






为了挑选并构造出对目标变量有较高预测力的自变量,需要对变量进行WOE编码,通过IV值的看变量的贡献。
1、WOE(weight of Evidence 证据权重)
1)解释及公式
WOE是对原始自变量的一种编码形式。
要对一个变量进行WOE编码,需要首先把这个变量进行分组处理/离散化处理(等宽切割,等高切割,或者利用决策树来切割)。分组后,对于第i组,WOE的计算公式如下:
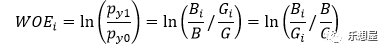
其中:pyi为坏样本占所有坏样本的比例,py0好样本占所有好样本的比例;B为坏样本总数,Bi为变量i对应的坏样本个数,G为好样本总数,Gi为变量i对应的好样本个数 ;
注:将模型目标变量y为1记为违约用户(坏样本),对于目标变量为0记为正常用户(好样本)
2)直观字面理解:
WOE表示的实际上是“当前分组中坏客户占所有坏客户的比例”和“当前分组中好客户占所
有坏客户的比例”的差异。转化公式以后,也可以理解为:当前这个组中坏客户和好客户的比值,和所有样本中这个比值的差异。这个差异为这两个比值的比值,再取对数来表示的。
WOE越大,这种差异越大,这个分组里的样本坏样本可能性就越大,WOE越小,差异越小,这个分组里的坏样本可能性就越小。
3)WOE计算案例:
以年龄为某个自变量,由于年龄是连续型自变量,需要对其进行离散化处理,假设离散化分为5组。#bad和#good表示在这五组年龄中好样本和坏样本的数量分布。

当前分组中,坏样本比例越大,WOE值越大
当前分组WOE的正负,由当前分组坏样本和好样本的比例,与样本整体坏样本和好样本的比例的大小关系决定,当前分组的比例小于样本整体比例时,WOE为负,当前分组的比例大于整体比例时,WOE为正,当前分组的比例和整体比例相等时,WOE为0。
WOE的取值范围是全体实数。
WOE其实描述了变量当前这个分组,对判断个体是否属于坏样本所起到影响方向和大小。当WOE为正时,变量当前取值对判断个体是否会响应起到的正向的影响,当WOE为负时,起到了负向影响。而WOE值的大小,则是这个影响的大小的体现。
4)WOE转化优势:提升模型的预测效果,提高模型的可理解性。
标准化的功能。
WOE编码之后,自变量其实具备了某种标准化的性质,也就是说,自变量内部的各个取值之间都可以直接进行比较(WOE之间的比较)
异常值处理。
一些极值变量,可以通过分组的WOE,变为非异常值
检查变量WOE后与违约概率的关系
一般筛选的变量WOE与违约概率都是单调的,如果出现U型,或者其他曲线形状,则需要重新看下变量是否有问题。
核查WOE变量模型的变量系数出现负值。
如果最终模型的出来的系数出现负值,需要考虑是否出现了多重共线性的影响,或者变量计算逻辑问题。
WOE没有考虑分组中样本占整体样本的比例,如果一个分组的WOE值很高,但是样本数占整体样本数很低,则对变量整体预测的能力会下降。因此,我们还需要计算IV
2、IV(Information Value)信息价值
1)为什么要用IV
在用逻辑回归、决策树等构建分类模型时,经常需要对自变量进行筛选。比如我们有200个候选自变量,通常情况下,不会直接把200个变量直接放到模型中去进行拟合训练,而是会用一些方法,从这200个自变量中挑选一些出来,放进模型,形成入模变量列表。
挑选入模变量过程比较复杂,需要考虑的因素很多,比如:变量的预测能力,变量之间的相关性,变量的简单性(容易生成和使用),变量的强壮性(不容易被绕过),变量在业务上的可解释性(被挑战时可以解释的通)等等。但是,其中最主要和最直接的衡量标准是变量的预测能力。
IV就是用来衡量自变量的预测能力。类似的指标还有信息增益、基尼系数等等。
2)如何理解IV
假设在一个分类问题中,目标变量值为1,0。对于一个待预测的个体A,要判断A属于1还是0,需要知道一写特定信息,假设这个信息总量是I,而这些所需要的信息,就蕴含在所有的自变量x1,x2,x3,……,xn中,那么,对于其中一个变量xi来说,其蕴含的信息越多,那么它对于判断A属于0还是1的贡献就越大,xi的信息价值就越大,xi的IV就越大,它就越应该进入到入模变量列表中。
3)IV的计算公式
IV的计算基于WOE,可以看成对WOE的加权求和
分组i的IV值计算:
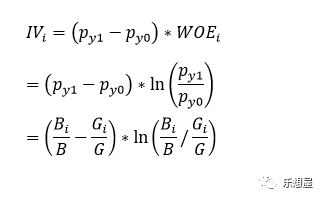
总体的IV:
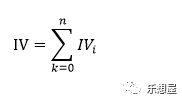
4)IV和WOE的差别
IV和WOE的差别,就在于IV在WOE基础上乘以一个权重(py1-py0),这个权重也是变量筛选考虑使用IV而非WOE去筛选变量的重要。
woe的取值为实数,含有负数,当我们衡量一个变量的预测能力时,使用的指标的评价一般为正数,比如woe值为-0.5的时候,就不知道如何评价这个指标的好坏。而且总体的WOE值,需要单独设立公式,而不是简单的各个组的WOE值相加。
而iv值,因为有这个(py1-py0)权重系数,保证了变量每个分组的结果都是非负数,可以验证一下,当一个分组的WOE是正数时,权重系数也是正数,当一个分组的WOE是负数时,权重也是负数,而当一个分组的WOE=0时,权重系数也是0。
IV值避免了一个组样本数很小,但Bi/Gi很大,从而WOE很大的情况。这种情况出现时,这组样本其实对整体的解释能力是很弱的,比如举个极端的例子,比如py1、py0均小于0.001,但Bi/Gi很大,比如0.9的情况,这时WOE值很高,但IV值会很小。
5)IV计算案例

对于变量的一个分组,这个分组的坏样本和好样本的比例与样本整体坏样本和好样本的比例相差越大,IV值越大,否则,IV值越小;
极端情况下,当前分组的好样本和坏样本的比例和样本整体的坏样本和好样本的比例相等时,IV值为0;
IV值的取值范围是[0,+∞),且,当当前分组中只包含好样本或坏样本时,IV = +∞,此种情况无任何意义
IV值为+∞处理:
IV其实有一个缺点,就是不能自动处理变量的分组中出现响应比例为0或100%的情况。遇到坏样本比例为0或者100%的情况,建议如下:
如果可能,直接把这个分组做成一个规则,作为模型的前置条件或补充条件;
重新对变量进行离散化或分组,使每个分组的响应比例都不为0且不为100%,尤其是当一个分组个体数很小时(比如小于100个),强烈建议这样做,因为本身把一个分组个体数弄得很小就不是太合理。
如果上面两种方法都无法使用,建议人工把该分组的响应数和非响应的数量进行一定的调整。如果响应数原本为0,可以人工调整响应数为1,如果非响应数原本为0,可以人工调整非响应数为1.
6)IV信息量大小与指标判别力有一个经验的规则:
若IV信息量取值小于0.02,认为该指标对因变量没有预测能力,应该被剔除;
若IV信息量取值在0.02与0.1之间,认为该指标对因变量有较弱的预测能力;
若IV信息量取值在0.1与0.3之间,认为该指标对因变量的预测能力一般;
若IV信息量取值大于0.3,认为该指标对因变量有较强的预测能力。
实际应用时,可以保留IV值大于0.1的指标。
参考文章:
http://blog.csdn.net/kevin7658/article/details/50780391
http://blog.sina.com.cn/s/blog_8813a3ae0102uyo3.html
分组变量常规的处理方式除了WOE,还有做dummy变量(哑编码):
3、哑编码
dummy变量是比较顺其自然的操作,例如某个自变量m有3种取值分别为m1,m2,m3,那么可以构造两个dummy变量M1、M2:当m取m1时,M1取1而M2取0;当m取m2时,M1取0而M2取1;当m取m3时,M1取0且M2取0。这样,M1和M2的取值就确定了m的取值。之所以不构造M3变量,是基于信息冗余和多重共线性之类的考虑。但是,构造dummy变量也存在一些缺点,例如无法对自变量的每一个取值计算其信用得分,并且回归模型筛选变量时可能出现某个自变量被部分地舍弃的情况。














 1390
1390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









