们就会在执行的过程当中从这儿给它切开,前面是上一个 stage ,后面是下一个 stage 。
那图上一共有多少个 task 呢?我们看 stage1 这里,按直观的理解,这里有 textFile 、 flatMap 、 map ,有三个分区,是不是执行了 9 个 task ?错的。 LineRDD 的 partition0 这个分区执行 flatMap 操作,变成 WordRDD 中的 partition0 , WordRDD 中的 partition0 ,通过 map 操作,变成 WordAndOneRDD 中的 partition0 ,这三个 RDD 的 partition0 分区的数据一定放在不同的节点里面吗?也就是说,LineRDD 中的 partition0 执行完运算,把数据 shuffle 给另外一个节点,再执行 map 操作后, shuffle 到另一个节点,有没有这个必要?这里有个概念叫做 pipeline ,叫做流水线处理,WordRDD 的 partition0 计算只依赖于 LineRDD 的 partition0 , 不依赖 partition1 和 partition2 ,我们可以直接在一个 task 里面把 LineRDD 的 partition0 变成 WordRDD 的 partition0 , 再变成 WordAndOneRDD 的 partition0 ,这三个分区之间的关系是严格的一对一的关系,没有必要把 WordRDD 和 WordAndOneRDD 中的 partition0 给弄到另外一个节点,把这三个 partition0 分区放在同一个 task 结束就完了,这样做效率高一些。真实的情况是这个 WordRDD 当中数据压根都没有,为什么呢?因为 partition0 当中的 hello huangbo 变成了 hello 之后,马上就变成了 (hello, 1) ,在没有必要非得去看一下 WordRDD 当中分区的数据的时候,这个分区当中的数据压根就没有,也就相当于我们最终任务在运行的时候,这个一行直接一眨眼的功夫就变成了单词对了。当然中间会有一个逻辑过程,这个逻辑过程就是说我们一句话先变成多个单词,这就是做了 flatMap ,每个单词通过 map 操作再变成单词对,这个逻辑上的操作,是由 LineRDD 转成 WordRDD 再转成 WordAndOneRDD ,真实情况当中,没有必要非得把他们放在三个不同的节点,他们可以在同一个节点执行。这样做就相当于我们一行数据直接一溜烟就变成了单词对,那中间的这个 RDD 数据压根没必要存在,相当于我们中间有一个转化过程,这个转化过程是包含这个数据,但是,在不拿的情况当中,就没有物理存储的概念,相当于并不是真实存在,是存在于我们的脑海里面,存在于我们的抽象里面。既然这样的话,这三个分区之间的转换关系,最终就形成了一个 task ,stage1 有三个分区,就有三个 task。Mapreduce 编程模型当中的 map 阶段,是有多少个数据块就有多少个分区,也是这么来的, stage1 搞定。
stage2 呢,根据需求来定,有可能你会把它弄成两个,或者弄成四个,或者弄成六个都有可能,如图,它弄成了两个分区,所以最终就执行了两个 task 。这两个 task 执行完了之后,最终的结果就可以输出到 HDFS 了。
整个这张图,讲的是一个 application ,这一个 application ,分成了两个 stage。当然还有一个前提,就是我们最终要执行一个 action 算子,可能是 collect 、 foreach 或者 saveAsTextFile ,也就是说最终的结果拿到了, reduce 阶段已经得到的结果,最终我们需要把它落地,放在 HDFS ,或者到标准输出,这就是一个 action 算子,触发前面一系列的 transformation 算子的真正执行,前面的 transformation 算子都在由一个 RDD 变成另外的 RDD 。这个 WordCount 应用程序中只有一个 action 算子,就只有一个 job 。
我们整个流程描述的是一个 WordCount 的计算任务,这个逻辑概念,是一个宏观概念上的一个任务,我们就把它叫做一个应用程序,叫做 application ,这个 application 的内部,有几个 action 算子,就有几个 job ,每个 job 都是独立运行的,每个 job 当中又会根据是否有 shuffle 操作,然后分成多个 stage ,如果有一个 shuffle 操作就会生成两个阶段,如果有四个 shuffle 过程,就会分成五个阶段,当前 WordCount 这个程序当中,只有 reduceByKey 是 shuffle 操作,所以我们最终就会生成两个 stage 。那么生成了几个 task 呢?我们第一个 stage 有三个 task ,第二个 stage 有两个 task ,所以有五个 task 。
所以,一个 application 会有一到多个 job ,一个 job 会有一到多个 stage ,每个 stage 又会有一到多个 task ,这个 task 执行在哪里呢?会有一个资源管理系统,资源管理系统主节点叫 cluster manager ,从节点叫 worker , worker 是真正干活的,worker 中会去启动 JVM 进程,叫做 executor ,那么 executor 中会有线程,这个线程可能会有很多,每个线程会去运行一个一个 task ,所以,我们最终一个应用程序,那么多的 task 都是在 worker 节点当中的 executor 进程里面的线程当中去执行的。另外,这个 driver 程序到底在哪里运行,决定了我们用的模式是哪个,或者说我们提交任务的时候使用的是哪种模式,就决定了 driver 运行在哪个节点。那如果说是 client 模式,那就表示 driver 程序运行在客户端,那如果是 cluster 模式,那就表示 driver 程序运行在 worker 节点当中。
微信公众号「padluo」,分享数据科学家的自我修养,既然遇见,不如一起成长。关注【数据分析】公众号,后台回复【文章】,获得整理好的【数据分析】文章全集。
















 2776
2776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









