






前段时间leader让我选择一个东西深入研究下,我选择了Kafka,学习中以书籍为主,也在网上找了很多参考文献,其实Kafka主要就是网络通行和数据存储,更像是一个数据库,客户端的行为就是提交数据和获取数据,经过了一个月的陆陆续续的学历和文档整理,这次做一次整合怪,把总体的学习分享出来。下一步准备抽时间研究kafka源码。内容非常滴多,有兴趣的同学可以收藏起来慢慢看。
一 kafka摘要
Kafka摘要部分主要以摘取官方描述为主。主要包含了Kafka的设计定位,核心能力,生态以及Kafka的体系结构介绍,帮助读者对Kafka有一个总体的了解。
1.1 Kafka简介
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
--摘自Kafka官方
1.1.1 核心特性
1 HIGH THROUGHPUT(高吞吐量)
Deliver messages at network limited throughput using a cluster of machines with latencies as low as 2ms.
2 SCALABLE(可扩展)
Scale production clusters up to a thousand brokers, trillions of messages per day, petabytes of data, hundreds of thousands of partitions. Elastically expand and contract storage and processing.
3 PERMANENT STORAGE(持久化)
Store streams of data safely in a distributed, durable, fault-tolerant cluster.
4 HIGH AVAILABILITY(高可用)
Stretch clusters efficiently over availability zones or connect separate clusters across geographic regions.
1.1.2 Kafka生态
1 BUILT-IN STREAM PROCESSING
Process streams of events with joins, aggregations, filters, transformations, and more, using event-time and exactly-once processing.
2 CONNECT TO ALMOST ANYTHING
Kafka’s out-of-the-box Connect interface integrates with hundreds of event sources and event sinks including Postgres, JMS, Elasticsearch, AWS S3, and more.
3 CLIENT LIBRARIES
Read, write, and process streams of events in a vast array of programming languages.
4 LARGE ECOSYSTEM OPEN SOURCE TOOLS
Large ecosystem of open source tools: Leverage a vast array of community-driven tooling.
1.1.3 为什么是Kafka
1 MISSION CRITICAL(关键任务)
Support mission-critical use cases with guaranteed ordering, zero message loss, and efficient exactly-once processing.
2 TRUSTED BY THOUSANDS OF ORGS
Thousands of organizations use Kafka, from internet giants to car manufacturers to stock exchanges. More than 5 million unique lifetime downloads.
3 VAST USER COMMUNITY(强大的社区)
Kafka is one of the five most active projects of the Apache Software Foundation, with hundreds of meetups around the world.
4 RICH ONLINE RESOURCES
Rich documentation, online training, guided tutorials, videos, sample projects, Stack Overflow, etc.
1.2 Kafka体系结构
kafka的整体结构如下图,主要的元素包括消息,批次,主题,分区,生产者,消费者,偏移量,broker,集群以及保存Kafka元数据的zookeeper等。以下对他们分别做介绍
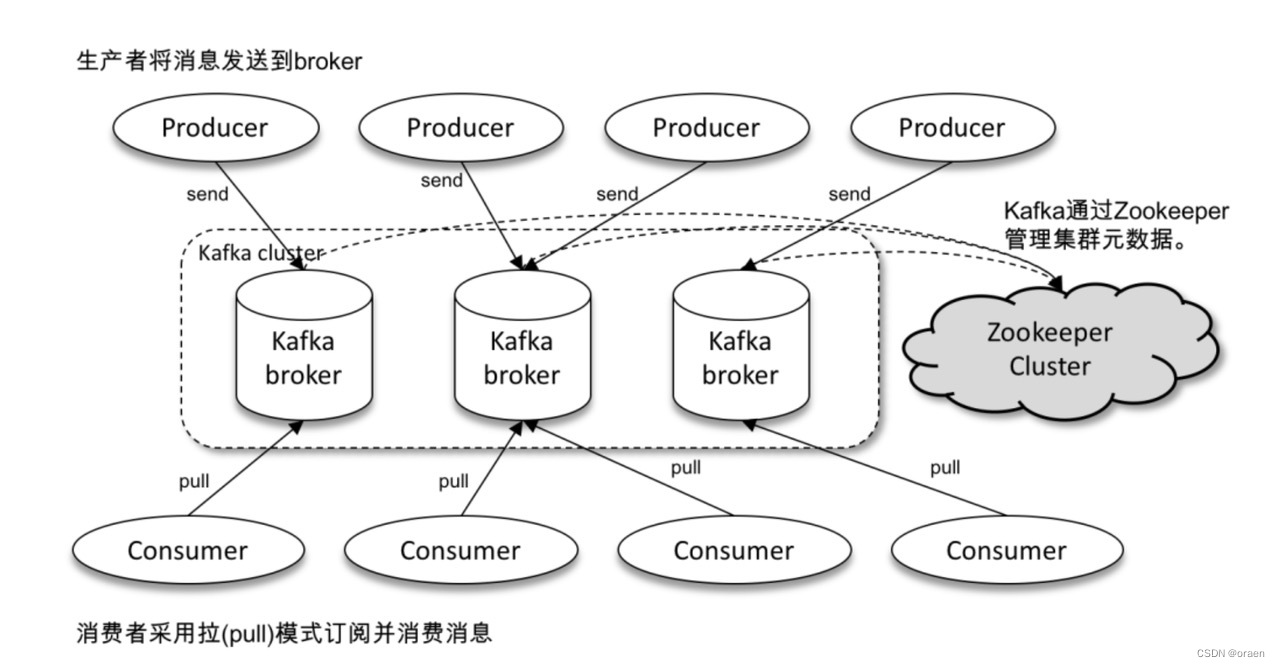
各个组件的官方介绍可参考https://kafka.apache.org/intro
1.2.1 消息和批次
Kafka的数据单元被称为消息,类似于数据库里的一条记录。消息可以有个可选的元数据也就是键,通过key可以用于控制消息落在哪一个分区(一般用在需要保证消费顺序时),或者业务上对消息进行标识等。为了提高效率,消息被分批次写入Kafka,批次就是一组消息,这些消息属于同一主题和分区。如果每 个消息都单独穿行于网络,会导致大的网络开销,把消息分成批次传输可以减少网络开销。不过,这要在时间延迟和吞吐量之间作出权衡:
1.2.2 主题和分区
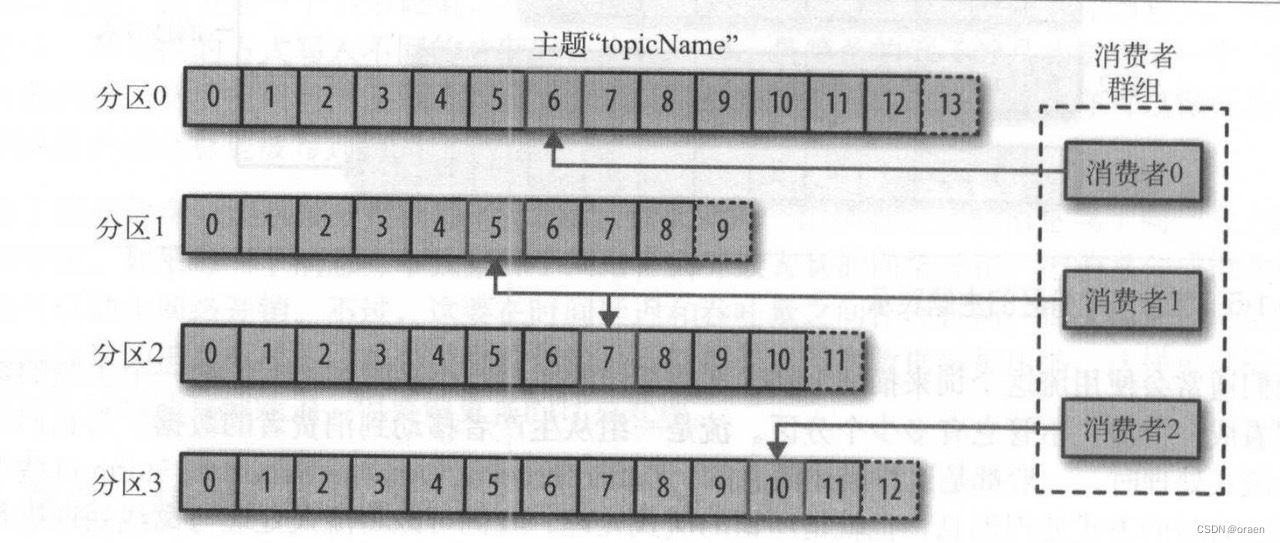
Kaflca 的消息通过主题进行分类。主题就好比数据库的表,或者文件系统里的文件夹。主题可以被分为若干个分区,一个分区就是一个提交日志。消息以追加的方式写入分区,然后以先入先出的顺序读取。要注意,由于一个主题一般包含几个分区,因此无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。下图所示的主题有4个分区,消息被追加写入到每个分区的尾部。 Kafka 通过分区来实现数据冗余和伸缩性。分区可以分布在不同的服务器上,也就是说, 一个主题可以横跨多个服务器,以此来提供比单个服务器更强大的性能。

1.2.3 生产者,消费,偏移量
Kaflca 的客户端就是 Kaflea 系统的用户,它们被分为两种基本类型 生产者和消费者。即使是Kafka管理客户端API内部也是集成了生产者和消费者组件。
生产者用于创建消息。一般情况下,一个消息会被发布到一个特定的主题上。生产者在默认情况下把消息均衡地分布到主题的所有分区上,而并不关心特定消息会被写到哪个分区。不过,在某些情况下,生产者会把消息直接写到指定的分区。这通常是通过消息键和分区器来实现的,分区器为消息的键生成一个散列值,并将其映射到指定的分区上。这样可以保证包含同一个键的消息会被写到同一个分区上。生产者也可以使用自定义的分区器,根据不同的业务规则将消息映射到分区。
消费者读取消息。消费者订阅一个或多个主题,并按照消息生成的顺序读取它们。消费者通过检查消息的偏移量来区分已经读取过的消息。
偏移量属于一种元数据(属于消费者组和分区共同的元数据),它是个不断递增的整数值,在创建消息时, Kafka 会把它添加到消息里。在给定的分区里,每个消息的偏移量都是唯一的。消费者把每个分区最后读取的悄息偏移量保存Zookeeper(老版本)或者Kafka(新版本)上,这样当消费者关闭或重启的时候,它的读取状态不会丢失。
消费者是消费者组的一部分,会有一个或多个消费者共同读取一个主题,Kafka在同一个消费者组中保证每个分区只能被一个消费者使用 。下图所示的消费者组中,两个消费者各自读取一个分区,另外一个消费者读取其他两个分区。而不会出现多个消费者读取同一个分区的情况,消费者与分区之间的映射通常被称为消费者对分区的所有权关系,通过这种方式,消费者可以消费包含大量消息的主题。而且,如果 个消费者失效,群组里的其他消费者可以接管失效悄费者的工作。
1.2.4 broker和集群
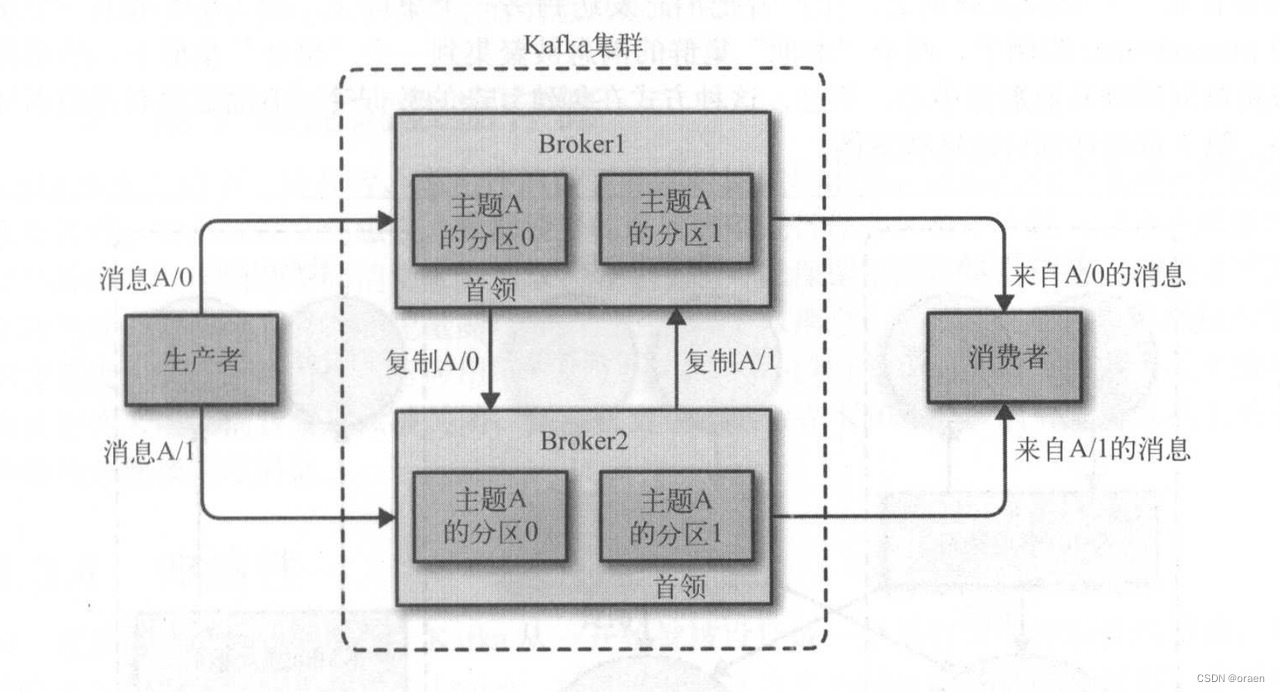
一个独立的 Kafka 服务器被称为broker, broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。broker为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。根据特定的硬件及其性能特征(顺序IO的读写速度其实很快),单个 broker 可以轻松处理数千个分区以及每秒百万级的消息量。
broker 是集群的组成部分。每个集群都有一个broker同时充当了集群控制器的角色(自动从集群的活跃成员中选举出来)。控制器负责管理工作,包括将分区分配给broker以及监控broker.。在集群中,一个分区从属于一个broker, 这个broker被称为这个分区的首领。一个分区可以分配给多个 broker,这个时候会发生分区复制。这种复制机制为分区提供了消息冗余,如果有一个 broker 失效,其他 broker 可以接管领导权。不过,相关的消费者和生产者都要重新连接到新的首领。
1.2.5 多集群
随着 Kafka 部署数量的增加,往往会出现数据类型分离,安全需求隔离,多数据中心(灾难恢复)等需求。最好的建议是使用多个集群。
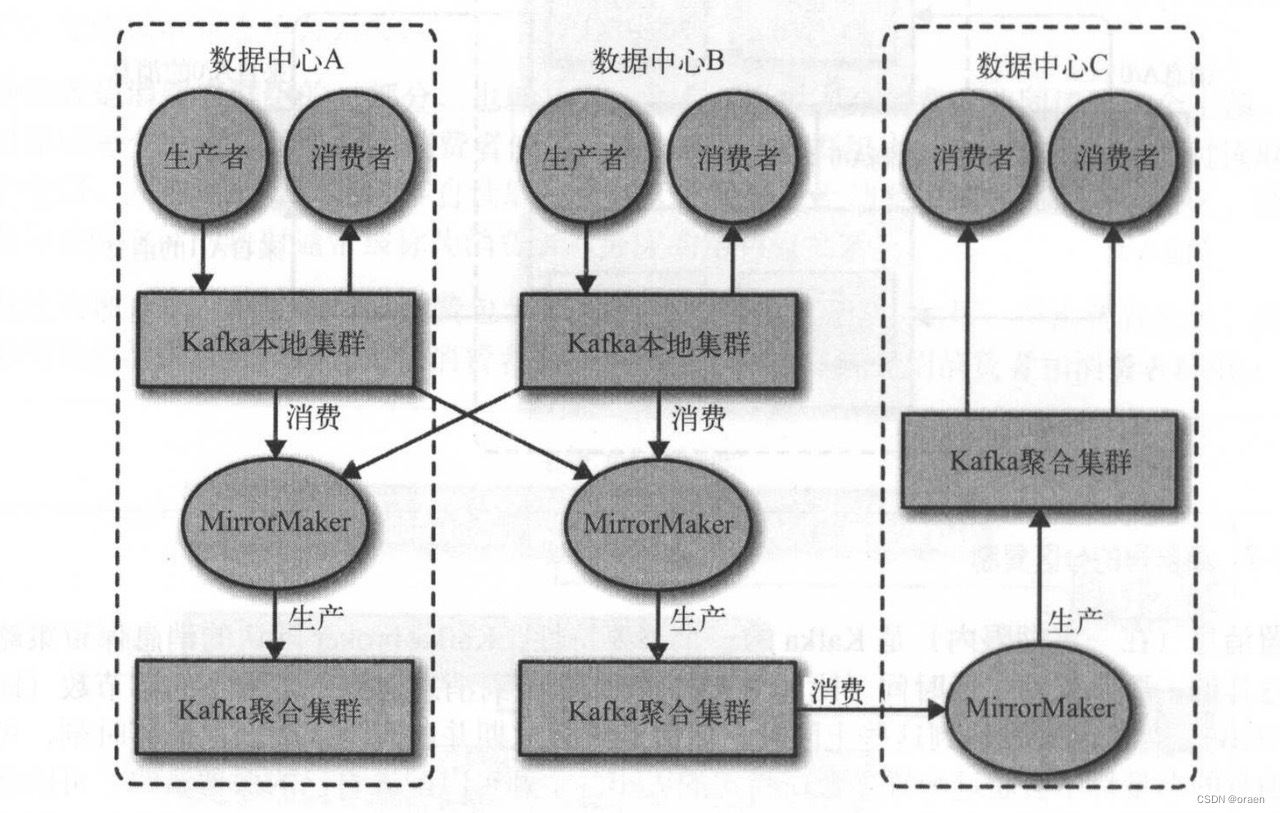
如果使用多个数据中心,就需要在它们之间复制消息。这样,在线应用程序才可以访问到多个姑点的用户活动信息。例如,如果一个用户修改了他的资料信息,不管从哪个数据中心都应该能看到这些改动。或者多个站点的监控数据可以被聚集到一个部署了分析程序和告警系统的中心位置。不过, Kafka 的消息复制机制只能在单个集群里进行,不能在多个集群之间进行。
Kafka 提供了 个叫作 Mirror Maker 的工具,可以用它来实现集群间的消息复制。Mirror Maker 的核心组件包含了一个生产者和一个消费者,两者之间通过一个队列相连。消费者从一个集群读取消息,生产者把消息发送到另一个集群上。下图展示了一个使MirrorMaker 的例子,两个“本地”集群的消息被聚集到一个“聚合”集群上,然后将该集群复制到其他数据中心。不过,这种方式在创建复杂的数据管道方面显得有点力不从心
。
1.3 Kafka官方及社区资源
官网:https://kafka.apache.org
GitHub:https://github.com/apache/kafka
Kafka 开发者邮件组社区:dev@kafka.apache.org
二 kafka通信
Kafka作为一个事件流平台,本质上就是提供了客户端往Kafka提交事件流(称为生产者客户端)和读取事件流(称为消费者客户端)的能力。这样便存在客户端和Kafka通信的问题,本章节讲解Kafka的通信部分的设计,包括Kafka的通信模型,协议以及流程梳理等。
2.1 Kafka通信模型
2.1.1 Kafka的通信模型设计
Kafka中的网络模型是基于NIO的主从Reactor多线程模型进行设计的,主从Reactor多线程模型大体如下
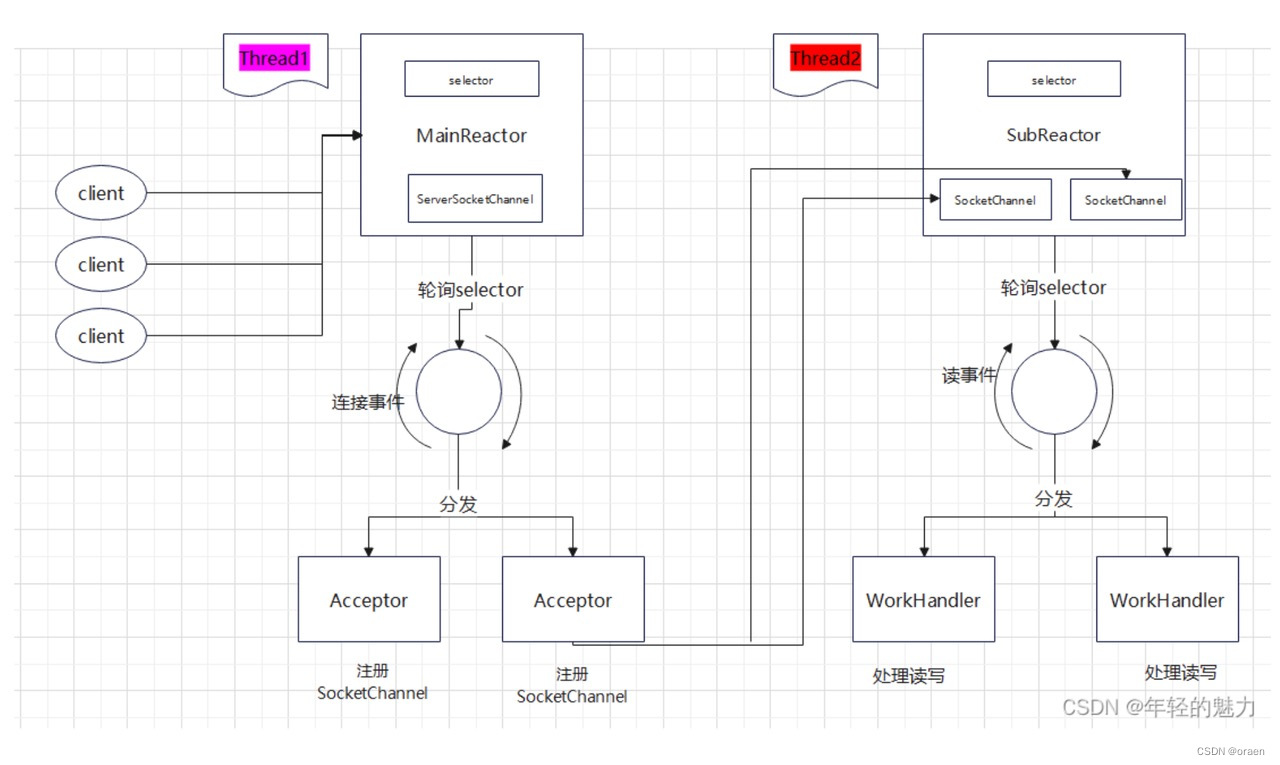
Kafka并没有使用第三方网络框架,而且自己基于java nio封装的,主要采用了 1(1个Acceptor线程)+N(N个Processor线程)+M(M个业务处理线程) 总体网络模型如下
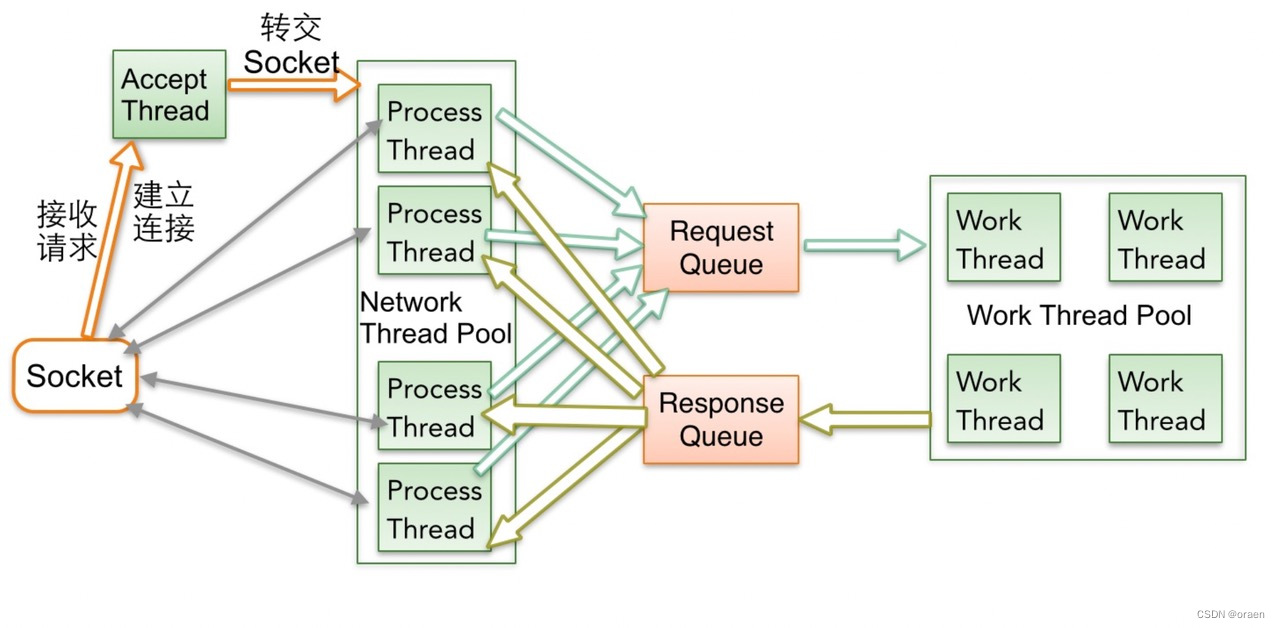
1 Accept Thread负责与客户端建立连接链路,然后把Socket轮转交给Process Thread
2 Process Thread负责接收请求和响应数据,Process Thread每次基于Selector事件循环,首先从Response Queue读取响应数据,向客户端回复响应,然后接收到客户端请求后,读取数据放入Request Queue
3 Work Thread负责业务逻辑、IO磁盘处理等,负责从Request Queue读取请求,并把处理结果放入Response Queue中,待Process Thread发送出去
2.1.1 Kafka的通信流程梳理
Kafka处理网络请求的大体流程图如下
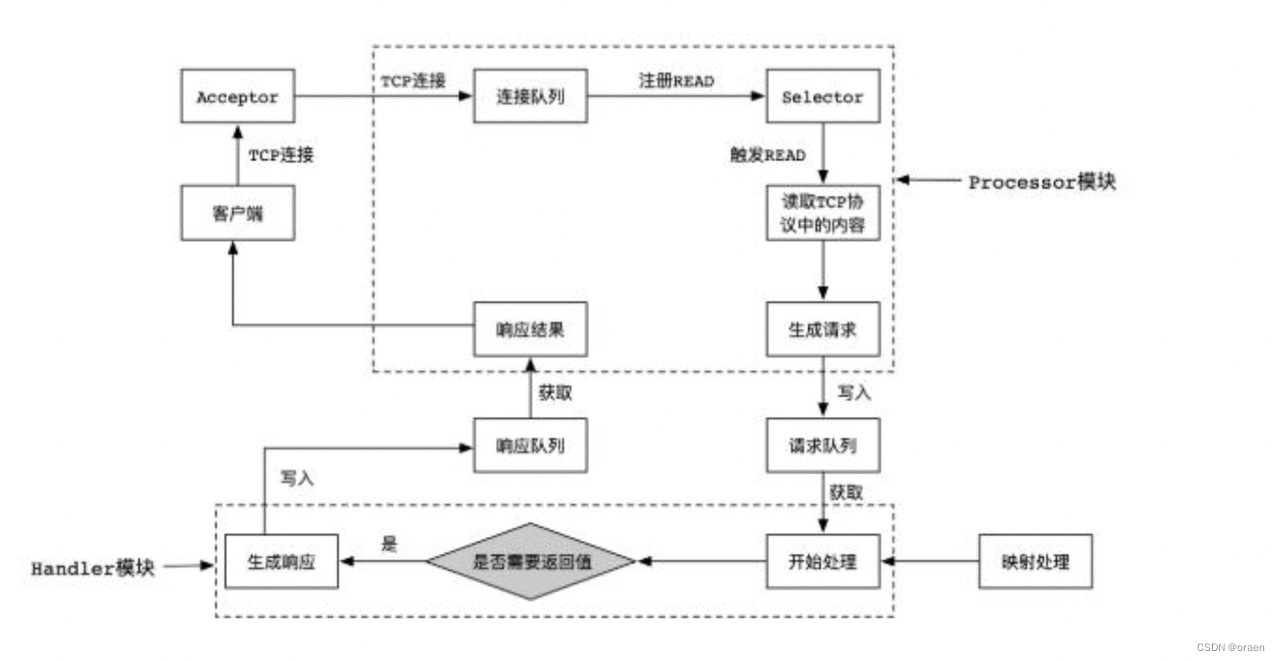
1 Client向Server发送请求时,Acceptor负责接收TCP请求,连接成功后传递给Processor线程
2 Processor线程接收到新的连接后,将其注册到自身的Selector中,并监听READ事件
3 当Client在当前连接对象上写入数据时,会触发READ事件,把请求数据放到请求队列RequestQueue上,Handler在请求队列获取请求进行处理
4 Handler处理完成后,可能会有返回值给Client,并将Handler返回的结果绑定请求,然后放到返回队列ResponseQueue上, Processor线程在返回队列获取处理结果返回给客户端
2.2 Kafka通信协议
2.2.1 数据类型和结构
kafka的通讯协议是基于tcp之上的二进制协议,所有类型的请求和响应都是结构化的,由不同的初始类型构成。初始类型大体上可以分为三类
-
定长数据类型:int8,int16,int32和int64,对应到Java中就是byte, short, int和long。
-
变长数据类型:bytes和string。变长的数据类型由两部分组成,分别是一个有符号整数N(表示内容的长度)和N个字节的内容。其中,N为-1表示内容为null。bytes的长度由int32表示,string的长度由int16表示。
-
数组:数组由两部分组成,分别是一个由int32类型的数字表示的数组长度N和N个元素。
。
所有的请求和响应都具有统一的格式,即size+Request/Response,其中的Size时int32表示的整数,协议内容总体表示如下。
| 名称 | 类型 | 描述 |
| MessageSize | int32 | 消息的大小(b) |
| RequestMessage/ResponseMessage | -- | 请求信息或者响应信息 |
RequestMessage的结构如下:
| 名称 | 类型 | 描述 |
| ApiKey | int16 | 表示这次请求的API编号 |
| ApiVersion | int16 | 表示请求的API的版本,有了版本后就可以做到后向兼容 |
| CorrelationId | int32 | 由客户端指定的一个数字唯一标示这次请求的id,服务器端在处理完请求后也会把同样的CorrelationId写到Response中,这样客户端就能把某个请求和响应对应起来了 |
| ClientId | string | 客户端指定的用来描述客户端的字符串,会被用来记录日志和监控,它唯一标示一个客户端。 |
| Request | Request的具体内容 |
ResponseMessage的结构如下
| 名称 | 类型 | 描述 |
| CorrelationId | int32 | 由客户端指定的一个数字唯一标示这次请求的id,服务器端在处理完请求后也会把同样的CorrelationId写到Response中,这样客户端就能把某个请求和响应对应起来了 |
| Response | string | 对应Request的Response,不同的Request的Response的字段是不一样的 |
Message
Kafka是一个分布式消息系统,Producer生产消息并推送(Push)给Broker,然后Consumer再从Broker那里取走(Pull)消息。Producer生产的消息就是由Message来表示的,对用户来讲,它就是键-值对,他的结构如图
| 名称 | 类型 | 描述 |
| CRC | int32 | 表示这条消息(不包括CRC字段本身)的校验码 |
| MagicByte | int8 | 表示消息格式的版本,用来做后向兼容,目前值为0 |
| Attributes | int8 | 表示这条消息的元数据,目前最低两位用来表示压缩格式 |
| Key | bytes | 表示这条消息的Key,可以为null |
| Value | bytes | 表示这条消息的Value。Kafka支持消息嵌套,也就是把一条消息作为Value放到另外一条消息里面 |
Message的Attribute的最低两位的值表示信息的压缩方式,因为单条消息中重复内容可能不多,所以通常把多条消息放在一起组成MessageSet,然后再把MessageSet放到一条Message里面去,这样MessageSet也能压缩了
Kafka的Message支持下面几种压缩方式,
| 压缩方式 | 编码 |
| 不压缩 | 0 |
| Gzip | 1 |
| Snappy | 2 |
| LZ4 | 3 |
MessageSet
MessageSet用来组合多条Message,它在每条Message的基础上加上了Offset和MessageSize,其结构是:
| 名称 | 类型 | 描述 |
| Offset | int64 | 它用来作为log中的序列号,Producer在生产消息的时候还不知道具体的值是什么,可以随便填个数字进去 |
| MessageSize | int32 | 表示这条Message的大小 |
| Message | 表示这条Message的具体内容,其格式见上一小节 |
2.2.2 byte协议
kafka协议规范图
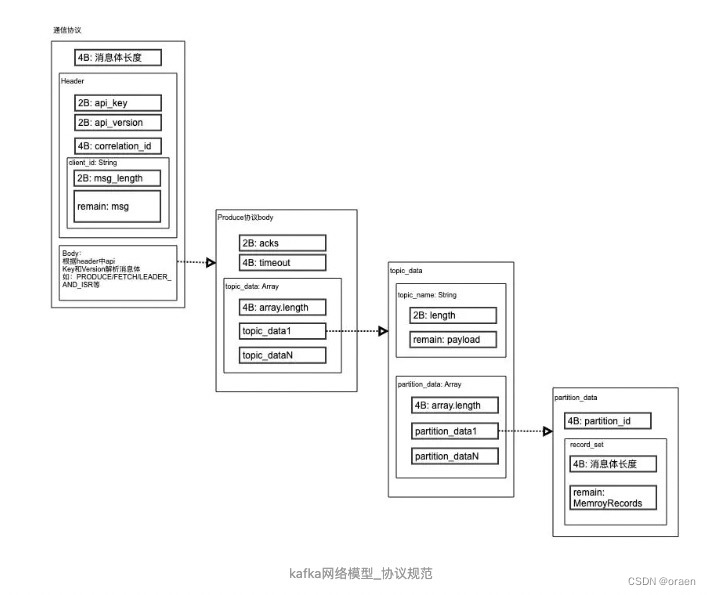
kafka接收到的数据内容格式如上图所示,可总结为如下的表示
-
4B: 整个数据的长度,最大为
2^31 - 1,超过socket.request.max.bytes则报错,默认是100M
-
Header
-
2B: api_key
-
2B: api_version,api_key+api_version,可以决定当前消息的协议,如Producer、Fetcher、LeaderAndISR等
-
4B: correlation_id,返回给客户端时携带
-
clientId: string
-
2B: string长度
-
remain: string具体内容
-
-
-
Body(Payload),根据不同的协议使用不同的解析方法,此处以
Produce协议为例-
2B: acks,写入的ack值,-1、0、1等,分别表示写入的可靠性要求
-
4B: timeout,表示此Produce请求的超时时间
-
topic_data[]: Array
-
4B: array长度
-
topic_data
-
topic_name: string
-
2B: string长度
-
remain: string具体内容
-
-
partition_data[]: Array
-
4B: array长度
-
partition_data
-
4B: partition_id
-
4B: 消息体长度
-
remain: MemoryRecords
-
-
-
-
-
2.3 Kafka通信实现
2.3.1 网络UML设计
//todo
2.3.2 核心元素介绍
网络通信层包括几个重要元素:SocketServer、Acceptor、Processor、RequestChannel和KafkaRequestHandler。
SocketServer
SocketServer是接收客户端Socket请求连接、处理请求并返回处理结果的核心类,Acceptor及Processor的初始化、处理逻辑都是在这里实现的。在KafkaServer实例启动时会调用其startup的初始化方法,会初始化1个 Acceptor和N个Processor线程(每个EndPoint都会初始化,一般来说一个Server只会设置一个端口)
Acceptor
Acceptor是一个继承自抽象类AbstractServerThread的线程类。Acceptor的主要任务是监听并且接收客户端的请求,同时建立数据传输通道—SocketChannel,然后以轮询的方式交给一个后端的Processor线程处理(具体的方式是添加socketChannel至并发队列并唤醒Processor线程处理)。
在该线程类中主要有两个重要的变量:
(1)nioSelector :通过NSelector.open()方法创建的变量,封装了JAVA NIO Selector的相关操作
(2)serverChannel :用于监听端口的服务端Socket套接字对象
Acceptor线程启动后,首先会向用于监听端口的服务端套接字对象—ServerSocketChannel上注册OP_ACCEPT 事件。然后以轮询的方式等待所关注的事件发生。如果该事件发生,则调用accept()方法对OP_ACCEPT事件进行处理。这里,Processor是通过 round robin(轮询调度) 方法选择的,这样可以保证后面多个Processor线程的负载基本均匀。
Acceptor的accept()方法的作用主要如下:
(1)通过SelectionKey取得与之对应的serverSocketChannel实例,并调用它的accept()方法与客户端建立连接
(2)调用connectionQuotas.inc()方法增加连接统计计数;并同时设置第(1)步中创建返回的socketChannel属性(如sendBufferSize、KeepAlive、TcpNoDelay、configureBlocking等)
(3)将socketChannel交给processor.accept()方法进行处理。这里主要是将socketChannel加入Processor处理器的并发队列newConnections队列中,然后唤醒Processor线程从队列中获取socketChannel并处理。其中,newConnections会被Acceptor线程和Processor线程并发访问操作,所以newConnections是ConcurrentLinkedQueue队列(一个基于链接节点的无界线程安全队列)
Processor
Processor同Acceptor一样,也是一个线程类,继承了抽象类AbstractServerThread。其主要是从客户端的请求中读取数据和将KafkaRequestHandler处理完响应结果返回给客户端。在该线程类中有以下几个重要的变量:
(1)newConnections :在上面的 Acceptor 一节中已经提到过,它是一种ConcurrentLinkedQueue[SocketChannel]类型的队列,用于保存新连接交由Processor处理的socketChannel
(2)inflightResponses :是一个Map[String, RequestChannel.Response]类型的集合,用于记录尚未发送的响应
(3)selector :是一个类型为KSelector变量,用于管理网络连接
Processor处理器线程run方法执行的流程如图所示:
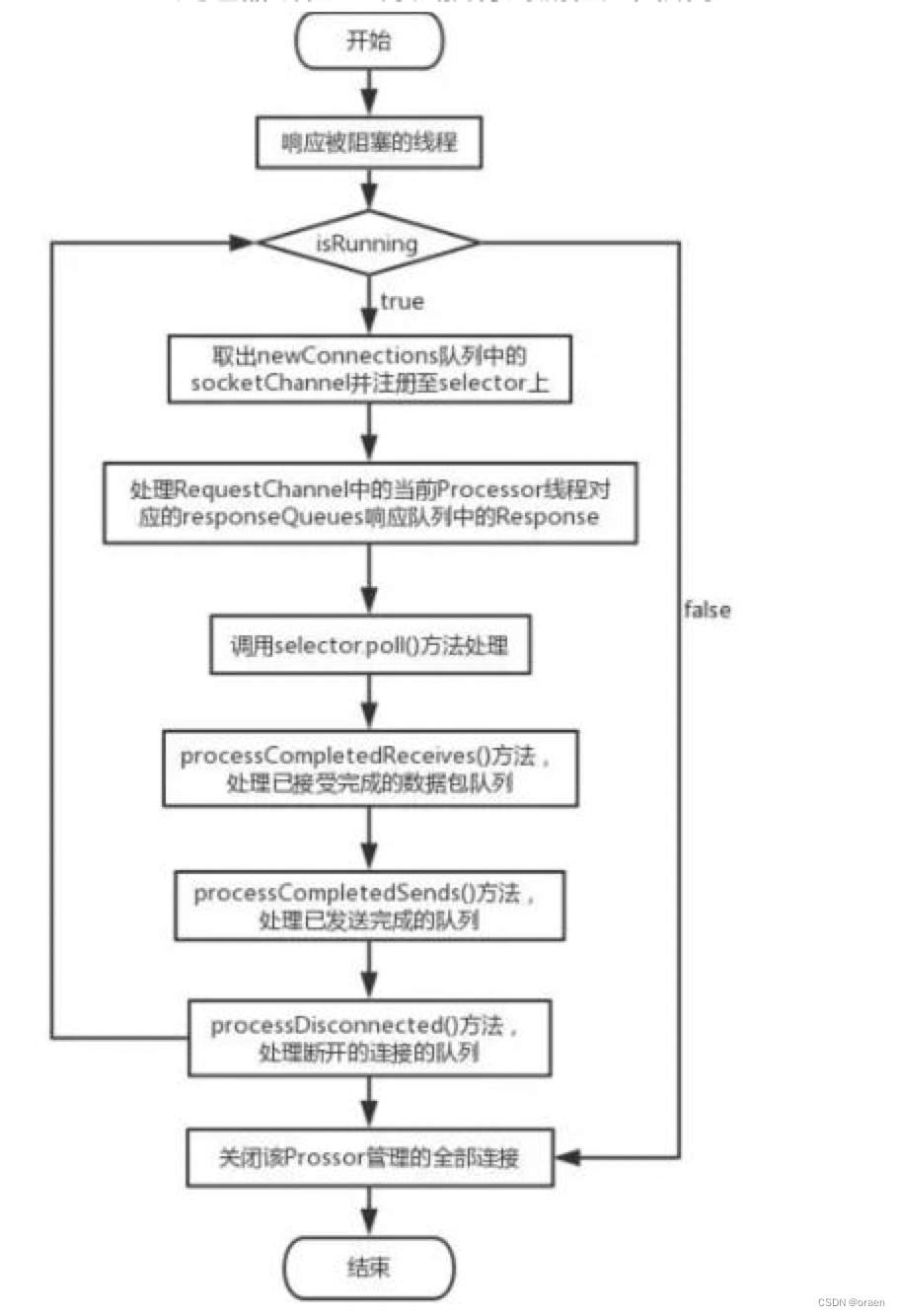
RequestChannel
在Kafka的网络通信层中,RequestChannel为Processor处理器线程与KafkaRequestHandler线程之间的数据交换提供了一个数据缓冲区,是通信过程中Request和Response缓存的地方。因此,其作用就是在通信中起到了一个数据缓冲队列的作用。Processor线程将读取到的请求添加至RequestChannel的全局请求队列—requestQueue中;KafkaRequestHandler线程从请求队列中获取并处理,处理完以后将Response添加至RequestChannel的响应队列—responseQueue中,并通过responseListeners唤醒对应的Processor线程,最后Processor线程从响应队列中取出后发送至客户端
KafkaRequestHandler
KafkaRequestHandler也是一种线程类,在KafkaServer实例启动时候会实例化一个线程池—KafkaRequestHandlerPool对象(包含了若干个KafkaRequestHandler线程),这些线程以守护线程的方式在后台运行。在KafkaRequestHandler的run方法中会循环地从RequestChannel中阻塞式读取request,读取后再交由KafkaApis来具体处理
有这样以下几点优势:
1 能够单独指定Handler的线程数,便于调优和管理
2 防止一个过大的请求阻塞一个Processor线程
3 Request、Handler、Response之间都是通过队列来进行连接的,这样它们彼此之间不存在耦合现象,对提升Kafka系统的性能很有帮助
KafkaApis
KafkaApis是用于处理对通信网络传输过来的业务消息请求的中心转发组件。该组件反映出Kafka Broker Server可以提供哪些服务
2.4 Kafka通信模拟实验
//todo
2.5 Kafka通信总结
1 Kafka的Producer、Broker和Consumer之间采用的是一套自行设计的基于TCP层的协议。Kafka的这套协议完全是为了Kafka自身的业务需求而定制的
2 kafka的通讯协议是基于tcp之上的二进制协议,所有类型的请求和响应都是结构化的,由不同的初始类型构成
3 Kafka中的网络模型是基于NIO的主从Reactor多线程模型进行设计的
三 Kafka存储
Kafka作为一个事件流平台,肯定是需要将生产者发送的数据进行存储的,本章节会对Kafka数据存储的方式和细节做一些介绍。
3.1 存储方式
3.1.1 存储概括和性能辩证
Kafka 依赖于文件系统来存储和缓存消息。数据都是存储在文件上的,绝大多数情况下来说也就是存储在硬盘上的,这可能让很多人感觉到奇怪,因为一说到Kafka,很多人脑海中想到的第一个词就是高吞吐量(这当然是需要高性能支撑的),而我们一说到硬盘,想到的可能就是慢,低效率。这明显和Kafka的特性不符合,事实上磁盘可以比我们预想的要快,也可能比我们预想的要慢,这完全取决于我们如何使用它。有关测试结果表明,一个由6块 7200r/min 的 RAID-5 阵列组成的磁盘簇的线性(顺序)写入速度可以达到 600MB/s,而随机写入速度只有 100KB/s,两者性能相差6000倍。操作系统可以针对线性读写做深层次的优化,比如预读(read-ahead,提前将一个比较大的磁盘块读入内存)和后写(write-behind,将很多小的逻辑写操作合并起来组成一个大的物理写操作)技术。顺序写盘的速度不仅比随机写盘的速度快,而且也比随机写内存的速度快,如下图所示。
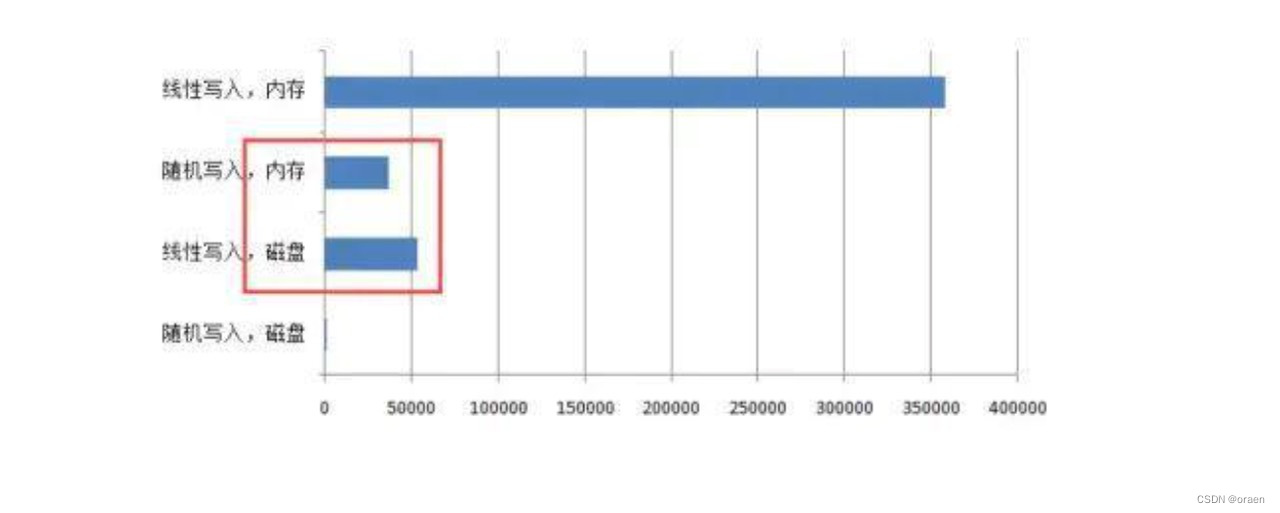
Kafka 在设计时采用了文件追加的方式来写入消息,即只能在日志文件的尾部追加新的消息,并且也不允许修改已写入的消息,这种方式属于典型的顺序写盘的操作,所以就算Kafka使用磁盘作为存储介质,它所能承载的吞吐量也不容小觑。而且,现代操作系统也会通过例如页缓存等方式来实现磁盘缓存,以此用来减少对磁盘 I/O 的操作。具体来说,就是把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问。为了弥补性能上的差异,现代操作系统越来越“激进地”将内存作为磁盘缓存,甚至会非常乐意将所有可用的内存用作磁盘缓存,这样当内存回收时也几乎没有性能损失,所有对于磁盘的读写也将经由统一的缓存。
3.1.2 存储机制
在Kafka中Topic是逻辑上的概念,而partition是物理上的概念,每个partition都有对应的log文件,该log文件中存储的就是Producer生产的数据,Producer生产的数据会被不断追加到该log文件末端,为防log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment,每个segment主要包括:“.index”文件(索引文件)、“.log”文件(日志文件)和.timeindex文件(时间戳索引文件),这些文件以当前segment的第一条消息的offset命名(有20个字符,前面用0填充)。并且这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号,例如:first-0。总体结构如图示:
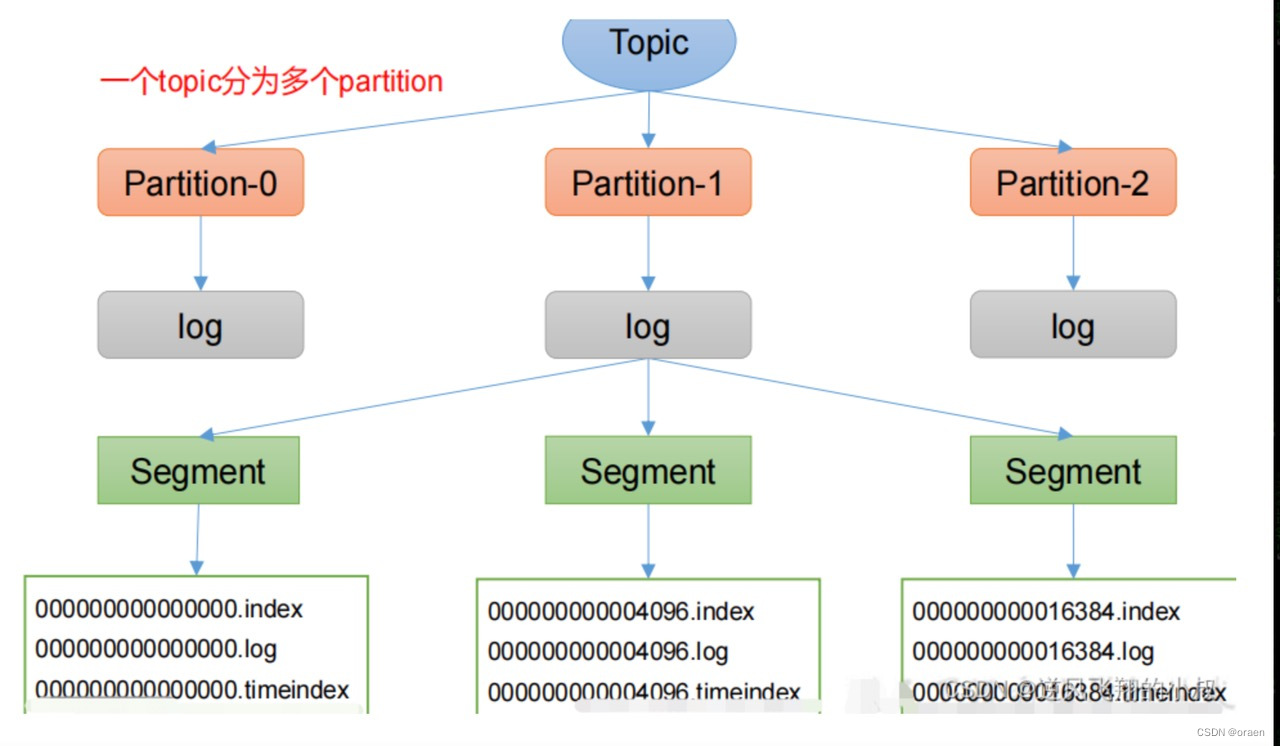
3.1.3 分区分配
在创建主题时, Kafka 首先会决定如何在 broker间分配分区。为了方便大家形象地理解Kafka的分区分配规则,我们举一个详细例子。假设假设你有6个 broker ,打算创建一个包含 10 个分区的主题,并且复制系数为3 。那么 Kafka 就会有 30个分区副本,它们可以被分配给6个broker 。在进行分区分配时,我们要达到如下的目标。
1 分区副本平均地分布到各个broke上。对于我们的例子来说,就是要保证每个broker可以分到(30/6=5)个副本。
2 确保每个分区的每个副本分布在不同的 broker上。假设分区0的首领副本在 broker2上,那么可以把跟随者副本分别放在broker3和broker4上,但不能放在 broker2上,也不能两个都放在 broker3或者broker4上。
3 如果为 broker 指定了机架信息,那么尽可能把每个分区的副本分配到不同机架的 broker上。这样做是为了保证一个机架的不可用不会导致整体的分区不可用。
为了实现这个目标,我们先随机选择一个broker(假设是4),然后使用轮询的方式给每个broke 分配分区来确定首领分区的位置。于是,首领分区0会在broker4上,首领分区1会在broker5上,首领分区2会在broker0上(只有6个broker),并以此类推。然后,我们从分区首领开始,依次分配跟随者副本。如果分区0的首领在broker4上,那么它的第一个跟随者副本会在broker5上,第二个跟随者副本在broker0 上。分区0的首领在broker5上,那么它的第一个跟随者副本在broker0上,第二个跟随者副本在broker1上。如果配置了机架信息,那么就不是按照数字顺序来选择broker了,而是按照交替机架的方来选择broker 。假设 broker0,broker1,broker2放置在同一个机架上,broker3,broker4,broker5分别放置在其他不同机架上。我们不是按照从0到5的顺序来选择broker,而是按照 0, 3, 1, 4, 2, 5的顺序来选择,这样每个相邻的 broker 都在不同的机架上。于是,如果分区0的首领在broker4上,那么第一个跟随者副本会在broker2上,这两个 broker 在不同的机架上。如果第一个机架下线,还有其他副本仍然活跃着,所以分区仍然可用。这对所有副本来说都是一样的,因此在机架下线时仍然能够保证可用性。
为分区和副本选好合适的broker 之后,接下来要决定这些分区应该使用broker下的哪个目录。我们单独为每个分区分配目录,规则很简单,计算每个目录里的分区数量,新的分区总是被添加到分区数量最小的那个目录里。也就是说,如果添加了一个新磁盘,所有新的分区都会被创建到这个磁盘上。因为在完成分配工作之前,新磁盘拥有的分区数量总是最少的。
--注意磁盘空间
要注意,Kafka在为broker分配分区时并没有考虑可用空间和工作负载问题,而且,将分区分配到broker的磁盘上时只会考虑分区数量,不考虑分区大小,如果有些 broker 的磁盘空间比其他 broker 要大(有可能是因为集群同时使用了旧服务器和新服务器),有些分区非常大,或者同一个broker上有大小不同的磁盘,那么在分配分区时要格外小心。Kafka管理员该如何解决这种 broker负载不均衡的问题,我们后面可能会说,也可能不会。现在我也不知道。
3.2 文件管理和操作策略
保留数据是Kafka的一个基本特性,上一小节中我们讲解了Kafka的数据存储的方式,是基于文件系统的,对于数据的管理和操作其实就是对于文件的管理和操作。所以本小节我们会介绍Kafka的文件管理方和操作策略。
3.2.1 Kafka消息的存储和追加策略
在上一个小节中我们了解到了Kafka的存储方式,因为在一个大文件里查找和删除消息是很费时的,也很容易出错,所以我们把一个分区分成若干个片段,默认情况下,每个片段包含 lGB或一周的数据,以较小的那个为准。当生产者把数据提交给broker时,broker会往对应分区日志文件中的活动片段(当前正在写入数据的片段)的尾部追加新的消息,并且不允许修改已写入的消息,如果达到片段上限,就关闭当前片段文件,井打开一个新的片段文件。这个新的片段文件就代替老的片段文件成为了活动片段。
3.2.2 Kafka消息的保留和删除策略
3.2.2.1 Kafka消息的清除
Kafka不会一直保留数据,也不会等到所有消费者都读取了消息之后才删除消息。相反,Kafka管理员需要为每个主题配置了数据保留期限,规定数据可以保留多长时间,或者保留的数据量大小。一个要注意的是活动片段永远不会被删除,所以如果你要保留数据一天,但是你设置了每个片段包含5天的数据,那么这些数据会被保留5天,因为在片段被关闭之前片段里的数据无法被删除,如果你要保留数据1周,而且每天使用1个新片段,那么你就会看到,每天在使用1个新片段的同时会删除1个最老的片段,这个时候大部分时间该分区会有7个片段存在。另外一个要注意的是,broker会为分区里的每个片段打开一个文件句柄,哪怕片段是不活跃的,这样会导致打开过多的文件句柄,所以操作系统必须根据实际情况做一些调优。
3.2.2.2 Kafka消息的清理(compact)
试想一下这样的场景,如果你使用 Kafka 保存客户的收货地址,那么保存客户的最新地址比保存客户上周甚至去年的地址要有意义得多,这样你就不用担心会用错旧地址,而且短时间内客户也不会修改新地址。另外一个场景,一个应用程序使用 Kafka 保存它的状态,每次状态发生变化,它就把状态写入到Kafka 。在应用程序从崩愤中恢复时,它从 Kafka 读取消息来恢复最近的状态。在这种情况下,应用程序只关心它在崩愤前的那个状态,而不心运行过程中的那些状态变化。Kafka可以通过改变主题的保留策略来满足这些使用场景。早于保留时间的旧事件会被删除,为每个键保留最新的值,从而达到清理的效果。很显然,只有当应用程序生成的事件里包含了键值对时,为这些主题设置 compact 策略才有意义。如果主题包含 null 键(没有key),就不会清理它。接下来我们说一下Kafka消息清理的工作原理
工作原理
每个日志片段可以分为以下两个部分。
干净的部分:这些消息之前被清理过,每个键只有一个对应的值,这个值是上一次清理时保留下来的,也就是老数据
污浊的部分:这些消息是在上一次清理之后写入的,也就是新数据
两个片段的示意图如下
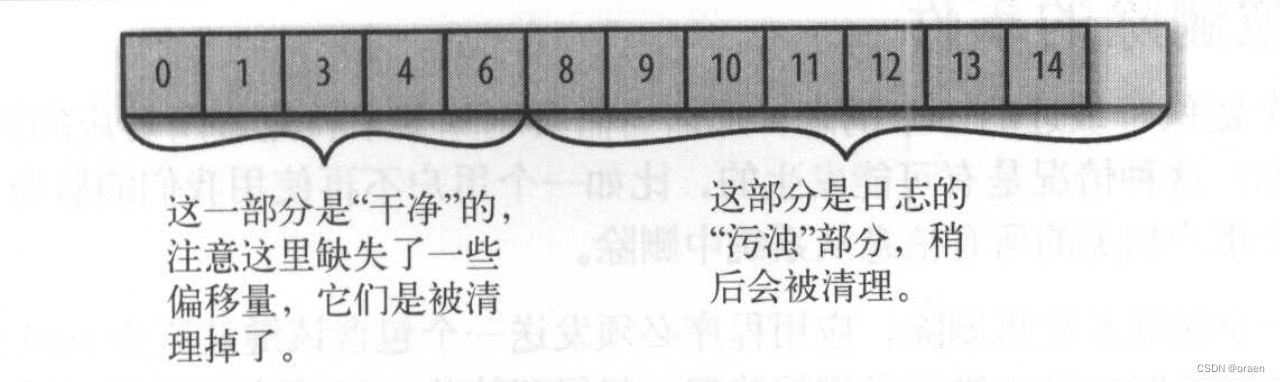
如果在 Kafka 启动时启用了清理功能(通过配置 log.cleane.enabled 参数),每个broker会启动一个清理管理器线程和多个清理线程,它们负责执行清理任务。这些线程会选择污浊率(污浊消息占分区总大小的比例)较高的分区进行清理。为了清理分区 ,清理线程会读取分区的污浊部分,井在内存里创建一个map,map里的每个元素包含了消息键的散列值和消息的偏移量,键的散列值是 16B,加上偏移量总共是24B,如果要清理 lGB的日志片段,并假设每个消息大小为1KB,那么这个片段就包含一百万个消息,而我们只需要用24MB的map 就可以清理这个片段。(如果有重复的键,可以重用散列项,从而使用更少的内存)这是非常高效的!
管理员在配置 Kafka时可以对map使用的内存大小进行配置。每个线程都有自己的 map,而这个参数指的是所有线程可使用的内存总大小。如果你为map分配了lGB 内存,并使用了5个清理线程,那么每个钱程可以使用 200MB内存来创建自己的 map,Kafka井不要求分区的整个污烛部分来适应这个map的大小,但要求至少有一个完整的片段必须符合。如果不符合,那么 Kafka 就会报错,管理员要么分配更多 的内存,要么减少清理线程数。如果只有少部分片段可以完全符合, Kafka 将从最旧的片段开始清理,等待下一次清理剩余的部分。
清理线程在创建好偏移map后,开始从干净的片段处读取消息,从最旧的消息开始,把它们的内容 map 里的内容进行比对。它会检查消息的键是否存在于 map 中,如果不存在,那么说明消息的值是最新的,就把消息复制到替换片段上 如果键已存在,消息会被忽略,因为在分区的后部已经有一个具有相同键的消息存在。在复制完所有的消息之后,我们就将替换片段与原始片段进行交换,然后开始清理下一个片段。完成整个清理过程之后,每个键对应一个不同的消息,这些消息的值都是最新的。清理前后的分区片段如图所示。
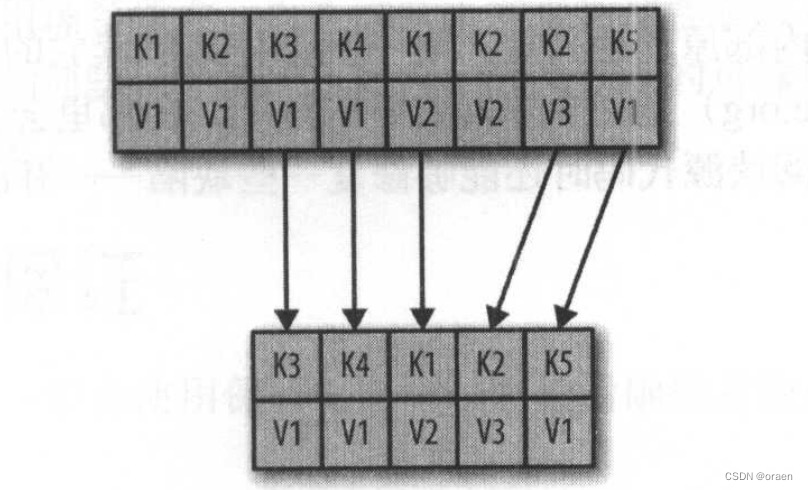
删除特定键对应的所有消息
如果只为每个键保留最近的一个消息,那么当需要删除某个特定键所对应的所有消息时我们该怎么办?这种情况是有可能发生的,比如 个用户不再使用我们的服务,那么完全可以把与这个用户相关的所有信息从系统中删除。为了彻底把某个键从系统里删除,应用程序必须发送一个包含该键且值为 null 的消息。清理线程发现该消息时,会先进行常规的清理,只保留值为null的消息。该消息(被称为墓
碑消息)会被保留一段时间,时间长短是可配置的。在这期间,消费者可以看到这个基碑消息,井且发现它的值已经被删除。于是,如果消费者往数据库里复制 Kafka 的数据,它看到这个墓碑消息时,就知道应该要把相关的用户信息从数据库里删除。在这个时间过后,清理线程会移除这个墓碑消息,这个键也将从 Kafka 分区里消失。重要的是,要给消费者足够多的时间,让他看到墓碑消息,因为如果消费者离线几个小时并错过了墓碑消息,就看不到这个键,也就不知道它已经从 Kafka 里删除,从而也就不会去删除数据库里的相关数据了。
何时清理
就像delete策略不会删除当前活跃的片段一样,compact策略不会对当前片段进行清理,只有旧片段里的消息才会被清理。在0.10.0 和更早的版本里, Kafka 会在包含脏记录的主题数量达到 50% 时进行清理。 这样做的目的是避免太过频繁的清理(因为清理会影响主题的读写性能),同时也避免存在太多脏记录(因为它们会占用磁盘空间)。浪费50%的磁盘空间给主题存放脏记录,然后进行一次清理,这是个合理的折中,管理员也可以对它进行调整。Kafka计划在未来的版本中加入宽限期,在宽限期内保证消息不会被清理。对于想看到主题的每个消息的应用程序来说,它们就有了足够的时间。
3.2.3 Kafka消息的查找策略
消费者可以从Kafka的任意可用偏移量位置开始读取消息。假设消费者要读取从偏移量100开始的1MB消息,那么 broker必须立即定位到偏移量100(可能是在分区的任意一个片里),然后开始从这个位置读取消息。为了帮助 broker 更快地定位到指定的偏移量, Kafka为每个分区的每个片段维护了一个索引(也就是index文件)。索引把偏移量映射到对应的片段文件和偏移量在文件里的位置。在删除消息时也可以删除相应的索引, Kafka不维护索引的校验和。如果索引出现损坏, Kafka 会通过重新读取消息并录制偏移量和位置来重新生成索引。如果有必要,管理员可以删除索引,这样做是绝对安全的, Kafka 会自动重新生成这些索引。
在索引文件中(也就是.index文件)存储的是连续的key-value格式的数据,key代表在消息数据文件(.log文件)中按顺序开始顺序消费的offset值(该segment中的相对offset),value代表该消息的物理消息存放位置。但是在.index中不是对每条消息都做记录,它是每隔一些消息记录一次,避免占用太多内存。即使消息不在index记录中,在已有的记录中查找,范围也大大缩小了。
下面演示下kakfa 中是如何根据索引定位到具体的消息,假如有两个segment 索引文件为:
00000000000000000000.index 00000000000001000000.index
下面查找 offset 值为 7912 的消息:
1 首先获取所有Segment文件的文件名,根据二分查找算法,得到数据在00000000000000000000 segment中。
2 先访问该segment中中的index文件,根据offset值查询到物理存放位置,如下图,根据二分算法(由于index中的每一项key-value的大小是固定的,通过计算可以直接进行随机访问)得到4597< 7912 < 9807 即可以得到消息在 4597 的向下附近的位置,根据 index中 position 到 .log 文件中找到 message3 ,从这个位置向下依次 +1 遍历,最终得到offset 值7912 的消息。
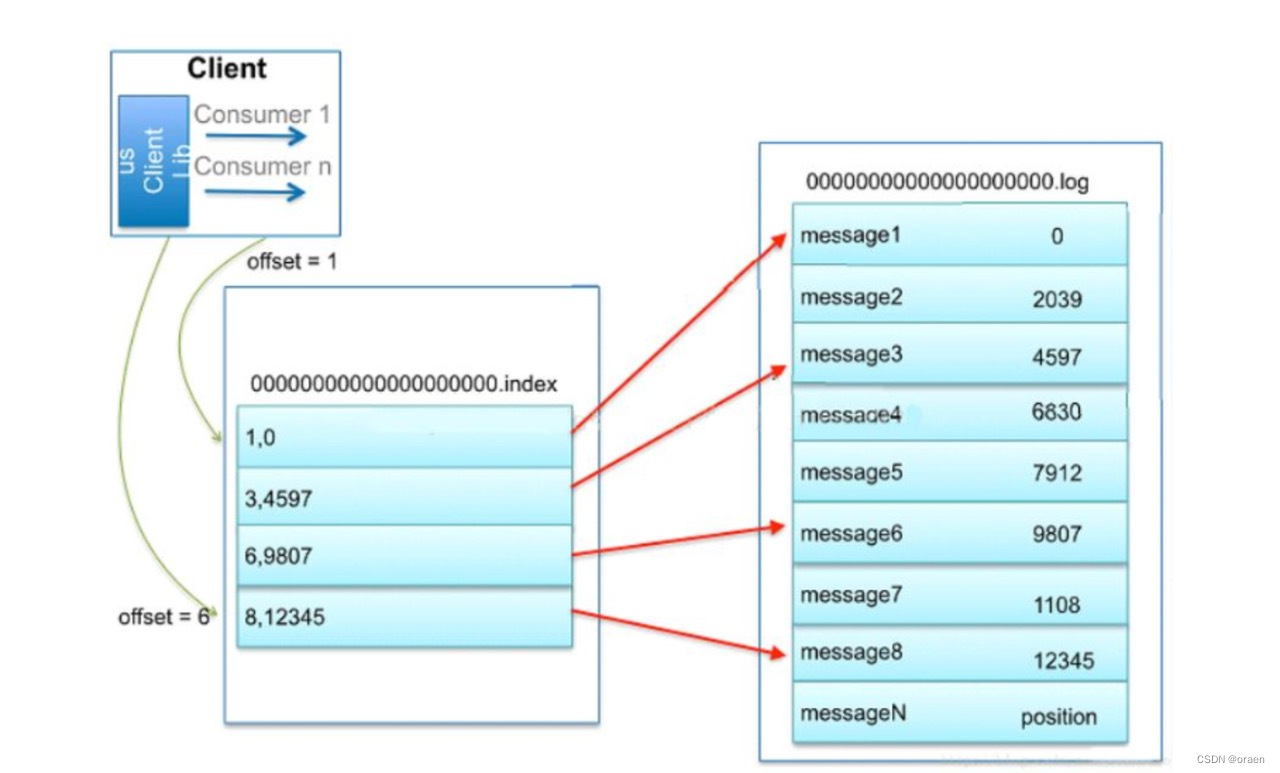
图片补充:图中左边的index表示中,index文件存放的是连续的key-value值,key表示偏移量(图中的值),value是该偏移量的消息的物理地址(由红色箭头线表示),右边的log表示中左边是具体消息,右边是该消息的偏移量。
从上面的过程可以看出,kafka没有对每个文件建立索引,而是利用kafka 消息写入磁盘的顺序性,对其中部分的消息建立了索引,这就是稀疏索引,即并非进入log文件的每条数据都在索引文件中进行记录,而是当log中的文件数累计到一定的数量才会在index文件中记录一次(默认大约每往log写入4kb数据时,kafka会往index写入一条索引,log.index.interval.bytes默认为4kb)
目的是为了节约我们空间的资源,定位到邻居,再根据顺序遍历查找,也可以看出这个方式的时间复杂度是O(n)。
3.2.4 数据文件刷盘策略
当我们把数据写入到文件系统之后,数据其实在操作系统的page cache里面(在操作系统支持页缓存的情况下),并没有直接刷到磁盘上去。如果此时操作系统挂了,其实数据就丢了。这里可以根据消息的数量log.flush.interval.messages和时间log.flush.interval.ms进行配置,Kafka会在数据满足其中一种情况的时候做刷盘,如果时间设置的过大,又没达到指定的数量的情况下,如果系统挂了,数据就会丢失。
注意:Kafka官方并不建议通过Broker端的log.flush.interval.messages和log.flush.interval.ms强制写盘的方式在保证数据可靠性,认为数据的可靠性应该通过Replica来保证,而强制Flush数据到磁盘会对整体性能产生影响。
3.3 文件内容
我们把Kafka的消息和偏移量保存在文件里。保存在磁盘上的数据格式与从生产者发送过来或者发送给消费者的消息格式是一样的。因为使用了相同的消息格式进行磁盘存储和网络传输,不需要在JVM内存中做其他的处理,Kafka可以很容易使用零复制技术给消费者发送消息,同时避免了对生产者已经压缩过的消息进行解压和再压缩。除了键、值和偏移量外,消息里还包含了消息大小、校验和、消息格式版本号、压缩算法(Snappy,GZip或LZ4 )和时间戳(在 0.10.0 版本里引入的)。时间戳可以是生产者发送消息的时间,也可以是消息到达 broker 的时间,这个是可配置的。
如果生产者发送的是压缩过的消息,那么同一个批次的消息会被压缩在一起,被当作“包装消息”进行发送。于是 broker 就会收到一个这样的消息,然后再把它发送给消费者。消费者在解压这个消息之后,会看到整个批次的消息,它们都有自己的时间戳和偏移量。下图中上面为普通消息的格式,下面为包装消息的格式
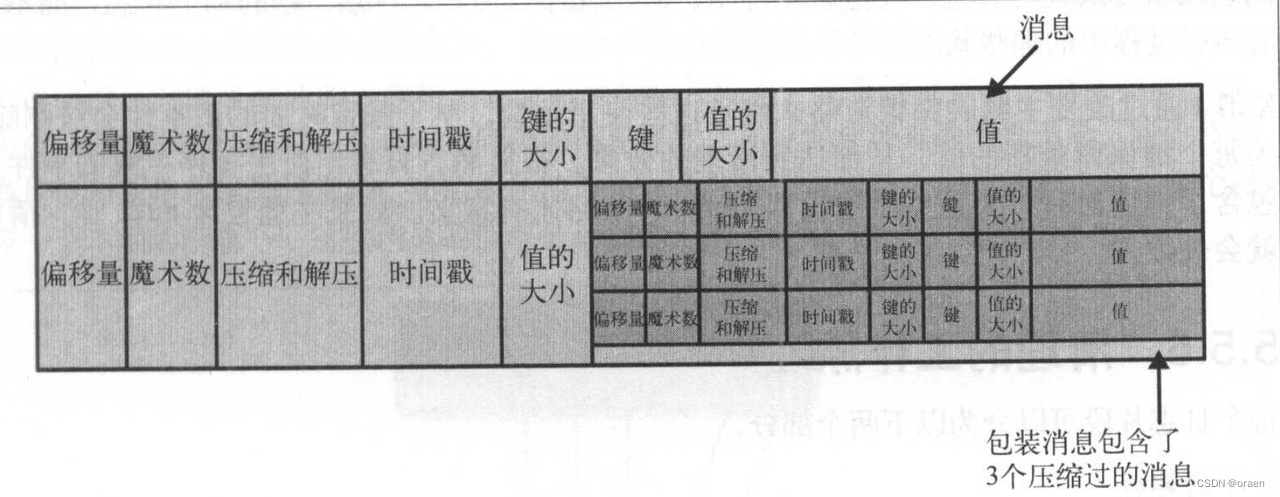
如果在生产者端使用了压缩功能(极力推荐),那么发送的批次越大,就意味着在网络传输和磁盘存储方面会获得越好的压缩性能,同时意味着如果修改了消费者使用的消息格式(例如,在消息里增加了时间戳),那么网络传输和磁盘存储的格式也要随之修改,而且 broker要知道如何处理包含了两种消息格式的文件(修改了消息格式后,原本在broker里面进行过压缩的消息拿到消费者上可能无法正常解压)。
Kafka附带了一个叫DumpLogSegment的工具,可以用它查看片段的内容。它可以显示每个消息的偏移量、校验和、魔术数字节、消息大小和压缩算法。运行该工具的方法如下
bin/kafka-run-class .sh kafka.tools.DumpLogSegments
如果使用了--deep-iteration参数,可以显示被压缩到包装消息里的消息。
四 Kafka可靠性保证
与性能一样,在系统的设计之初就应该考虑可靠性问题,而不能在事后才来考虑。而且,可靠性是系统的 个属性,而不是一个独立的组件,所以在讨论 Kafka 的可靠性保证时,还是要从系统的整体出发。说到可靠性,那些与 Kafka 集成的系统与 Kafka 本身一样重要。正因为可靠性是系统层面的概念,所以它不只是某个个体的事情。 Kafka 管理员、 Linux系统管理员、网络和存储管理员以及应用程序开发者,所有人必须协同作战,才能构建一个可靠的系统。kafka 在数据传递可靠性方面具备很大的灵活性。我们知道, Kafka 可以被用在很多场景里, 从跟踪用户点击动作到处理信用卡支付操作。有些场景要求很高的可靠性,而有些则更看重速度和简便性。 Kafka 被设计成高度可配置的,而且它的客户端 API 可以满足不同程度的可靠性需求。不过,灵活性有时候也很容易让人掉入陷阱。有时候,你的系统看起来是可靠的,但实上有可能不是。本章会在系统的层面上对kafka的可靠性做一个介绍。
4.1 kafka集群
kafka的可靠性保证很大一部分是他的集群贡献的(写文章时莫名其妙变成了英文腔),所以首先我们简单说一下kafka集群的架构,第一章介绍的kafka体系结构其实已经简单介绍了kafka的broker集群,现在我们从集群和可靠性的角度来介绍kafka的集群架构。如图所示,一个集群通常包含多个broker节点上,数据分布在不同的broker,生产者总能找到自己需要的broker并且往他提交信息,消费者也一样能够准确自己自己要消费的消息位于哪个broker上,集群的相关元数据都保留在zookeeper上。早期版本消费者需要通过zookeeper了解自己消费的消息位于哪个broker中,然后再和对应broker建立连接,新版本后便可以直接找到broker了。一个broker可能是一部分分区的首领,他会接受生产者的消息,然后提供给消费者和其他分区跟随者,也可能是另外一部分分区的跟随者,不和生产者和消费者对接,只是复制该分区首领的这个分区的消息,只有在当首领节点挂了的情况下代替他成为首领。

后面我们对集群里面的一些核心细节做一些介绍。
4.1.1 集群成员broker
Kafka 使用 Zookeeper 来维护集群成员的信息。每个 broker 都有一个唯一标识符,这个标识符可以在配置文件里指定 ,也可以自动生成。在 broker 启动的时候,它通过创建临时节点把自己的ID注册到 Zookeeper。 Kafka 组件订阅 Zookeeper的/brokers/ids 路径(broker在Zookeeper 上的注册路径),当有broker加入集群或退出集群时,这些组件就可以获得通知。
如果你要启动另一个具有相同ID的broker ,会得到一个错误,broker 会试着进行注册,但不会成功,因为 Zookeeper 里已经有一个具有相同 ID的broker。
在broker停机、出现网络分区或长时间垃圾回收停顿时, broker 会从 Zookeeper上断开连接,此时 broker在启动时创建的临时节点会自动从 Zookeeper上移除。监听 broker列表的Kafka 组件会被告知该 broker 已移除。
在关闭 broker 时,它对应的节点也会消失,不过它的 ID 会继续存在于其他数据结构中,例如,主题的副本列表(下面会介绍)里就可能包含这些ID。在完全关闭一个 broker后,如果使用相同的ID启动另一个全新的 broker ,它会立即加入集群,井拥有与旧 broker相同的分区和主题。
4.1.2 集群的控制器
控制器其实就是集群里的一个broker,只不过它除了具有一般 broker 的功能之外,还负责分区的首领的选举。集群里第一个启动的broker通过在Zookeeper里创建一个临时节点/controller让自己成为控制器。其它broker在启动时也会尝试创建这个节点,不过它们会收到一个“节点已存在”的异常,然后“意识”到控制器节点已存在,也就是说集群里已经有一个控制器了。其他 broker在控制器节点上创建Zookeeper watch对象,这样它们就可以收到这个节点的变更通知。这种方式可以确保集群里一次只有一个控制器存在。
如果控制器被关闭或者与Zookeeper断开连接, Zookeeper上的临时节点就会消失。集群里的其他 broker通过watch对象得到控制器节点消失的通知,它们会尝试让自己成为新的控制器。第一个在 Zookeeper里成功创建控制器节点的 broker 就会成为新的控制器,其他节点会收到“节点已存在”的异常,然后在新的控制器节点上再次创建watch对象。每个新选出的控制器通过Zookeeper的条件递增操作获得一个全新的、数值更大的 controller epoch 。其他 broker在知道当前controller epoch后,如果收到由控制器发出的包含较旧epoch的消息,就会忽略它们。
当控制器发现一个broker已经离开集群(通过观察相关的 Zookeeper路径),它就知道,那些失去首领的分区需要一个新首领(这些分区的首领刚好是在这个 broker 上)。控制器遍历这些分区,并确定谁应该成为新首领(简单来说就是分区副本列表里的下一个副本),然后向新首领和现有跟随者的 broker发送请求。该请求消息包含了谁是新首领以及谁是分区跟随者的信息。随后,新首领开始处理来自生产者和消费者的请求,而跟随者开始从新首领那里复制消息。
当控制器发现一个broker加入集群时,它会使用broker ID来检查新加入的 broker是否包含现有分区的副本(比如是之前的broker离线重连的情况下就会包含现有分区的副本)。如果有,控制器就把变更通知发送给新加入的 broker和其他 broker,新broker上的副本开始从首领那里复制消息。
简而言之,Kafka使用Zookeeper的临时节点来选举控制器,并在节点加入集群或退出集群时通知控制器。控制器负责在节点加入或离开集群时进行分区首领选举。控制器使用epoch来避免“脑裂” 。“脑裂”是指两个节点同时认为自己是当前的控制器。
4.1.3 集群内数据复制
复制功能是 Kafka 架构的核心。在 Kafka 的文档里, Kafka 把自己描述成“一个分布式的、可分区的、可复制的提交日志服务”。复制之所以这么关键,是因为它可以在个别节点失效时仍能保证Kafka的可用性和持久性。
Kafka使用主题来组织数据,每个主题被分为若干个分区,每个分区有多个副本。那些副本被保存在各个broker上,每个broker可以保存成百上千个属于不同主题和分区的副本。副本有以下两种类型。
首领副本:每个分区都有一个首领副本为了保证一致致性,所有生产者请求和消费者请求都会经过这个副本。
跟随者副本:首领以外的副本都是跟随者副本。跟随者副本不处理来自客户端的请求,它们唯一的任务就是从首领那里复制消息,保持与首领一致的状态。如果首领发生崩渍,其中的一个跟随者会被提升为新首领。
首领的另一个任务是搞清楚哪个跟随者的状态与自己是一致的。跟随者为了保持与首领的状态一致、在有新消息到达时尝试从首领那里复制消息,不过有各种原因会导致同失败,例如,网络拥塞导致复制变慢,broker发生崩横导致复制滞后,直到重启broker后复制才会继续。
为了与首领保持同步,跟随者向首领发送获取数据的请求,这种请求与消费者为了读取消息而发送的请求是一样的。首领将响应消息发给跟随者。请求消息里包含了跟随者想要获取消息的偏移量,而且这些偏移量总是有序的,一个跟随者副本先请求消息1 ,接着请求消息2 ,然后请求消息3 ,在收到这三个请求的响应之前,它是不会发送第4个请求消息的。如果跟随者发送了请求消息4 ,那么首领就知道它已经收到了前面3个请求的响应。通过查看每个跟随者请求的最新偏移量 ,首领就会知道每个跟随者复制的进度。如果跟随者在 10秒内没有请求任何消息,或者虽然在请求消息,但在10秒内没有请求最新的数据,那么它就会被认为是不同步的。如果一个副本无法与首领保持一致,在首领发生失效时,它就不可能成为新首领,毕竟它没有包含全部的消息。相反,持续请求得到的最新消息副本被称为同步副本。在首领发生失效时,只有同步副本才有可能被选为新首领。
跟随者的正常不活跃时间或在成为不同步副本之前的时间是通过replica.lag.time.max.ms参数来配置的。这个时间间隔直接影响着首领选举期间的客户端行为和数据保留机制。
除了当前首领之外,每个分区都有一个首选首领,在创建主题时选定的首领就是这个分区的首选首领。之所以把它叫作首选首领,是因为在创建分区时,需要在各个broker之间均衡首领,使得不同分区的首领尽可能平均地分配在不同broker上(后面会介绍在 broker 间分布副本和首领的算怯)。因此,我们希望首选首领在成为真正的首领时, broker间的负载最终会得到均衡。默认情况下,kafka的auto.leader.rebalance.enable被设为true,它会检查首选首领是不是当前首领,如果不是,而且首选首领的副本是同步的,那么就触发首领选举,让首选首领成为当前首领。
找到首选首领
从分区的副本清单里可以很容易找到首选首领(可以使用 kafka topics.sh工具查看副本和分区的详细信息)。清单里的第一个副本一般就是首选首领。不管当前首领是哪一个副本,都不会改变这个事实,即使使用副本分配工具将副本重新分配给其他broker 。要记住,如果你手动进行副本分配,第一个指定的副本就是首选首领,所以要确保首选首领被传播到其他broker上,避免让包含了首领的broker负载过重,而其他broker却无泣为它们分担负载。
Kafka的复制机制和分区的多副本架构是Kafka可靠性保证的核心。把消息写入多个副本可以使 Kafka 在发生崩愤时仍能保证消息的持久性。分区首领当然是同步副本,而对于跟随者副本来说,它需要同时满足以下条件才能被认为是同步的。
1 与Zookeeper之间有一个活跃的会话,也就是说,它在过去的6s(可配置)内向Zookeeper发送过心跳。
2 在过去的10s内(可配置)从首领那里获取过消息。
3 在过去的10s内从首领那里获取过最新的消息。光从首领那里获取消息是不够的,它还必须是儿乎零延迟的。
如果跟随者副本不能满足以上任何一点,比如与Zookeeer断开连接,或者不再获取新消息,或者获取消息滞后了10s 以上,那么它就被认为是不同步的。 一个不同步的副本通过与Zookeeper重新建立连接,井从首领那里获取最新消息,可以重新变成同步的。这个过程在网络出现临时问题井很快得到修复的情况下会很快完成,但如果broker发生崩愤就需要较长的时间。
一个滞后的同步副本会导致生产者和消费者变慢,因为在消息被认为已提交之前,客户端等待所有同步副本接收消息。而如果一个副本不再同步了,我们就不再关注它是否已经收到消息。虽然非同步副本同样滞后,但它并不会对性能产生任何影响。但是,更少的同步副本意味着更低的有效复制系数,在发生岩机时丢失数据的风险更大。
如果一个或多个副本在同步和非同步状态之间快速切换,说明集群内部出现了问题,通常是Java不恰当的垃圾回收配置导致的。不恰当的垃圾回收配置会造成几秒钟的停顿,从而让 broker Zookeeper 之间断开连接,最后变成不同步的,进而发生状态切换。
4.2 处理请求
broker的大部分工作是处理客户端,分区副本和控制器发送给分区首领的请求。 对于如何处理请求也是直接关系到kafka的可靠性。本节会从可靠性保障的角度上讲解kafka上的请求处理。
4.2.1 请求处理流程
Kafka提供了一个二进制协议(基于TCP ),指定了请求消息的格式以及broker如何对请求作出响应,包括成功处理请求或在处理请求过程中遇到错误。客户端发起连接并发送请求,broker处理请求井作出响应。 broker按照请求到达的顺序来处理它们,这种顺序保证让Kafka具有了消息队列的特性,同时保证保存的消息也是有序的。所有的请求消息都包含一个标准消息头:
Request type:也就是 API key)
Request version :broker 可以处理不同版本的客户端请求,井根据客户端版本作出 不同
的响应
Correlation ID:一个具有唯一性的数字, 用于标识请求消息,同时也会出现在响应消息和错误日志里,用于诊断问题
Client ID:用于标识发送请求的客户端
由于前面已经详细地介绍了kafka通信协议,这里不再描述了。本节重点是在可靠性保障的角度上了解broker如何处理请求的,broker会在它所监听的每个端口上运行一个Acceptor线程,这个线程会为每个请求创建一个连接,并把它交给 Pocessor线程去处理。 Pocessor线程(也被叫作“网络线程”)的数量是可配置的。网络线程负责从客户端获取请求消息,把它们放进请求队列,然后从晌应队列获取响应消息,把它们发送给客户端。如下图。(这里只是做概述,详细流程在上面的kafka通信实现章节里面有讲到)
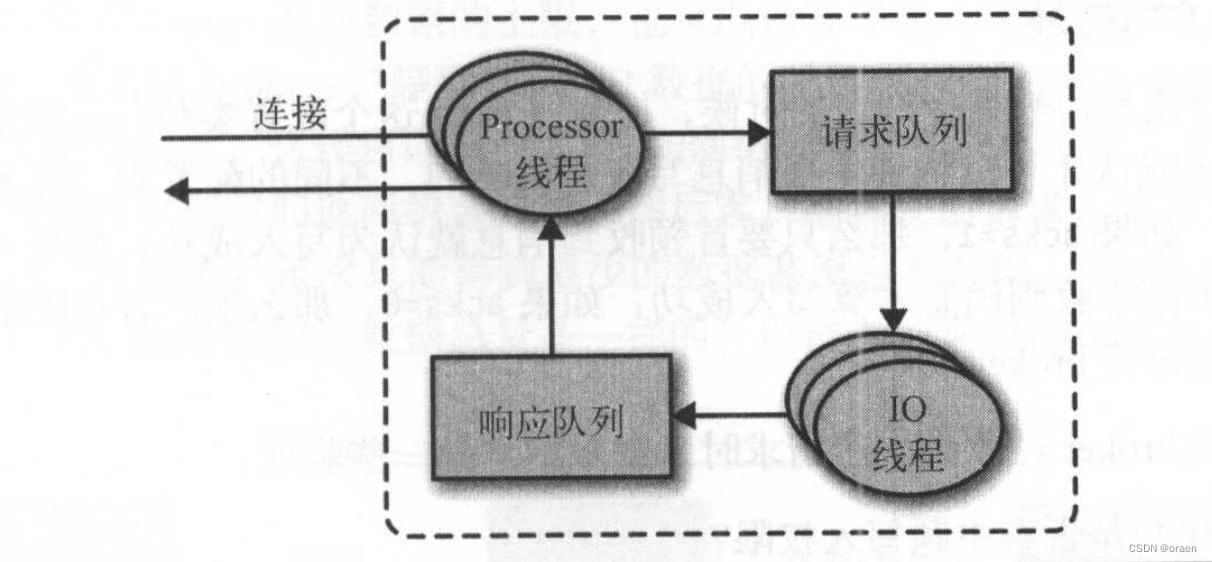
请求消息被放到请求队列后,IO线程会负责处理它们。下面是几种最常见的请求类型
生产请求:生产者发送的请求,它包含客户端要写入broker的消息。
获取请求:在消费者和跟随者副本需要从broker读取消息时发送的请求。
生产请求和获取请求都必须发送给分区的首领副本。如果broker收到一个针对特定分区的请求,而该分区的首领在另一个broker上,那么发送请求的客户端会收到一个“非分区首领”的错误响应。当针对特定分区的获取请求被发送到一个不含有该分区首领的 broker上,也会出现同样的错误。 Kafka客户端要自己负责把生产请求和获取请求发送到正确的broker上。那么客户端怎么知道该往哪里发送请求呢?客户端使用了另一种请求类型,也就是元数据请求。这种请求包含了客户端感兴趣的主题列表。服务器端的响应消息里指明了这些主题所包含的分区、每个分区都有哪些副本, 以及哪个副本是首领。元数据请求可以发送给任意一个broker,因为所有 broker 都缓存了这些信息。一般情况下,客户端会把这些信息缓存起来,并直接往目标 broker上发送生产请求和获取请求。它们需要时不时地通过发送元数据请求来刷新这些信息(刷新的时间间隔通过metadata.max.age.ms 参数来配置),从而知道元数据是否发生了变更,比如,在新broker加入集群时,部分副本会被移动到新 broker 上(如图)。另外,如果客户端收到“非首领”错误,它会在尝试重发请求之前先刷新元数据,因为这个错误说明了客户端正在使用过期的元数据信息,之前的请求被发到了错误的 broker上。
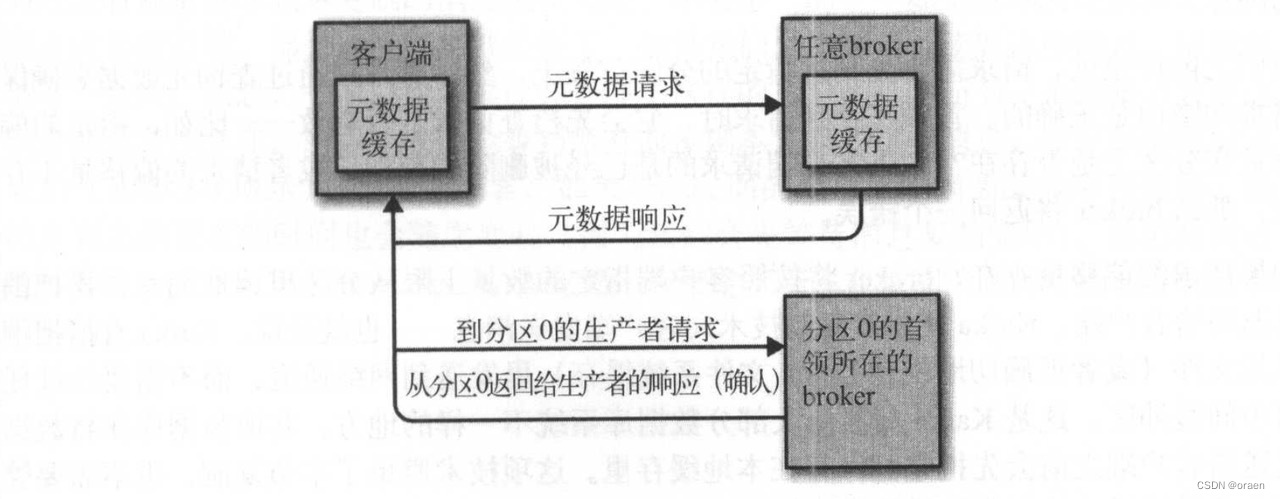
4.2.2 生产请求的处理
在配置生产者的时候,可以使用acks这个配置参数,该参数指定了需要多少个broker确认才可以认为一个消息写入是成功的。不同的配置对“ 写入成功”的界定是不一样的,如果 acks=1,那么只要首领收到消息就认为写入成功;如果acks=all ,那么需要所有同步副本收到消息才算写入成功,如果 ack=0,那么生产者在把消息发出去后,完全不需要等待broker 的响应。
包含首领副本的broker在收到生产请求时,会对请求做一些验证。
1 发送数据的用户是否有主题写入权限?
2 请求里包含的acks值是否有效?(只允许出现0, 1或all))?
3 如果acks的值是all,是否有足够多的同步副本保证消息已经被安全写入?(我们可以对broker进行配置,如果同步副本的数量不足, broker可以拒绝处理新消息)
之后,消息被写入本地磁盘。在Linux系统上,消息会被写到文件系统缓存里,并不保证它们何时会被刷新到磁盘上。Kafka不会一直等待数据被写到磁盘上,它依赖复制功能来保证消息的持久性。在消息被写入分区的首领之后,broker开始检查acks配置参数,如果acks被设为1,那么broker立即返回响应;如果 ack被设为all ,那么请求会被保存在一个叫作炼狱的缓冲区里,直到首领发现所有跟随者副本都复制了消息,晌应才会被返回给客户端。
4.2.3 获取请求的处理
broker处理获取请求的方式与处理生产请求的方式很相似。客户端发送请求,向 broker请求主题分区里具有特定偏移量的消息,好像在说 “请把主题Test0分区偏移量从53开始的消息以及主题Test分区3偏移量从64开始的消息发给我”,客户端还可以指定broker最多可以从一个分区里返回多少数据。这个限制是非常重要的,因为客户端需要为broker返回的数据分配足够的内存。如果没有这个限制, broker返回的大量数据有可能耗尽客户端的内存。我们之前说过,请求需要先到达指定的分区首领上,然后客户端通过查询元数据来确保请求的路由是正确的。首领在收到请求时,它会先检查请求是否有效,比如,指定的偏移量在分区上是否存在?如果客户端请求的是已经被删除的数据,或者请求的偏移量不在,那么 broker将返回一个错误。如果请求的偏移量存在, broker 将按照客户端指定的数量上限从分区里读取消息,再把消息返回给客户端。 Kafka使用零复制技术向客户端发送消息,也就是说, Kafka 直接把消息从文件(或者更确切地说是 Liunx文件系统缓存)里发送到网络通道,而不需要经过任何中间缓冲区。这是Kafka与其他大部分数据库系统不一样的地方(前面章节也有提到),其他数据库在将数据发送给客户端之前会先把它们保存在本地缓存里。这项技术避免了字节复制,也不需要管理内存缓冲区,从而获得更好的性能。客户端除了可以设置broker返回数据的上限,也可以设置下限。例如,如果把下限设置为10KB,就好像是在告诉broker:“等到有10KB 数据的时候再把它们发送给我。”在主题消息流量不是很大的情况下,这样可以减少 CPU 和网络开销。客户端发送一个请求, broker等到有足够的数据时才把它们返回给客户端,然后客户端再发出请求,而不是让客户端每隔几毫秒就发送一次请求,每次只能得到很少的数据甚至没有数据。如图所示,对比这两种情况,它们最终读取的数据总量是一样的,但前者的来回传送次数更少,因此开销也更小。
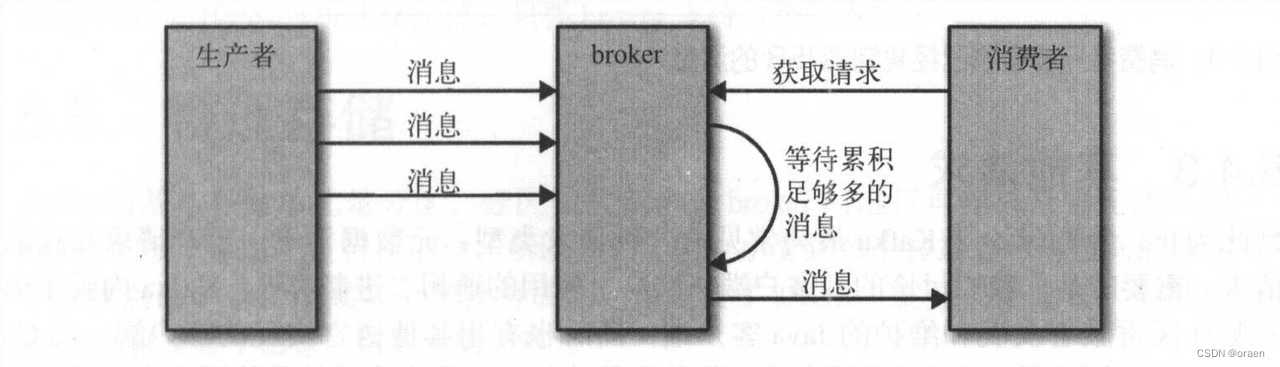
当然,我们不会让客户端一直等待broker累积数据。在等待了一段时间之后,就可以把可用的数据拿回处理,而不是一直等待下去。所以,客户端可以定义一个超时时间,告诉broker :“如果你无告在X毫秒内累积满足要求的数据量,那么就把当前这些数据返回给我。”。
有意思的是,并不是所有保存在分区首领上的数据都可以被客户端读取。大部分客户端只能读取已经被 入所有同步副本的消息(跟随者副本broker除外,尽管它们本质上也是消费者,不然复制就无法工作了)。分区首领知道每个消息会被复制到哪个副本上,在消息还没有被写入所有同步副本之前,是不会发送给消费者的,尝试获取这些消息的请求会得到空的响应而不是错误,因为还没有被足够多副本复制的情况是被认为是“不安全”的,如果首领发生崩愤,另一个副本成为新首领,那么这些消息就丢失了。如果我们允许消费者读取这些消息,可能就会破坏一致性。试想, 一个消费者读取并处理了这样的一个消息,而另一个消费者发现这个消息其实并不存在。 所以,我们会等到所有同步副本复制了这些消息,才允许消费者读取它们,但是这也意味着,如果broker的消息复制因为某些原因变慢,那么消息到达消费者的时间也会随之变长(因为我们会先等待消息复制完毕)。延迟时间可以通过参数replica.lag.time.max.ms来配置,它指定了副本在复制消息时可被允许的最大延迟时间。
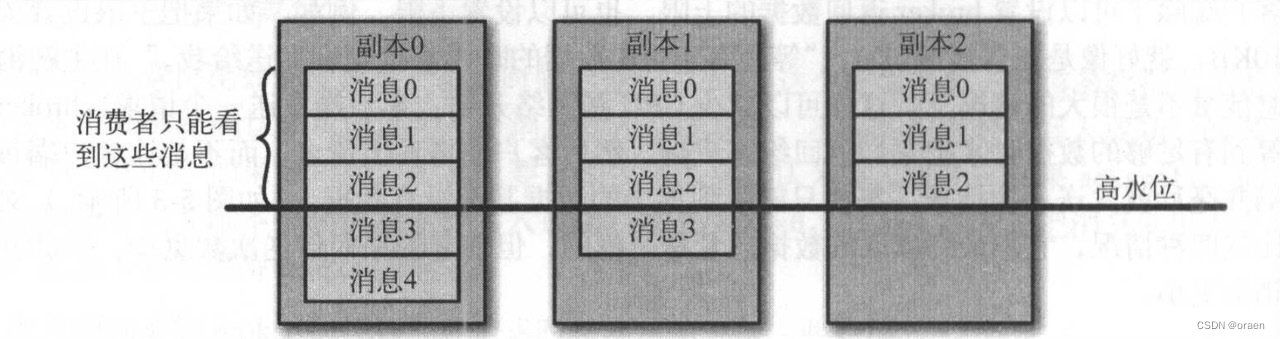
如图:消费者只能看到已经复制到ISR的消息
4.2.4 其他请求的处理
到此为止,我们讨论了Kafka最为常见的几种请求类型:元数据请求、生产请求和获取请求。重要的是,我们讨论的是客户揣在网络上使用的通用二进制协议。 Kafka内置了由开源社区贡献者实现和维护的Java 客户端,同时也有用其他语言实现的客户端,如C Python Go 语言等。 Kafka 网站上有它们的完整清单,这些客户端就是使用这个二进制协议与broker通信的。另外,broker之间也使用同样的通信协议。它们之间的请求发生在Kafka内部,客户端不应该使用这些请求。例如,当一个新首领被选举出来,控制器会发送LeaderAndIsr请求给新首领(这样它就可以开始接收来自客户端的请求)和跟随者(这样它们就知道要开始跟随新首领了)。
Kafka协议当前可以处理20种不同类型的请求,而且会有更多的类型加入进来。协议在持续演化,随着客户端功能的不断增加,kafka需要改进协议来满足需求。例如,之前的Kafka消费者使用Zookeeper来跟踪偏移量,在消费者启动的时候,它通过检查保存在Zookeper上的偏移量就可以知道从哪里开始处理消息。因为各种原因,kafka决定不再使用Zookeeper来保存偏移量,而是把偏移量保存在特定的Kafka 主题上。为了达到这个目的,kafka不得不往协议里增加几种请求类型:OffsetCommitRequest,OffsetFetchRequest和ListOffsetsRequest。现在,在应用程序调用 commitOffset() 方法时,客户端不再把偏移量写入Zookeeper,而是往Kafka发送OffsetCommitRequest请求。
主题的创建仍然需要通过命令行工具来完成,命令行工具会直接更新 Zookeeper 里的主题列表, broker监听这些主题列表,在有新主题加入时,它们会收到通知。Kafka正在计划改进 ,增加了ceateTopicRequest请求类型,这样客户端(包括那些不支持 Zookeeper户端的编程语言)就可以直接向broker请求创建新主题了。
除了往协议里增加新的请求类型外,kafka也在通过修改已有的请求类型来给它们增加新功能。例如,从 Kafka0.9.0到Kafka 0.10.0 ,kafka希望能够让客户端知道谁是当前的控制器,于是把控制器信息添加到元数据响应消息里。kafka还在元数据请求消息和响应消息里添加一个新的version字段。现在,0.9.0 版本的客户端发送的元数据请求里version为0(0.9.0本客户端的version不会是1)。不管是 0.9.0 版本的 broker ,还是 0.10.0 版本的 broker,它们都知道应该返回version为0的响应,也就是不包含控制器信息的响应。 0.9.0版本的客户端不需要控制器的信息,而且也没必要知道如何去解析它。0.10.0 版本的客户端会发送version为1的元数据请求,0.10.0版本的broker会返回version为1的响应,里面包含了控制器的信息。如果0.10.0版本的客户端发送version为1的请求给0.9.0 版本的broker,这个版本的broker不知道该如何处理这个请求,就会返回一个错误。这就是为什么我们建议在升级客户端之前先升级broker,因为新的broker知道如何处理旧的请求,反过来则不然。
0.10.0版本的Kafka里加入了ApiVersi.onRequest,客户端可以询问broker支持哪些版本的请求,然后使用正确的版本与broker通信。如果能够正确使用这个新功能,客户端就可以与旧版本的broker通信,只要broker支持这个版本的协议。
4.3 kafka的可靠性保障
4.3.1 kafka的可靠性保证
了解系统的保证机制对于构建可靠的应用程序来说至关重要,这也是能够在不同条件下解释系统行为的前提。那么kakfa上可以在哪些方面作出保证呢?
1 Kafka可以保证分区消息的顺序。如果使用同一个生产者往同一个分区写入消息,而且消息B在消息A之后写入,那么broker可以保证消息B的偏移量比消息A的偏移量大,而且消费者会先读取消息A,再读取消息B。
2 只有当消息被写入分区的所有同步副本时(但不一定要写入磁盘),它才被认为是“提交”的。生产者可以选择接收不同类型的确认,比如在消息被完全提交时的确认,或者在消息被写入首领副本时的确认,又或者只要在消息被发送到网络时的确认。
3 只要还有一个副本是活跃的,那么已经提交的消息就不会丢失。
4 消费者只能读取已经提交的消息。
4.3.2 broker的可靠性核心配置
broker有3个配置参数会影响Kafka消息存储的可靠性。与其他配置参数一样,它们可以应用在broker级别,用于控制所有主题的行为,也可以应用在主题级别,用于控制个别主题的行为。在主题级别控制可靠性,意味着 Kafka 集群可以同时拥有可靠的主题和非可靠的主题。例如,在银行里,管理员可能把整个集群设置为可靠的,但把其中的某个主题设置为非可靠的,用于保存来自客户的投诉,因为这些消息是允许丢失的。让我们来逐个介绍这些配置参数,看看它们如何影响消息存储的可靠性,以及Kafka在哪些方面作出了权衡。
复制系数
主题级别的配置参数是replicatlon.factor,而在broker级别则可以通过default.replication.factor来配置自动创建的主题。假设主题的复制系数都是3,也就是说每个分区总共会被3个不同的broker复制3次。Kafka 的默认复制系数就是3,用户可以修改它。即使是在主题创建之后,也可以通过新增或移除副本来改变复制系数。
如果复制系数为N,那么在N-1个broker失效的情况下,仍然能够从主题读取数据或向主题写入数据。所以,更高的复制系数会带来更高的可用性、可靠性和更少的故障。另一方面,复制系数为N需要至少 N个broker,而且会有N个数据副本,也就是说它们会占用N倍的磁盘空间。我们一般会在可用性和存储硬件之间作出权衡。那么该如何确定一个主题需要几个副本呢?这要看主题的重要程度,以及你愿意付出 多少成本来换取可用性。有时候这与你的偏执程度也有点关系。如果因broker重启导致的主题不可用是可接受的(这在集群里是很正常的行为),那么把复制系数设为1就可以了 。在作出这个权衡的时候要确保这样不会对你的组织和用户造成影响,因为你在节省了硬件成本的同时也降低了可用性。复制系数为1意味着可以容忍broker发生失效,看起来已经足够了。不过要记住,有时候 broker生失效会导致集群不稳定(通常是旧版的 Kafka ),迫使你重启另一个集群控制器broker。也就是说,如果将复制系数设为1,就有可能因为重启等问题导致集群不可用 。所以这是一个两难的选择。
基于以上几点原因,kafka建议在要求可用性的场景里把复制系数设为3。在大多数情况下,这已经足够安全了 不过我们也见过有些银行使用5个副本,以防不测。
副本的分布也很重要。默认情况下, Kafka会确保分区的每个副本被放在不同的broker上。不过,有时候这样仍然不够安全。如果这些 broker处于同一个机架上,一旦机架的交换机发生故障,分区就会不可用,这时候把复制系数设为多少都不管用,为了避免机架级别的故障,kafka建议把broker分布在多个不同的机架上,并使用broker.rack参数来为每个broker配置所在机架的名字。如果配置了机架名字,Kafka保证分区的副本被分布在多个机架上,从而获得更高的可用性(3.1.3分区分配章节有具体举例)。
不完全的首领选举
unclean leader.election只能在broker级别(实际上是在集群范围内)进行配置, 它的默认值是true,我们之前提到过,当分区首领不可用时,一个同步副本会被选为新首领,如果在选举过程中没有丢失数据,也就是说提交的数据同时存在于所有的同步副本上,那么这个选举就是“完全”的。但如果在首领不可用时其他副本都是不同步的,我们该怎么办呢?这种情况会在以下两种场景里出现。
1 分区有3个副本,其中的两个跟随者副本不可用(比如有两个broker发生崩愤)。这个时候,如果生产者继续往首领写入数据,所有消息都会得到确认井被提交(因为此时领是唯一的同步副本)。现在我们假设首领也不可用了(又一个 broker 发生崩愤),这个时候,如果之前的一个跟随者重新启动,它就成为了分区的唯一不同步副本。
2 分区有3个副本,因为网络问题导致两个跟随者副本复制消息滞后,所以尽管它们还在复制消息,但已经不同步了。首领作为唯一的同步副本继续接收消息。这个时候,如果首领变为不可用,另外两个副本就再也无法变成同步的了。
对于这两种场景 ,我们要作出一个两难的选择。如果不同步的副本不能被提升为新首领,那么分区在旧首领(最后一个同步副本)恢复之前是不可用的。有时候这种状态会持续数小时(比如更换内存芯片)。如果不同步的副本可以被提升为新首领,那么在这个副本变为不同步之后写入旧首领的消息、会全部丢失,导致数据不一致。为什么会这样呢?假设在副本0和副本1不可用时,偏移量100-200的消息被写入副本3(首领)。现在副本2变为不可用的,而副本0变为可用的。副本0只包含偏移量0-100的消息,不包含偏移量100-200 的消息。如果我们允许副本0成为新首领,生产者就可以继续写人数据,消费者可以继续读取数据。于是新首领就有了偏移量100-200的新消息。这样,部分消费者会读取到偏移 100-200的旧消息,部分消费者会读取到偏移量100-200的新消息,还有部分消费者读取的是二者的混合。这样会导致非常不好的结果,比如生成不准确的报表。另外 ,副本2可能会新变为可用,并成为新首领的跟随者。这个时候,它会把比当前首领旧的消息全部删除,而这些消息对于所有消费者来说都是不可用的。
简而言之,如果我们允许不同步的副本成为首领,那么就要承担丢失数据和出现数据不一致的风险。 如果不允许它们成为首领,那么就要接受较低的可用性,因为我们必须等待原先的首领恢复到可用状态,如果把unclean.leader.election.enable 设为true,就是允许不同步的副本成为首领(也就是“不完全的选举,那么我们将面临丢失消息的风险。如果把这个参数设为false,就要等待原先的首领重新上线,从而降低了可用性。我们经常看到一些对数据质量和数据一致性要求较高的系统会禁用这种不完全的首领选举(把这个参数设为 false 。银行系统是这方面最好的例子,大部分银行系统宁愿选择在几分钟甚至几小时内不处理信用卡支付事务,也不会冒险处理错误的消息。不过在对可用性要求较高的系统里,比如实时点击,流分析系统,一般会启用不完全的首领选举。
最少同步副本
在主题级别和broker级别上,这个参数都叫min.insync.replicas,我们知道 ,尽管为主题配置了3个副本,还是会出现只有一个同步副本的情况。如果这个同步副本变为不可用,我们必须在可用性和一致性之间作出选择,这是一个两难的选择。 kafka消息只有在被写入到所有同步副本之后才被认为是已提交的。但如果这里的“所有副本”只包含一个同步副本,那么在这个副本变为不可用时 ,数据就会丢失。如果要确保已提交的数据被写入不止一个副本,就需要把最少同步副本数量设置为大一点的值。对于一个包含3个副本的主题,如果min.insync.replicas被设为2,那么至少要存在两个同步副本才能向分区写入数据。如果3个副本都是同步的,或者其中1个副本变为不可用,都不会有什么问题。不过,如果有两个副本变为不可用,那么broker就会停止接受生产者的请求。尝试发送数据的生产者会收到NotEnoughReplicasException异常。消费者仍然可以继续读取已有的数据。实际上,如果使用这样的配置,那么当只剩下一个同步副本时,它就变成只读了,这是为了避免在发生不完全选举时数据的写入和读取出现非预期的行为。为了从只读状态中恢复,必须让两个不可用分区中的至少一个重新变为可用的(比如重启broker),并等待它变为同步的。
4.4 kafka可靠保障体系里面的生产者
即使我们尽可能把 broker 配置得很可靠,但如果没有对生产者进行可靠性方面的配置,整个系统仍然有可能出现突发性的数据丢失。 请看以下两个例子
1 为broker配置了3个副本,井且禁用了不完全首领选举,这样应该可以保证万无一失。我们把生产者发送消息的acks设为1(只要首领接收到消息就可以认为消息写入成功)。 生产者发送一个消息给首领,首领成功写入,但跟随者副本还没有接收到这个消息。首领向生产者发送了一个响应,告诉它“消息写入成功”,然后它崩横了,而此时消息还没有被其他副本复制过去,另外两个副本此时仍然被认为是同步的(毕竟判定一个副本不同步需要一小段时间),而且其中的一个副本成了新的首领 因为消息还没有被写入这个副本,所以就丢失了,但发送消息的客户端却认为消息已成功写入,因为消费者看不到丢失的消息,所以此时的系统仍然是一致的(因为副本没有收到这个消息,所以消息不算已提交),但从生产者角度来看,它丢失了一个消息 。
2 为broke配置了3个副本,并且禁用了不完全首领选举。我们接受了之前的教训把生产者的 acks 设为 all 。假设现在往 Kafka 发送消息,分区的首领刚好崩愤,新的首领正在选举当中,Kafka 会向生产者返回“首领不可用”的响应 在这个时候,如果生产者没能正确处理这个错误,也没有重试发送消息直到发送成功,那么消息也有可能丢失。 这算不上是 broker 的可靠性问题,因为broker并没有收到这个消息。这也不是一致性问题,因为消费者井没有读到这个消息。问题在于如果生产者没能正确处理这些错误, 弄丢消息的是它们自己。
那么,我们该如何避免这些悲剧性的后果呢?从上面两个例子可以看出,每个使用Kafk的开发人员都要注意两件事情。1: 根据可靠性需求配置恰当的acks值。 2: 在参数配置和代码里正确处理错误。
4.4.1 发送确认
生产者可以选择以下3种不同的确认模式。
acks=0 意味着如果生产者能够通过网络把消息发送出去,那么就认为消息已成功写入Kafka 。在这种情况下也可以发现一些错误,比如发送的对象无法被序列化或者网卡发生故障,但如果是分区离线或整个集群长时间不可用,那就不能收到任何错误,即使在发生完全首领选举的情况下,这种模式仍然会丢失消息,因为在新首领选举过程中,并不知道首领已经不可用了。在acks=0模式下的运行速度是非常快的(这就是为什么很多基准测试都是基于这个模式),你可以得到惊人的吞吐量和带宽利用 ,不过如果选择了这种模式,一定会丢失一些消息。
acks=1意味着若首领在收到消息并把它写入到分区数据文件(不一定同步到磁盘上)时会返回确认或错误响应。在这个模式下,如果发生正常的首领选举,生产者会在选举时收到 LeaderNotAvailableException异常,如果生产者能恰当地处理这个错误、它会重试发送悄息,最终消息会安全到达新的首领那里。不过在这个模式下仍然有可能丢失数据,比如消息已经成功写入首领,但在消息被复制到跟随者副本之 前首领发生崩溃。
acks=all意味着首领在返回确认或错误响应之前,会等待所有同步副本都收到消息。如果和min.insync. replicas参数结合起来,就可以决定在返回确认前至少有多少个副本能够收到消息,这是最保险的做法,生产者会一直重试直到消息被成功提交。不过这也是最慢的做法,生产者在继续发送其他消息之前需要等待所有副本都收到当前的消息。可以通过使用异步模式和更大的批次来加快速度,但这样做通常会降低吞吐量。
4.4.2 重试参数
生产者需要处理的错误包括两部分,部分是生产者可以自动处理的错误,还有一部分是要开发者手动处理的错误。
如果broker返回的错误可以通过重试来解决,那么生产者会自动处理这些错误。生产者向broker发送消息时,broker可以返回一个成功晌应码或者一个错误响应码。错误晌应码可以分为两种,一种是在重试之后可以解决的,还有一种是无法通过重试解决的。例如,如果broker返回的是 LEADER_NOT_AVAILABLE 错误,生产者可以尝试重新发送消息。也许在这个时候一个新的首领被选举出来了,那么这次发送就会成功。 也就是说, LEADER_NOT_AVAILABLE是一个可重试错误。另一方面,如果broker返回的是INVALID_CONFIG错误,即使通过重试也无能改变配置选项,所以这样的重试是没有意义的。这种错误是不可重试错误。
一般情况下,如果你的目标是不丢失任何消息,那么最好让生产者在遇到可重试错误时能够保持重试。为什么要这样?因为像首领选举或网络连接这类问题都可以在几秒钟之内得到解决,如果让生产者保持重试,你就不需要额外去处理这些问题了。经常会有人问:“为生产者配置多少重试次数比较好?”这个要看你在生产者放弃重试井抛出异常之后想做些什么 如果你想抓住异常并再多重试几次,那么就可以把重试次数设置得多一点,让生产者继续重试,如果你想直接丢弃消息,多次重试造成的延迟已经失去发送消息的意义,或者如果你想把消息保存到某个地方然后回过头来再继续处理,那就可以停止重试。 Kafka的跨数据中心复制工具MirrorMaker会进行无限制的重试(例如 retries=MAX_INT )。作为一个具有高可靠性的复制工具,它决不会丢失消息。
要注意,重试发送一个已经失败的消息会带来一些风险,如果两个消息都写入成功,会导致消息重复。例如,生产者因为网络问题没有收到broker的确认,但实际上消息已经写入 成功,生产者会认为网络出现了临时故障,就重试发送该消息(因为它不知道消息已经写入成功)。在这种情况下,broker会收到两个相同的消息。重试和恰当的错误处理可以保证每个消息“至少被保存一次”,但当前的 Kafka 版本(0.10.0 )无法保证每个消息“只被保存一次”。现实中的很多应用程序在消息里加入唯一标识符,用于检测重复消息,消费者在读取消息时可以对它们进行清理。还有一些应用程序可以做到消息的“幂等”,也就是说,即使出现了重复消息,也不会对处理结果的正确性造成负面影响。例如,消息 “这个账号里有110美元”就是幕等的,因为即使多次发送这样的消息,产生的结果都是一样的。不过消息“往这个账号里增加10美元”就不是幂等的。
4.4.3 额外的错误处理
使用生产者内置的重试机制可以在不造成消息丢失的情况下轻松地处理大部分错误,不过对于开发人员来说,仍然需要处理其他类型的错误,包括:
1 不可重试的 broker错误,例如消息大小错误、认证错误等
2 在消息发送之前发生的错误,例如序列化错误
3 在生产者达到重试次数上限时或者在消息占用的内存达到上限时发生的错误
我们可以为同步发送消息和异步发送悄息编写错误处理器。这些错误处理器的代码逻辑与具体的应用程序及其目标有关。丢弃不合法的消息?把错误记录下来?把这些消息保存在本地磁盘上?回调另一个应用程序?具体使用哪一种逻辑要根据具体的架构来决定。只要记住,如果错误处理只是为了重试发送消息,那么最好还是使用生产者内置的重试机制。
4.5 kafka可靠保障体系里面的消费者
我们已经学习了如何在保证Kafka可靠性的前提下生产数据,现在来看看如何在同样的前提下读取数据。 在本章的开始部分可以看到,只有那些被提交到Kafka的数据,也就是那些已经被写入所有同步副本的数据,对消费者是可用的,这意味着消费者得到的消息已经具备了一致性,消费者唯一要做的是跟踪哪些消息是已经读取过的,哪些是还没有读取过的。这是在读取消息时不丢失消息的关键。在从分区读取数据时,消费者会获取一批事件,检查这批事件里最大的偏移量,然后从这个偏移量开始读取另外 一批事件。这样可以保证消费者总能以正确的顺序获取新数据,不会错过任何事件。
如果一个消费者退出,另一个消费者需要知道从什么地方开始继续处理,它需要知道前面的消费者在退出前处理的最后一个偏移量是多少。所谓的“另一个”消费者,也可能就是它自己重启之后重新回来工作。这也就是为什么消费者要“提交”它们的偏移量。它们把当前读取的偏移量保存起来,在退出之后,同一个群组里的其他消费者就可以接手它们的工作。如果消费者提交了偏移量却未能处理完消息,那么就有可能造成消息丢失,这也是消费者丢失消息的主要原因。在这种情况下,如果其他消费者接手了工作,那些没有被处理完的消息就会被忽略,永远得不到处理。这就是为什么我们非常重视偏移量提交的时间点和提交的方式。
己提交消息与已提交偏移量
要注意,此处的已提交息与之前讨论过的已提交消息是不一样的,后者是指已经被写入所有同步副本并且对消费者可见的消息,而已提交偏移量是指消费者发送给Kafka的偏移量,用于确认它已经收到并处理好的消息位置。
4.5.1 消费者的可靠性配置
为了保证消费者行为的可靠性,需要注意以下4个非常重要的配置参数。
1 第一个是group.id。如果两个消费者具有相同的group.id井且订阅了同一个主题,那么每个消费者会分到主题分区的一个子集, 就是说一个消费者只能读到所有消息的一个子集(不过整个群组会读取主题所有的消息)。如果你希望消费者可以看到主题的所有消息,那么需要为它设置唯一的group.id
2 第二个是auto.offset.reset。这个参数指定了在没有偏移量可提交时(比如消费者第一次启动时)或者请求的偏移量在broker上不存在时,消费者会做些什么。这个参数有两种配置,一种是earliest,如果选择了这种配置,消费者会从分区的开始位置读取数据,不管偏移量是否有效,这样会导致消费者读取大量的重复数据,但可以保证最少的数据丢失。一种是latest,如果选择了这种配置,消费者会从分区的末尾开始读取数据,这样可以减少重复处理消息,但很有可能会错过一些消息。
3 第3个是enable.auto.commit。这是一个非常重要的配置参数,你可以让消费者基于任务调度自动提交偏移量,也可以在代码里手动提交偏移量。自动提交的一个最大好处是,在实现消费者逻辑时可以少考虑一些问题。如果你在消费者轮询操作里处理所有的数据,那么自动提交可以保证只提交已经处理过的偏移量。自动提交的主要缺点是,无法控制重复处理消息(比如消费者在自动提交偏移量之前停止处理消息),而且如果把消息交给另外一个后台线程去处理,自动提交机制可能会在消息还没有处理完毕就提交偏移量。
第4个配置参数 auto.commit.interval.ms与第3个参数有直接的联系。如果选择了自动提交偏移量,可以通过该参数配置提交的频度,默认值是每5秒钟提交1次。 一般来说,频繁的提交会增加额外的开销,但也会降低重复处理消息的概率。
4.5.2 显式提交偏移量
如果选择了自动提交偏移量,就不需要关心显式提交的问题。不过如果希望能够更多地控制偏移量提交的时间点,那么就要仔细想想该如何提交偏移量了,要么是为了减少重复处理消息 ,要么是因为把消息处理逻辑放在了轮询之外。本节会着重说明几个在开发具有可靠性消费者应用程序需要注意的事项。我们先从简单的开始,再逐步深入 。
1 总是在处理完事件后再提交偏移量
如果所有的处理都是在轮询里完成,并且不需要在轮询之间维护状态(比如为了实现多条消息的聚合操作),那么可以使用自动提交,或者在轮询结束时进行手动提交。
2 提交频度是性能和重复消息数之间的权衡
即使是在最简单的场景里,比如所有的处理都在轮询里完成,井且不需要在轮询之间维护状态,你仍然可以在一个循环里多次提交偏移量(甚至可以在每处理完个事件之后),或者多个循环里只提交一次,这完全取决于你在性能和重复处理消息之间作出的权衡。
3 确保对提交的偏移量心里有数
在轮询过程中提交偏移量有一个不好的地方,就是提交的偏移量有可能是读取到的最新偏移量,而不是处理过的最新偏移量。要记住,在处理完消息后再提交偏移量是非常关键的,否则会导致消费者错过消息(比如消费者提交了偏移量后在处理消息时挂了)。
4 再均衡
在设计应用程序时要注意处理消费者的再均衡问题。一般要在分区被撤销之前提交偏移量,井在分配到新分区时清理之前的状态。
5 消费者可能需要重试
有时候,在进行轮询之后,有些消息不会被完全处理,你想稍后再来处理。例如,假设要把Kafka的数据写到数据库里,不过那个时候数据库不可用,于是你想稍后重试。要注意,你提交的是偏移量,而不是对消息的“确认”,这个与传统的发布和订阅消息系统不一样。如果记录#30处理失败,但记录#31处理成功,那么你不应该提交#31,否则会导致的#31以内的偏移量都被提交,包括的#30在内,而这可能不是你想看到的结果。不过可以采用以下两种模式来解决这个问题。
第一种模式,在遇到可重试错误时,提交最后一个处理成功的偏移量,然后把还没有处理好的消息保存到缓冲区里(这样下一个轮询就不会把它们覆盖掉),调用消费者的 pause()方法来确保其他的轮询不会返回数据(不需要担心在重试时缓冲区隘出),在保持轮询的同时尝试重新处理。如果重试成功,或者重试试次数达到上限井决定放弃,那么把错误记录下来井丢弃消息,然后调用 resume()方能让 消费者继续从轮询里获取新数据。
第二种模式,在遇到可重试错误时,把错误写入一个独立的主题,然后继续。 一个独立的消费者群组负责从该主题上读取错误消息,井进行重试,或者使用其中的一个消费者同时从该主题上读取错误消息并进行重试,不过在重试时需要暂停该主题。这种模式有点像其他消息系统里的死信队列。
6 消费者可能需要维护状态
有时候你希望在多个轮询之间维护状态,例如,你想计算消息的移动平均数,希望在首次轮询之后计算平均数,然后在后续的轮询中更新这个结果。如果进程重启 ,你不仅需要从上一个偏移量开始处理数据,还要恢复移动平均数。有一种办怯是在提交偏移量的同时把最近计算的平均数写到一个“结果”主题上。消费者线程在重新启动之后,它就可以拿到最近的平均数并接着计算。不过这并不能完全地解决问题,因为 Kafka 并没有提供事务支持。消费者有可能在写入平均数之后来不及提交偏移量就崩溃了,或者反过来也一样。这个很复杂的问题,你不应该尝试自己去解决这个问题,建议尝试一下KafkaStreams 这个类库 ,它为聚合、连接、时间窗和其他复杂的分析提供了高级的 DSLAPI 。
7. 长时间处理
有时候处理数据需要很长时间,你可能会从发生阻塞的外部系统获取信息,或者把数据写到外部系统,或者进行一个非常复杂的计算。要记住,暂停轮询的时间不能超过几秒钟。即使不想获取更多的数据,也要保持轮询,这样客户端才能往 broker发送心跳。在这种情况下,一种常见的做法是使用一个线程池来处理数据,因为使用多个线程可以进行并行处理,从而加快处理速度。在把数据移交给线程地去处理之后,你就可以暂停消费者,然后保持轮询,但不获取新数据,直到工作线程处理完成。在工作线程处理完成之后,可以让消费者继续获取新数据。因为消费者一直保持轮询,心跳会正常发送,就不会发生再均衡。
8. 仅一次传递
有些应用程序不仅仅需要“至少一次”(at-least-once)语义(意味着没有数据丢失),还需要“仅一次”( exactly-once )语义。尽管 Kafka 现在还不能完全支持仅一次语义,消费者还是有一些办法可以保证Kafka里的每个消息只被写到外部系统一次(但不会处理向Kafka写入数据时可能出现的重复数据),实现仅一次处理最简单且最常用的办能是把结果写到一个支持唯一键的系统里,比如键值存储引擎、关系型数据库,ElasticSearch或其他数据存储引擎。在这种情况下,要么消息本身包含一个唯一键 (通常都是这样),要么使用主题、分区和偏移量的组合来创建唯一键,它们的组合可以唯一标识一个Kafka记录。如果你把消息和一个唯一键写入系统,然后碰巧又读到一个相同的消息,只要把原先的键值覆盖掉即可。数据存储引擎会覆盖已经存在的键值对,就像没有出现过重复数据一样。这个模式被叫作幂等性写入,它是很常见也很有用的模式。如果写入消息的系统支持事务, 那么就可以使用另一种方案。最简单的是使用关系型数据库,不过HDFS里有一些被重新定义过的原子操作也经常用来达到相同的目的。我们把消息和偏移量放在同一事务里,这样它们就能保持同步。在消费者启动时,它会获取最近处理过的消息偏移量,然后调用seek()方法从该偏移量位置继续读取数据。
五 Kafka常见问题总结
5.1 kafka怎么提高吞吐量
有时候处理海量消息,使用kafka作为数据管道时,我们就不得不面一个问题,吞吐量,在解决一系列时候,我们应该要从系统的整体性思考,不仅是kafka的集群,生产者,消费者,以及其他的一些业务程序都应该纳入我们考虑的范围,这里总结了一些比较通用的提升吞吐量的方法
生产者的优化
1 增加每个分区的消息批的大小( batch.size: 16k),适当增加批的最大缓存时间( linger.ms)让生产者累积器中的每个Sender可以累积更多的消息再发送,减少网络请求次数,同时也能增加broker硬盘IO的存储效率(每次顺序写入的多)
2 增加生产者中累积器的内存缓冲区(buffer.memory: 32M)大小,当累积器的缓冲区用完时,也会吧消息发送给broker,通过增加增加生产者中累积器,也可以减少网络请求次数
3 并行生产,多个生产者并行生产消息
4 压缩消息(compression.type:none-默认不压缩),可以选择 gzip、snappy、lz4、zstd 等。减少网络传输的数据量,但是会增加cpu负担,可以在网络流量和cpu之间找到一个平衡点
5 在必要条件时,可以吧ack设置为0,但是会使得丢消息的概率提高
broker的优化
1 适当增加topic的分区数,充分运用到多个broker资源和broker内部的并行处理能力,但需注意过多的分区可能导致的问题。
2 节点配置的优化,比如IO线程数(handler的数量:num.io.threads),网络线程数(Processor的数量:num.network.threads),还有套接字缓冲区的大小(socket.send.buffer.bytes/socket.receive.buffer.bytes)
3 使用固态硬盘等增加硬盘性能,优化文件存储目录的布局以减少 I/O 竞争,如果有多个硬盘,尽量让日志文件分布在多个硬盘上
4 对kafka的jvm进行调优,比如内存和 GC方面优化
5 优化分区副本的放置,确保高可用的同时,避免跨数据中心的复制延迟
消费者的优化
1 通过分区和消费者的关系,可以知道如果分区数和消费者数相同时候,可以充分利用并行处理能力
2 调整每次拉取消息的量(fetch.min.bytes和fetch.max.bytes)减少网络IO
3 并行处理,消费者内部使用多线程处理消息。
5.2 kafka分区太多会带来的问题
1 如果一个broker上分区太多,会降低kafka自身顺序写IO的优势,降低性能
2 元数据量太大,会影响消费者上下线重平衡,broker上线分区重新分配,和leader选举等过程的时间,降低高可用性
3 每个分区在文件系统都有自己的一个目录,broker需要维护这个目录的句柄,开启的文件句柄过多对系统的性能也有一定影响
5.3 怎么确定合理的kafka分区数
创建一个只有1个分区的topic,然后测试这个topic的producer吞吐量和consumer吞吐量。假设它们的值分别是Tp和Tc,单位可以是MB/s。然后假设总的目标吞吐量是Tt,那么分区数 = Tt / max(Tp, Tc),总吞吐量可以通过发送和消费的压测来观察,kafka数据增加放缓或者趋于平稳的时候得到生产吞吐量,开始出现稳定的消息堆积时候得出消费吞吐量,















 2290
2290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









