






前言
共享内存的存在可以帮助我们更快速的写入和读取数据,缩短进程时间,以矩阵转置为例,记录一些自己的学习笔记。
一、参考链接
老规矩列出本文的参考链接:
CUDA - CUDA C/C++中的高效矩阵转置_cuda实现矩阵转置-CSDN博客
CUDA学习之共享内存和常量内存--part2-CSDN博客
二、矩阵转置
1.一些概念
①cuda的概念
在main函数中定义的grid和block:
int main(int argc,char** argv)
{
printf("strating...\n");
initDevice(0);
int nx=1<<12;
int ny=1<<12;
int dimx=BDIMX;
int dimy=BDIMY;
int nxy=nx*ny;
int nBytes=nxy*sizeof(float);
int transform_kernel=0;
if(argc==2)
transform_kernel=atoi(argv[1]);
if(argc>=4)
{
transform_kernel=atoi(argv[1]);
dimx=atoi(argv[2]);
dimy=atoi(argv[3]);
}
//Malloc
float* A_host=(float*)malloc(nBytes);
float* B_host_cpu=(float*)malloc(nBytes);
float* B_host=(float*)malloc(nBytes);
initialData(A_host,nxy);
//cudaMalloc
float *A_dev=NULL;
float *B_dev=NULL;
CHECK(cudaMalloc((void**)&A_dev,nBytes));
CHECK(cudaMalloc((void**)&B_dev,nBytes));
CHECK(cudaMemcpy(A_dev,A_host,nBytes,cudaMemcpyHostToDevice));
CHECK(cudaMemset(B_dev,0,nBytes));
// cpu compute
double iStart=cpuSecond();
transformMatrix2D_CPU(A_host,B_host_cpu,nx,ny);
double iElaps=cpuSecond()-iStart;
printf("CPU Execution Time elapsed %f sec\n",iElaps);
// 2d block and 2d grid
dim3 block(dimx,dimy);
dim3 grid((nx-1)/block.x+1,(ny-1)/block.y+1);
这里用nx和ny,定义了一个2^12x2^12的矩阵;
下面用dim3定义了一个8x8的block(BDIMX和BDIMY在代码开始宏定义的);
下面的grid被定义为512x512;
也就是说block的维度为8x8个thread,grid的尺寸为512x512个block,
那么一共含有乘起来的thread(我实在是有点懒得画图)
那么每个block负责转置2^6x2^6的数据块
也就是每个thread负责1个元素
②矩阵和线程
在这个表格中,每一个单元格表示一个元素,单元格中的值(行索引, 列索引)表示该元素在矩阵中的位置。例如,(0,0)表示矩阵中第0行第0列的元素,(3,3)表示矩阵中第3行第3列的元素。
表1
| 列0 | 列1 | 列2 | 列3 | |
|---|---|---|---|---|
| 行0 | (0,0) | (0,1) | (0,2) | (0,3) |
| 行1 | (1,0) | (1,1) | (1,2) | (1,3) |
| 行2 | (2,0) | (2,1) | (2,2) | (2,3) |
| 行3 | (3,0) | (3,1) | (3,2) | (3,3) |
-----------------------
假设我们有一个2维的线程块,大小为32x32,那么我们可以用threadIdx.x和threadIdx.y来表示线程块中的每一个线程。例如,线程块的左上角的线程的索引为(0,0),右下角的线程的索引为(31,31)。
下面是一个简单的表格来表示这个32x32的线程块:
表2
| 0 | 1 | 2 | … | 31 | |
|---|---|---|---|---|---|
| 0 | (0,0) | (0,1) | (0,2) | … | (0,31) |
| 1 | (1,0) | (1,1) | (1,2) | … | (1,31) |
| 2 | (2,0) | (2,1) | (2,2) | … | (2,31) |
| … | … | … | … | … | … |
| 31 | (31,0) | (31,1) | (31,2) | … | (31,31) |
在这个表格中,每一个单元格表示一个线程,单元格中的值(threadIdx.x, threadIdx.y)表示该线程的索引。
-----------
如果你使用tile[threadIdx.x][threadIdx.y]这种方式来访问数据,那么线程索引的表格将会是按列来取数据。在这种情况下,一个32x32的线程块的线程索引表格可能如下所示:
表3
| 列0 | 列1 | 列2 | … | 列31 | |
|---|---|---|---|---|---|
| 行0 | (0,0) | (1,0) | (2,0) | … | (31,0) |
| 行1 | (0,1) | (1,1) | (2,1) | … | (31,1) |
| 行2 | (0,2) | (1,2) | (2,2) | … | (31,2) |
| … | … | … | … | … | … |
| 行31 | (0,31) | (1,31) | (2,31) | … | (31,31) |
在这个表格中,每一个单元格表示一个线程,单元格中的值(threadIdx.y, threadIdx.x)表示该线程的索引。例如,(0,0)表示线程块中第0列第0行的线程,(31,31)表示线程块中第31列第31行的线程。

表3对应的是tile[threadIdx.y][threadIdx.x];对应红框,无冲突,一个事务完成。行主序
表2对应的是tile[threadIdx.x][threadIdx.y];对应绿框,全部冲突;列主序
2.串行转置
代码如下:
void transformMatrix2D_CPU(float * in,float * out,int nx,int ny)
{
for(int j=0;j<ny;j++)
{
for(int i=0;i<nx;i++)
{
out[i*nx+j]=in[j*nx+i];
}
}
}用aij来表示矩阵中的元素,其中i表示行,j表示列。
那么,对于一个3x4的输入矩阵in,我们可以表示为:
in = [[a_{00}, a_{01}, a_{02}, a_{03}],
[a_{10}, a_{11}, a_{12}, a_{13}],
[a_{20}, a_{21}, a_{22}, a_{23}]]
当i和j分别等于0, 1, 2, 3时,已知nx=3,ny=4,我们可以看到转置的过程:
- 当
i=0, j=0时,out[0*3+0] = in[0*4+0],即out00=a00。 - 当
i=0, j=1时,out[1*3+0] = in[0*4+1],即out10=a01。 - 当
i=0, j=2时,out[2*3+0] = in[0*4+2],即out20=a02。 - 当
i=0, j=3时,out[3*3+0] = in[0*4+3],即out30=a03。
以此类推,我们可以得到转置后的输出矩阵out:
out = [[a_{00}, a_{10}, a_{20}],
[a_{01}, a_{11}, a_{21}],
[a_{02}, a_{12}, a_{22}],
[a_{03}, a_{13}, a_{23}]]3.并行基础矩阵转置
代码如下:
__global__ void transformNaiveRow(float * in,float * out,int nx,int ny)
{
int ix=threadIdx.x+blockDim.x*blockIdx.x;
int iy=threadIdx.y+blockDim.y*blockIdx.y;
int idx_row=ix+iy*nx;
int idx_col=ix*ny+iy;
if (ix<nx && iy<ny)
{
out[idx_col]=in[idx_row];
}
}假设我们有一个3x4的输入矩阵in,我们可以表示为:
in = [[a_{00}, a_{01}, a_{02}, a_{03}],
[a_{10}, a_{11}, a_{12}, a_{13}],
[a_{20}, a_{21}, a_{22}, a_{23}]]
对于每个线程,它首先计算出自己在矩阵中的位置(ix, iy),然后计算出输入矩阵和输出矩阵中对应的索引idx_row和idx_col。然后,如果(ix, iy)在矩阵的范围内,它就将输入矩阵中的元素复制到输出矩阵的对应位置。
例如,对于线程块尺寸为(1,1),网格尺寸为(3,4)的情况(同样保证每个线程处理一个数据),
当线程块索引(blockIdx.x, blockIdx.y)为(0,0),线程索引(threadIdx.x, threadIdx.y)为(0,0)时,我们有:
ix = 0 + 1*0 = 0iy = 0 + 1*0 = 0idx_row = 0 + 0*3 = 0idx_col = 0*4 + 0 = 0
所以,out_{00} = a_{00}。
当线程块索引(blockIdx.x, blockIdx.y)为(0,1),线程索引(threadIdx.x, threadIdx.y)为(0,0)时,我们有:
ix = 0 + 1*0 = 0iy = 0 + 1*1 = 1idx_row = 0 + 1*3 = 3idx_col = 0*4 + 1 = 1
所以,out_{10} = a_{01}。
当线程块索引(blockIdx.x, blockIdx.y)为(1,0),线程索引(threadIdx.x, threadIdx.y)为(0,0)时,我们有:
ix = 0 + 1*1 = 1iy = 0 + 1*0 = 0idx_row = 1 + 0*3 = 1idx_col = 1*4 + 0 = 4
所以,out_{01} = a_{10}。
当线程块索引(blockIdx.x, blockIdx.y)为(1,1),线程索引(threadIdx.x, threadIdx.y)为(0,0)时,我们有:
ix = 0 + 1*1 = 1iy = 0 + 1*1 = 1idx_row = 1 + 1*3 = 4idx_col = 1*4 + 1 = 5
所以,out_{11} = a_{11}。
以此类推,我们可以得到转置后的输出矩阵out:
out = [[a_{00}, a_{10}, a_{20}],
[a_{01}, a_{11}, a_{21}],
[a_{02}, a_{12}, a_{22}],
[a_{03}, a_{13}, a_{23}]]4.使用共享内存的矩阵转置
代码如下:
__global__ void transformSmem(float * in,float* out,int nx,int ny)
{
//引入共享内存
__shared__ float tile[BDIMY][BDIMX];
unsigned int ix,iy,transform_in_idx,transform_out_idx;
//计算当前grid中的thread的全局坐标
ix=threadIdx.x+blockDim.x*blockIdx.x;
iy=threadIdx.y+blockDim.y*blockIdx.y;
//利用transform_in_idx计算一维坐标
transform_in_idx=iy*nx+ix;
unsigned int bidx,irow,icol;
//bidx计算thread的一维block内坐标
bidx=threadIdx.y*blockDim.x+threadIdx.x;
irow=bidx/blockDim.y;
icol=bidx%blockDim.y;
ix=blockIdx.y*blockDim.y+icol;
iy=blockIdx.x*blockDim.x+irow;
transform_out_idx=iy*ny+ix;
if(ix<nx&& iy<ny)
{
tile[threadIdx.y][threadIdx.x]=in[transform_in_idx];
__syncthreads();
out[transform_out_idx]=tile[icol][irow];
}
}1、首先引入共享内存,根据二.1.2的介绍,需要把数组定义为行主序的访问2
2、计算一维全局坐标ix,iy(blockIdx.x表示的是当前线程所在的块(block)在网格中的位置,blockDim.x表示的是块的大小(即块中包含的线程数),threadIdx.x表示的是当前线程在块中的位置。因此,blockIdx.x * blockDim.x + threadIdx.x这个表达式实际上是在计算当前线程在整个grid中的位置。)
3、计算thread在当前block中的一维索引 bidx(threadIdx.y和threadIdx.x表示的是当前线程在线程块中的位置,blockDim.x表示的是线程块的宽度(即线程块的x维度上的线程数));
4、利用一维索引bidx求得在共享内存 tile 中的二维索引 irow 和 icol。(icol和irow是基于线程的线性索引bidx计算得出的。这种计算方式使得icol和irow能够在一个线程束中连续变化,从而优化内存访问。这是因为在CUDA中,我们通常让threadIdx.x在线程束中连续变化,以优化内存访问。如果你直接将icol替换为threadIdx.y,将irow替换为threadIdx.x,那么在一个线程束中,ix和iy的计算将不再保持连续性,这可能会导致内存访问效率降低)这一步将二维坐标映射到一维坐标。
应该注意的是此时的irow和icol已经用除和取余的方式有了一个小转置
5、利用ix和iy重新求得全局索引,让x去对应列,y对应行
6、输出一维索引transform_out_idx,串行代码中 out[i*nx+j]=in[j*nx+i];这里也是同理,按列写入数据原本应该是ny*ix+iy,但是上面是用ix表示的列,iy表示的行,所以交换了一下,所以对应的一维索引就变为 transform_out_idx = iy * ny + ix。
7、其实transform_in_idx就是从全局内存把输入的矩阵按照行读取数据,展开成一维的,存入数组in中(因为“我们所有的数据,结构体也好,数组也好,多维数组也好,所有的数据,在内存硬件层面都是一维排布的”)。计算出转置后的二维坐标对应的全局内存的一维位置
8、然后把in这个组的一维索引,以行主序复制到共享内存中的数组tile的对应位置中,
9、进行同步
10、将共享内存中的数据拷贝到全局内存中,每个线程将自己的索引值写入全局内存的相应位置
重点就是在位置的找寻上,
输入矩阵按照行读取到tile里
然后tile的列写到输出矩阵的行里
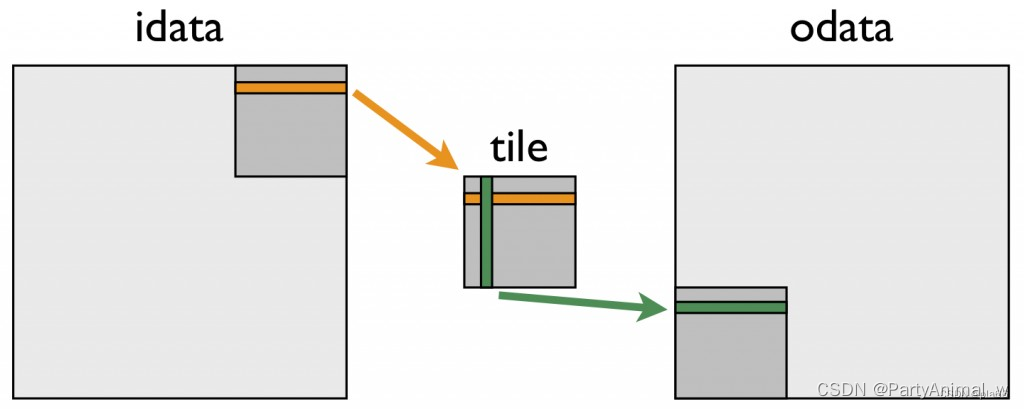
5.共享内存转置进阶
①bank冲突
为解决bank冲突,可以在定义tile时将维度设置为tile[BDIMY][BDIMX+IPAD]
②内存展开
将if语句进行循环展开
__global__ void transformSmemUnrollPad(float * in,float* out,int nx,int ny)
{
__shared__ float tile[BDIMY*(BDIMX*2+IPAD)];
//1.
unsigned int ix,iy,transform_in_idx,transform_out_idx;
ix=threadIdx.x+blockDim.x*blockIdx.x*2;
iy=threadIdx.y+blockDim.y*blockIdx.y;
transform_in_idx=iy*nx+ix;
//2.
unsigned int bidx,irow,icol;
bidx=threadIdx.y*blockDim.x+threadIdx.x;
irow=bidx/blockDim.y;
icol=bidx%blockDim.y;
//3.
unsigned int ix2=blockIdx.y*blockDim.y+icol;
unsigned int iy2=blockIdx.x*blockDim.x*2+irow;
//4.
transform_out_idx=iy2*ny+ix2;
if(ix+blockDim.x<nx&& iy<ny)
{
unsigned int row_idx=threadIdx.y*(blockDim.x*2+IPAD)+threadIdx.x;
tile[row_idx]=in[transform_in_idx];
tile[row_idx+BDIMX]=in[transform_in_idx+BDIMX];
//5
__syncthreads();
unsigned int col_idx=icol*(blockDim.x*2+IPAD)+irow;
out[transform_out_idx]=tile[col_idx];
out[transform_out_idx+ny*BDIMX]=tile[col_idx+BDIMX];
}
}总结
- 从全局内存读取数据(按行)写入共享内存(按行)
- 从共享内存读取一列写入全局内存的一行















 2467
2467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









