







Redis基础数据类型
Redis特点
1.简单稳定
- Redis使用单线程模型(在Redis 6版本中实质执行命令线程还是单线程)
- Redis不需要依赖于操作系统中的类库,比如Memcache需要依赖libevent这样的系统类库
- Redis源码较少
2.运行速度快
- Redis的所有数据都是存放在内存中
- Redis使用C语言实现的(C语言编写的程序距离操作系统更近、执行速度相对较快)
- Redis命令执行是单线程的,所以预防了多线程上下文频繁切换的问题
官方给出的结果是读写性能可以达到每秒10万次以上
3.功能丰富
除了常用的String、List、Hash、Set、Zset这5种数据类型之外,Redis还提供了许多额外的功能:
- 键过期功能,可以用来实现缓存
- 发布和订阅功能,可以用作消息系统
- Lua脚本扩展功能,可以利用Lua创造新的Redis命令。
- 简单的事务功能,能在一定程度上保证事务特性。
- 管道(Pipeline)功能,客户端能将多条命令一次性传到Redis执行,减少网络开销
4.高可扩展、高性能与高可用特性
- Redis是内存数据库,但是数据放在内存中是不安全的,一旦发生断电或者机器故障,重要的数据就可能会丢失,于是Redis提供了RDB和AOF两种持久化方式,可让用户将内存数据保存在硬盘中,以保证数据的安全
- Redis从3.0版本开始正式提供了Redis Cluster(真正的分布式实现),提高了读写和容量的扩展性
- 在编程语言方面,几乎所有主流的编程语言都可以很方便地接入Redis,例如NET、Java、PHP、Python、C、C++、Node.js等
数据结构
1.String 结构
常用操作
SET key value //存入字符串键值对
MSET key value [key value …] //批量存储字符串键值对
SETNX key value //存入一个不存在的字符串键值对
GET key //获取一个字符串键值
MGET key [key …] //批量获取字符串键值
DEL key [key …] //删除一个键
EXPIRE key seconds //设置一个键的过期时间(秒)
原子加减
INCR key //将key中储存的数字值加1
DECR key //将key中储存的数字值减1
INCRBY key increment //将key所储存的值加上increment
DECRBY key decrement //将key所储存的值减去decrement
应用场景
1.单值缓存
比如:在分布式项目中需要一个统一的鉴权和授权中心将相应的算法生成token,而token本身就是单个字符串,这样完全可以利用Redis中的String数据类型来实现。
2.对象缓存
用户信息可能是一个对象或者高频率访问但是很少修改的数据,这些数据可以作为一个整体对象,如果想要减轻数据库访问的压力,那么可以将其对象进行json序列化后缓存起来。这样的数据可以采用String数据类型进行存储。
两种方式:
1.将对象一次性转换成json序列化进行存储
2.利用mset、mget同时设置多个键、获取多个键的值(只适合使用对象某个属性值的场景)
3.计数器
比如:在双十一或者其他大型节日,业务服务器资源有限,但在高并发场景下,过多请求可能会导致服务器宕机等问题,所以会对接口请求做一些限制,比如 限制每秒请求总数为200次,超过200次就等待,等下一秒再次请求,这里用Redis作为计数器的模式来实现:
1)首先在接到请求之后设置一个键,然后自增1,如果不存在,则值会被初始化为0。
incr mykey #第一次执行返回的结果是1
这里的mykey可能需要特殊处理,因为是根据秒来的,所以当接口得到一个请求之后,应该获取当前时间生成动态的键,如20230529235959:mykey。
2)当接口得到请求后,执行incr yyyyMMddHHmmss:mykey,如果返回结果小于200则进行处理,超过200将等待下一秒处理。
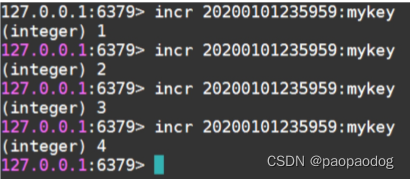
3)因为每秒会生成一个键,为了节省内存空间,可能需要一个定时任务,定时删除这些已经使用过的键。
4.分布式系统全局序列号
每台机器分配1000个,存放在各自内存中,使用完再从redis获取1000个。
INCRBY orderId 1000 //redis批量生成序列号提升性能
只适合对id顺序要求不严格的场景,严格的话还需要雪花算法
5.文章阅读数或者网页浏览数统计
INCR article:readcount:{文章id}
GET article:readcount:{文章id}
6.分布式锁
SET product:10001 true ex 20 nx //创建锁的同时设置锁过期时间保证原子性,防止程序意外终止导致死锁,到期后键自动删除
。。。执行业务操作
SETNX product:10001 true ex 20 nx //其他客户端尝试加锁命令,返回0则表示锁被占用,只能后期继续尝试再执行返回0代表获取锁失败
2.Hash结构
常用操作
HSET key field value //存储一个哈希表key的键值
HSETNX key field value //存储一个不存在的哈希表key的键值
HMSET key field value [field value …] //在一个哈希表key中存储多个键值对
HGET key field //获取哈希表key对应的field键值
HMGET key field [field …] //批量获取哈希表key中多个field键值
HDEL key field [field …] //删除哈希表key中的field键值
HLEN key //返回哈希表key中field的数量
HGETALL key //返回哈希表key中所有的键值
HINCRBY key field increment //为哈希表key中field键的值加上增量increment
相较于String类型
优点
- 同类数据归类整合储存,方便数据管理;
- 相比string操作消耗内存与cpu更小;
- 相比string储存更节省空间;
缺点
- 过期功能不能使用在field上,只能用在key上
- Redis集群架构下不适合大规模使用,容易造成数据倾斜,需要hash散列
应用场景
1.电商购物车
比如:以每个用户的userid作为Redis的键(Key),每个用户的购物车都是一个哈希表,它存储了商品ID与商品订购数量之间的映射关系。在商品的订购数量出现变化时,操作Redis哈希对购物车进行更新。
1)以用户id为key
2)商品id为field
3)商品数量为value
添加商品hset userid:1001 10088 1
增加数量hincrby userid:1001 10088 1
商品总数hlen userid:1001
删除商品hdel userid:1001 10088
获取购物车所有商品hgetall userid:1001
2.计数器
Hash常被用于记录网站一天、一月、一年的访问数量。每次访问,在对应的field上自增1即可。比如:
// 记录博客文章每月的访问量
hincrby myBlog 202305 1
hincrby myBlog 202305 1
hincrby myBlog 202305 1
hincrby myBlog 202405 1
// 记录商品的好评量、差评量
hincrby pid:1 Good 1
hincrby pid:1 Good 1
hincrby pid:1 bad 1
// 记录实时在线人数
// 登录
hincrby mySite 20230501 1
hincrby mySite 20230501 1
// 退出
hincrby mySite 20230501 -1
3.List结构
常用操作
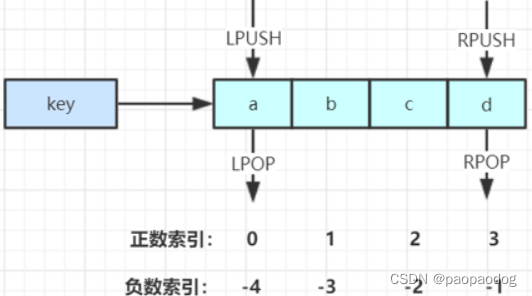
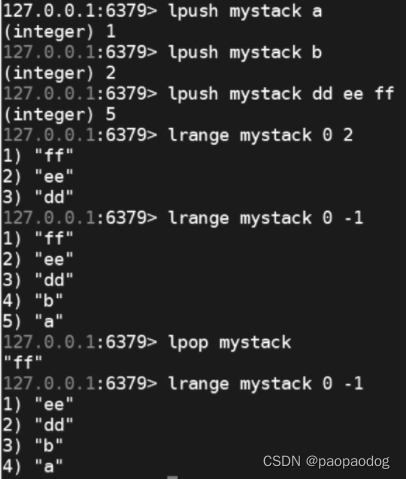
LPUSH key value [value …] //将一个或多个值value插入到key列表的表头(最左边)
RPUSH key value [value …] //将一个或多个值value插入到key列表的表尾(最右边)
LPOP key //移除并返回key列表的头元素
RPOP key //移除并返回key列表的尾元素
LRANGE key start stop //返回列表key中指定区间内的元素,区间以偏移量start和stop指定
BLPOP key [key …] timeout //从key列表表头弹出一个元素,若列表中没有元素,阻塞等待 timeout秒,如果timeout=0,一直阻塞等待
BRPOP key [key …] timeout //从key列表表尾弹出一个元素,若列表中没有元素,阻塞等待 timeout秒,如果timeout=0,一直阻塞等待
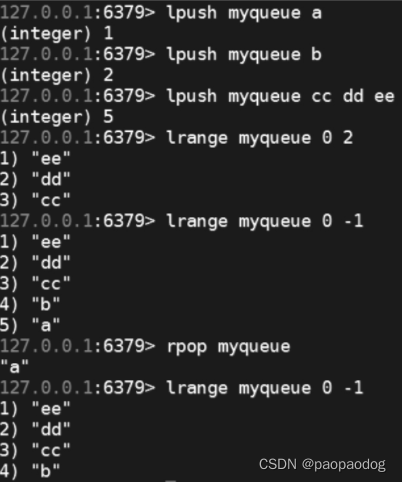
模拟数据结构
-
Stack(栈) :先进后出 ,LPUSH + LPOP 操作
-
Queue(队列):先进先出 , LPUSH + RPOP 操作
-
Blocking MQ(阻塞队列): LPUSH + BRPOP 操作
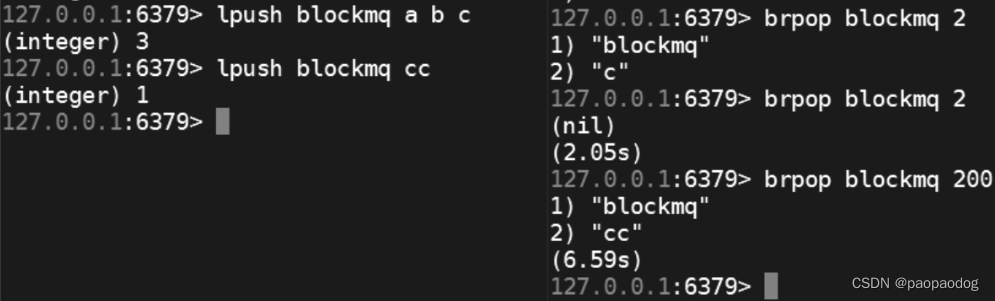
BRPOP是一个包含两个元素的数组(还包含键的名称),brpop和blpop通过阻塞方式等待来自多个列表的元素
应用场景
1.微博和微信公号消息流
我关注了大V1和大V2
1)大V1发微博,消息ID为10018
LPUSH msg:{我userid} 10018
2)大V2发微博,消息ID为10086
LPUSH msg:{我userid} 10086
3)查看最新微博消息
LRANGE msg:{我userid} 0 4
如果每次分页获取的文章数较多,就需要执行多次hgetall操作,此时可以考虑使用Pipeline批量获取,或者考虑将文章数据序列化为字符串类型,然后使用mget批量获取。
在我们访问任何一个网站时,并发最高的可能就是网站的首页,如果首页是列表类信息,那么完全可以使用List来实现。
但是如果数据量特别大,可以把标题和当前文章的ID主键存储在Redis的List中,当用户点击当前文章并需要查看详情的时候,结合主键ID再去数据库中查询。
4.Set结构
常用操作
SADD key member [member …] //往集合key中存入元素,元素存在则忽略,若key不存在则新建
SREM key member [member …] //从集合key中删除元素
SMEMBERS key //获取集合key中所有元素
SCARD key //获取集合key的元素个数
SISMEMBER key member //判断member元素是否存在于集合key中
SRANDMEMBER key [count] //从集合key中选出count个元素,元素不从key中删除
SPOP key [count] //从集合key中选出count个元素,元素从key中删除
运算操作
SINTER key [key …] //交集运算
SINTERSTORE destination key [key …] //将交集结果存入新集合destination中
SUNION key [key …] //并集运算
SUNIONSTORE destination key [key …] //将并集结果存入新集合destination中
SDIFF key [key …] //差集运算
SDIFFSTORE destination key [key …] //将差集结果存入新集合destination中
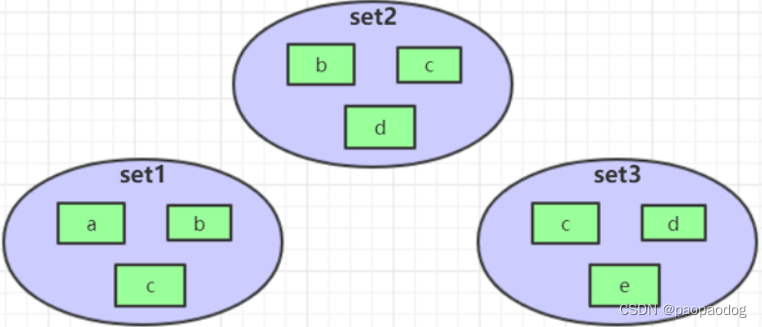
SINTER set1 set2 set3 -> { c } //交集
SUNION set1 set2 set3 -> { a,b,c,d,e } //并集
SDIFF set1 set2 set3 -> { a } //差集,第一个集合减去后面集合的并集
集合类型和列表类型的区别
- 列表可以存储重复元素,集合默认去重
- 列表顺序存储,而集合是无序存储
- 列表和集合都支持增、删、改、查,同时集合还支持取多个集合的交集、并集、差集
应用场景
1.微信抽奖小程序

1)点击参与抽奖加入集合 SADD key {userlD}
2)查看参与抽奖所有用户 SMEMBERS key
3)随机抽取count名中奖者 SRANDMEMBER key [count] / SPOP key [count]
2.微信微博点赞,收藏,标签
- 点赞 SADD like:{消息ID} {用户ID}
- 取消点赞 SREM like:{消息ID} {用户ID}
- 检查用户是否点过赞 SISMEMBER like:{消息ID} {用户ID}
- 获取点赞的用户列表 SMEMBERS like:{消息ID}
- 获取点赞用户数 SCARD like:{消息ID}
3.集合操作实现微博微信关注模型

- 预设条件:
- 我关注的人: meSet -> {bigV1, bigV2}
- 大V1关注的人: bigV1Set -> {me,bigV2,bigV3,bigV4}
- 大V2关注的人: bigV2Set -> {me,bigV1,bigV5,bigV6)
- 查询:
- 我和大V1共同关注的人: SINTER meSet bigV1Set -> {bigV2}
- 我关注的人也关注他(大V1):
SISMEMBER bigV2Set bigV1
SISMEMBER bigV5Set bigV1 - 我可能想认识的人: SDIFF bigV1Set meSet ->(me,bigV3,bigV4}
4.实现电商商品筛选

预设条件:
SADD brand:huawei P40
SADD brand:xiaomi mi-10
SADD brand:iPhone iphone12
SADD os:android P40 mi-10
SADD cpu:brand:intel P40 mi-10
SADD ram:8G P40 mi-10 iphone12
查询:安卓系统、英特尔cpu、8G存储
SINTER os:android cpu:brand:intel ram:8G -> {P40,mi-10} //得到交集
5.ZSet有序集合结构
常用操作
ZADD key score member [[score member]…] //往有序集合key中加入带分值元素
ZREM key member [member …] //从有序集合key中删除元素
ZSCORE key member //返回有序集合key中元素member的分值
ZINCRBY key increment member //为有序集合key中元素member的分值加上increment
ZCARD key //返回有序集合key中元素个数
ZRANGE key start stop [WITHSCORES] //正序获取有序集合key从start下标到stop下标的元素
ZREVRANGE key start stop [WITHSCORES] //倒序获取有序集合key从start下标到stop下标的元素
集合操作
ZUNIONSTORE destkey numkeys key [key …] //并集计算
ZINTERSTORE destkey numkeys key [key …] //交集计算
应用场景
1.Zset集合操作实现排行榜

1)点击新闻 ZINCRBY hotNews:20230501 1 xxxx
2)展示当日排行前十 ZREVRANGE hotNews:20230501 0 9 WITHSCORES
3)七日搜索榜单计算 ZUNIONSTORE hotNews:20230425-20230501 7 hotNews:20230425 hotNews:20230426 … hotNews:20230501
//创建7个key,做并集处理
4)展示七日排行前十 ZREVRANGE hotNews:20230425-20230501 0 9 WITHSCORES
6.HyperLogLog
常用操作
pfadd key element [element …] //添加元素,添加成功返回 1
pfcount key [key …] //计算一个或多个 HyperLogLog 独立总数
pfmerge destkey sourcekey [sourcekey … ] //求出多个 HyperLogLog 的并集并赋值给 destkey
与集合类型占用空间对比
| 数据类型 | 1 天 | 1 月 | 1 年 |
|---|---|---|---|
| 集合类型 | 80M | 2.4G | 28G |
| HyperLogLog | 15k | 450k | 5M |
HyperLogLog基于概率论中伯努利试验并结合了极大似然估算方法,并做了分桶优化。
提供不精确的去重计数方案,官方给出标准误差是 0.81%
应用场景
1统计网页每天的 UV 数据
(后续待增加)
















 120
120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











