






点击上方“Python共享之家”
关注回复“资料”可获赠Python学习福利
今
日
鸡
汤
声喧乱石中,色静深松里。
大家好,我是皮皮。其实这个pandas教程,卷的很严重了,才哥,小P等人写了很多的文章,这篇文章是粉丝【古月星辰】投稿,自己学习过程中整理的一些基础资料,整理成文,这里发出来给大家一起学习。

Pandas入门
本文主要详细介绍了pandas的各种基础操作,源文件为zlJob.csv,可以私我进行获取,下图是原始数据部分一览。

pandas官网:
https://pandas.pydata.org/pandas-docs/stable/getting_started/index.html目录结构:
生成数据表
数据表基本操作
数据清洗
时间序列
一.生成数据表
1.1 数据读取
一般情况下我们得到的数据类型大多数csv或者excel文件,这里仅给出csv,
读取csv文件
pd.read_csv()读取excel文件
pd.read_excel()1.2 数据的创建
pandas可以创建两种数据类型,series和DataFrame;
创建Series(类似于列表,是一个一维序列)
s = pd.Series([1,2,3,4,5])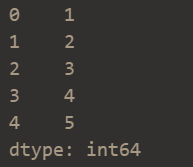
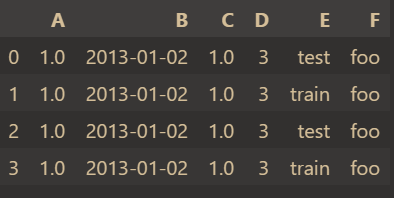
创建dataframe(类似于excel表格,是二维数据)
df2 = pd.DataFrame( { "A": 1.0, "B": pd.Timestamp("20130102"), "C": pd.Series(1, index=list(range(4)), dtype="float32"), "D": np.array([3] * 4, dtype="int32"), "E": pd.Categorical(["test", "train", "test", "train"]), "F": "foo", } )
二、数据表的基本操作
2.1 数据查看
查看前五行
data.head() # head() 参数表示前几行,默认为5

基本信息
data.shape(990, 9)
data.dtypes
查看空值
data['name'].isnull() # 查看name这一列是否有空值
2.2 行和列的操作
添加一列
dic = {'name':'前端开发','salary':2万-2.5万, 'company':'上海科技有限公司', 'adress':'上海','eduBack':'本科','companyType':'民营', 'scale':1000-10000人,'info':'小程序'}
df = pd.Series(dic)
df.name = 38738
data = data.append(df)
data.tail()结果:

删除一行
data = data.drop([990])添加一列
data = data["xx"] = range(len(data))删除一列
data = data.drop('序号',axis=1)axis表示轴向,axis=1,表示纵向(删除一列)
2.3 索引操作
loc
loc主要是基于标签(label)的,包括行标签(index)和列标签(columns),即行名称和列名称,可以使用df.loc[index_name,col_name],选择指定位置的数据,其它的用法有:
1. 使用单个标签
data.loc[10,'salary']
# 9千-1.3万2. 单个标签的list
data.loc[:,'name'][:5]
3. 标签的切片对象
data.loc[:,['name','salary']][:5]
iloc
iloc是基于位置的索引,利用元素在各个轴上的索引序号进行选择,序号超出范围会产生IndexError,切片时允许序号超过范围,用法包括:
1. 使用整数
data.iloc[2] # 取出索引为2的那一行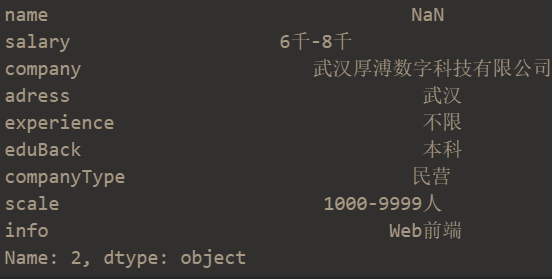
2. 使用列表或数组
data.iloc[:5]
3. 切片对象
data.iloc[:5,:4] # 以,分割,前面切片5行,后面切片4列
常见的方法就如上所示。
2.4 层次化索引
series层次化索引
s = pd.Series(np.arange(1,10),index=[list('aaabbccdd'),[1,2,3,1,2,3,1,2,3]])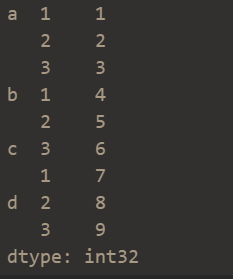
dataframe层次化索引
df = pd.DataFrame(np.arange(12).reshape(4,3),index=[['a','a','b','b'],[1,2,1,2]],columns=[['X','X','Y'],['m','n','t']])
层次化索引应用于当目标数据的特征值很多时,我们需要对多个特征进行分析。
三、数据预处理
3.1 缺失值处理
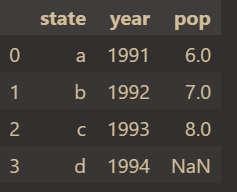
首先创建一个简单的表格:
df = pd.DataFrame({'state':['a','b','c','d'],'year':[1991,1992,1993,1994],'pop':[6.0,7.0,8.0,np.NaN]})
df结果如下:
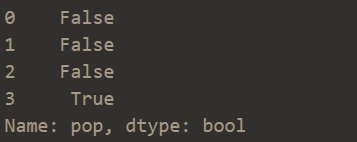
判断缺失值
df['pop'].isnull()结果如下:
填充缺失值
df['pop'].fillna(0,inplace=True) # 使用0填充缺失值
df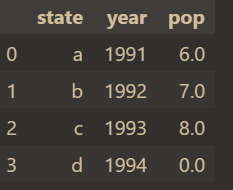
删除缺失值
data.dropna(how = 'all') # 传入这个参数后将只丢弃全为缺失值的那些行结果如下:

当然还有其他情况:
data.dropna(axis = 1) # 丢弃有缺失值的列(一般不会这么做,这样会删掉一个特征)
data.dropna(axis=1,how="all") # 丢弃全为缺失值的那些列
data.dropna(axis=0,subset = ["Age", "Sex"]) # 丢弃‘Age’和‘Sex’这两列中有缺失值的行这里就不做一一展示(原理都是一样的)
3.2 字符处理
清除字符空格
df['A']=df['A'].map(str.stri())大小写转换
df['A'] = df['A'].str.lower()3.3 重复值处理
删除后面出现的重复值
df['A'] = df['A'].drop_duplicates() # 某一列后出现重复数据被清除删除先出现的重复值
df['A'] = df['A'].drop_duplicates(keep=last) # # 某一列先出现重复数据被清除数据替换
df['A'].replace('sh','shanghai') # 同于字符串替换四、数据表操作
分组
groupby
group = data.groupby(data['name']) # 根据职位名称进行分组
group根据职位名称进行分组:
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x00000265DBD335F8>
得到一个对象,我们可以去进行平均值,总和计算;
当然了可以根据多个特征进行分组,也是没有问题的;
聚合
concat():
pd.concat(
objs,
axis=0,
join="outer",
ignore_index=False,
keys=None,
levels=None,
names=None,
verify_integrity=False,
copy=True,
)官网参数解释如下:
objs: Series 或 DataFrame 对象的序列或映射。如果传递了 dict,排序后的键将用作keys参数,除非传递,在这种情况下将选择值(见下文)。任何 None 对象都将被静默删除,除非它们都是 None 在这种情况下将引发 ValueError 。axis:{0, 1, …},默认为 0。要沿其连接的轴。join: {'inner', 'outer'}, 默认为 'outer'。如何处理其他轴上的索引。外部用于联合,内部用于交集。ignore_index: 布尔值,默认为 False。如果为 True,则不要使用串联轴上的索引值。结果轴将被标记为 0, …, n - 1。如果您在连接轴没有有意义的索引信息的情况下连接对象,这将非常有用。请注意,其他轴上的索引值在连接中仍然有效。keys: 序列,默认无。使用传递的键作为最外层构建分层索引。如果通过了多个级别,则应包含元组。levels: 序列列表,默认无。用于构建 MultiIndex 的特定级别(唯一值)。否则,它们将从密钥中推断出来。names: 列表,默认无。生成的分层索引中级别的名称。verify_integrity: 布尔值,默认为 False。检查新的串联轴是否包含重复项。相对于实际的数据串联,这可能非常昂贵。copy: 布尔值,默认为真。如果为 False,则不要不必要地复制数据。
测试:
df1 = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3],
)
df2 = pd.DataFrame(
{
"A": ["A4", "A5", "A6", "A7"],
"B": ["B4", "B5", "B6", "B7"],
"C": ["C4", "C5", "C6", "C7"],
"D": ["D4", "D5", "D6", "D7"],
},
index=[4, 5, 6, 7],
)
df3 = pd.DataFrame(
{
"A": ["A8", "A9", "A10", "A11"],
"B": ["B8", "B9", "B10", "B11"],
"C": ["C8", "C9", "C10", "C11"],
"D": ["D8", "D9", "D10", "D11"],
},
index=[8, 9, 10, 11],
)
frames = [df1, df2, df3]
result = pd.concat(frames)
result结果如下:

merge()
pd.merge(
left,
right,
how="inner",
on=None,
left_on=None,
right_on=None,
left_index=False,
right_index=False,
sort=True,
suffixes=("_x", "_y"),
copy=True,
indicator=False,
validate=None,
)这里给出常用参数解释:
left:一个 DataFrame 或命名的 Series 对象;right:另一个 DataFrame 或命名的 Series 对象;on: 要加入的列或索引级别名称;left_on:左侧 DataFrame 或 Series 的列或索引级别用作键。可以是列名称、索引级别名称或长度等于 DataFrame 或 Series 长度的数组;right_on:来自正确 DataFrame 或 Series 的列或索引级别用作键。可以是列名称、索引级别名称或长度等于 DataFrame 或 Series 长度的数组left_index:如果True,则使用左侧 DataFrame 或 Series 中的索引(行标签)作为其连接键;right_index:与left_index正确的 DataFrame 或 Series 的用法相同;how:'left','right','outer', 之一'inner'。默认为inner. 有关每种方法的更详细说明,请参见下文。
测试:
left = pd.DataFrame(
{
"key": ["K0", "K1", "K2", "K3"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
}
)
right = pd.DataFrame(
{
"key": ["K0", "K1", "K2", "K3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
}
)
result = pd.merge(left, right, on="key")
result结果如下:
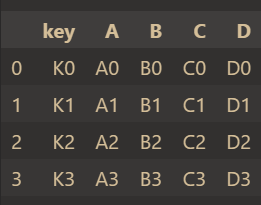
相同的字段是'key',所以指定on='key',进行合并。
五、时间序列
5.1 生成一段时间范围
date = pd.period_range(start='20210913',end='20210919')
date输出结果:
PeriodIndex(['2021-09-13', '2021-09-14', '2021-09-15', '2021-09-16', '2021-09-17', '2021-09-18', '2021-09-19'], dtype='period[D]', freq='D')
5.2 时间序列在pandas中的应用
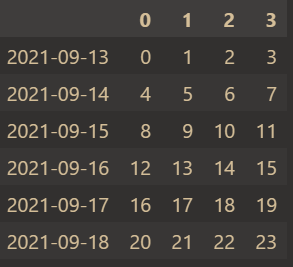
index = pd.period_range(start='20210913',end='20210918')
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=index)
df输出结果:
六、总结
本文基于源文件zlJob.csv,进行了部分pandas操作,演示了pandas库常见的数据处理操作,由于pandas功能复杂,具体详细讲解请参见官网:
https://pandas.pydata.org/pandas-docs/stable/getting_started/index.html
需要源数据的小伙伴可以添加我为好友,私我进行获取。

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









