







该方法是对文献【6】的改进。域自适应技术处理域迁移问题通过对抗训练对齐特征。之前的工作实现的全局特征对齐,没有考虑到目标的位置。为什么考虑目标的位置?作者通过城市场景中数据特点举例子,城市场景中目标与他们的空间位置高度相关,天空往往会出现在图像的顶部,汽车通常出现在图像的中部。作者根据这个观点,提出空间感知判别器,用于理解目标的空间先验,1以提高特征对齐。
作者使用【16】的方法风格化源域图像,目的让其看来与目标域图像更为相似。风格化的源域图像和目标域域图像作为分割网络的训练数据。然后,作者使用两个对抗模型训练分割网络。第一个模块是,全局域适应模块(global adaptation module),查看风格化的源域图像和目标域图像预测的语义标签,然后对齐特征,以便让他们彼此更为相似。第二个模块是,空间感知适应模块(spatial aware adaptation module),在源域到目标域的适应过程中,整合前景类的空间先验。

2.1 风格转换(Style Transfer)
作者使用FastPhotoStyle风格化源域图像,随机选取目标图像作为参考风格图像(reference style image)。为什么要选择FastPhotoStyle? 因为FastPhotoStyle在执行风格转换之后,不会扭曲图像并保持空间一致性(distort the images and preserves spatial coherency),这样转换后的风格图像仍可以使用源域图像的标签,没有任何修改。
2.2 域自适应模块(Domain Adaptation Module)
域自适应模块由两个部分组成,一个是分割网络G,一个判别器D。判别器D 尝试一个图像的预测语义标签属于源域还是目标域?
使用文献【17】的hinge loss 来训练判别器D,如等式1所示。 为什么使用hinge loss? 因为对于对抗训练(adversarial training)hinge loss 比标准的交叉熵更稳定。等式2,定义了分割网络的对抗损失函数。
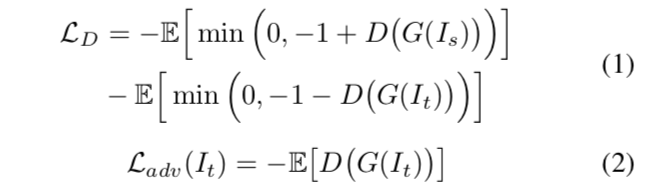
2.3 空间感知适应模块(Spatial Aware Adaptation Module)
每个类的先验空间概率:。作者使用训练集中目标位置的标准化频率计数来计算
。具体的计算方式还需要结合代码。然后,作者使用
对输入图像的分割结果
进行加权,得到
,如等式3所示。
![]()
等式3中为什么需要加1?因为仅仅是训练集的近似,在物体很可能出现的地方概率为0。为了避免忽视这些位置,作者添加了一个常量值1到
中。作者仅仅计算前景物体的空间先验。
作者将空间信息整合为条件信息,使用文献【21】所提出来的投影公式。空间适应模块的结构示意图,如图3所示。

该判别器的损失函数,也是hinge loss。如等式4,5所示。该判别器的结构与文献【21】中的判别器结构类似,但是作者使用带specal normalizaiton 的卷积取代了文献【21】中的残差链接。

类似整合空间先验信息的方法,如文献:【30】,【31】
参考文献:
[6] Y.H.Tsai,W.C.Hung,S.Schulter,K.Sohn,M.H.Yang, and M. Chandraker, “Learning to adapt structured out- put space for semantic segmentation,” in IEEE Conf. on Computer Vision and Pattern Recognition, June 2018.
[16] Y. Li, M.Y. Liu, X. Li, M.H. Yang, and J. Kautz, “A closed-form solution to photorealistic image stylization,” in European Conference on Computer Vision, September 2018.
[17] H. Zhang, I. Goodfellow, D. Metaxas, and A. Odena, “Self-attention generative adversarial networks,” arXiv preprint arXiv:1805.08318, 2018.
[21] T. Miyato and M. Koyama, “cgans with projection discriminator,” arXiv preprint arXiv:1802.05637, 2018
[22] T. Miyato, T. Kataoka, M. Koyama, and Y. Yoshida, “Spectral normalization for generative adversarial networks,” arXiv preprint arXiv:1802.05957, 2018.
【30】Silberman, N., Fergus, R.: Indoor scene segmentation using a structured light sen- sor. In: Computer Vision Workshops (ICCV Workshops), 2011 IEEE International Conference on. pp. 601–608. IEEE (2011) 10
【31】2018_ECCV_Unsupervised Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training















 1732
1732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









