







DOM解析XML文件时,会将XML文件的所有内容读取到内存中,然后允许您使用DOM API遍历XML树、检索所需的数据。使用DOM操作XML的代码看起来比较直观。但是,因为DOM需要将XML文件的所有内容读取到内存中,所以内存的消耗比较大。
DOM 将 XML 文档作为一个树形结构,而树叶被定义为节点。
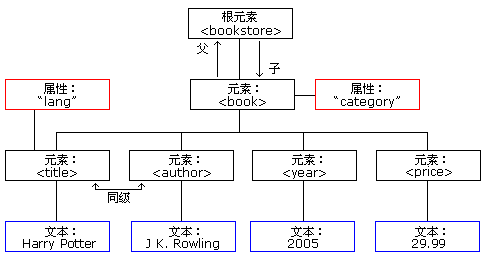
(参见:http://www.w3school.com.cn/xmldom/)
要解析的xml文件为book.xml,内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="1001">
<name>Thinking In Java</name>
<price>80.0</price>
</book>
<book id="1002">
<name>Core Java</name>
<price>90.0</price>
</book>
<book id="1003">
<name>Hello, Andriod</name>
<price>100.0</price>
</book>
</books> 最终获得List<Book>对象,以下Book.java的代码:
public class Book {
private int id;
private String name;
private float price;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public float getPrice() {
return price;
}
public void setPrice(float price) {
this.price = price;
}
@Override
public String toString() {
return "id:" + id + ", name:" + name + ", price:" + price;
}
} 使用DOM解析器:
import java.io.InputStream;
import java.io.StringWriter;
import java.util.ArrayList;
import java.util.List;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Result;
import javax.xml.transform.Source;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class DomBookParser {
public List<Book> parse(InputStream is) throws Exception {
List<Book> books = new ArrayList<Book>();
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); //取得DocumentBuilderFactory实例
DocumentBuilder builder = factory.newDocumentBuilder(); //从factory获取DocumentBuilder实例
Document doc = builder.parse(is); //解析输入流 得到Document实例
Element rootElement = doc.getDocumentElement();
NodeList items = rootElement.getElementsByTagName("book");
for (int i = 0; i < items.getLength(); i++) {
Book book = new Book();
Node item = items.item(i);
NodeList properties = item.getChildNodes();
for (int j = 0; j < properties.getLength(); j++) {
Node property = properties.item(j);
String nodeName = property.getNodeName();
if (nodeName.equals("id")) {
book.setId(Integer.parseInt(property.getFirstChild().getNodeValue()));
} else if (nodeName.equals("name")) {
book.setName(property.getFirstChild().getNodeValue());
} else if (nodeName.equals("price")) {
book.setPrice(Float.parseFloat(property.getFirstChild().getNodeValue()));
}
}
books.add(book);
}
return books;
}
public String serialize(List<Book> books) {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document doc = builder.newDocument(); //由builder创建新文档
Element rootElement = doc.createElement("books");
for (Book book : books) {
Element bookElement = doc.createElement("book");
bookElement.setAttribute("id", book.getId() + "");
Element nameElement = doc.createElement("name");
nameElement.setTextContent(book.getName());
bookElement.appendChild(nameElement);
Element priceElement = doc.createElement("price");
priceElement.setTextContent(book.getPrice() + "");
bookElement.appendChild(priceElement);
rootElement.appendChild(bookElement);
}
doc.appendChild(rootElement);
TransformerFactory transFactory = TransformerFactory.newInstance();//取得TransformerFactory实例
Transformer transformer = transFactory.newTransformer(); //从transFactory获取Transformer实例
transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8"); // 设置输出采用的编码方式
transformer.setOutputProperty(OutputKeys.INDENT, "yes"); // 是否自动添加额外的空白
transformer.setOutputProperty(OutputKeys.OMIT_XML_DECLARATION, "no"); // 是否忽略XML声明
StringWriter writer = new StringWriter();
Source source = new DOMSource(doc); //表明文档来源是doc
Result result = new StreamResult(writer);//表明目标结果为writer
transformer.transform(source, result); //开始转换
return writer.toString();
}
}















 1210
1210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









