







 本文探讨了在使用PyTorch训练模型时遇到的RuntimeError:expected scalar type Double but found Float。问题源于数据类型不匹配,即输入np.array与模型权重torch.Tensor的类型冲突。通过分析Dataset和DataLoader的数据转换,发现DataLoader将numpy.array转为了torch.float64。为避免此类问题,建议在使用这些工具前,确保数据提前转化为torch.Tensor格式。
本文探讨了在使用PyTorch训练模型时遇到的RuntimeError:expected scalar type Double but found Float。问题源于数据类型不匹配,即输入np.array与模型权重torch.Tensor的类型冲突。通过分析Dataset和DataLoader的数据转换,发现DataLoader将numpy.array转为了torch.float64。为避免此类问题,建议在使用这些工具前,确保数据提前转化为torch.Tensor格式。
RuntimeError: expected scalar type Double but found Float
在使用torch训练模型的时候,发现该问题。根据提示,是双精度和float之间的冲突。原因在于我使用Dataset和DataLoader套餐的时候,输入的数据是np.array而非是torch.Tensor.具体研究过程请看下面娓娓道来。
- 报错语句的位置为
lhs = torch.matmul(torch.matmul(x.permute(0, 3, 2, 1), self.U1),
self.U2)
一共有三个变量:x, self.U1, self.U2。分别查看其数据类型
x1=x.permute(0, 3, 2, 1)
print(x1.dtype) # torch.float64
print(self.U1.dtype) #torch.float32
print(self.U2.dtype) #torch.float32
可以看到是输入数据(x)与模型权重(self.U1,self.U2)的数据类型之间的冲突。
Q1:模型权重参数的设置的结果?
- 在
def __init__中找到模型参数的设置
self.U1 = nn.Parameter(torch.FloatTensor(num_of_vertices).to(DEVICE)) # 307个顶点(传感器)
self.U2 = nn.Parameter(torch.FloatTensor(num_of_features, num_of_vertices).to(DEVICE)) # (1, 307)thon
torch中默认生成的tensor数据为float32,如下图所示。默认使用单精度float32训练模型,原因在于:使用float16训练模型,模型效果会有损失,而使用double(float64)会有2倍的内存压力,且不会带来太多的精度提升。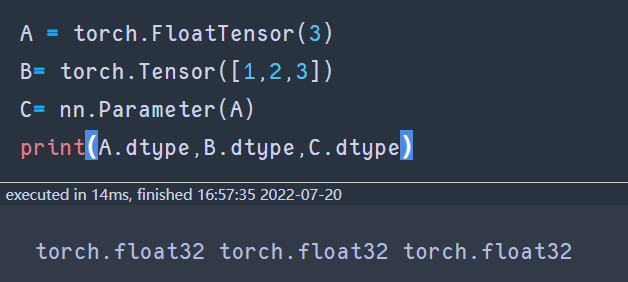
Q2: x是如何变为torch.float64的呢?
猜测一:numpy–>Tensor?结果证明不是
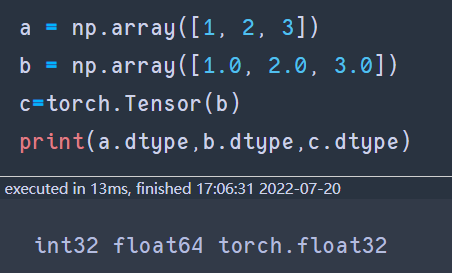
- 输入数据由numpy.array转化而来,当为float的时候默认为float64.转化为Tensor的时候是torch.float32.
猜测二: 经历了Dataset和DataLoader
- 输入数据的产生过程
## 1. 生成了numpy.array的字典
data_seq = gen_seq_data(data,num_of_weeks=2,num_of_days=2,num_of_hours=2,num_time_output=12, num_time_input_unit=12)
# data_seq["week"]:array,shape is (12948, 307, 3, 24)
# data_seq['day']:array,shape is (12948, 307, 3, 24)
# data_seq['hour']:array,shape is (12948, 307, 3, 24)
# data_seq['target']:array,shape is (12948, 12, 307)
## 2. 生成Dataset数据结构
dataset = dataset_astgcn(data_seq) # dataset_astgcn是自定义的Dataset的子类
## 3. 生成batch的迭代器
loader = DataLoader(dataset, batch_size=50, shuffle=True)#DataLoader是torch自带的
- 查看
Dataset数据的类型: 依旧保持array属性
print(type(dataset.__getitem__(0)[1])) # numpy.ndarray
print(dataset.__getitem__(0)[1].shape) # dtype('float64')
- 查看
DataLoader数据的类型: 已经变为torch.float64
for i, [train_w, train_d, train_r, train_t] in enumerate(loader):
print(train_w.dtype,train_w.shape)
if i >1:break
out:
torch.float64 torch.Size([50, 307, 3, 24])
torch.float64 torch.Size([50, 307, 3, 24])
torch.float64 torch.Size([50, 307, 3, 24])
验证:是否经过DataLoader数据会转化为torch.float64?
自定义了一个Dataset类,即My_dataset,定义的原因是DataLoader需要Dataset中的函数__getitem__。准备了两组类型的数据:np.array(即train)和torch.Tensor(即test)。如下所示。
X=np.random.normal(size=(10,2)) #shape is (10,2),dtype:float64
Y=np.random.uniform(size=(10,)) # shape is (10,),dtype:float64
train={"X":X,"Y":Y}
test={"X":torch.Tensor(X),"Y":torch.Tensor(Y)}# dtype:torch.float32
class My_dataset(Dataset):
def __init__(self,data):
self.data=data
def __getitem__(self,index):
return self.data['X'][index],self.data['Y'][index]
def __len__(self):
return len(self.data["X"])
将两组数据分别放入DataLoder,查看数据类型。
- np.array放入DataLoader
dataset=My_dataset(train)
loader = DataLoader(dataset, batch_size=3, shuffle=True)
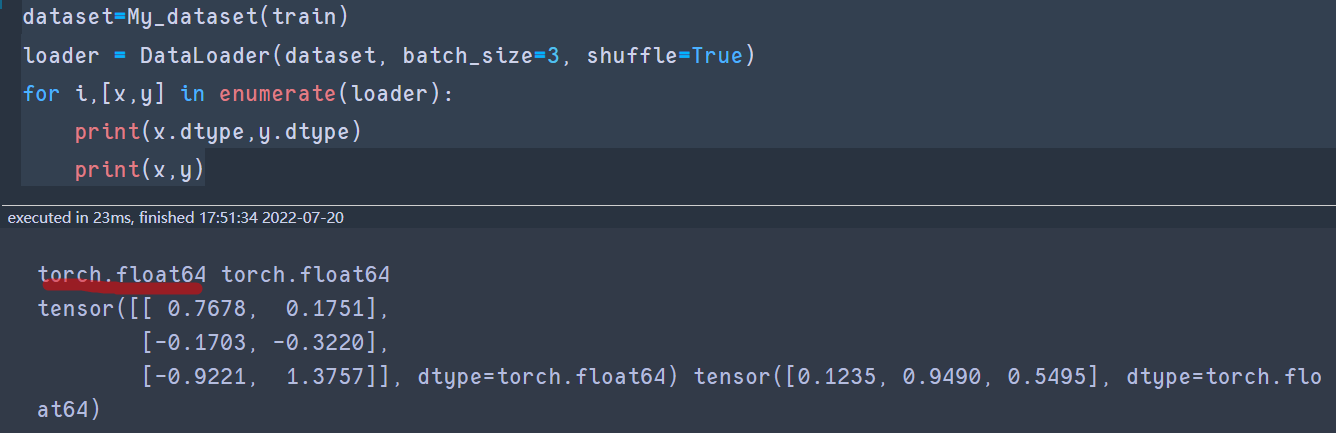
for i,[x,y] in enumerate(loader):
print(x.dtype,y.dtype)
print(x,y)
结果变为了:torch.float64!!!
- 将tensor放入DataLoader
dataset=My_dataset(test)
loader = DataLoader(dataset, batch_size=3, shuffle=True)
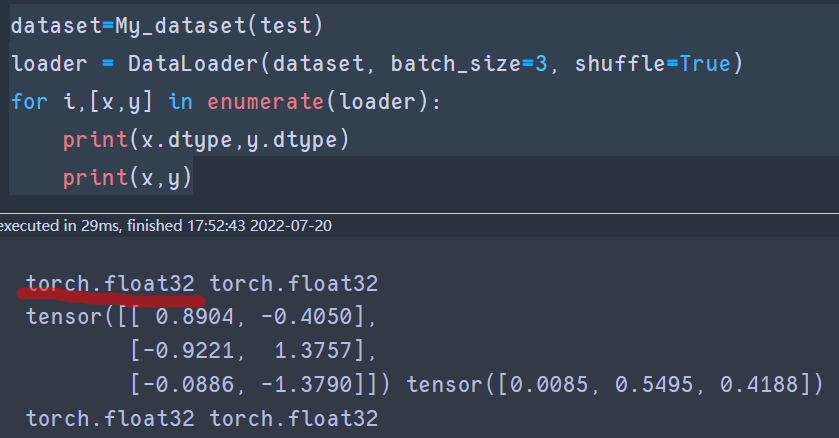
for i,[x,y] in enumerate(loader):
print(x.dtype,y.dtype)
print(x,y)
结果:产生torch.float32.适配结果良好!!!
验证结果
根据上面的实验,为了避免出现报错的现象。我们在使用Dataset和DataLoader的套餐的时候,要提前转化为Tensor,而不是直接使用np.array。


















 1368
1368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









