







 超级会员免费看
超级会员免费看
关于ACE2005数据集
ACE2005数据集是一个用于命名实体识别和关系抽取的英文数据集。它是Automatic Content Extraction (ACE)项目的一部分,旨在推动信息提取系统的发展。由于该数据集非常难得稀缺,基本上网络上找不到,因此我写下这篇文章来分享给更多的人,从而帮助他们能有一个便捷的渠道获取资源的介绍和下载使用。

ACE2005数据集包含来自新闻文本的标注实体和关系的信息,其中实体包括人物、组织、地点等类别,关系则包括人物之间的关系、人物与组织之间的关系等。这些标注的信息可以帮助训练机器学习模型来识别文本中的实体和关系,从而进行自动化的信息提取和知识图谱构建。

 The ACE 2005 dataset addresses five primary tasks – the recognition of entities, values, temporal expressions, relations, and events.
The ACE 2005 dataset addresses five primary tasks – the recognition of entities, values, temporal expressions, relations, and events.
ACE2005数据库解决了3项基本的任务——实体识别、值、事件表达式、关系和事件
The dataset is available at the Linguistic Data Consortium. The data is taken from a variety of sources and is available for the tasks in the following languages: Arabic, Chinese and English.
这个数据集可以从语言数据联盟获得. 数据来自多种数据源并可以在如下语言的相关任务中使用
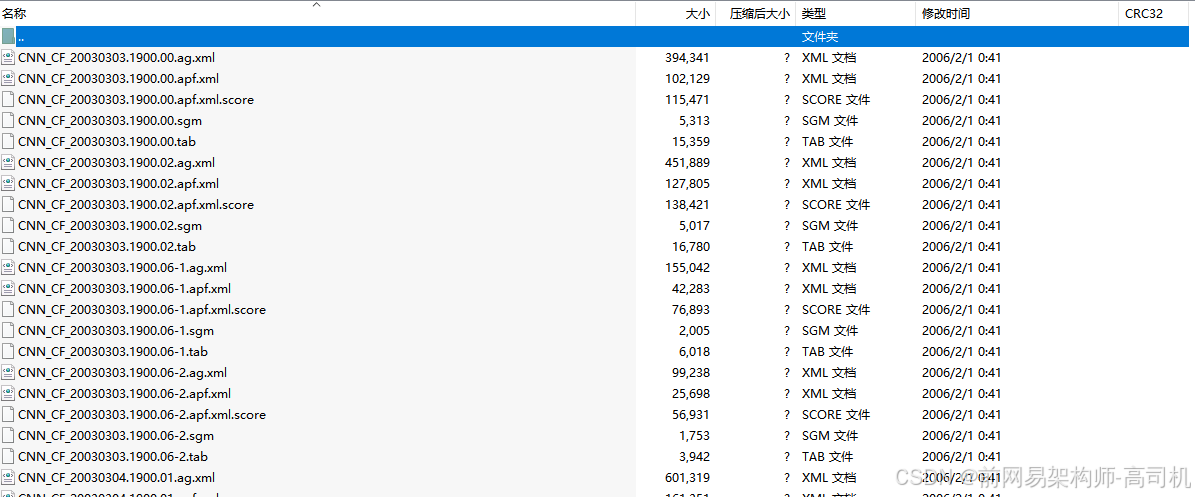
Four versions of each document are provided:
每一个文件都提供了4种版本:
Source text files (.sgm): All source files, including the Chinese files, are encoded in UTF-8.
源文本文件(.sgm):所有源文件,包括中文文件,都用UTF-8编码。
APF files (.apf.xml): The ACE Program Format.
APF文件 (.apf.xml): ACE程序格式
AG files (.ag.xml): The LDC Annotation Graph Format.
AG文件(. AG .xml): LDC注释图格式。
TABLE files (.tab): Files that store mapping tables between the IDs used in each ag.xml file and their corresponding apf.xml file.
表文件(.tab):存储每个ag.xml文件中使用的id与其对应的apf.xml文件id之间的映射表的文件

The detailed statistics for the training portion of this corpus are as follows:
应用:
ACE2005数据集在自然语言处理领域被广泛应用,特别是在命名实体识别和关系抽取任务中。研究人员和开发者可以利用这个数据集来评估他们的模型在信息提取任务上的性能,并不断改进模型的准确性和泛化能力。
总的来说,ACE2005数据集为自然语言处理领域的研究提供了一个标准化的评估基准,促进了信息提取技术的发展和应用。
下载地址:
本文提供两种方式获取数据集:
1.通过ACE 2005 Multilingual Training Corpus - Linguistic Data Consortium 联系宾夕法尼亚大学获取
2.通过CSDN提供的下载链接获取:https://download.csdn.net/download/pbymw8iwm/88596642
(如果已经订阅该专栏,下载资源可享受半价优惠,优惠通道可点击下方的微信链接获取)


















 126
126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









