








加入 PowerBI自己学 知识星球:下载源文件,边学边练;遇到问题,提问交流,有问必答。
RANKX、RANK、ROWNUMBER都是排名函数。ROWNUMBER和RANK都是窗口函数,语法也类似,在去合计、去并列上比RANKX简便很多,性能也高;ROWNUMBER在去并列上比RANK又略微简便一点。因此,大部分排名场景下,不去并列用RANK,去并列用RANK或ROWNUMBER都可以。排名场景有:
度量值:
1 单个字段相对排名
2 单个字段绝对排名
3 单个字段分组相对排名
4 多个字段相对排名
5 多个字段绝对排名
计算列:
在表内新建计算列,排名没有相对和绝对之分,只有不分组和分组之分。
1 单个字段排名
2 单个字段分组排名
3 多个字段排名
计算表:
1 新建计算表,并一步到位增加一列单个字段排名
2 新建计算表,并一步到位增加一列单个字段分组排名
3 新建计算表,并一步到位增加一列多个字段排名
举例
使用不同函数实现各种场景的排名,了解排名函数的特点和用法。
模型
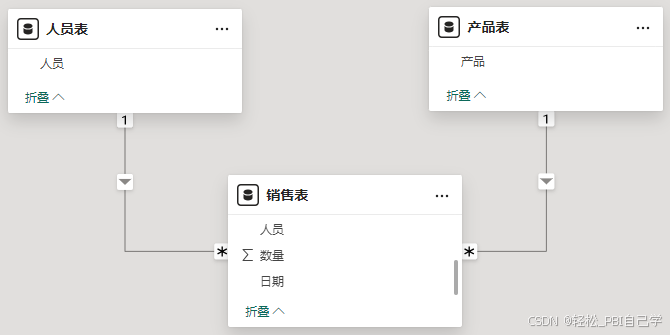
销售表
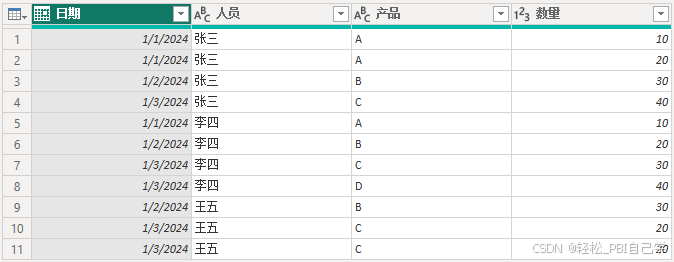
度量值
1 单个字段相对排名
RANKX:
RANKX在去合计、去并列上有一定的劣势,分步骤了解一下并实现最终的度量值。
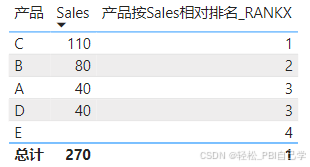
STEP 1 只用RANKX。
产品按Sales相对排名_RANKX = RANKX(ALLSELECTED('产品表'[产品]), [Sales],,, Dense)
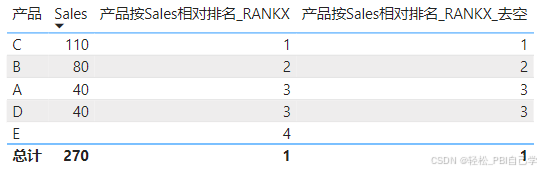
STEP 2 有些产品没有销售数据,不参与排名。
产品按Sales相对排名_RANKX_去空 =
VAR _vm_rank = RANKX(ALLSELECTED('产品表'[产品]), [Sales],,, Dense)
RETURN IF(NOT ISBLANK([Sales]), _vm_rank)
STEP 3 合计行不参与排名。
产品按Sales相对排名_RANKX_去空_去合计 =
VAR _vm_rank = RANKX(ALLSELECTED('产品表'[产品]), [Sales],,, Dense)
RETURN IF(NOT ISBLANK([Sales]) && ISINSCOPE('产品表'[产品]), _vm_rank)
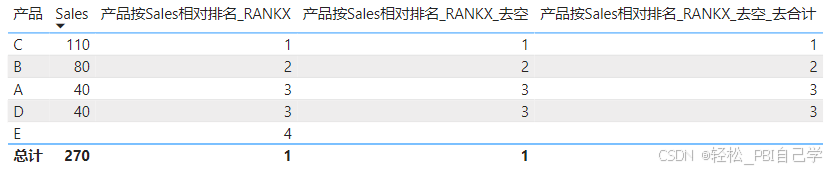
STEP 4 如果遇到销量并列,按照产品名称再次排名去并列。RANKX不支持按多个依据排名,可以做两次排名叠加,按产品个数放大销量排名的倍数,然后在这个基础上叠加产品排名。
产品按Sales相对排名_RANKX_去空_去合计_去并列 =
VAR _vm_NumberProducts = CALCULATE(DISTINCTCOUNT('产品表'[产品]), ALL())
VAR _vm_rank = RANKX(
ALLSELECTED('产品表'[产品]),
CALCULATE(RANKX(ALLSELECTED('产品表'[产品]), [Sales],, ASC))*_vm_NumberProducts+
CALCULATE(RANKX(ALLSELECTED('产品表'[产品]), CALCULATE(MAX('产品表'[产品])),, DESC))
)
RETURN IF(NOT ISBLANK([Sales]) && ISINSCOPE('产品表'[产品]), _vm_rank)

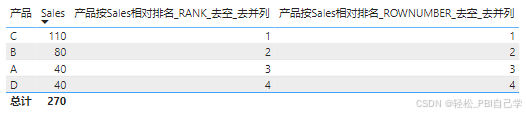
RANK和ROWNUMBER:
不用去合计,但仍然需要增加一个去空的判断条件,去并列的时候,RANK可以自由地补充排名依据按需要去并列,ROWNUMBER会在RANK的基础上增加一个按照排名字段升序彻底去并列。
产品按Sales相对排名_RANK_去空_去并列 =
VAR _vm_rank = RANK(DENSE, ALLSELECTED('产品表'[产品]), ORDERBY([Sales], DESC, [产品], ASC))
RETURN IF(NOT ISBLANK([Sales]), _vm_rank)
产品按Sales相对排名_ROWNUMBER_去空_去并列 =
VAR _vm_rank = ROWNUMBER(ALLSELECTED('产品表'[产品]), ORDERBY([Sales], DESC))
RETURN IF(NOT ISBLANK([Sales]), _vm_rank)
2 单个字段绝对排名
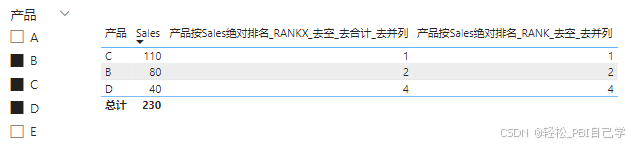
上述方案因为使用了ALLSELECTED函数,排名的范围会受到上下文的筛选的影响,要实现绝对排名,只需要把ALLSELECTED换成ALL即可。
注意:即便使用了ALL也跳不出行级别权限的筛选上下文,因此具备行级别权限的用户,不能看到排名对象在模型整体中的排名。
RANKX:
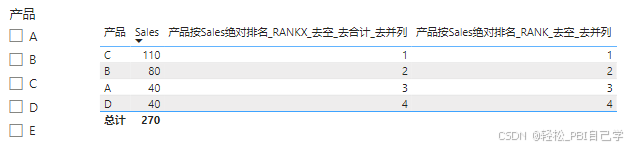
产品按Sales绝对排名_RANKX_去空_去合计_去并列 =
VAR _vm_NumberProducts = CALCULATE(DISTINCTCOUNT('产品表'[产品]), ALL())
VAR _vm_rank = RANKX(
ALL('产品表'[产品]),
CALCULATE(RANKX(ALL('产品表'[产品]), [Sales],, ASC))*_vm_NumberProducts+
CALCULATE(RANKX(ALL('产品表'[产品]), CALCULATE(MAX('产品表'[产品])),, DESC))
)
RETURN IF(NOT ISBLANK([Sales]) && ISINSCOPE('产品表'[产品]), _vm_rank)
RANK(ROWNUMBER与RANK用法相同,不再举例):
产品按Sales绝对排名_RANK_去空_去并列 =
VAR _vm_rank = RANK(DENSE, ALL('产品表'[产品]), ORDERBY([Sales], DESC, [产品], ASC))
RETURN IF(NOT ISBLANK([Sales]), _vm_rank)
不筛选:
筛选后,排名保持不变:
3 单个字段分组相对排名
相对排名的特点是受上下文筛选的影响,把分组的维度字段放入视觉对象中,维度值会起到筛选上下文的作用,排名自然会在这个上下文下重新生成。因此,第1种场景中的度量值都自然就会按分组排名。
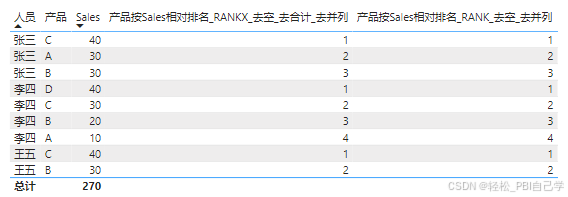
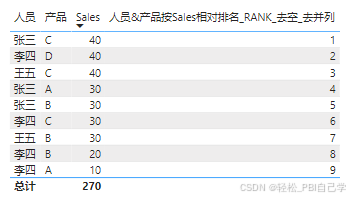
4 多个字段相对排名
第3种场景下,表中有两个维度字段,人员和产品,除了分组给产品排名,还有一种情况就是把人员&产品当作排名对象,按销量做排名。把其他维度字段放入表中,同样起到分组排名的作用。
因为RANKX实现去合计和去并列比较复杂,此处开始仅用RANK举例。
RANK:
人员&产品按Sales相对排名_RANK_去空_去并列 =
VAR _vm_rank =
RANK(
DENSE,
//把人员和产品透视成一个表,上下文为ALLSELECTED
CALCULATETABLE(SUMMARIZECOLUMNS('人员表'[人员], '产品表'[产品]), ALLSELECTED()),
ORDERBY([Sales],DESC,[人员],ASC,[产品],ASC)
)
RETURN IF(NOT ISBLANK([Sales]), _vm_rank)
5 多个字段绝对排名
方法同第2种场景,ALLSELECTED换为ALL。
计算列
计算列中做排名,使用CALCULATE+ALLEXCEPT把排名依据的上下文调整成与排名字段一致即可。
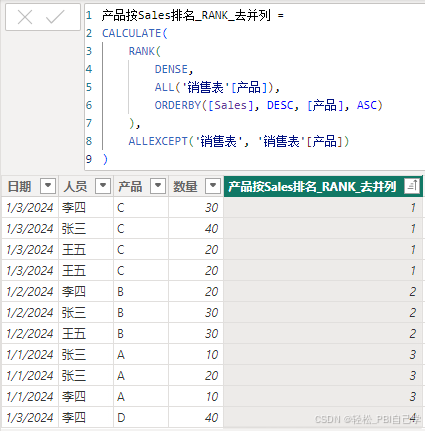
1 单个字段排名,数据表中不存在相对和绝对之分,都是绝对排名
产品按Sales排名_RANK_去并列 =
RANK(
DENSE,
ALL('销售表'[产品]),
ORDERBY(CALCULATE(SUM('销售表'[数量]), ALLEXCEPT('销售表','销售表'[产品])), DESC, [产品], ASC)
)
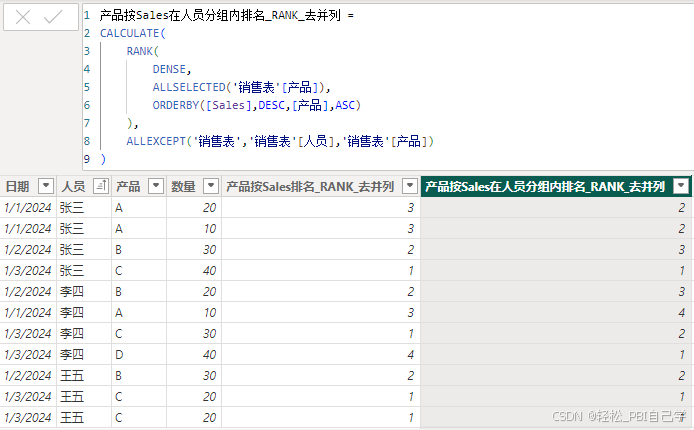
2 单个字段分组排名
产品按Sales在人员分组内排名_RANK_去并列 =
RANK(
DENSE,
ALLSELECTED('销售表'[产品]),
ORDERBY(CALCULATE(SUM('销售表'[数量]), ALLEXCEPT('销售表','销售表'[人员],'销售表'[产品])), DESC, [产品], ASC)
)
3 多个字段排名
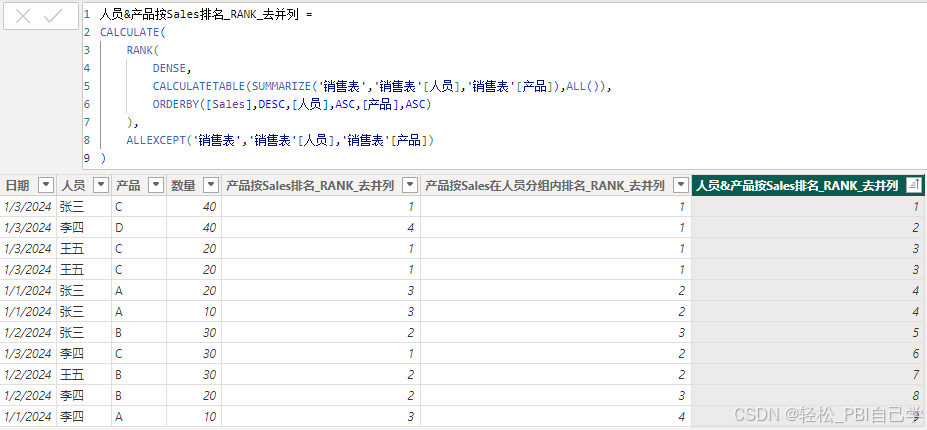
人员&产品按Sales排名_RANK_去并列 =
RANK(
DENSE,
ALL('销售表'[人员],'销售表'[产品]),
ORDERBY(CALCULATE(SUM('销售表'[数量]),ALLEXCEPT('销售表','销售表'[人员],'销售表'[产品])),DESC,[人员],ASC,[产品],ASC)
)
计算表
1 新建计算表,并一步到位增加一列单个字段排名
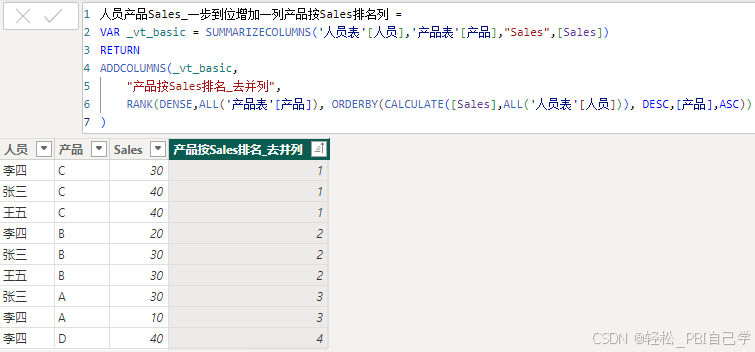
按每个产品的总销量排序,因此排名依据改成了CALCULATE([Sales],ALL('人员表'[人员]))。
人员产品Sales_一步到位增加一列产品按Sales排名列2 =
VAR _vt_basic = SUMMARIZECOLUMNS('人员表'[人员],'产品表'[产品],"Sales",[Sales])
RETURN
ADDCOLUMNS(_vt_basic,
"产品按Sales排名_去并列",
RANK(DENSE,ALL('产品表'[产品]), ORDERBY(CALCULATE([Sales],ALL('人员表'[人员])), DESC,[产品],ASC))
)
2 新建计算表,并一步到位增加一列单个字段分组排名
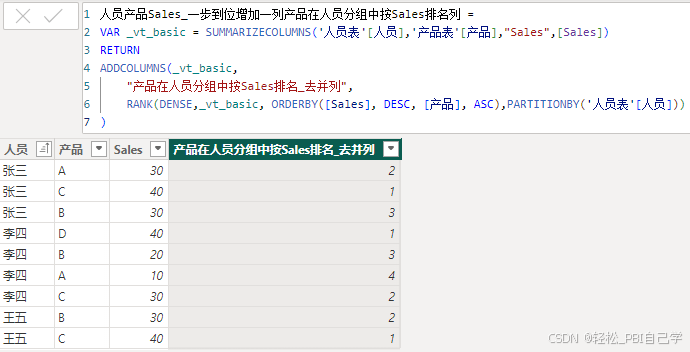
计算表中,给整个表新增一个排名列,使用RANK函数中的PARTITIONBY参数,先分组再排名。
人员产品Sales_一步到位增加一列产品在人员分组中按Sales排名列 =
VAR _vt_basic = SUMMARIZECOLUMNS('人员表'[人员],'产品表'[产品],"Sales",[Sales])
RETURN
ADDCOLUMNS(_vt_basic,
"产品在人员分组中按Sales排名_去并列",
RANK(DENSE,_vt_basic, ORDERBY([Sales], DESC, [产品], ASC),PARTITIONBY('人员表'[人员]))
)
3 新建计算表,并一步到位增加一列多个字段排名
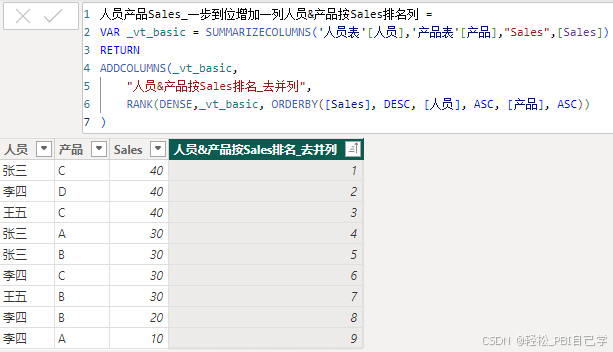
这种最简单,计算表中,给整个表新增一个排名列,默认就是所有列都参与排名。
人员产品Sales_一步到位增加一列人员&产品按Sales排名列 =
VAR _vt_basic = SUMMARIZECOLUMNS('人员表'[人员],'产品表'[产品],"Sales",[Sales])
RETURN
ADDCOLUMNS(_vt_basic,
"人员&产品按Sales排名_去并列",
CALCULATE(RANK(DENSE,_vt_basic, ORDERBY([Sales], DESC, [人员], ASC, [产品], ASC)))
)
拓展
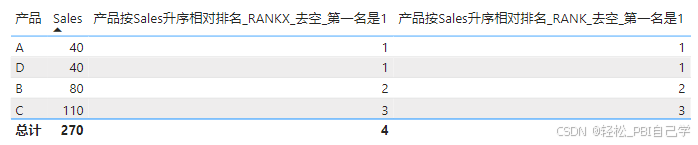
在去空方面,以上案例为数字降序排名,使用条件判断,遇到空值时排名返回空,报告页面会默认隐藏空值。如果是升序排列,空值会按0处理把前面的排名序号占掉,仍然使用条件判断的方法会导致第一名不是从1开始。
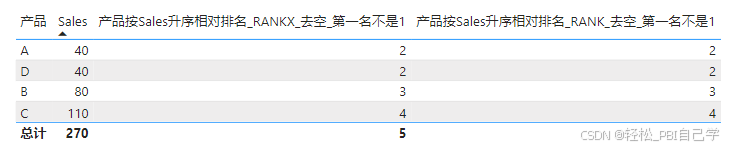
遇到这种情况,RANKX和RANK都会有相应的应对方法,但RANK更强大,从这一点看,排名仍然是推荐使用RANK函数。
RANKX可以通过条件判断改变排名度量值的值,为空值赋一个特别大的数字,把空值强行放在排名的最后。
产品按Sales升序相对排名_RANKX_去空_第一名是1 =
VAR _vm_rank = RANKX(ALLSELECTED('产品表'[产品]), IF(ISBLANK([Sales]), 9999999999, [Sales]),, ASC, Dense)
RETURN IF(NOT ISBLANK([Sales]), _vm_rank)
RANK可以直接使用空值处理参数LAST将空值放在排名的最后。
产品按Sales升序相对排名_RANK_去空_第一名是1 =
VAR _vm_rank = RANK(DENSE, ALLSELECTED('产品表'[产品]), ORDERBY([Sales], ASC), LAST)
RETURN IF(NOT ISBLANK([Sales]), _vm_rank)

















 3008
3008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









