










提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
提示:这里可以添加本文要记录的大概内容:
Hadoop Spark HA环境搭建好了,试着创建程序提交到Spark集群执行简单计算统计
提示:以下是本篇文章正文内容,下面案例可供参考
一、需求分析
需求:单词计数
执行步骤:
1、远程取两个文件
2、获取两个文件内的数据
3、将文件内的数据进行扁平化
4、将相同单词进行分组
5、聚合计算每个单词的个数
二、使用步骤
1.准备环境
资源列表
| 软件/工具 | 版本 |
|---|---|
| VMware | VMware® Workstation 16 Pro |
| FinalShell | FinalShell 3.9.5.4 |
| IDEA | IDEA 2020.1 |
虚拟机
| 主机名 | IP |
|---|---|
| hadoop01 | 192.168.74.88 |
| hadoop02 | 192.168.74.89 |
| hadoop03 | 192.168.74.90 |
启动Hadoop HA
启动Spark HA
2.测试数据
编写多个测试数据.txt文件,文件名随意,将文本文件上传至hdfs的/datas目录
以1.txt、2.txt为例
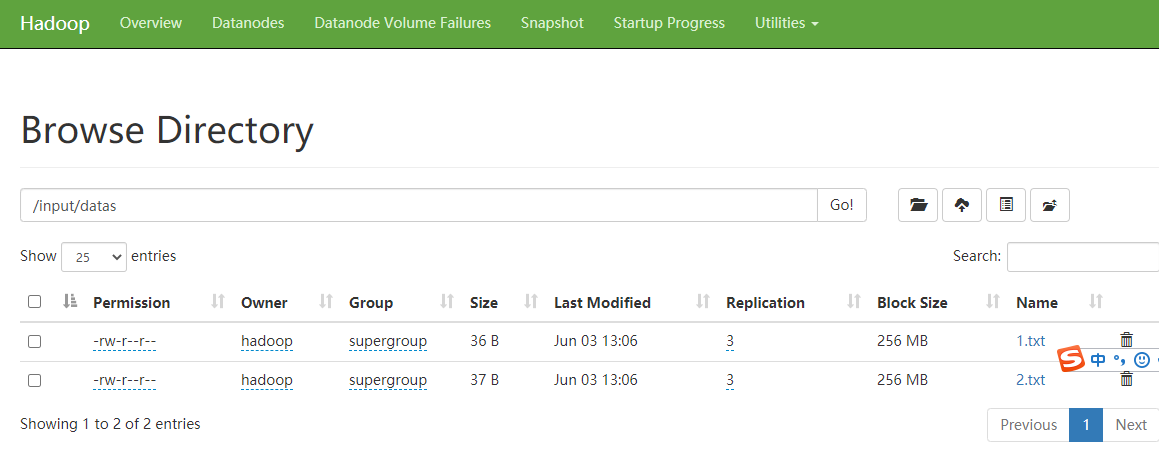
将测试数据传到hdfs的/input/datas目录
hadoop fs -mkdir /input
hadoop fs -mkdir /input/datas
hadoop fs -put 1.txt /input/datas
hadoop fs -put 2.txt /input/datas
创建结果存储目录/output
hadoop fs -mkdir /output
3.代码实现
代码如下(示例):
System.setProperty("HADOOP_USER_NAME", "hadoop");
//创建链接
SparkConf conf = new SparkConf()
.setMaster("spark://hadoop01:7077")
.setAppName("JavaWordCount")
.set("spark.cores.max","1")
.set("spark.executor.memory","512M")
.set("spark.driver.memory","512M")
//.setJars(JavaSparkContext.jarOfClass(JavaWordCount.class));
.setJars(new String[]{("target/WordCount.jar")});
JavaSparkContext sc = new JavaSparkContext(conf);
System.out.println("1.读取文件");
//业务操作
//1.读取文件
JavaRDD<String> lines = sc.textFile("hdfs://ns/input/datas");
System.out.println("1.读取文件,line:"+lines.count());
//2.拆分单词
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
public Iterator<String> call(String s) throws Exception {
List<String> list = new ArrayList<String>();
String[] arr = s.split(" ");
for (String s1 : arr) {
list.add(s1);
}
return list.iterator();
}
});
System.out.println("2.拆分单词,words:");
//3.单词计数
JavaPairRDD<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
System.out.println("3.单词计数");
//4.单词统计
JavaPairRDD<String, Integer> wordToCount = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer + integer2;
}
});
System.out.println("4.单词统计");
//5.数据采集
List<Tuple2<String, Integer>> arrays = wordToCount.collect();
System.out.println("数据采集");
for (Tuple2<String, Integer> array : arrays) {
System.out.println(array);
}
System.out.println("5.数据采集");
//6.保存输出结果
//wordToCount.saveAsTextFile("hdfs://ns/output/wordCount/java/JavaWordCount");
System.out.println("6.保存输出结果");
//关闭资源
sc.close();
执行main方法,控制台输出计算结果
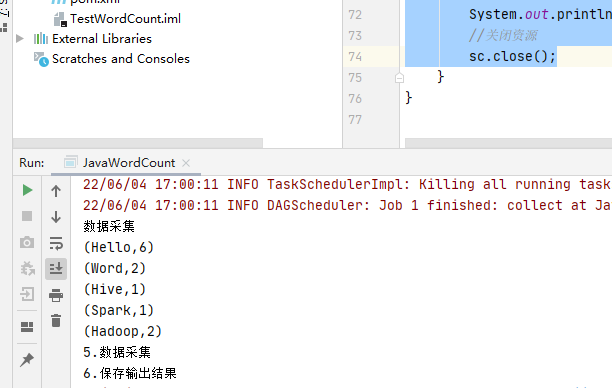
4.Spark集群执行
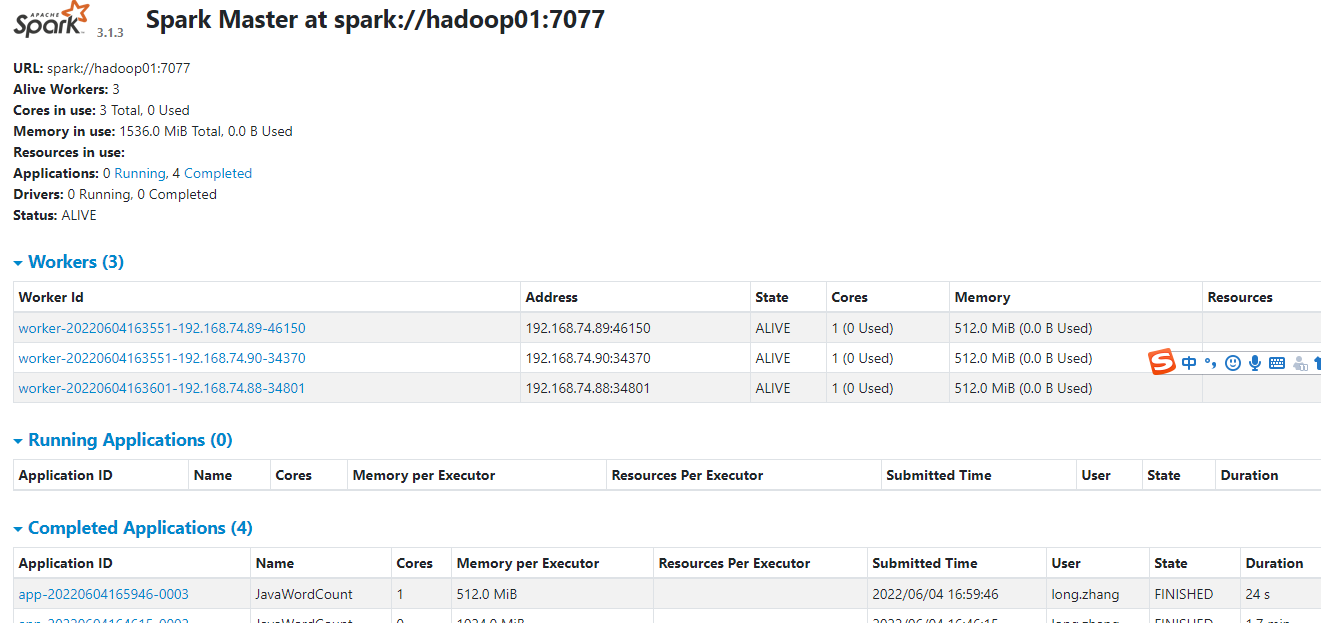
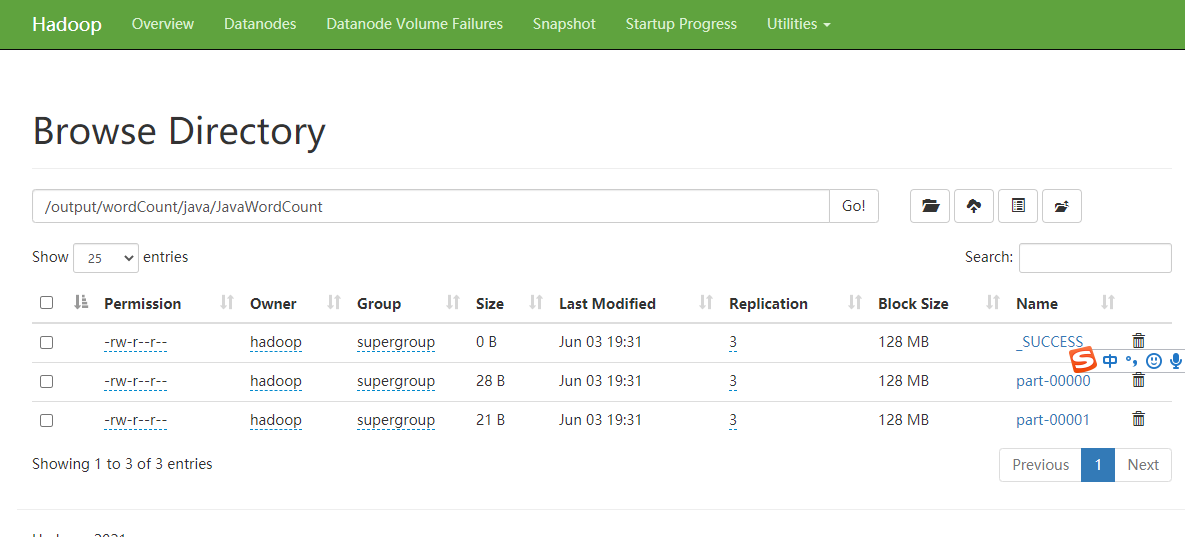
5.hdfs输出目录
总结
记录点点滴滴
















 628
628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











