








1.ES相关性评分应用
全文检索与数据库查询的一个显著区别是它并不一定会根据查询条件做完全精确的匹配,在全文检索出的结果展示出来前,还会进行一次相关性评分并按评分降序排列,将那些与查询条件相关性高的文档排在最前面返回。
相关度是指两个事物间相互关联的程度,在检索领域特指检索请求与检索结果之间的相关程度。在ES中返回的每一条结果中都会包含一个_score字段,这个字段的值就是当前文档匹配检索请求的相关性评分。
// 请求
POST /users/_doc
{
"name":"arong",
"age":22,
"city":"shenzhen",
"favor":"唱跳、Rap、篮球、写代码"
}
GET /users/_search
{
"query": {
"match": {
"favor":{
"analyzer": "ik_max_word",
"query": "写代码"
}
}
}
}
// 返回结果
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 0.13353139,
"hits" : [
{
"_index" : "users",
"_type" : "_doc",
"_id" : "td7UGH4BuhepqELSpQdP",
"_score" : 0.13353139,
"_source" : {
"name" : "彭博荣",
"age" : 22,
"city" : "shenzhen",
"favor" : "唱跳、Rap、篮球、写代码"
}
}
]
}
ES中相关性评分的应用很广泛,最常见的应用就是搜索引擎中,将最相关的链接展示在最前面,其次还有一些应用:
- 推荐系统中的用户最爱:每个用户的喜好不一致,对喜好字段设置更高权重,由ES打分并推荐最相关商品文档
- 风控系统中的团伙挖掘:对团伙各相关字段(手机号相同、地址相同等)设置权重,并由ES打分获取最相关的团伙文档
- 实时日志检索:基于ELK架构,以关键字作为评分依据,搜索最相关日志文档
2.ES相关性评分算法
ES中的相关性评分算法主要为TF-IDF及EM25算法,在ES 5.0之前使用的都是TF/IDF算法,在之后采用的是EM25算法。
2.1.TF-IDF算法
TF-IDF算法(Term Frequency-Inverse Document Frequency)是文本分析和自然语言处理中常用于计算单词之间相似度的函数。
TF-IDF 通过将词频(Term Frequency)和反向文档频率(Inverse Document Frequency)相乘来工作。词频,是给定单词在文档中出现的次数。后者逆向文档频率,是对单词在语料库中的罕见程度进行评分的一种计算。单词越罕见,其得分就越高。
所以TF-IDF算法的思想就是,关键词在给定文档中出现的次数越高、全体文档中出现的次数越低时,该关键词在给定文档的评分就越高:
- 局部常见:该单词在文档中多次出现
- 全局罕见:该单词在语料库中出现的次数并不多
TF-IDF计算公式为:
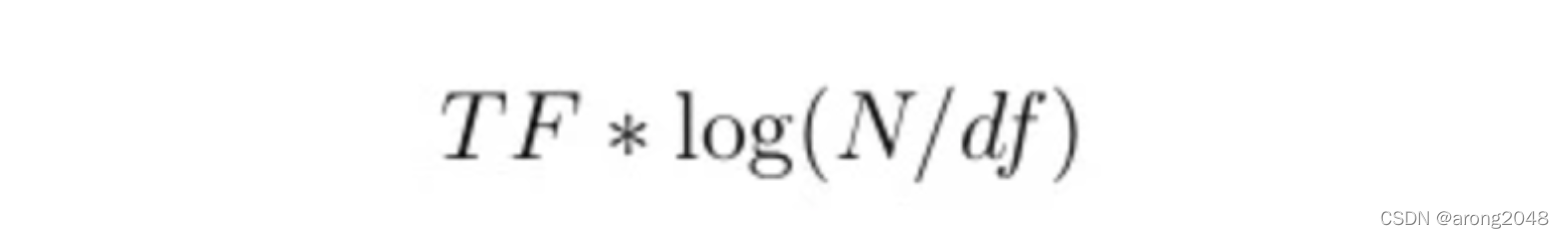
- TF:关键字在指定文档中的词频
- N:所有文档数量
- df:包含了关键字的文档数量
可以看到词频越大,或df越小时,TF-IDF的计算值会越大。
TF-IDF为什么不只依赖于词频,还要依赖于反向文档频率呢?
- 文档长度影响:词频越高不代表越相关,比如A文档只有10个词并命中了1个关键字,而B文档有100个词并命中了5个关键字,此时A文档词频是更高的,但是不一定A文档比B文档更相关
- 常见词影响:如果只看文档的局部词频,那么常见词的影响会很大,并且搜索出来的结果也并不一定相关
所以综合文档长度影响和常见词影响,不只需要考虑文档局部词频,还需要综合考虑该关键字在全部文档中出现次数,以获取更相关的评分。
2.2.EM25算法
在 ES5.0 版本之前其实一直都是使用TF-IDF来计算相似度评分,但由于下面的这些缺陷,它后来转而使用BM25:
- 未考虑文档长度影响:1000个词的文档含有10个关键词,比10个词的文档含有1个词,相似度并不一定更高,因为文档越长所含的关键字也会更多
- 未考虑词频饱和度:词频饱和度指的是当词频超过一定数量之后,它对相关度的影响将趋于饱和。换句话说,词频10次的相关度比词频1次的分值要大很多,但100次与10次之间差距就不会那么明显了
基于上述两个原因,ES 5.0之后采用了BM25算法作为默认的相似度评分算法,BM25算法实际上也借鉴了TF-IDF算法的思想,随着词频的变大和逆向文档频率的变小,相似度会变大,但是不同之处在于考虑了文档长度影响以及词频饱和度,BM25的计算式基于贝叶斯定律推导,是一种概率评分模型,实际上可描述为 IDF * TF:
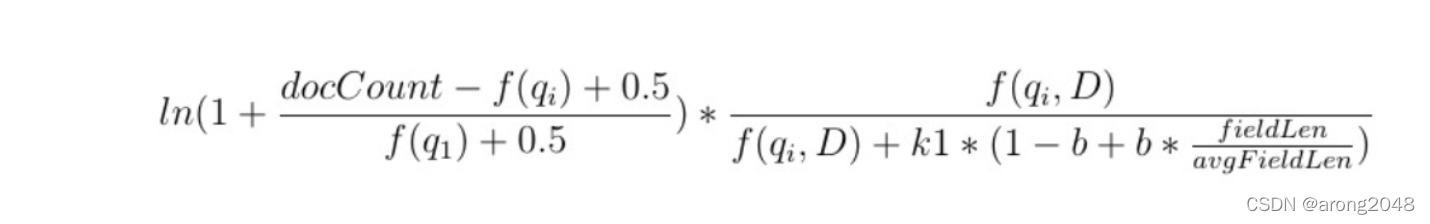
- docCount:文档数量
- f(q):含有关键字的文档数量
- f(q,D):当前文档词频
- k1:词频饱和度控制
- b:文档长度归一化控制
- filedLen:当前文档词大小
- avgFieldLen:平均文档词大小
BM25词频饱和度控制
在BM25算法中,控制词频饱和度的参数是k1,默认值为1.2,参数k1的值越小词频对相关度的影响就会越快趋于饱和,而值越大词频饱和度变化越慢。
BM25长度归一化控制
长度归一化控制也就是文档长度控制,引入了b作为控制因子,使用当前文档长度及平均文档长度的比值来归一化文档长度的影响,当当前文档长度大于平均文档长度时则整体得分会被惩罚。b=0则不开启长度归一化,b=1则完全开启长度归一化, b默认=0.75。
3.ES评分权重提升
3.1.boost参数的使用
在一些情况下需要将某些字段的相关度权重提升,以增加这些字段对检索结果相关性评分的影响。比如,同时使用对文章标题title字段和文章内容content字段做检索,title字段在相关性评分中的权重应该比content字段高一些,这时就可以将title字段的相关度评分权重提高。
可以在执行检索时动态指定boost参数来提升字段的权重,boost参数的默认值为1,一般的使用形式为boost:value 或 field^value:
// 提升单个字段的权重
"match": {
"description": {
"query": "elasticsearch",
"boost": 2.5
}
}
// 对于跨越多个字段的查询,如multi_match,用户可以指定整个multi_match的权重
"multi_match": {
"query": "elasticsearh",
"fields": [
"name",
"description"
],
"boost": 2.5
}
比如要提升name的权重为2,而description的权重保持1,那么可以使用field^boost的方式:
"multi_match": {
"query": "elasticsearch",
"fields": [
"name^2",
"description"
]
}
3.2.布尔组合查询
ES中最常用的组合查询为bool组合查询,bool组合查询可用的布尔类型子句包括must、filter、should和must_not四种,它们接收参数值的类型为数组来实现组合查询机制。
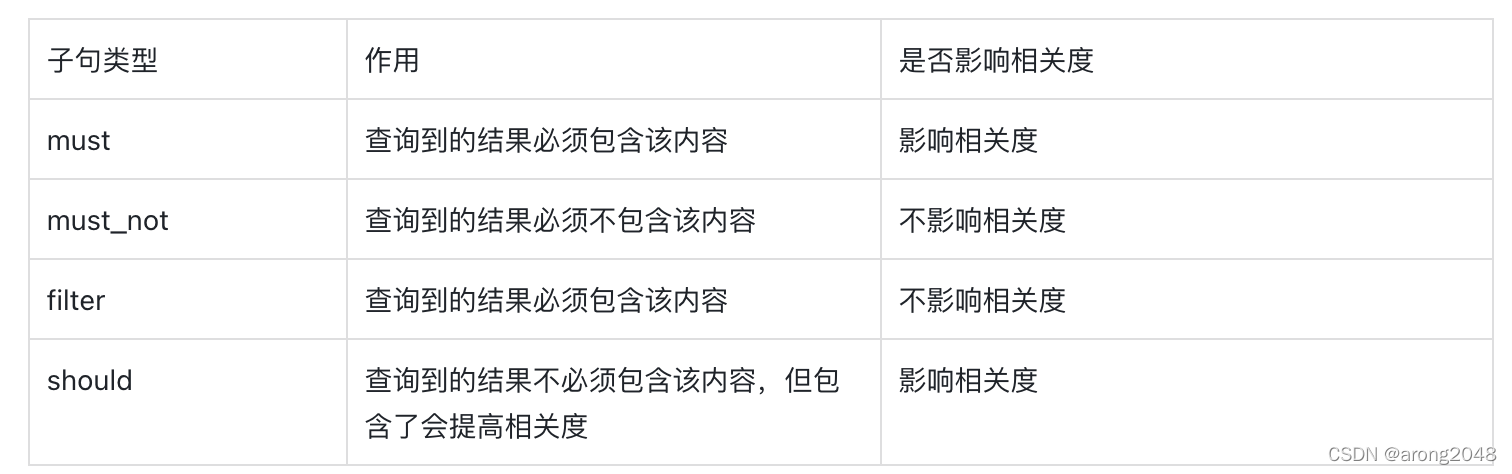
使用这些布尔子句可以组合出更复杂的查询,比如需要查询favor字段包含"写代码"的文档,并且city字段如果包含"guangzhou"那么将city字段权重设置为2,可以这么实现:
GET /users/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"city": {
"value": "guangzhou",
"boost": 2
}
}
}
],
"must": [
{
"match": {
"favor": {
"analyzer": "ik_max_word",
"query": "写代码"
}
}
}
]
}
}
}
3.3.自定义打分函数
function_score查询提供了一组计算查询结果相关度的不同函数,通过为查询条件定义不同打分函数实现文档检索相关性的自定义打分机制。一个function_score自定义打分的结构如图:
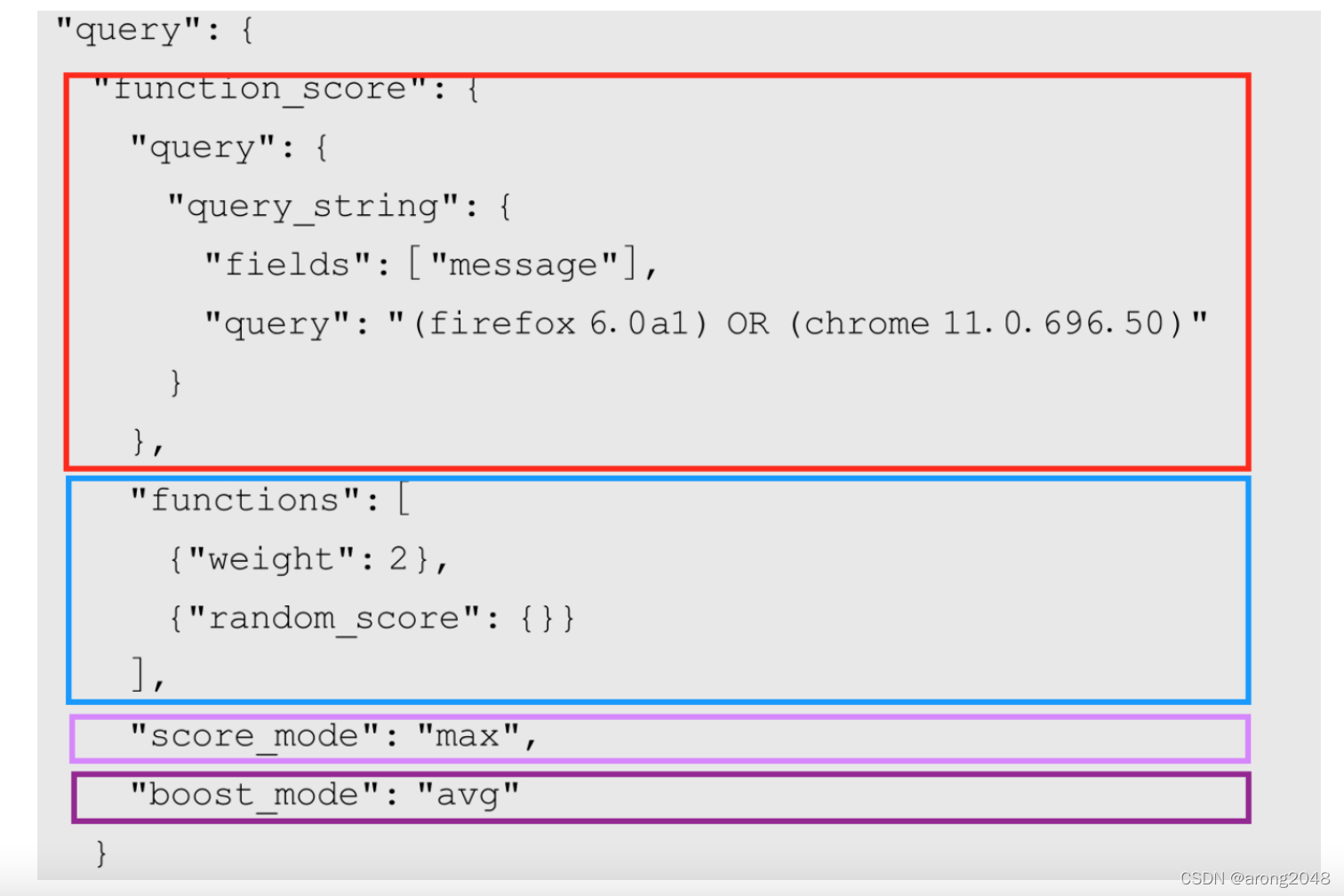
- query:和普通的查询条件格式一致,即文档的查询条件,得到的打分为query_score
- functions:数组格式,定义多个打分函数,打分函数有如下:
- weight : 加权打分
- random_score : 随机打分
- field_value_factor : 使用字段的数值参与计算分数
- decay_function : 衰减函数 gauss, linear, exp 等
- script_score : 自定义脚本
- score_mode:在所有评分函数的运算结果中取它们的乘积、和、平均值、首个值、最大值和最小值打分为func_score
- multiply、sum、avg、first、max、min
- boost_mode:将query_score和func_score结合为最后的文档打分结果result_score,可选的为乘积、和、平均值、替换值、最大值和最小值
- multiply : 相乘(默认),result_score = query_score * function_score
- replace : 替换,result_score = function_score
- sum : 相加,result_score = query_score + function_score
- avg : 取两者的平均值,result_score = avg(query_score, function_score)
- max : 取两者之中的最大值,result_score = max(query_score, function_score)
- min : 取两者之中的最小值,result_score = min(query_score, function_score)



















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











