







使用Flume采集业务日志写入Hadoop
目录
1. 需求
2. 开发步骤
3. 部署flume
4. 准备测试数据
5. 配置flume
6. flume采集日志数据
7. hadoop检查采集结果
8. 异常解决
需求
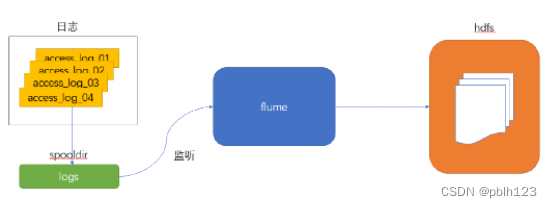
大数据开发工作中,经常涉及到非结构化数据采集的业务需求。其中业务日志的需求最为常见,需要把产生的新日志采集到HDFS,业务流程图如下说所示。
开发步骤
- 安装配置Hadoop集群(已完成则跳过)
- 启动Hadoop集群
- 安装Flume
- 开发Flume配置文件
- 启动agent采集数据
- 检测数据采集结果
部署flume
上传Flume安装包到数据源所在节点,并解压
tar -zxvf apache-flume-1.7.0-bin.tar.gz -C /opt/soft_installed/
进入flume的目录,修改conf下的flume-env.sh,在里面配置JAVA_HOME
cd /opt/soft_installed/apache-flume-1.7.0-bin
cp flume-env.sh.template flume-env.sh
vim flume-env.sh
export JAVA_HOME=/opt/soft_installed/jdk1.8.0_171
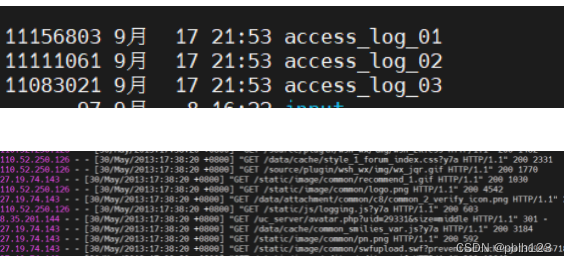
准备测试数据
配置flume
flume配置文件
[root@master conf]# cat spooldir-hdfs.conf
#定义三大组件的名称
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# 配置source组件
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /home/lh/hadooptest/logs/
agent1.sources.source1.fileHeader = false
# 配置拦截器
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = host
agent1.sources.source1.interceptors.i1.hostHeader = hostname
# 配置sink组件
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path =hdfs://node1:9000/weblog/flume-collection/%Y%m%d/%H-%M
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
agent1.sinks.sink1.hdfs.rollSize = 102400
agent1.sinks.sink1.hdfs.rollCount = 1000000
agent1.sinks.sink1.hdfs.rollInterval = 60
#agent1.sinks.sink1.hdfs.round = true
#agent1.sinks.sink1.hdfs.roundValue = 10
#agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in memory
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
flume采集日志数据
[root@master scripts]# cat flume_spooldir_logs.sh
#! /bin/bash
/opt/soft_installed/apache-flume-1.7.0-bin/bin/flume-ng agent -c /opt/soft_installed/apache-flume-1.7.0-bin/conf -f /opt/soft_installed/apache-flume-1.7.0-bin/conf/spooldir-hdfs.conf -n agent1 -Dflume.root.logger=INFO,console
[root@master scripts]#./flume_spooldir_logs.sh
[lh@master hadooptest]$ ls
access_log_01 access_log_02 access_log_03 input logs
[lh@master hadooptest]$ mv access_log_01 logs/

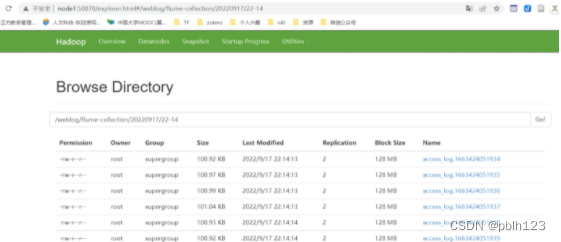
hadoop检查采集结果
异常解决
问题描述: 当使用flume-ng进行日志采集的时候,如果日志文件很大,容易导致flume出现:
java.lang.OutOfMemoryError: Java heap space
解决方法: 调整flume相应的jvm启动参数。修改 flume下的conf/flume-env.sh文件:
```shell
export JAVA_OPTS="-Xms100m -Xmx256m -Dcom.sun.management.jmxremote"
思考题
在企业里,hdfs集群一般不存储小文件,目前flume配置存储了很多小文件。这样的情况企业会怎么解决这个问题?给出你的解决方案。
















 7597
7597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









