







学习资料:《[强化学习实战]出租车调度-Q learning & SARSA》
文章目录
一、环境taxi
gym.make('Taxi-v3')
智能体(即出租车)需要学会在一个网格状的城市中接送乘客到指定的目的地
axi环境的状态空间是离散的,由以下四个部分组成:
- 出租车所在行(taxi_row):表示出租车当前所在的网格行。
- 出租车所在列(taxi_col):表示出租车当前所在的网格列。
- 乘客位置(passenger_location):表示乘客当前所在的网格位置,通常用一个字母(如R、G、B、Y等)或坐标来表示。
- 目的地(destination):表示乘客需要到达的目的地,同样可以用一个字母或坐标来表示。
这四个部分共同构成了一个元组,表示了Taxi环境的当前状态。例如,状态(2, 1, ‘R’, ‘G’)表示出租车在第2行第1列,乘客在位置R,目的地是G。
动作空间
- 向南移动(south):出租车向南移动一格(如果当前位置在网格的最底部,则无法移动)。
- 向北移动(north):出租车向北移动一格(如果当前位置在网格的最顶部,则无法移动)。
- 向东移动(east):出租车向东移动一格(如果当前位置在网格的最右侧,则无法移动)。
- 向西移动(west):出租车向西移动一格(如果当前位置在网格的最左侧,则无法移动)。
- 接乘客(pickup):如果出租车当前位置与乘客位置相同,并且乘客尚未被接走,则执行此动作可以接走乘客。
- 放乘客(drop-off):如果出租车当前位置与目的地相同,并且乘客已被接走,则执行此动作可以放下乘客并完成任务。
智能体需要根据当前状态选择适当的动作,以最大化其获得的奖励。在Taxi环境中,通常设定了一些规则来奖励或惩罚智能体的行为,例如成功接送乘客会获得奖励,而执行无效动作(如试图在没有乘客的情况下放下乘客)则会受到惩罚。
1.Gym库里出租车调度问题
在5*5的网格世界中有四个指定位置,分别由R(ed)、G(reen)、Y(ellow)和B(lue)表示(见代码12-20行)。当episode开始时,出租车在一个随机的广场上出发,乘客在一个任意的位置。出租车开到乘客的位置,接乘客,开到乘客的目的地(四个指定位置中的另一个),然后下车。乘客下车后,这一episode就结束了
- 出租车的位置随机
- 乘客初始位置四选一
- episode:接乘客-送乘客,完成一轮
状态空间

状态是由出租车的位置、乘客的位置(包括乘客是否在出租车中)以及目的地的位置这三个因素共同决定的。
- 出租车的位置:出租车可以在一个5x5的方格地图上移动,因此有25个可能的位置。
- 乘客的位置:乘客可以位于四个出租车停靠点中的任意一个,或者已经在出租车上。因此,乘客有5个可能的位置(4个停靠点+1个在出租车上的状态)。
- 目的地的位置:乘客的目的地可以是四个停靠点中的任意一个,因此有4个可能的目的地。
三个因素可以组合成的总状态数为:
25(出租车位置)× 5(乘客位置)× 4(目的地位置)= 500个状态
env.observation_space
# 输出:Discrete(500)
env.observation_space.n
# 输出:500
每一个状态都可以用一个四元组 (taxi_row, taxi_col, passenger_location, destination) 来表示,其中:
- taxi_row 和 taxi_col 分别表示出租车在地图上的行和列位置(取值范围为0到4)。—int型变量
- passenger_location 表示乘客的位置,取值范围为0到4,其中0到3表示乘客在四个停靠点中的位置,4表示乘客已经在出租车上。—int型变量
- 0: R(ed)
- 1: G(reen)
- 2: Y(ellow)
- 3: B(lue)
- 4: in taxi
- destination 表示目的地的位置,取值范围为0到3,对应四个停靠点。—int型变量
- 0: R(ed)–>(0,0)
- 1: G(reen)–>(0,4)
- 2: Y(ellow)–>(4,0)
- 3: B(lue)—>(4,3)
A. state的encode
见代码210~219
潜在缺点是它假设了所有位置索引都是独立的,并且可以通过简单的数学运算组合在一起。这可能在某些情况下导致状态空间的浪费(例如,当某些位置组合在实际上是不可能的时候)或不够直观(因为编码后的整数不直接反映环境的物理布局)。然而,对于强化学习算法来说,只要编码是一致的,并且能够覆盖所有可能的状态,这种方法通常是可行的。
B. state的decode
见代码221~231
C.代码测试
import gym
env = gym.make('Taxi-v3')
state = env.reset() #初始化状态,随机
print(state)
#taxi_row, taxi_col, pass_loc, dest_idx = env.unwrapped.decode(state)#报错,提示输入'int',not'tuple'
taxi_row, taxi_col, pass_loc, dest_idx = env.unwrapped.decode(188)
# print(taxi_row, taxi_col, pass_loc, dest_idx)
out:
state:(188, {'prob': 1.0, 'action_mask': array([1, 1, 0, 1, 0, 0], dtype=int8)})
💡解读
188:采用数字表示状态,因为最多有500个状态。数值不可能超过500.
字典:prob是概率;action_mast是动作的掩码
✋ 案例
| 动作 | south | north | east | west | pickup | dropoff | 状态 | taxi_row | taxi_col | pass_loc | dest_idx |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 掩码 | 1 | 1 | 0 | 1 | 0 | 0 | 188 | 1 | 4 | 2 | 0 |
| - | 1 | 1 | 1 | 1 | 0 | 0 | 266 | 2 | 3 | 1 | 2 |
状态188
可达状态
在一次episode运动中,实际上可以达到400个state。
当乘客在目的地的位置的时候(乘客位置=目的地位置,供4种),出租车的随机位置共100个,所以要删除4*25=100个没必要的状态。
成功状态(终止条件)
当乘客和出租车都在目的地时,存在4种可能的成功状态(因为目的地有4个)。这些状态通常标志着episode的结束,但在某些实验或分析中,它们可能被当作可达状态来计算
🐒 总共给出了404个可到达的离散状态。
动作空间
数字表示动作
env.action_space
# 输出: Discrete(6)
env.action_space.n
# 输出:6
-
0: move south—>执行后的奖励:-1
-
1: move north—>执行后的奖励:-1
-
2: move east—>执行后的奖励:-1
-
3: move west—>执行后的奖励:-1
-
4: pickup passenger—>执行后的奖励:-1或者-10
如果动作成功(即出租车正确地接上了乘客),则奖励通常为-1(表示执行动作的成本)。
如果动作非法(例如,乘客已经在车上,或者出租车和乘客不在同一位置),则奖励为-10(表示错误的行为)。 -
5: drop off passenger—>执行后的奖励:+20或者-10
如果动作成功(即出租车正确地将乘客送达目的地并让其下车),则奖励为+20(表示完成任务的奖励)。
如果动作非法(例如,乘客不在车上,或者出租车不在目的地),则奖励为-10(表示错误的行为)。
奖励
- 每一步 -1,除非触发其他奖励。
- +20运送乘客。
- -10 非法执行“接送”和“下车”行为。
- 非法“pick-up”
如果出租车在尝试接送乘客时,没有正确地与乘客的位置对齐
当乘客不在出租车可以接送的停靠点时,如果出租车尝试执行“pickup”动作,则会被视为非法行为。
- 乘客可能位于地图上的某个非停靠点位置
- 乘客已经处于出租车上
- 非法执行“drop-off”行为
如果出租车在尝试送达乘客时,没有正确地将乘客送到目的地停靠点
当乘客不在出租车上时,如果出租车尝试执行“drop-off”动作,则会被视为非法行为
- 乘客还没有被接送
- 已经在之前某个时刻被送达了目的地并下车了
信息
- “step”和“reset”都会返回一个包含概率“p”动作掩码“action_mask”的信息字典。见代码263和278行。
- step:
return (int(s), r, t, False, {"prob": p, "action_mask": self.action_mask(s)}) - reset:
return int(self.s), {"prob": 1.0, "action_mask": self.action_mask(self.s)}
这里的“prob”:1.0是值当前状态经过某个动作转移到下一个状态的概率是1.0.每个动作是确定性的,当执行动作时,环境会以100%的概率转移到下一个状态。
- step:
- 动作无效:在某些特定的状态下,执行某些动作是无效的。例如,出租车和乘客不在同一个位置,但尝试执行“dropoff”动作。
info[“action_mask”]:
这是一个字典,其中包含了关于当前状态下哪些动作是有效的(即会改变状态)哪些是无效的(即不会改变状态)的信息。对于每个可能的动作,info[“action_mask”]提供了一个NumPy数组,数组中的每个元素对应一个动作,如果该元素为True,则表示执行该动作会改变状态;如果为False,则表示执行该动作不会改变状态。
二、DQN代码
import gym #强化学习环境
import numpy as np
import random
import torch
import torch.nn as nn
import torch.optim as optim
from collections import deque #deque是队列
2.1 神经网络
class DQN(nn.Module):
def __init__(self, state_size, hidden_size, action_size):
super(DQN, self).__init__()
self.fc1 = nn.Linear(state_size, hidden_size) #输入层
self.fc2 = nn.Linear(hidden_size, hidden_size)#隐藏层
self.fc3 = nn.Linear(6hidden_size, action_size)#输出层
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
state_size =4
hidden_size =64
action_size=6
💡解读
这个DQN(Deep Q-Network)模型是一个简单的三层全连接神经网络,用于强化学习任务中的值函数近似。
设 x 为输入状态向量,其维度为 state_size。
- 第一层(输入层): h 1 = R e L U ( W 1 ⋅ x + b 1 ) h1=ReLU(W_1\cdot x+b1) h1=ReLU(W1⋅x+b1)
其中,W1 是第一层的权重矩阵(大小为 64×state_size),b1 是偏置向量(大小为64),h1 是第一层隐藏层的输出向量(大小为64)。- 第二层(隐藏层): h 2 = R e L U ( W 2 ⋅ h 1 + b 2 ) h2=ReLU(W_2\cdot h1+b2) h2=ReLU(W2⋅h1+b2)
其中,W2 是第二层的权重矩阵(大小为 64×64),b2 是偏置向量(大小为64),h2 是第二层隐藏层的输出向量(大小为64)。- 输出层: Q = W 3 ⋅ h 2 + b 3 Q=W_3 \cdot h2+b3 Q=W3⋅h2+b3
其中,W3 是输出层的权重矩阵(大小为 action_size×64),b3 是偏置向量(大小为 action_size),Q 是输出向量,表示每个动作的Q值(大小为 action_size)。
2.2 经验池buffer
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity)
def push(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))#添加经验条
def sample(self, batch_size):
return random.sample(self.buffer, batch_size) #批量抽取数据
def __len__(self):
return len(self.buffer)
2.3. 环境交互
2.3.1 动作选择
Q表格
采用ε-greedy策略进行动作选择。使用Q表格的方法获得动作的选择。一般令epsilon=0.01
# 选择动作:epsilon-greedy策略
if np.random.rand() < epsilon:
action = env.action_space.sample() #选择动作
else:
np.argmax(Q[state, :]) #Q是Q-表格
DQN
import random #还有其他的导入包
class DQNAgent:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
##还有其他的值
self.epsilon = 0.1
self.model = DQN(state_size, action_size)
def act(self, state_decoded):
p =random.random()
if p<= self.epsilon:
action = random.randint(0,self.action_size-1) #任意随机值
return action
state = torch.FloatTensor(state_decoded).unsqueeze(0) #升维(1,action_size)
Q_values = self.model(state).squeeze(0)#降维(action_size,)
return torch.argmax(Q_values).item() #返回函数生成的动作
2.3.2 马尔可夫链-图示
在env = gym.make('Taxi-v3')中,Q表格.shape=(500,6).假设state=67,其decode=[0,3,1,3],含义为vehicle在index(0,3)的位置,乘客的位置为1(Green),目的地为3(Blue).见图a.最优的路线之一见图b.
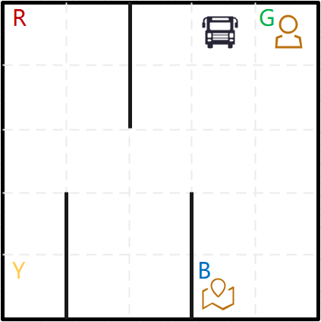 图a
图a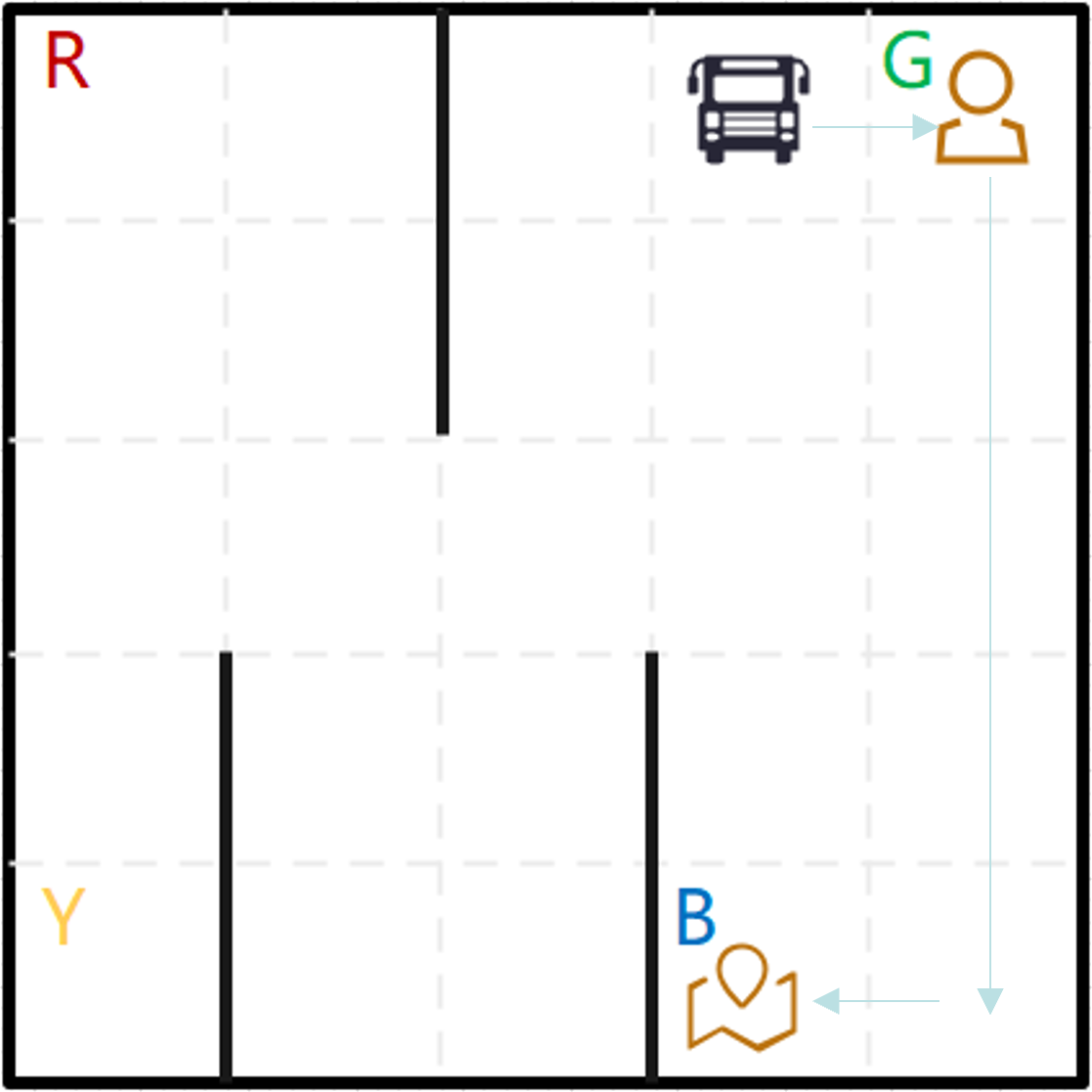 图b
图b
67 ( 0 , 3 , 1 , 3 ) → 东 , − 1 87 ( 0 , 4 , 1 , 3 ) ⟶ p i c k u p , − 1 99 ( 0 , 4 , 4 , 3 ) ⟶ 南 , − 1 199 ( 1 , 4 , 4 , 3 ) ⟶ 南 , − 1 299 ( 2 , 4 , 4 , 3 ) ⟶ 南 , − 1 399 ( 3 , 4 , 4 , 3 ) ⟶ 南 , − 1 499 ( 4 , 4 , 4 , 3 ) ⟶ 西 , − 1 479 ( 4 , 3 , 4 , 3 ) ⟶ d r o p o f f , 20 475 ( 3 , 4 , 3 , 3 ) 67(0,3,1,3) \stackrel{东,-1}→87(0,4,1,3)\stackrel{pickup,-1} \longrightarrow 99(0,4,4,3) \stackrel{南,-1}\longrightarrow199(1,4,4,3)\stackrel{南,-1}\longrightarrow299(2,4,4,3)\stackrel{南,-1}\longrightarrow399(3,4,4,3)\stackrel{南,-1}\longrightarrow499(4,4,4,3)\stackrel{西,-1}\longrightarrow479(4,3,4,3)\stackrel{dropoff,20}\longrightarrow475(3,4,3,3) 67(0,3,1,3)→东,−187(0,4,1,3)⟶pickup,−199(0,4,4,3)⟶南,−1199(1,4,4,3)⟶南,−1299(2,4,4,3)⟶南,−1399(3,4,4,3)⟶南,−1499(4,4,4,3)⟶西,−1479(4,3,4,3)⟶dropoff,20475(3,4,3,3)
G
a
i
n
t
=
R
t
+
γ
⋅
G
a
i
n
t
+
1
=
R
t
+
γ
R
t
+
1
+
γ
2
R
t
+
2
+
⋯
Gain_t= R_t+\gamma \cdot Gain_{t+1}=R_t+\gamma R_{t+1}+\gamma^2 R_{t+2}+\cdots
Gaint=Rt+γ⋅Gaint+1=Rt+γRt+1+γ2Rt+2+⋯
G
a
i
n
[
67
]
=
(
−
1
)
+
(
−
1
)
⋅
0.9
+
(
−
1
)
⋅
0.
9
2
+
(
−
1
)
⋅
0.
9
3
+
(
−
1
)
⋅
0.
9
4
+
(
−
1
)
⋅
0.
9
5
+
(
−
1
)
⋅
0.
9
6
+
20
⋅
0.
9
7
=
4.3489070000000005
Gain_{[67]}=(-1)+(-1)\cdot 0.9+(-1)\cdot 0.9^2+(-1)\cdot 0.9^3 +(-1)\cdot 0.9^4+(-1)\cdot 0.9^5 +(-1)\cdot 0.9^6+20\cdot 0.9^7=4.3489070000000005
Gain[67]=(−1)+(−1)⋅0.9+(−1)⋅0.92+(−1)⋅0.93+(−1)⋅0.94+(−1)⋅0.95+(−1)⋅0.96+20⋅0.97=4.3489070000000005
2.3.3 使用代码环境交互
环境初始化
state,info = env.reset() # 获取状态整数
state_decoded = decode_state(state) #整数解码
def decode_state(state_idx):
"""将0-499的整数状态解码为[taxi_row, taxi_col, pass_loc, dest_idx]"""
dest_idx = state_idx % 4
state_idx = state_idx // 4
pass_loc = state_idx % 5
state_idx = state_idx // 5
taxi_col = state_idx % 5
taxi_row = state_idx // 5
return [taxi_row, taxi_col, pass_loc, dest_idx]
设state=44,info={'prob': 1.0, 'action_mask': array([1, 0, 1, 0, 0, 0], dtype=int8)},state_decoded=[0,2,1,0]
执行动作获得下一状态
action = 2 #east 东 #[0,2,1,0]--东-->[0,3,1,0]
next_state, reward, done, _, info = env.step(action)
# 64,-1,False, False,{'prob': 1.0, 'action_mask': array([1, 0, 1, 1, 0, 0], dtype=int8)}
# decode_state(64) #[0, 3, 1, 0]
执行掩码中为0的动作,返回的状态不变,state=64, 进行无效操作action=1后,next_state=64
action = 1
next_state, reward, done, _, info = env.step(action)
#64,-1,False, False,{'prob': 1.0, 'action_mask': array([1, 0, 1, 1, 0, 0], dtype=int8)}
2.3.4 终止状态的交互情况
| terminated [整数 | 0 | 85 | 410 | 475 |
|---|---|---|---|---|
| 解码 | 【0,0,0,0】 | 【0,4,1,1】 | 【4,0,2,2】 | 【4,3,3,3】 |
| last_action | 5 | 5 | 5 | 5 |
| last_state | 【0,0,4,0】 | 【0,4,4,1】 | 【4,0,4,2】 | 【4,3,4,3】 |
| 整数 | 16 | 97 | 418 | 479 |
| last_action | 北=1 | 北=1 | 南=0 | 南=0 |
| last_state | 【1,0,4,0】 | 【1,4,4,1】 | 【3,0,4,2】 | 【3,3,4,3】 |
| 整数 | 116 | 197 | 318 | 379 |
218–南(0)–>318–南(0)–>418
next_state= 418,reward=-1,done=False, info={'prob': 1.0, 'action_mask': array([0, 1, 0, 0, 0, 1], dtype=int8)}
执行动作action=5 (即dropoff)
next_state=410,reward=20,done=True,info={'prob': 1.0, 'action_mask': array([0, 1, 0, 0, 1, 0], dtype=int8)}
参数更新
附录:taxi.py的代码
(注释是自己加的)
from contextlib import closing
from io import StringIO
from os import path
from typing import Optional
import numpy as np
from gym import Env, logger, spaces, utils
from gym.envs.toy_text.utils import categorical_sample
from gym.error import DependencyNotInstalled
MAP = [
"+---------+",
"|R: | : :G|",
"| : | : : |",
"| : : : : |",
"| | : | : |",
"|Y| : |B: |",
"+---------+",
]
WINDOW_SIZE = (550, 350)#窗口大小
class TaxiEnv(Env):
"""
The Taxi Problem
from "Hierarchical Reinforcement Learning with the MAXQ Value Function Decomposition"
by Tom Dietterich
### Description
There are four designated locations in the grid world indicated by R(ed),
G(reen), Y(ellow), and B(lue). When the episode starts, the taxi starts off
at a random square and the passenger is at a random location. The taxi
drives to the passenger's location, picks up the passenger, drives to the
passenger's destination (another one of the four specified locations), and
then drops off the passenger. Once the passenger is dropped off, the episode ends.
Map:
+---------+
|R: | : :G|
| : | : : |
| : : : : |
| | : | : |
|Y| : |B: |
+---------+
### Actions
There are 6 discrete deterministic actions:
- 0: move south
- 1: move north
- 2: move east
- 3: move west
- 4: pickup passenger
- 5: drop off passenger
### Observations
There are 500 discrete states since there are 25 taxi positions, 5 possible
locations of the passenger (including the case when the passenger is in the
taxi), and 4 destination locations.
Note that there are 400 states that can actually be reached during an
episode. The missing states correspond to situations in which the passenger
is at the same location as their destination, as this typically signals the
end of an episode. Four additional states can be observed right after a
successful episodes, when both the passenger and the taxi are at the destination.
This gives a total of 404 reachable discrete states.
Each state space is represented by the tuple:
(taxi_row, taxi_col, passenger_location, destination)
An observation is an integer that encodes the corresponding state.
The state tuple can then be decoded with the "decode" method.
Passenger locations:
- 0: R(ed)
- 1: G(reen)
- 2: Y(ellow)
- 3: B(lue)
- 4: in taxi
Destinations:
- 0: R(ed)
- 1: G(reen)
- 2: Y(ellow)
- 3: B(lue)
### Info
``step`` and ``reset()`` will return an info dictionary that contains "p" and "action_mask" containing
the probability that the state is taken and a mask of what actions will result in a change of state to speed up training.
As Taxi's initial state is a stochastic, the "p" key represents the probability of the
transition however this value is currently bugged being 1.0, this will be fixed soon.
As the steps are deterministic, "p" represents the probability of the transition which is always 1.0
For some cases, taking an action will have no effect on the state of the agent.
In v0.25.0, ``info["action_mask"]`` contains a np.ndarray for each of the action specifying
if the action will change the state.
To sample a modifying action, use ``action = env.action_space.sample(info["action_mask"])``
Or with a Q-value based algorithm ``action = np.argmax(q_values[obs, np.where(info["action_mask"] == 1)[0]])``.
### Rewards
- -1 per step unless other reward is triggered.
- +20 delivering passenger.
- -10 executing "pickup" and "drop-off" actions illegally.
### Arguments
```
gym.make('Taxi-v3')
```
### Version History
* v3: Map Correction + Cleaner Domain Description, v0.25.0 action masking added to the reset and step information
* v2: Disallow Taxi start location = goal location, Update Taxi observations in the rollout, Update Taxi reward threshold.
* v1: Remove (3,2) from locs, add passidx<4 check
* v0: Initial versions release
"""
metadata = {
"render_modes": ["human", "ansi", "rgb_array"],
"render_fps": 4,
}
def __init__(self, render_mode: Optional[str] = None):
self.desc = np.asarray(MAP, dtype="c")
self.locs = locs = [(0, 0), (0, 4), (4, 0), (4, 3)]
self.locs_colors = [(255, 0, 0), (0, 255, 0), (255, 255, 0), (0, 0, 255)]#
num_states = 500
num_rows = 5
num_columns = 5
max_row = num_rows - 1
max_col = num_columns - 1
self.initial_state_distrib = np.zeros(num_states)
num_actions = 6
self.P = {
state: {action: [] for action in range(num_actions)}
for state in range(num_states)
}
for row in range(num_rows):
for col in range(num_columns):
for pass_idx in range(len(locs) + 1): # +1 for being inside taxi
for dest_idx in range(len(locs)):
state = self.encode(row, col, pass_idx, dest_idx)
if pass_idx < 4 and pass_idx != dest_idx:
self.initial_state_distrib[state] += 1
for action in range(num_actions):
# defaults
new_row, new_col, new_pass_idx = row, col, pass_idx
reward = (
-1
) # default reward when there is no pickup/dropoff
terminated = False
taxi_loc = (row, col)
if action == 0:
new_row = min(row + 1, max_row)
elif action == 1:
new_row = max(row - 1, 0)
if action == 2 and self.desc[1 + row, 2 * col + 2] == b":":
new_col = min(col + 1, max_col)
elif action == 3 and self.desc[1 + row, 2 * col] == b":":
new_col = max(col - 1, 0)
elif action == 4: # pickup
if pass_idx < 4 and taxi_loc == locs[pass_idx]:
new_pass_idx = 4
else: # passenger not at location
reward = -10
elif action == 5: # dropoff
if (taxi_loc == locs[dest_idx]) and pass_idx == 4:
new_pass_idx = dest_idx
terminated = True
reward = 20
elif (taxi_loc in locs) and pass_idx == 4:
new_pass_idx = locs.index(taxi_loc)
else: # dropoff at wrong location
reward = -10
new_state = self.encode(
new_row, new_col, new_pass_idx, dest_idx
)
self.P[state][action].append(
(1.0, new_state, reward, terminated)
)
self.initial_state_distrib /= self.initial_state_distrib.sum()
self.action_space = spaces.Discrete(num_actions)
self.observation_space = spaces.Discrete(num_states)
self.render_mode = render_mode
# pygame utils
self.window = None
self.clock = None
self.cell_size = (
WINDOW_SIZE[0] / self.desc.shape[1],
WINDOW_SIZE[1] / self.desc.shape[0],
)
self.taxi_imgs = None
self.taxi_orientation = 0
self.passenger_img = None
self.destination_img = None
self.median_horiz = None
self.median_vert = None
self.background_img = None
def encode(self, taxi_row, taxi_col, pass_loc, dest_idx):
# (5) 5, 5, 4
i = taxi_row
i *= 5
i += taxi_col
i *= 5
i += pass_loc
i *= 4
i += dest_idx
return i
def decode(self, i):
out = []
out.append(i % 4)
i = i // 4
out.append(i % 5)
i = i // 5
out.append(i % 5)
i = i // 5
out.append(i)
assert 0 <= i < 5
return reversed(out)
def action_mask(self, state: int):
"""Computes an action mask for the action space using the state information."""
mask = np.zeros(6, dtype=np.int8)
taxi_row, taxi_col, pass_loc, dest_idx = self.decode(state)
if taxi_row < 4:
mask[0] = 1
if taxi_row > 0:
mask[1] = 1
if taxi_col < 4 and self.desc[taxi_row + 1, 2 * taxi_col + 2] == b":":
mask[2] = 1
if taxi_col > 0 and self.desc[taxi_row + 1, 2 * taxi_col] == b":":
mask[3] = 1
if pass_loc < 4 and (taxi_row, taxi_col) == self.locs[pass_loc]:
mask[4] = 1
if pass_loc == 4 and (
(taxi_row, taxi_col) == self.locs[dest_idx]
or (taxi_row, taxi_col) in self.locs
):
mask[5] = 1
return mask
def step(self, a):
transitions = self.P[self.s][a]
i = categorical_sample([t[0] for t in transitions], self.np_random)
p, s, r, t = transitions[i]
self.s = s
self.lastaction = a
if self.render_mode == "human":
self.render()
return (int(s), r, t, False, {"prob": p, "action_mask": self.action_mask(s)})
def reset(
self,
*,
seed: Optional[int] = None,
options: Optional[dict] = None,
):
super().reset(seed=seed)
self.s = categorical_sample(self.initial_state_distrib, self.np_random)
self.lastaction = None
self.taxi_orientation = 0
if self.render_mode == "human":
self.render()
return int(self.s), {"prob": 1.0, "action_mask": self.action_mask(self.s)}
def render(self):
if self.render_mode is None:
logger.warn(
"You are calling render method without specifying any render mode. "
"You can specify the render_mode at initialization, "
f'e.g. gym("{self.spec.id}", render_mode="rgb_array")'
)
if self.render_mode == "ansi":
return self._render_text()
else: # self.render_mode in {"human", "rgb_array"}:
return self._render_gui(self.render_mode)
def _render_gui(self, mode):
try:
import pygame # dependency to pygame only if rendering with human
except ImportError:
raise DependencyNotInstalled(
"pygame is not installed, run `pip install gym[toy_text]`"
)
if self.window is None:
pygame.init()
pygame.display.set_caption("Taxi")
if mode == "human":
self.window = pygame.display.set_mode(WINDOW_SIZE)
elif mode == "rgb_array":
self.window = pygame.Surface(WINDOW_SIZE)
assert (
self.window is not None
), "Something went wrong with pygame. This should never happen."
if self.clock is None:
self.clock = pygame.time.Clock()
if self.taxi_imgs is None:
file_names = [
path.join(path.dirname(__file__), "img/cab_front.png"),
path.join(path.dirname(__file__), "img/cab_rear.png"),
path.join(path.dirname(__file__), "img/cab_right.png"),
path.join(path.dirname(__file__), "img/cab_left.png"),
]
self.taxi_imgs = [
pygame.transform.scale(pygame.image.load(file_name), self.cell_size)
for file_name in file_names
]
if self.passenger_img is None:
file_name = path.join(path.dirname(__file__), "img/passenger.png")
self.passenger_img = pygame.transform.scale(
pygame.image.load(file_name), self.cell_size
)
if self.destination_img is None:
file_name = path.join(path.dirname(__file__), "img/hotel.png")
self.destination_img = pygame.transform.scale(
pygame.image.load(file_name), self.cell_size
)
self.destination_img.set_alpha(170)
if self.median_horiz is None:
file_names = [
path.join(path.dirname(__file__), "img/gridworld_median_left.png"),
path.join(path.dirname(__file__), "img/gridworld_median_horiz.png"),
path.join(path.dirname(__file__), "img/gridworld_median_right.png"),
]
self.median_horiz = [
pygame.transform.scale(pygame.image.load(file_name), self.cell_size)
for file_name in file_names
]
if self.median_vert is None:
file_names = [
path.join(path.dirname(__file__), "img/gridworld_median_top.png"),
path.join(path.dirname(__file__), "img/gridworld_median_vert.png"),
path.join(path.dirname(__file__), "img/gridworld_median_bottom.png"),
]
self.median_vert = [
pygame.transform.scale(pygame.image.load(file_name), self.cell_size)
for file_name in file_names
]
if self.background_img is None:
file_name = path.join(path.dirname(__file__), "img/taxi_background.png")
self.background_img = pygame.transform.scale(
pygame.image.load(file_name), self.cell_size
)
desc = self.desc
for y in range(0, desc.shape[0]):
for x in range(0, desc.shape[1]):
cell = (x * self.cell_size[0], y * self.cell_size[1])
self.window.blit(self.background_img, cell)
if desc[y][x] == b"|" and (y == 0 or desc[y - 1][x] != b"|"):
self.window.blit(self.median_vert[0], cell)
elif desc[y][x] == b"|" and (
y == desc.shape[0] - 1 or desc[y + 1][x] != b"|"
):
self.window.blit(self.median_vert[2], cell)
elif desc[y][x] == b"|":
self.window.blit(self.median_vert[1], cell)
elif desc[y][x] == b"-" and (x == 0 or desc[y][x - 1] != b"-"):
self.window.blit(self.median_horiz[0], cell)
elif desc[y][x] == b"-" and (
x == desc.shape[1] - 1 or desc[y][x + 1] != b"-"
):
self.window.blit(self.median_horiz[2], cell)
elif desc[y][x] == b"-":
self.window.blit(self.median_horiz[1], cell)
for cell, color in zip(self.locs, self.locs_colors):
color_cell = pygame.Surface(self.cell_size)
color_cell.set_alpha(128)
color_cell.fill(color)
loc = self.get_surf_loc(cell)
self.window.blit(color_cell, (loc[0], loc[1] + 10))
taxi_row, taxi_col, pass_idx, dest_idx = self.decode(self.s)
if pass_idx < 4:
self.window.blit(self.passenger_img, self.get_surf_loc(self.locs[pass_idx]))
if self.lastaction in [0, 1, 2, 3]:
self.taxi_orientation = self.lastaction
dest_loc = self.get_surf_loc(self.locs[dest_idx])
taxi_location = self.get_surf_loc((taxi_row, taxi_col))
if dest_loc[1] <= taxi_location[1]:
self.window.blit(
self.destination_img,
(dest_loc[0], dest_loc[1] - self.cell_size[1] // 2),
)
self.window.blit(self.taxi_imgs[self.taxi_orientation], taxi_location)
else: # change blit order for overlapping appearance
self.window.blit(self.taxi_imgs[self.taxi_orientation], taxi_location)
self.window.blit(
self.destination_img,
(dest_loc[0], dest_loc[1] - self.cell_size[1] // 2),
)
if mode == "human":
pygame.display.update()
self.clock.tick(self.metadata["render_fps"])
elif mode == "rgb_array":
return np.transpose(
np.array(pygame.surfarray.pixels3d(self.window)), axes=(1, 0, 2)
)
def get_surf_loc(self, map_loc):
return (map_loc[1] * 2 + 1) * self.cell_size[0], (
map_loc[0] + 1
) * self.cell_size[1]
def _render_text(self):
desc = self.desc.copy().tolist()
outfile = StringIO()
out = [[c.decode("utf-8") for c in line] for line in desc]
taxi_row, taxi_col, pass_idx, dest_idx = self.decode(self.s)
def ul(x):
return "_" if x == " " else x
if pass_idx < 4:
out[1 + taxi_row][2 * taxi_col + 1] = utils.colorize(
out[1 + taxi_row][2 * taxi_col + 1], "yellow", highlight=True
)
pi, pj = self.locs[pass_idx]
out[1 + pi][2 * pj + 1] = utils.colorize(
out[1 + pi][2 * pj + 1], "blue", bold=True
)
else: # passenger in taxi
out[1 + taxi_row][2 * taxi_col + 1] = utils.colorize(
ul(out[1 + taxi_row][2 * taxi_col + 1]), "green", highlight=True
)
di, dj = self.locs[dest_idx]
out[1 + di][2 * dj + 1] = utils.colorize(out[1 + di][2 * dj + 1], "magenta")
outfile.write("\n".join(["".join(row) for row in out]) + "\n")
if self.lastaction is not None:
outfile.write(
f" ({['South', 'North', 'East', 'West', 'Pickup', 'Dropoff'][self.lastaction]})\n"
)
else:
outfile.write("\n")
with closing(outfile):
return outfile.getvalue()
def close(self):
if self.window is not None:
import pygame
pygame.display.quit()
pygame.quit()
# Taxi rider from https://franuka.itch.io/rpg-asset-pack
# All other assets by Mel Tillery http://www.cyaneus.com/

















 1221
1221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









