







Elasticsearch 相关度评分算法
| 序号 | 内容 | 链接地址 |
|---|---|---|
| 1 | SpringBoot整合Elasticsearch7.6.1 | https://blog.csdn.net/miaomiao19971215/article/details/105106783 |
| 2 | Elasticsearch Filter执行原理 | https://blog.csdn.net/miaomiao19971215/article/details/105487446 |
| 3 | Elasticsearch 倒排索引与重建索引 | https://blog.csdn.net/miaomiao19971215/article/details/105487532 |
| 4 | Elasticsearch Document写入原理 | https://blog.csdn.net/miaomiao19971215/article/details/105487574 |
| 5 | Elasticsearch 相关度评分算法 | https://blog.csdn.net/miaomiao19971215/article/details/105487656 |
| 6 | Elasticsearch Doc values | https://blog.csdn.net/miaomiao19971215/article/details/105487676 |
| 7 | Elasticsearch 搜索技术深入 | https://blog.csdn.net/miaomiao19971215/article/details/105487711 |
| 8 | Elasticsearch 聚合搜索技术深入 | https://blog.csdn.net/miaomiao19971215/article/details/105487885 |
| 9 | Elasticsearch 内存使用 | https://blog.csdn.net/miaomiao19971215/article/details/105605379 |
| 10 | Elasticsearch ES-Document数据建模详解 | https://blog.csdn.net/miaomiao19971215/article/details/105720737 |
一. 相关度评分算法的组成
对于Elasticsearch而言,相关度评分的计算规则通过三部分组成: boolean model,TF/IDF,Vector space model。这三个部分没有所谓的权重,它们是平等的,计算时逐层推进。
1.1 boolean model
boolean model是相关度分数计算的第一步操作。
Elasticsearch搜索时,首先根据搜索条件,过滤出符合条件的document,此时Elasticsearch不会做任何的相关度分数计算,仅仅只记录true或false,标记document是否满足搜索要求(对标Elasticsearch内存中的Node Query Cache区域)。
1.2 TF/IDF
TF/IDF是相关度分数计算的第二步操作。
在对搜索条件进行分词后,Elasticsearch会根据TF/IDF算法,依托于index内所有document中,计算每一个(不可拆分的)词条的相关度分数。
TF/IDF算法可以被拆分成TF算法,IDF算法以及length norm算法:
-
TF: term frequency,词频算法。对搜索条件进行分词后,各词条在整个index的所有document中出现的次数越多,则权重越高。
举例:搜索条件为"hello es",document1对应 {“field_test”: “hello world, I am learning es”},document2对应{“field_test”: “hello Wuhan”}。
分析:由于搜索条件分词后,document1包含了2个关键词,而document2只包含了1个关键词,因此在计算TF这一项相关度分数算法指标时,document1比document2高。 -
IDF: inverse document frequency,逆文本频率指数算法。对搜索条件进行分词后,统计各词条在所有(已过滤的)document中出现的次数,出现的次数越多,词条的特性越弱,该词条在后续用于评定相关度分数时,起到的作用也越低。
举例:搜索条件为hello es,document1对应 {“field_test”: “hello world, I am learning something new”},document2对应{“field_test”: “java es”} 其中,hello在index中出现了1000次,es出现了100次。
分析:即便document1和document2中出现词条的次数相同,由于"hello"的相关度评定价值比"es"低,因此,在计算IDF这项相关度算法的权重时,document1比document2低。 -
length norm: 长度规范。对已匹配目标词条的document而言,document的长度越长,则相关度分数阅读。
举例:搜索条件为hello es,document1对应 {“field_test”: “hello world, I am learning something new”}, document2对应{“field_test”: “heelo es”}
分析:虽然两个document都只包含了一个目标词条,但document1内的无用数据比document2多,因此在计算length norm这项相关度算法的权重时,document1比document2低。
最后Elasticsearch会综合上述三种算法,计算出每一个term对于每一个document的权重。
1.3 Vector space model
空间向量算法是相关度分数计算的第三步操作。
从TF/IDF最终的执行结果中,我们不难看出这种算法仍然不能满足我们的需求,因为搜索条件中往往不止有一个term,经过TF/IDF算法后,仅仅只是为每一个(过滤后的)document计算出每一个term的相关度分数,那么怎样求得一个"总分"呢?贸然的对所有term分数求和肯定不好,所以空间向量算法(Vector space model)就派上用场了。
首先,我们从document出发。document由若干个term组成(忽略停用词),通过TF/IDF算法计算后,我们可以得知每一个term在document中的权重,而不同的term又会根据自己的权重影响当前document的相关度得分。
在这里,我们将当前document中出现的所有term的权重组合起来,形成一条向量——Document Vector
显然,Document Vector可能会有多条。
Document = {term1, term2, …… ,termN}
Document Vector = {weight1, weight2, …… ,weightN}
接着,我们把查询条件也看做一个document,分别为其中的每一个词条参考它们在所有document中的权重值计算出各自的权重值,最后组合起来,形成一条向量——Query Vector。
Query = {term1, term2, …… , termN}
Query Vector = {weight1, weight2, …… , weightN}
最后,我们把所有计算出的向量(文档向量和查询向量)放在同一个N维空间中,如图所示:
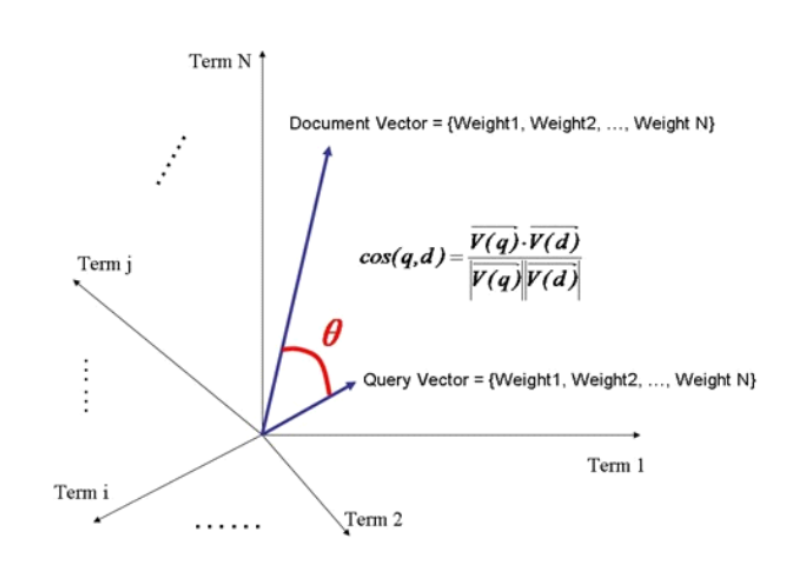
现在的关键是计算每一个Document Vector对于Query Vector的相似度。Elasticsearch认为,若两个向量之间的夹角越小,则相似度越高。
即: 夹角越小 -> 该角的余弦值越大 -> 两条向量的相似度越高 -> 最终相关度分数越高
相关度分数的计算公式如下:

若想对空间向量算法做更深入的了解,可以参考文章: ElasticSearch之向量空间模型算法介绍、
二. Lucene中的相关度分数算法
Lucene中的相关度分数算法,相当于整个相关度评分算法的第二步——TD/IDF算法。
在Lucene中,使用practical scoring function来计算query对某一个document的相关度分数。该函数会使用以下方式计算:
score(q,d) =
queryNorm(q)
· coord(q,d)
· ∑ (
tf(t in d)
· idf(t)2
· t.getBoost()
· norm(t,d)
) (t in q)
这里面涉及到了许多函数,它们的功能大致如下:
- score(q,d)
官方解释: score(q,d)is the relevance score of document d for query q.
这个函数能够计算出一个query(q)针对一个document(d)的最终相关度分数。 - queryNorm(q)
官方解释: queryNorm(q) is the query normalization factor(new).
这个函数用来让document的最终相关度得分处于一个合理的区间,比如document1的分数为1000,而document2的分数却只有0.1,像这种评分跨度就太大了,不适合做最终评分数统计。算法大概是1/√sumOfSquaredWeights,其中sumOfSquaredWeights是∑公式结果,我们对这个结果做平方根计算,再被1除,得到的就是queryNorm()的最终结果。 - coord(q,d)
官方解释: coord(q,d) is the coordination factor (new).
简单来说,就是对更加匹配query的document进行分数上的成倍奖励。比如: query搜索条件是hello java spark,如果某个document中只有hello这个term匹配,假设给定一个term的匹配分数为1.5,那么通过coord算法计算出的分数为: 1.5 x 1 / 3 = 0.5。如果另一个document中有hello和world匹配,假设匹配两个term时,每个term给定的分数是3,那么通过coord算法计算出的分数为: 3 * 2 / 3 = 2。依次类推。涉及coord算法的理由便是为了给那些更匹配query的document给予成倍的分数奖励。 - ∑
官方解释: The sum of the weights for each term t in the query q for document d.
将搜索条件分词后的每一个term对document的相关度分数进行求和,相当于向量空间算法。比如: query搜索条件为hello world,分词后可以得到"hello"和"world"这两个词条。接着,分别对每一个document计算这两个词条的相关度分数,最后求和。 - tf()
官方解释: tf(t in d) is the term frequency for term t in document d.
计算每一个term的对document的分数。本质上是TF算法。 - idf()
官方解释: idf(t) is the inverse document frequency for term t.
计算query搜索条件分词后的词条在逆文本频率指数中的得分。本质上是IDF算法。 - getBoost()
官方解释: t.getBoost() is the boost that has been applied to the query (new).
获取搜索条件中设置的权重,在计算相关度分数时,若搜索条件匹配成功,则乘以对应的权重。 - norm(t, d)
官方解释: norm(t,d) is the field-length norm, combined with the index-time field-level boost, if any. (new).
根据field的长度来计算document的得分。本质上是norm-length算法。
三. 优化相关度分数计算的方式(推荐使用☆☆☆☆☆)
3.1 query-time boost
在搜索时,通过对搜索条件设置boost,实现条件匹配时分数倍增的目的。
GET /index_name/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"field1": {
"query": "value1",
"boost": 2
}
}
},
{
"match": {
"field2": {
"query": "value2",
"boost": 4
}
}
}
]
}
}
}
3.2 negative boost
在搜索时,通过对搜索条件设置negative boost,实现匹配某些条件时分数降低的目的。
比如希望搜索出包含java的数据,但不太想搜索出包含elasticsearch的数据。如果贸然使用must和must_not,会造成同时包含java和elasticsearch的数据被过滤掉的后果。
此时,我们可以使用negative boost来解决这个问题。negative boost会降低elasticsearch词条在每个document中相关度分数计算时的比值,从而变相的提高了java词条的比值,实现更加合理的排序。
GET /index_name/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"field1": "java"
}
},
"negative": {
"match": {
"field1": "elasticsearch"
}
},
"negative_boost": 0.2
}
}
}
注意:
- "positive"代表正向计算相关度分数,默认权重为1(不能修改,比如像3.1节中使用boost手动指定权重)。"negative"代表反向计算相关度分数,它的权重指由"negative_boost"指定。
- negative boost能够"拖垮"整个document的相关度分数。
3.3 constant score
使用constant_score会忽略相关度分数的计算过程,所有document的相关度分数都是1。在Elasticsearch6.x版本以后,constant score内不能使用query语法,只能通过filter来实现数据的过滤,但filter本身恰好又是不计算相关度分数的,因此借助constant score来影响相关度分数的做法渐渐不再被使用。
GET /index_name/_search
{
"query": {
"bool": {
"should": [
{
"constant_score": {
"filter": {
"term": {
"field1": "java"
}
}
}
},
{
"constant_score": {
"filter": {
"terms": {
"field1": ["elasticsearch"]
}
}
}
}
]
}
}
}
四. 使用function score自定义相关度分数算法
4.1 field_value_factor
Elasticsearch中允许自定义相关度分数算法的计算函数,这个函数计算出的结果可以参与到最终的相关度分数计算中,甚至可以直接作为最终的相关度分数(但不会影响boolean model,TF/IDF以及Vector Space Model的执行过程)。
举例:
POST /index_name/_bulk
{"index" : { "_id" : "1" }}
{"fc" : 10, "f" : "hello world"}
{"index" : { "_id" : "2" }}
{"fc" : 20, "f" : "hello java"}
{"index" : { "_id" : "3" }}
{"fc" : 5, "f" : "hello spark"}
{"index" : { "_id" : "4" }}
{"fc" : 15, "f" : "hello bye bye"}
{"index" : { "_id" : "5" }}
{"fc" : 13, "f" : "hi world"}
GET /index_name/_search
{
"query": {
"function_score": {
"query": {
"match": {
"f": "java spark"
}
},
"field_value_factor": {
"field": "fc",
"modifier": "log2p",
"factor": 0.5
},
"boost_mode": "sum",
"max_boost": 0.8
}
}
}
如果field_value_factor中只写了"field",那么Elasticsearch会在query match中计算出的相关度分数的基础上直接乘以document中对应"field"字段的值。比如直接使用query match “f”: "java spark"时,得到的document的分数为1.43,而fc的值为20,那么组合后计算出的相关度分数为1.43 x 20 = 28.6。
modifier是针对field的计算公式。Elasticsearch内部提供了大量的计算公式,比如ln、ln1p、ln2p、log1p、log2p等等。举个例子,log2p对应的公式为: log以2为底,2+number_of_votes的对数,number_of_votes就是document中对应自定义相关度分数计算字段的值。最终得到的结果再去和前面query match计算出的值相乘。
factor可以进一步影响相关度分数的计算, log(1 + factor * number_of_votes)。
前面都是用自定义相关度分数乘以query match的值作为最终的相关度分数,倘若不想使用乘法,我们还可以选用boost_mode参数。
boost_mode可以选择函数: max(最大值)、min(最小值)、avg(平均值)、multiply(乘法[默认值])、replace(替换)、sum(求和)。
max_boost,限制自定义相关度分数字段最终计算出的数值不得超过max_boost指定的值,如果超过,则直接使用max_boost的值。














 1606
1606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









