







欢迎关注公众后”三哥说运维“ 之后在这更新哈
背景:原本是50G的,添加了50G磁盘,但是系统显示报错如标题。
1. 虚拟机增加硬盘容量
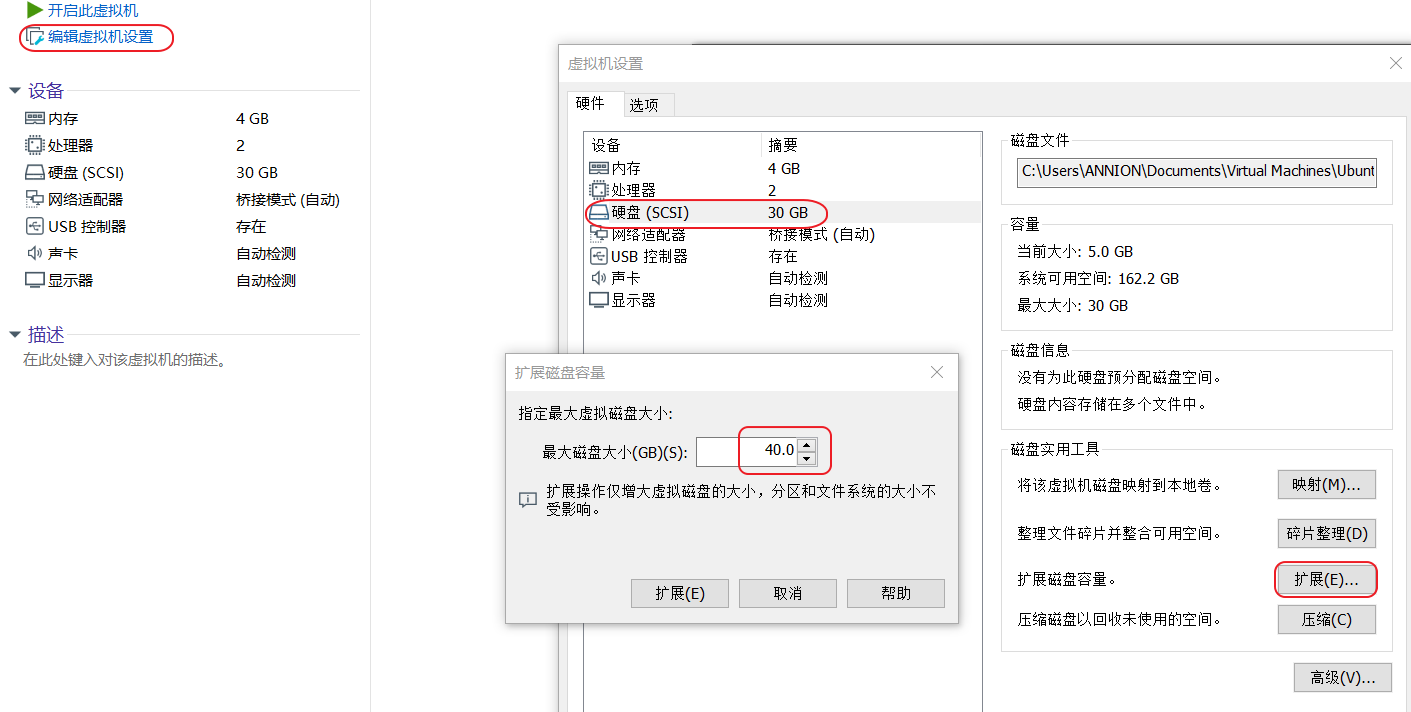
2. 查看ubuntu中当前硬盘信息
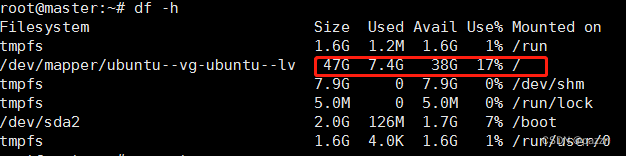
输入命令 df -h
输入命令 fdisk -l 出现报错
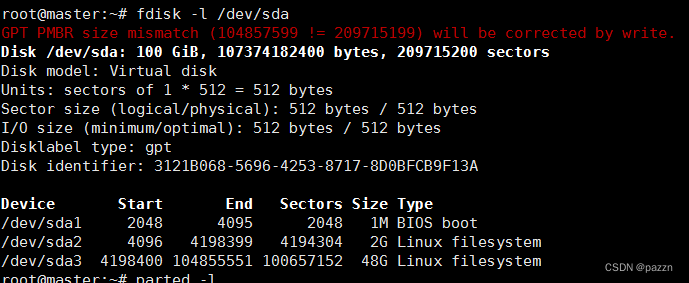
解决:GPT PMBR size mismatch (104857599 != 209715199) will be corrected by write.
输入命令 parted -l 修复分区表
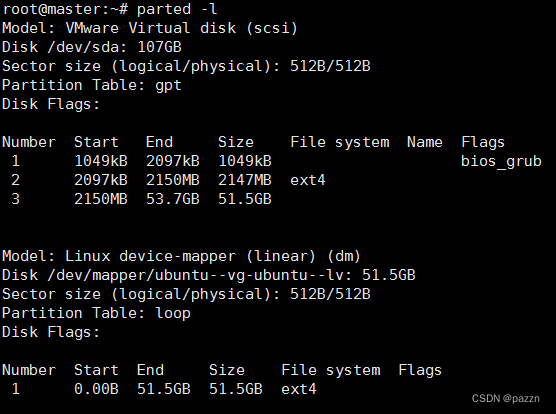
3. 使用 parted 追加容量到/dev/sda3
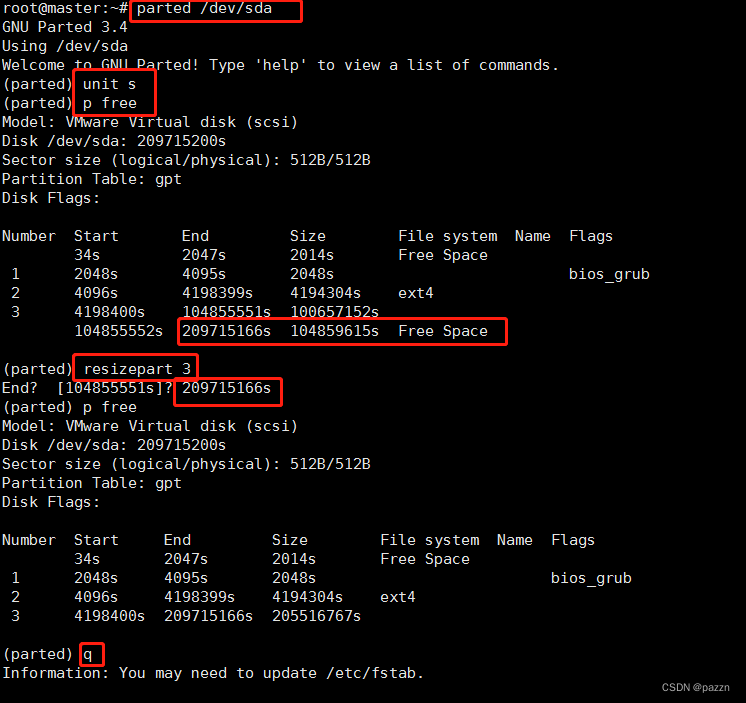
输入命令 parted /dev/sda
输入命令 unit s 设置Size单位,方便追加输入
输入命令 p free 查看详情
输入命令 resizepart 3 追加容量到sda3
输入命令 209715166s空闲容量区间Free Space结束位置
输入命令 q 退出
4.更新LVM中pv物理卷
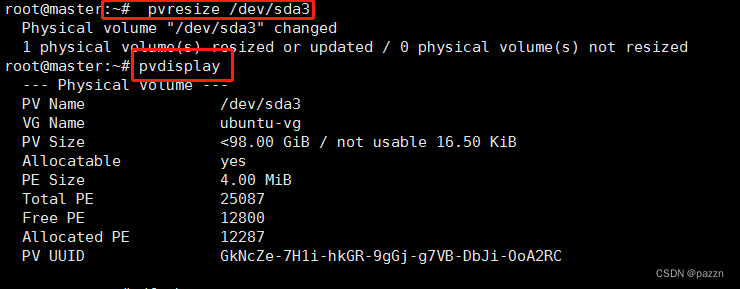
输入命令 pvresize /dev/sda3 更新pv物理卷
输入命令 pvdisplay 查看状态
5.LVM逻辑卷扩容
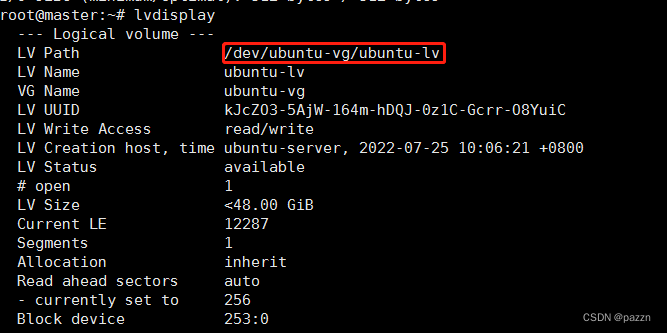
输入命令 lvdisplay获取到这个逻辑卷名称
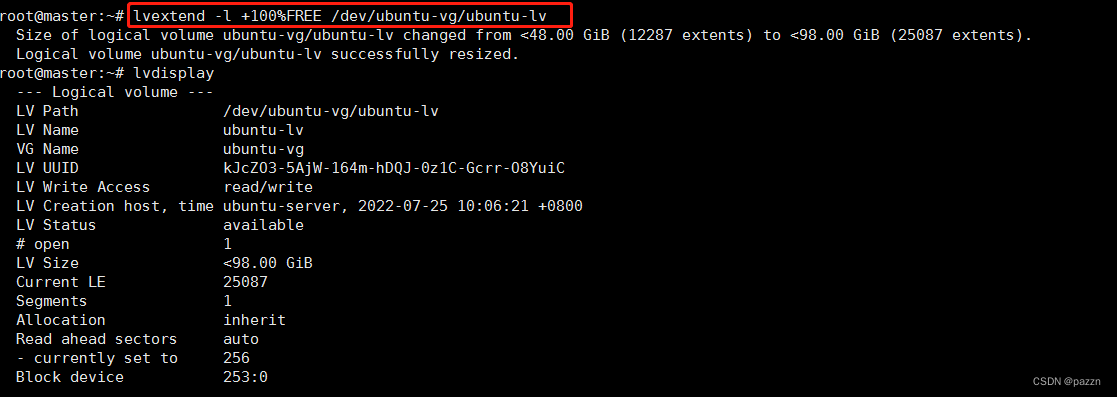
输入命令 lvextend -l +100%FREE /dev/ubuntu-vg/ubuntu-lv 逻辑卷扩容
输入命令 resize2fs /dev/ubuntu-vg/ubuntu-lv 刷新逻辑卷
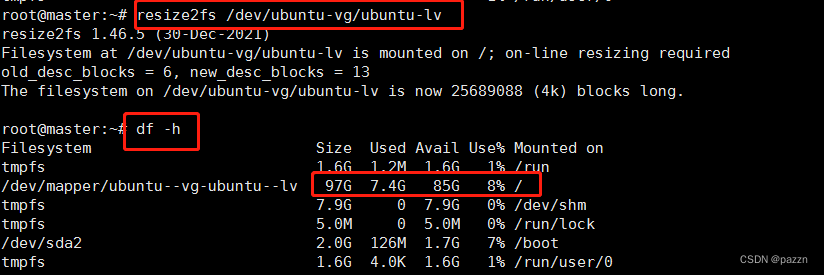
如上图,已经扩容至100G


















 1314
1314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









